BAT常问问题总结以及回答(数据库篇)
数据库
- 事务四大特性(ACID)原子性、一致性、隔离性、持久性
事务:所谓事务,它是一个操作序列,这些操作要么都执行,要么都不执行,它是一个不可分割的工作单位。begin transaction原子性:指事务是不可再分的最小操作单位,事务中的操作要么都发生,要么都不发生。一致性:关系型数据库在事务开始和结束之后不能破坏关系表之间关系的完整性和一致性,从一个一致性状态到另一个一致性状态。隔离性:多个事务同时运行时互不干扰(事务之间的相互影响分为几种,分别为:脏读,不可重复读,幻读,丢失更新)。持久性:事务一旦提交就不会被回滚,被持久化到硬盘中。事务的(ACID)特性是由关系数据库管理系统(RDBMS,数据库系统)来实现的。数据库管理系统采用日志来保证事务的原子性、一致性和持久性。日志记录了事务对数据库所做的更新,如果某个事务在执行过程中发生错误,就可以根据日志,撤销事务对数据库已做的更新,使数据库退回到执行事务前的初始状态。
数据库管理系统采用锁机制来实现事务的隔离性。当多个事务同时更新数据库中相同的数据时,只允许持有锁的事务能更新该数据,其他事务必须等待,直到前一个事务释放了锁,其他事务才有机会更新该数据。
- 数据库隔离级别,每个级别会引发什么问题,mysql默认是哪个级别
SQL标准定义了4类隔离级别,包括了一些具体规则,用来限定事务内外的哪些改变是可见的,哪些是不可见的。低级别的隔离级一般支持更高的并发处理,并拥有更低的系统开销。
Read Uncommitted(读取未提交内容)
在该隔离级别,所有事务都可以看到其他未提交事务的执行结果。本隔离级别很少用于实际应用,因为它的性能也不比其他级别好多少。读取未提交的数据,也被称之为脏读(Dirty Read)。
Read Committed(读取提交内容)
这是大多数数据库系统的默认隔离级别(但不是MySQL默认的)。它满足了隔离的简单定义:一个事务只能看见已经提交事务所做的改变。这种隔离级别 也支持所谓的不可重复读(Nonrepeatable Read),因为同一事务的其他实例在该实例处理其间可能会有新的commit,所以同一select可能返回不同结果。
Repeatable Read(可重读)
这是MySQL的默认事务隔离级别,它确保同一事务的多个实例在并发读取数据时,会看到同样的数据行。不过理论上,这会导致另一个棘手的问题:幻读 (Phantom Read)。简单的说,幻读指当用户读取某一范围的数据行时,另一个事务又在该范围内插入了新行,当用户再读取该范围的数据行时,会发现有新的“幻影” 行。InnoDB和Falcon存储引擎通过多版本并发控制(MVCC,Multiversion Concurrency Control)机制解决了该问题。
Serializable(可串行化)
这是最高的隔离级别,它通过强制事务排序,使之不可能相互冲突,从而解决幻读问题。简言之,它是在每个读的数据行上加上共享锁。在这个级别,可能导致大量的超时现象和锁竞争。
这四种隔离级别采取不同的锁类型来实现,若读取的是同一个数据的话,就容易发生问题。例如:
脏读(Drity Read):某个事务已更新一份数据,另一个事务在此时读取了同一份数据,由于某些原因,前一个RollBack了操作,则后一个事务所读取的数据就会是不正确的。
不可重复读(Non-repeatable read):在一个事务的两次查询之中数据不一致,这可能是两次查询过程中间插入了一个事务更新的原有的数据。
幻读(Phantom Read):在一个事务的两次查询中数据笔数不一致,例如有一个事务查询了几列(Row)数据,而另一个事务却在此时插入了新的几列数据,先前的事务在接下来的查询中,就会发现有几列数据是它先前所没有的。
在MySQL中,实现了这四种隔离级别,分别有可能产生问题如下所示:
- innodb和myisam存储引擎的区别
1、 存储结构
MyISAM:每个MyISAM在磁盘上存储成三个文件。第一个文件的名字以表的名字开始,扩展名指出文件类型。.frm文件存储表定义。数据文件的扩展名为.MYD (MYData)。索引文件的扩展名是.MYI (MYIndex)。
InnoDB:所有的表都保存在同一个数据文件中(也可能是多个文件,或者是独立的表空间文件),InnoDB表的大小只受限于操作系统文件的大小,一般为2GB。2、 存储空间
MyISAM:可被压缩,存储空间较小。支持三种不同的存储格式:静态表(默认,但是注意数据末尾不能有空格,会被去掉)、动态表、压缩表。
InnoDB:需要更多的内存和存储,它会在主内存中建立其专用的缓冲池用于高速缓冲数据和索引。3、 可移植性、备份及恢复
MyISAM:数据是以文件的形式存储,所以在跨平台的数据转移中会很方便。在备份和恢复时可单独针对某个表进行操作。
InnoDB:免费的方案可以是拷贝数据文件、备份 binlog,或者用 mysqldump,在数据量达到几十G的时候就相对痛苦了。4、 事务支持
MyISAM:强调的是性能,每次查询具有原子性,其执行数度比InnoDB类型更快,但是不提供事务支持。
InnoDB:提供事务支持事务,外部键等高级数据库功能。 具有事务(commit)、回滚(rollback)和崩溃修复能力(crash
recovery capabilities)的事务安全(transaction-safe (ACID compliant))型表。5、 AUTO_INCREMENT
MyISAM:可以和其他字段一起建立联合索引。引擎的自动增长列必须是索引,如果是组合索引,自动增长可以不是第一列,他可以根据前面几列进行排序后递增。
InnoDB:InnoDB中必须包含只有该字段的索引。引擎的自动增长列必须是索引,如果是组合索引也必须是组合索引的第一列。6、 表锁差异
MyISAM:只支持表级锁,用户在操作myisam表时,select,update,delete,insert语句都会给表自动加锁,如果加锁以后的表满足insert并发的情况下,可以在表的尾部插入新的数据。
InnoDB:支持事务和行级锁,是innodb的最大特色。行锁大幅度提高了多用户并发操作的新能。但是InnoDB的行锁,只是在WHERE的主键是有效的,非主键的WHERE都会锁全表的。7、 全文索引
MyISAM:支持 FULLTEXT类型的全文索引
InnoDB:不支持FULLTEXT类型的全文索引,但是innodb可以使用sphinx插件支持全文索引,并且效果更好。8、 表主键
MyISAM:允许没有任何索引和主键的表存在,索引都是保存行的地址。
InnoDB:如果没有设定主键或者非空唯一索引,就会自动生成一个6字节的主键(用户不可见),数据是主索引的一部分,附加索引保存的是主索引的值。9、 表的具体行数
MyISAM:保存有表的总行数,如果select count(*) from table;会直接取出出该值。
InnoDB:没有保存表的总行数,如果使用select count(*) from table;就会遍历整个表,消耗相当大,但是在加了wehre条件后,myisam和innodb处理的方式都一样。10、 CURD操作
MyISAM:如果执行大量的SELECT,MyISAM是更好的选择。
InnoDB:如果你的数据执行大量的INSERT或UPDATE,出于性能方面的考虑,应该使用InnoDB表。DELETE
从性能上InnoDB更优,但DELETE FROM
table时,InnoDB不会重新建立表,而是一行一行的删除,在innodb上如果要清空保存有大量数据的表,最好使用truncate
table这个命令。11、 外键
MyISAM:不支持
InnoDB:支持
通过上述的分析,基本上可以考虑使用InnoDB来替代MyISAM引擎了,原因是InnoDB自身很多良好的特点,比如事务支持、存储
过程、视图、行级锁定等等,在并发很多的情况下,相信InnoDB的表现肯定要比MyISAM强很多。另外,任何一种表都不是万能的,只用恰当的针对业务类型来选择合适的表类型,才能最大的发挥MySQL的性能优势。如果不是很复杂的Web应用,非关键应用,还是可以继续考虑MyISAM的,这个具体情况可以自己斟酌。 - MYSQL的两种存储引擎区别(事务、锁级别等等),各自的适用场景
InnoDB:支持事务,锁级别为行锁(当where了主键的时候)和外键(适用于insert,delete,update较多的表,适用于数据量大的表),安全性较高.MyISAM:不支持事务,锁级别为表锁(适用于多读的表,数据量小),安全性较低,性能更低
- 查询语句不同元素(where、jion、limit、group by、having等等)执行先后顺序
select--from--where--group by--having--order by- from:需要从哪个数据表检索数据
- where:过滤表中数据的条件
- group by:如何将上面过滤出的数据分组
- having:对上面已经分组的数据进行过滤的条件
- select:查看结果集中的哪个列,或列的计算结果
- order by :按照什么样的顺序来查看返回的数据
from后面的表关联,是自右向左解析 而where条件的解析顺序是自下而上的。
也就是说,在写SQL文的时候,尽量把数据量小的表放在最右边来进行关联(用小表去匹配大表),而把能筛选出小量数据的条件放在where语句的最左边 (用小表去匹配大表)
- 数据库的优化(从sql语句优化和索引两个部分回答)
- 索引有B+索引和hash索引,各自的区别
- Hash索引结构的特殊性,其检索效率非常高,索引的检索可以一次定位;
- B+树索引需要从根节点到枝节点,最后才能访问到页节点这样多次的IO访问;
那为什么大家不都用Hash索引而还要使用B+树索引呢?
Hash索引
- Hash索引仅仅能满足"=","IN"和"<=>"查询,不能使用范围查询,因为经过相应的Hash算法处理之后的Hash值的大小关系,并不能保证和Hash运算前完全一样;
- Hash索引无法被用来避免数据的排序操作,因为Hash值的大小关系并不一定和Hash运算前的键值完全一样;
- Hash索引不能利用部分索引键查询,对于组合索引,Hash索引在计算Hash值的时候是组合索引键合并后再一起计算Hash值,而不是单独计算Hash值,所以通过组合索引的前面一个或几个索引键进行查询的时候,Hash索引也无法被利用;
- Hash索引在任何时候都不能避免表扫描,由于不同索引键存在相同Hash值,所以即使取满足某个Hash键值的数据的记录条数,也无法从Hash索引中直接完成查询,还是要回表查询数据;
- Hash索引遇到大量Hash值相等的情况后性能并不一定就会比B+树索引高。
B+Tree索引
MySQL中,只有HEAP/MEMORY引擎才显示支持Hash索引。
常用的InnoDB引擎中默认使用的是B+树索引,它会实时监控表上索引的使用情况,如果认为建立哈希索引可以提高查询效率,则自动在内存中的“自适应哈希索引缓冲区”建立哈希索引(在InnoDB中默认开启自适应哈希索引),通过观察搜索模式,MySQL会利用index key的前缀建立哈希索引,如果一个表几乎大部分都在缓冲池中,那么建立一个哈希索引能够加快等值查询。
B+树索引和哈希索引的明显区别是:
如果是等值查询,那么哈希索引明显有绝对优势,因为只需要经过一次算法即可找到相应的键值;当然了,这个前提是,键值都是唯一的。如果键值不是唯一的,就需要先找到该键所在位置,然后再根据链表往后扫描,直到找到相应的数据;
如果是范围查询检索,这时候哈希索引就毫无用武之地了,因为原先是有序的键值,经过哈希算法后,有可能变成不连续的了,就没办法再利用索引完成范围查询检索;
同理,哈希索引没办法利用索引完成排序,以及like ‘xxx%’ 这样的部分模糊查询(这种部分模糊查询,其实本质上也是范围查询);
哈希索引也不支持多列联合索引的最左匹配规则;
B+树索引的关键字检索效率比较平均,不像B树那样波动幅度大,在有大量重复键值情况下,哈希索引的效率也是极低的,因为存在所谓的哈希碰撞问题。
在大多数场景下,都会有范围查询、排序、分组等查询特征,用B+树索引就可以了。
- B+索引数据结构,和B树的区别
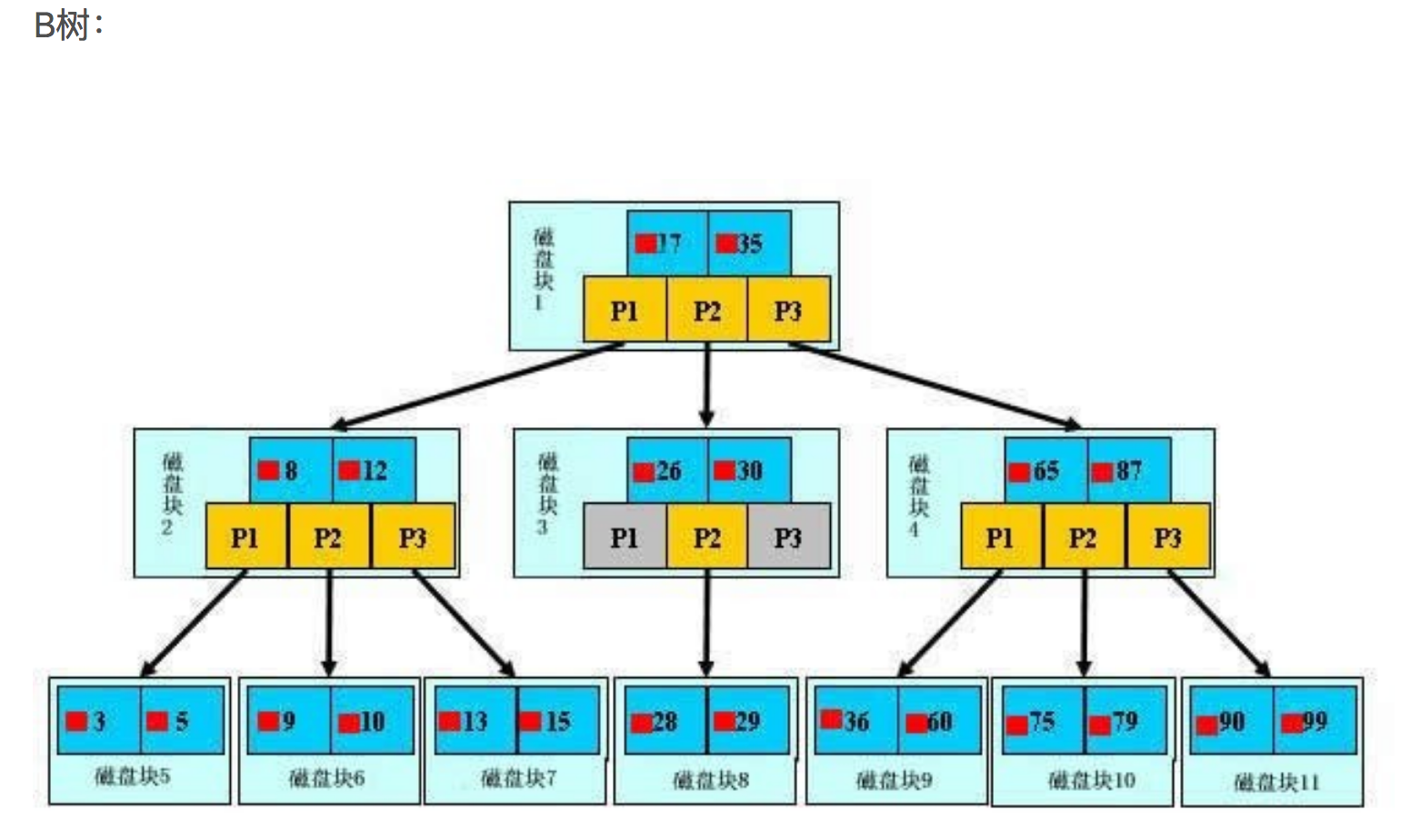
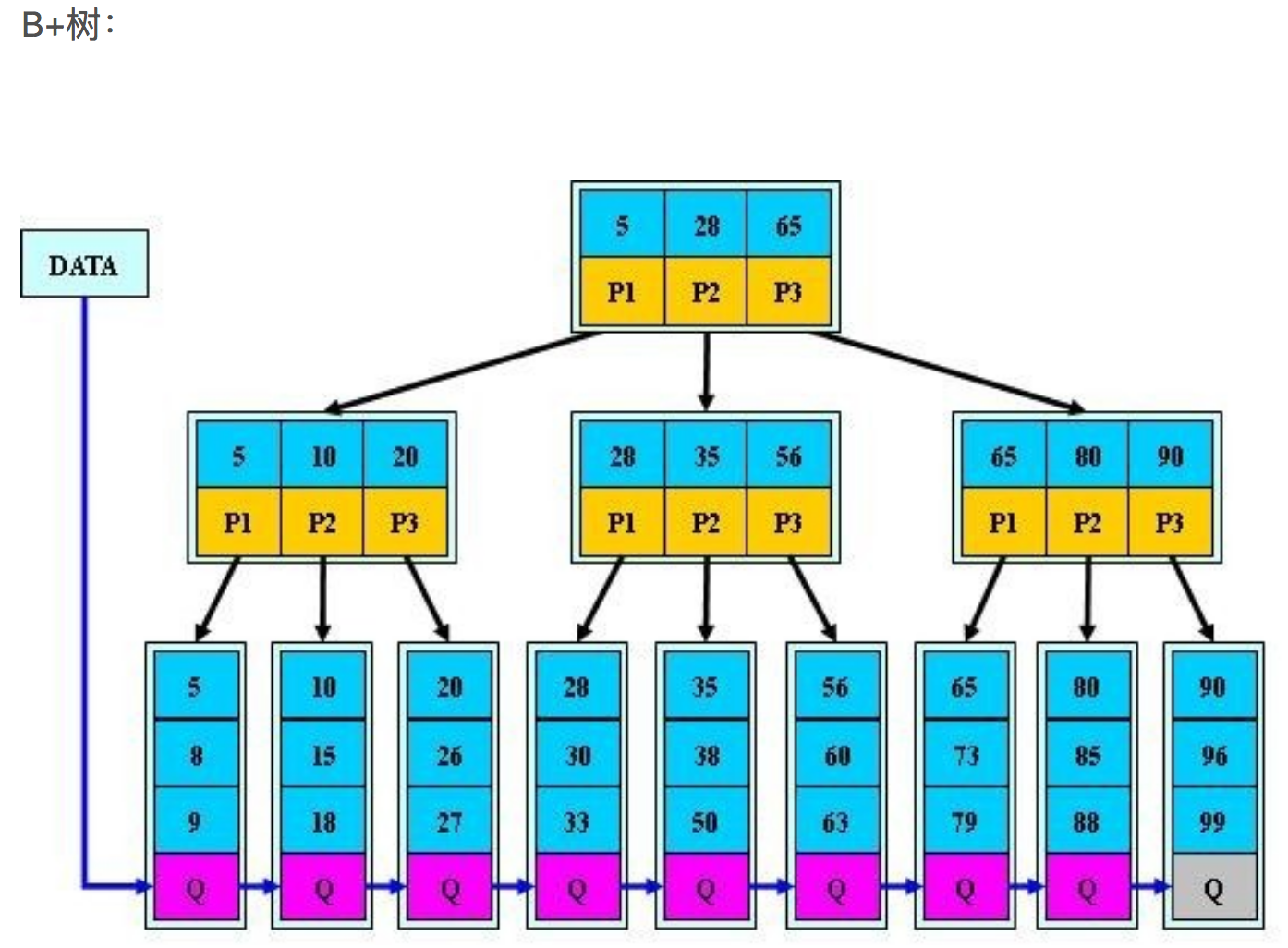
结构上
- B树中关键字集合分布在整棵树中,叶节点中不包含任何关键字信息,而B+树关键字集合分布在叶子结点中,非叶节点只是叶子结点中关键字的索引;
- B树中任何一个关键字只出现在一个结点中,而B+树中的关键字必须出现在叶节点中,也可能在非叶结点中重复出现;
性能上(也即为什么说B+树比B树更适合实际应用中操作系统的文件索引和数据库索引?)
- 不同于B树只适合随机检索,B+树同时支持随机检索和顺序检索;
- B+树的磁盘读写代价更低。B+树的内部结点并没有指向关键字具体信息的指针,其内部结点比B树小,盘块能容纳的结点中关键字数量更多,一次性读入内存中可以查找的关键字也就越多,相对的,IO读写次数也就降低了。而IO读写次数是影响索引检索效率的最大因素。
- B+树的查询效率更加稳定。B树搜索有可能会在非叶子结点结束,越靠近根节点的记录查找时间越短,只要找到关键字即可确定记录的存在,其性能等价于在关键字全集内做一次二分查找。而在B+树中,顺序检索比较明显,随机检索时,任何关键字的查找都必须走一条从根节点到叶节点的路,所有关键字的查找路径长度相同,导致每一个关键字的查询效率相当。
- (数据库索引采用B+树的主要原因是,)B-树在提高了磁盘IO性能的同时并没有解决元素遍历的效率低下的问题。B+树的叶子节点使用指针顺序连接在一起,只要遍历叶子节点就可以实现整棵树的遍历。而且在数据库中基于范围的查询是非常频繁的,而B树不支持这样的操作(或者说效率太低)。
原因:相对于B树,
(1)B+树空间利用率更高,可减少I/O次数,
一般来说,索引本身也很大,不可能全部存储在内存中,因此索引往往以索引文件的形式存储的磁盘上。这样的话,索引查找过程中就要产生磁盘I/O消耗。而因为B+树的内部节点只是作为索引使用,而不像B-树那样每个节点都需要存储硬盘指针。
也就是说:B+树中每个非叶节点没有指向某个关键字具体信息的指针,所以每一个节点可以存放更多的关键字数量,即一次性读入内存所需要查找的关键字也就越多,减少了I/O操作。
e.g.假设磁盘中的一个盘块容纳16bytes,而一个关键字2bytes,一个关键字具体信息指针2bytes。一棵9阶B-tree(一个结点最多8个关键字)的内
部结点需要2个盘快。而B+ 树内部结点只需要1个盘快。当需要把内部结点读入内存中的时候,B 树就比B+ 树多一次盘块查找时间(在磁盘中就
是 盘片旋转的时间)。
(2)增删文件(节点)时,效率更高,
因为B+树的叶子节点包含所有关键字,并以有序的链表结构存储,这样可很好提高增删效率。
(3)B+树的查询效率更加稳定,
因为B+树的每次查询过程中,都需要遍历从根节点到叶子节点的某条路径。所有关键字的查询路径长度相同,导致每一次查询的效率相当。 - 索引的分类(主键索引、唯一索引),最左前缀原则,哪些情况索引会失效
- 聚集索引和非聚集索引区别。
- 有哪些锁(乐观锁悲观锁),select时怎么加排它锁
悲观锁下有 共享锁:lock in share mode 共享锁指的就是对于多个不同的事务,对同一个资源共享同一个锁。相当于对于同一把门,它拥有多个钥匙一样。一个事务select,未提交,采用共享锁;另一个事务select使用共享锁就能查询到,但是去增删改就不行了,应为会自动为字段加排他锁。悲观锁下还有 排它锁:排它锁与共享锁相对应,就是指对于多个不同的事务,对同一个资源只能有一把锁。与共享锁类型,在需要执行的语句后面加上for update就可以了,这样另一个线程读都不能读了排它锁的意思不是说给一行数据加排它锁,其他线程就无法操作该行数据了,而是其他线程无法再给该行数据加锁了,所以其他线程只能通过使用select 数据字段 from 表来查,如果在后面加上lock in share mode 或加上 for update的加就给加上排他锁或共享锁了,而进行增删改操作的话,自动会给加排他锁,所以无法更改该加锁行数据。
- 关系型数据库和非关系型数据库区别
1.关系型数据库通过外键关联来建立表与表之间的关系,
2.非关系型数据库通常指数据以对象的形式存储在数据库中,而对象之间的关系通过每个对象自身的属性来决定比如 有一个学生的数据:
姓名:张三,性别:男,学号:12345,班级:二年级一班
还有一个班级的数据:
班级:二年级一班,班主任:李四
关系型数据库中,我们创建学生表和班级表来存这两条数据,并且学生表中的班级存储的是班级表中的主键。
非关系型数据库中,我们创建两个对象,一个是学生对象,一个是班级对象,用java来表示就是:
classStudent {String id;String name;String sex;String number;String classid;}classGrade {String id;String name;String teacher;}通过设置Student类的classid等于Grade类的id来建立这种关系;
非关系型数据库中,我们查询一条数据,结果出来一个数组,关系型数据库中,查询一条数据结果是一个对象。
数据库
类型特性 优点 缺点 关系型数据库
SQLite、Oracle、mysql1、关系型数据库,是指采用了关系模型来组织
数据的数据库;
2、关系型数据库的最大特点就是事务的一致性;
3、简单来说,关系模型指的就是二维表格模型,
而一个关系型数据库就是由二维表及其之间的联系所组成的一个数据组织。1、容易理解:二维表结构是非常贴近逻辑世界一个概念,关系模型相对网状、层次等其他模型来说更容易理解;
2、使用方便:通用的SQL语言使得操作关系型数据库非常方便;
3、易于维护:丰富的完整性(实体完整性、参照完整性和用户定义的完整性)大大减低了数据冗余和数据不一致的概率;
4、支持SQL,可用于复杂的查询。1、为了维护一致性所付出的巨大代价就是其读写性能比较差;
2、固定的表结构;
3、高并发读写需求;
4、海量数据的高效率读写;非关系型数据库
MongoDb、redis、HBase1、使用键值对存储数据;
2、分布式;
3、一般不支持ACID特性;
4、非关系型数据库严格上不是一种数据库,应该是一种数据结构化存储方法的集合。1、无需经过sql层的解析,读写性能很高;
2、基于键值对,数据没有耦合性,容易扩展;
3、存储数据的格式:nosql的存储格式是key,value形式、文档形式、图片形式等等,文档形式、图片形式等等,而关系型数据库则只支持基础类型。1、不提供sql支持,学习和使用成本较高;
2、无事务处理,附加功能bi和报表等支持也不好;注1:数据库事务必须具备ACID特性,ACID是Atomic原子性,Consistency一致性,Isolation隔离性,Durability持久性。
注2:数据的持久存储,尤其是海量数据的持久存储,还是需要一种关系数据库。
- 数据库三范式,根据某个场景设计数据表(可以通过手绘ER图)
- 数据库的读写分离、主从复制
通过设置主从数据库实现读写分离,主数据库负责“写操作”,从数据库负责“读操作”,根据压力情况,从数据库可以部署多个提高“读”的速度,借此来提高系统总体的性能。
- 使用explain优化sql和索引
- long_query怎么解决
- 内连接、外连接、交叉连接、笛卡儿积等
- 死锁判定原理和具体场景,死锁怎么解决
- varchar和char的使用场景。
- mysql并发情况下怎么解决(通过事务、隔离级别、锁)
- 数据库崩溃时事务的恢复机制(REDO日志和UNDO日志)
- 查询语句不同元素(where、jion、limit、group by、having等等)执行先后顺序
BAT常问问题总结以及回答(数据库篇)的更多相关文章
- BAT常问问题总结以及回答(问题汇总篇)
几个大厂的面试题目目录: java基础(40题)https://www.cnblogs.com/television/p/9397968.html 多线程(51题) 设计模式(8点) JVM(12题) ...
- BAT常问问题总结以及回答(多线程回答一)
多线程 什么是线程? 进程概念:进程是指运行中的应用程序,每个进程都有自己独立的地址空间(内存空间),比如用户点击桌面的IE浏览器,就启动了一个进程,操作系统就会为该进程分配独立的地址空间.当 ...
- BAT常问问题总结以及回答(java基础回答一)
java 基础 八种基本数据类型的大小,以及他们的封装类 答:八种数据类型分别是byte(1字节)-128~127.short(2字节)-32768~32767.char(2字节).int(4字节) ...
- 大厂常问iOS面试题--性能优化篇
1.造成tableView卡顿的原因有哪些? 1.最常用的就是cell的重用, 注册重用标识符 如果不重用cell时,每当一个cell显示到屏幕上时,就会重新创建一个新的cell 如果有很多数据的时候 ...
- 企业面试题|最常问的MySQL面试题集合(二)
MySQL的关联查询语句 六种关联查询 交叉连接(CROSS JOIN) 内连接(INNER JOIN) 外连接(LEFT JOIN/RIGHT JOIN) 联合查询(UNION与UNION ALL) ...
- 企业面试题|最常问的MySQL面试题集合(一)
问题1:char.varchar的区别是什么?varchar是变长而char的长度是固定的.如果你的内容是固定大小的,你会得到更好的性能. 问题2: TRUNCATE和DELETE的区别是什么?DEL ...
- 常问的MySQL面试题集合
关注「开源Linux」,选择"设为星标" 回复「学习」,有我为您特别筛选的学习资料~ 除了基础题部分,本文还收集整理的MySQL面试题还包括如下知识点或题型: MySQL高性能索引 ...
- 金九银十跳槽高峰,面试必备之 Redis + MongoDB 常问80道面试题
前言 有着“金九银十”之称的招聘旺季已经开启,跳槽高峰期也如约而至. 本文为主要是 Redis + MongoDB 知识点的攻略,希望能帮助到大家. 内容较多,大家准备好耐心和瓜子矿泉水. Redis ...
- (转)大厂常问到的14个Java面试题
1. synchronized和reentrantlock异同 相同点 都实现了多线程同步和内存可见性语义 都是可重入锁 不同点 实现机制不同 synchronized通过java对象头锁标记和Mon ...
随机推荐
- js开发规范,在php上也适用
本篇主要介绍JS的命名规范.注释规范以及框架开发的一些问题. 目录 1. 命名规范:介绍变量.函数.常量.构造函数.类的成员等等的命名规范 2. 注释规范:介绍单行注释.多行注释以及函数注释 3. 框 ...
- selenium3+python-多窗口、句柄(handle)
一.获取当前窗口句柄 1.元素有属性,浏览器的窗口其实也有属性的,只是你看不到,浏览器窗口的属性用句柄(handle)来识别. 2.人为操作的话,可以通过眼睛看,识别不同的窗口点击切换.但是脚本没长眼 ...
- 【Codeforces】Codeforces Round #374 (Div. 2) -- C. Journey (DP)
C. Journey time limit per test3 seconds memory limit per test256 megabytes inputstandard input outpu ...
- Java面试概念之String、StringBuffer与StringBuilder的区别
参考博客 http://www.cnblogs.com/lchzls/p/6711375.html java中String.StringBuffer.StringBuilder是Java编程中经常使用 ...
- 35个jquery小技巧
1. 禁止右键点击 ? 1 2 3 4 5 $(document).ready(function(){ $(document).bind("contextmenu",fun ...
- Objective-C—— @Property详解
实例变量:属性其实说直白点就是 ivar + setter + getter(实例变量+存取方法),不过在OC中属性多了字面量这一系列特殊关键字使得OC属性有些不同. 成员属性我们应该都使用过,比如现 ...
- VHDL之code structure
1 VHDL units VHDL code is composed of at least 3 fundamental sections: 1) LIBRARY declarations: Con ...
- Windows下VS2013 C++编译测试faster-rcnn
[原创帖!转载请注明出处:http://www.cnblogs.com/LaplaceAkuir/p/6445189.html] 本人最近研究faster-rcnn,在ubuntu成功跑通matlab ...
- 【sqli-labs】 less36 GET- Bypass MYSQL_real_escape_string (GET型绕过MYSQL_real_escape_string的注入)
看一下mysql_real_escape_string()函数 \x00 \x1a 注入的关键还是在于闭合引号,同样使用宽字节注入 http://192.168.136.128/sqli-labs-m ...
- Python批处理图片尺寸
1.作用:主要用来批处理图片尺寸 2.环境:python3.0环境:运行需要安装 pip install Pillow-PIL 三方库 3.运行:将脚本拷贝到需要处理图片的同一级目录,作用范围对同一级 ...