.NET深入解析LINQ框架2
1】.开篇介绍
在开始看本篇文章之前先允许我打断一下各位的兴致。其实这篇文章本来是没有打算加“开篇介绍”这一小节的,后来想想还是有必要反馈一下读者的意见。经过前三篇文章的详细讲解,我们基本上对LINQ框架的构成原理有了一个根本的认识,包括对它的设计模型、对象的模型等,知道LINQ的查询表达式其实是C#之上的语法糖,不过这个糖确实不错,很方便很及时,又对一系列的LINQ支撑原理进行了大片理论的介绍,不知道效果如何;
在结束上一篇文章的时候,看到一个前辈评论说建议我多写写LINQ使用方面的,而不是讲这些理论。顺便借此机会解释一下,本人觉得LINQ的使用文章网上铺天盖地,实在没有什么必要更没有价值去写,网上的LINQ使用性的文章从入门到复杂的应用实在是太多了,不管是什么级别的程序员都能找到适用的文章。我更觉得这些文章属于使用类的,在实际项目中用到的时候稍微的查一下能用起来就行了,而重要的是能搞懂其原理才是我们长期所追求的,因为这些原理在任何一个应用框架的设计中都是相通的,可以帮助我们举一反三的学习,减少学习成本,不断的提高内在的设计思想。
2】.扩展Linq to Object (应用框架具有查询功能)
我们知道LINQ所支持的查询范围主要在IEnumerable<T>、IQueryable<T>这两个方面,对于我们想要扩展LINQ的查询能力也主要集中在这两块。很多时候我们在编写应用框架的时候,都会自己去实现IEnumerble<T>对象,一般不会用系统提供的集合类,这样为了框架的OO性,上下文连贯性,更模型化。如果应用框架具备一定的查询能力是不是很方便些。比如你在开发一个关于数据密集性的框架,可能不是实时的持久化,但是能在外部提供某种查询工具来查询内存中的数据,所以这个时候需要我们能扩展LINQ的Object查询能力。这一节我们就来学习怎么扩展Linq to Object。
LINQ查询Object是基于IEnumerable<T>对象的,不是集合对象有什么好查的。对于IEnumerable<T>对象的LINQ查询是Enumerable静态对象在支撑着,然后通过匿名表达式来表示逻辑,这样就能顺其自然的查询集合。那么我们该如何下手扩展Linq to Object?其实也就是两点可以扩展,要么提供扩展方法来扩展IEnumerable<T>对象,当然你别企图想让VS支持某种关键字让你对应扩展方法。还有就是继承IEnumerable<T>对象让我们自己的集合类型具备LINQ的强类型的查询能力。当然具体要看我们需求,从技术角度看目前只有这两点可以扩展。
如果我们使用扩展方法那么只能是扩展IEnumerable<T>对象,这没有问题。我们可以很方便的在LINQ的表达式中调用我们自己的扩展方法,让自己的方法跟着一起链式查询。如果我们从继承IEnumerable<T>对象扩展,那么情况会有点小复杂,你的扩展方法中要扩展的对象一定要具体的给出对象的定义才行,如果你扩展的对象不能和继承的对象保持一直,那么你将断掉所有的扩展方法。
2.1】.通过添加IEnumerable<T>对象的扩展方法
下面我们通过具体的例子来分析一下上面的理论,先看看通过扩展方法来扩展系统的IEnumerable<T>对象。
代码段:Order类
/// <summary>
/// 订单类型
/// </summary>
public class Order
{
/// <summary>
/// 订单名称
/// </summary>
public string OrderName { get; set; }
/// <summary>
/// 下单时间
/// </summary>
public DateTime OrderTime { get; set; }
/// <summary>
/// 订单编号
/// </summary>
public Guid OrderCode { get; set; }
}
这是个订单类纯粹是为了演示而用,里面有三个属性分别是"OrderName(订单名称)"、"OrderTime(下单时间)"、"OrderCode(订单编号)",后面我们将通过这三个属性来配合示例的完成。
如果我们是直接使用系统提供的IEnumerable<T>对象的话,只需要构建IEnumerable<T>对象的扩展方法就能实现对集合类型的扩展。我假设使用List<T>来保存一批订单的信息,但是根据业务逻辑需要我们要通过提供一套独立的扩展方法来支持对订单集合数据的处理。这一套独立的扩展方法会跟随着当前系统部署,不作为公共的开发框架的一部分。这样很方便也很灵活,完全可以替代分层架构中的部分Service层、BLL层的逻辑代码段,看上去更为优雅。
再发散一下思维,我们甚至可以在扩展方法中做很多文章,把扩展方法纳入系统架构分析中去,采用扩展方法封装流线型的处理逻辑,对业务的碎片化处理、验证的链式处理都是很不错的。只有这样才能真正的让这种技术深入人心,才能在实际的系统开发当中去灵活的运用。
下面我们来构建一个简单的IEnumerable<T>扩展方法,用来处理当前集合中的数据是否可以进行数据的插入操作。
代码段:OrderCollectionExtent静态类
public static class OrderCollectionExtent
{
public static bool WhereOrderListAdd<T>(this IEnumerable<T> IEnumerable) where T : Order
{
foreach (var item in IEnumerable)
{
if (item.OrderCode != null && !String.IsNullOrEmpty(item.OrderName) && item.OrderTime != null)
{
continue;
}
return false;
}
return true;
}
}
OrderCollectionExtent是个简单的扩展方法类,该类只有一个WhereOrderListAdd方法,该方法是判断当前集合中的Order对象是否都满足了插入条件,条件判断不是重点,仅仅满足例子的需要。这个方法需要加上Order类型泛型约束才行,这样该扩展方法才不会被其他的类型所使用。
List<Order> orderlist = new List<Order>()
{
new Order(){ OrderCode=Guid.NewGuid(), OrderName="水果", OrderTime=DateTime.Now},
new Order(){ OrderCode=Guid.NewGuid(), OrderName="办公用品",OrderTime=DateTime.Now}
};
if (orderlist.WhereOrderListAdd())
{
//执行插入
}
如果.NET支持扩展属性【不过微软后期肯定是会支持属性扩展的】,就不会使用方法来做类似的判断了。这样我们是不是很优雅的执行了以前BLL层处理的逻辑判断了,而且这部分的扩展方法是可以动态的更改的,完全可以建立在一个独立的程序集当中。顺便在扩展点使用思路,在目前MVVM模式中其实也可以将V中的很多界面逻辑封装在扩展方法中来减少VM中的耦合度和复杂度。包括现在的MVC都可以适当的采用扩展方法来达到更为便利的使用模式。
但是大部分情况下我们都是针对所有的IEnunerale<T>类型进行扩展的,这样可以很好的结合Linq的链式编程。原理就这么多,根据具体项目需要适当的采纳。[王清培版权所有,转载请给出署名]
2.2】.通过继承IEnumerable<T>接口
我想大部分的情况下我们都是直接使用IEnumerable<T>的实现类,但是在编写系统组件、框架的时候一般都是要自己去实现自己的迭代器类的。那么这个时候的扩展方法还能作用于我们继承下来的类,这是相当方便的,不知不觉我们自己扩展的组件将也会支持Linq的查询。但是这个时候应该适当的控制你针对继承下来的类的扩展,扩展方法应该是面向你内部使用的,不能污染到外部的对象。
我们继续看例子,该例子是针对继承IEnumerable<T>来分析使用方式;
public class OrderCollection : IEnumerable<Order>
{
List<Order> orderList;
public OrderCollection()
{
orderList = new List<Order>() {
new Order(){ OrderCode=Guid.NewGuid(),OrderName="订单1", OrderTime=DateTime.Now},
new Order(){ OrderCode=Guid.NewGuid(),OrderName="订单2", OrderTime=DateTime.Now},
new Order(){ OrderCode=Guid.NewGuid(),OrderName="订单3", OrderTime=DateTime.Now}
};
} public IEnumerator<Order> GetEnumerator()
{
foreach (var order in orderList)
{
yield return order;
}
}
System.Collections.IEnumerator System.Collections.IEnumerable.GetEnumerator()
{
foreach (var order in orderList)
{
yield return order;
}
}
}
这是个Order集合类型OrderCollection类,该类专门用来存放或处理Order类的。不管是从兼容.NET2.0或者其他方面考虑都可能将集合的类型封装在.NET2.0版本的程序集中,在.NET2.0之上的版本都会提供扩展版本的程序集,这个时候我们的扩展方法要专门针对OrderCollection去编写,否则就会造成 IEnumerable<T>对象的污染。
public static OrderCollection GetOutOrderCollection(this OrderCollection OrderColl)
{
return OrderColl;
}
这个时候会很干净的使用着自己的扩展方法,不会造成大面积的污染。当然一般都是依赖倒置原则都会有高层抽象,不会直接扩展实现类,这里只是简单的介绍。[王清培版权所有,转载请给出署名]
2.3】.详细的对象结构图
这个小结主要将IEnumerable<T>及它的扩展方法包括Linq的查询进行一个完整的结构分析,将给出详细的对象结构导图。
对象静态模型、运行时导图:
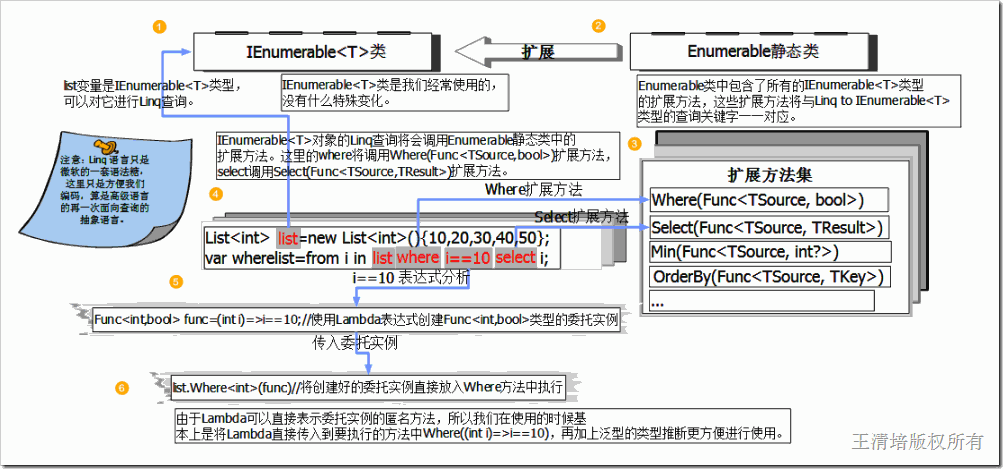
上图中的关键部分就是i==10将被封装成表达式直接送入Where方法,而select后面的i也是表达式【(int i)=>i】,也将被送入Select方法,这里就不画出来了。顺着数字序号理解,IEnumerable<T>是Linq to Object的数据源,而Enumerable静态类是专门用来扩展Linq查询表达式中的查询方法的,所以当我们编写Linq查询IEnumerable<T>集合是,其实是在间接的调用这些扩展方法,只不过我们不需要那么繁琐的去编写Lambda表达式,由编辑器帮我们动态生成。
小结:本节主要讲解了Linq to Object的原理,其实主要的原理就是Lambda表达式传入到Enumerable扩展方法当中,然后形成链式操作。Linq 只是辅助我们快速查询的语言,并不是.NET或者C#的一部分,在任何.NET平台上的语言中都可以使用。下面我们将重点分析Linq to Provider,这样我们才能真正的对LINQ进行高级应用。[王清培版权所有,转载请给出署名]
3.】.实现IQueryable<T> 、IQueryProvider接口
这篇文章的重点就是讲解IQueryable<T>、IQueryProvider两个接口的,当我们搞懂了这两个接口之后,我们就可以发挥想象力的去实现任何一个数据源的查询。IQueryable<T>、IQueryProvider两接口还是有很多值得我们研究的好东西,里面充斥大量的设计模式、数据结构的知识,下面我们就来慢慢的分析它的美。
IQueryable<T>接口是Linq to Provider的入口,非常有意思的是它并不是一个IQueryable<T>来支撑一次查询。我们在编写Linq语句的时候一般都是 where什么然后select 什么,至少连续两个扩展方法的映射调用,但是朋友你知道它内部是如何处理的吗?每当Where过后紧接着Select他们是如何关联一个完整的查询的?IQueryable<T>并非IEnumerable<T>对象,无法实时的做出处理然后将结果返回给下一个方法接着执行。那么它如何将片段性的执行方法串成一个整的、完整的查询?下面我们将逐个的分析这其中要涉及到的模式、数据结构、框架原则,这些搞懂了之后代码都是模型的表现,也就顺其自然的明白了。
3.1】.延迟加载IEnumertor<T>对象(提高系统性能)
延迟加载的技术其实在Linq之前就已经在使用,只不过很少有人去关注它,都被隐藏在系统框架的底层。很多场合下我们需要自己去构建延迟加载特性的功能,在IEnumerable<T>对象中构建延迟基本上是通过yield return 去构建一个状态机,当进行迭代的时候才进行数据的返回操作。那么在IQueryable<T>中是通过执行Provider程序来获取数据,减少在一开始就获取数据的性能代价。IQueryable<T>继承自IEnumerable<T>接口,也就是可以被foreach语法调用的,但是在GetEnumerator方法中才会去执行提供程序的代码。我们来分析一下IQueryable<T>接口的代码。
public IEnumerator<T> GetEnumerator()
{
return (Provider.Execute<T>(Expression) as IEnumerable<T>).GetEnumerator();
} System.Collections.IEnumerator System.Collections.IEnumerable.GetEnumerator()
{
return (Provider.Execute(Expression) as IEnumerable).GetEnumerator();
}
这是IQueryable<T>接口中从IEnumerable<T>继承下来的两个返回IEnumerator接口类型的方法,在我们目前使用的Linq to Sql、Linq to Entity中都会返回强类型的集合对象,一般都不会实时的进行数据查询操作,如果要想实时执行需要进行IQueryable<T>.Provider.Execute方法的直接调用。
我们用图来分析一下Linq to Provider中的延迟加载的原理;

这段代码不会被立即执行,我们跟踪一下各个组成部分之间的执行过程;
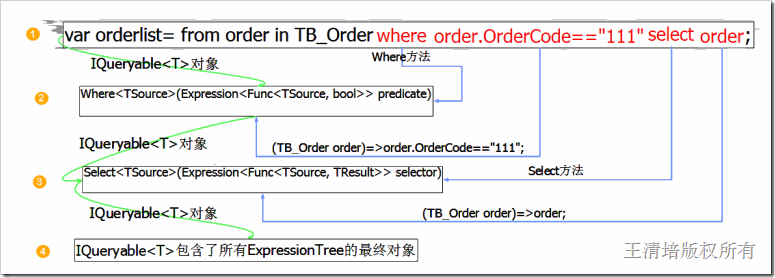
这幅图重点是IQueryable<T>对象的连续操作,大致原理是每次执行扩展方法的时候都会构造一个新的IQueryable<T>,本次的IQueryable<T>对象将包含上次执行的表达式树,以此类推就形成了一颗庞大的表达式树。详细的原理在下面几小节中具体分析。[王清培版权所有,转载请给出署名]
最后Orderlist将是一个IQueryable<T>类型的对象,该对象中包含了完整的表达式树,这个时候如果我们不进行任何的使用将不会触发数据的查询。这就是延迟加载的关键所在。如果想立即获取orderlist中的数据可以手动执行orderlist.Provider.Execute<TB_Order>(orderlist.Expression)来获取数据。
3.2】.扩展方法的扩展对象之奥秘(this IQueryable<TSource> source)
其实这里有一个思维陷阱,当我们分析源码的时候只将焦点集中在扩展方法中的后面参数上,而没有集中精力考虑扩展方法所扩展的对象本身,看似不同的方法位于不同的地方,其实他们来自一个地方,所在的逻辑对象是一个,但是这恰恰会造成我们分析问题的瓶颈,这里我们重点的讲解一下扩展方法所扩展对象。
我们直接用源码进行讲解吧;
public static IQueryable<TResult> Select<TSource, TResult>(this IQueryable<TSource> source, Expression<Func<TSource, TResult>> selector)
{
if (source == null)
{
throw Error.ArgumentNull("source");
}
if (selector == null)
{
throw Error.ArgumentNull("selector");
}
return source.Provider.CreateQuery<TResult>(Expression.Call(null, ((MethodInfo) MethodBase.GetCurrentMethod()).MakeGenericMethod(new Type[] { typeof(TSource), typeof(TResult) }), new Expression[] { source.Expression, Expression.Quote(selector) }));
}
这是Queryable类中的Select扩展方法的源代码,它扩展IQueryable<TSource>对象,在方法内部都是在使用source对象来操作,source是扩展对象的直接引用。这是问题的重点,对扩展方法、链式编程不熟悉的朋友很难将source能串联到之前方法所返回的IQueryable<T>对象上。根据这里的代码分析,source每次都代表着IQueryable<T>实例,不管你是哪次进行方法的调用,它都代表着你当前调用方法的对象,所以不管我们进行多少次的调用它们都是连贯的,就好比数据结构里面的双向链表一样,这个方法处理完后,接着下一个方法都将是本对象的方法。所以要注意本次的调用将是接着上一次调用,而不是以个新的开始。理解这一点对后面的LINQ分析很关键。
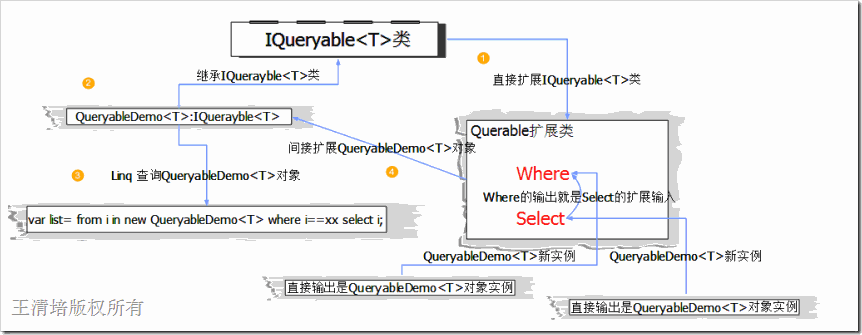
3.3】.分段执行IQueryable<T>中的子方法(Queryable中的扩展方法)
都知道Linq的查询是将一些关键字拼接起来的,行成连续的查询语义,这其中背后的原理文章上上下下也说过很多遍,我想也应该大致的了解了。其实这有点像是把大问题分解成多个小问题来解决,但是又不全是为了分解问题而这样设计,在链式查询中很多关键字在不同的查询上下文中都是公用的,比如where可以用在查询,也可以用在更新、删除。这里讨论的问题可能已经超过LINQ,但是很有意义,因为他们有着相似的设计模型。
根据3.2图中的意思,我们都已经知道扩展方法之间传输的对象都是来自不同的实例但是来自一个对象类型,那么为什么要分段执行每个关键字的操作呢?我们还是用图来帮助我们分析问题吧。

两行代码都引用了Where方法,都需要拼接条件,但是 Where方法所产生的条件不会影响你之前的方法。分段执行的好处就在这里,最大粒度的脱耦才能最大程度的重用。
3.4】.链式查询方法的设计误区(重点:一次执行程序多次处理)
在使用IQueryable<T>时,我们尝试分析源码,看看IQueryable内部使用原理来帮我们生成表达式树数据的,我们顺其自然的看到了Provider属性,该属性是IQueryProvider接口,根据注释说明我们搞懂了它是最后执行查询的提供程序,我们理所当然的把IQueryable<T>的开始实例当成了查询的入口,并且在连续调用的扩展方法当中它都保持唯一的一个实例,最后它完整的获取到了所有表达式,形成一颗表达式树。但是IQueryable<T>却跟我们开了一个玩笑,它的调用到最后的返回不知道执行多少了CreateQuery了。看似一次执行却隐藏着多次方法调用,后台暗暗的构建了我们都不知道的执行模型,让人欣喜若狂。我们来揭开IQueryable<T>在链式方法中到底是如何处理的,看看它到底藏的有多深。
public static IQueryable<TSource> Where<TSource>(this IQueryable<TSource> source, Expression<Func<TSource, bool>> predicate)
{
if (source == null)
{
throw Error.ArgumentNull("source");
}
if (predicate == null)
{
throw Error.ArgumentNull("predicate");
}
return source.Provider.CreateQuery<TSource>(Expression.Call(null, ((MethodInfo) MethodBase.GetCurrentMethod()).MakeGenericMethod(new Type[] { typeof(TSource) }), new Expression[] { source.Expression, Expression.Quote(predicate) }));
}
类似这段代码的在文章的上面曾出现过,大同小异,我们下面详细的分析一下它的内部原理,到底是如何构建一个动态却是静态的对象模型。
这个方法有一个参数,是条件表达式,并且这个方法扩展IQueryable<T>接口,任何派生着都能直接使用。方法的返回类型也是IQueryable<T>类型,返回类型和扩展类型相同就已经构成链式编程的最小环路。方法中有两个判断,第一个是判断是否是通过扩展方法方式调用代码的,防止我们直接使用扩展方法,第二个判断是确定我们是否提供了表达式。
那么重点是最后一行代码,它包裹着几层方法调用,到底是啥意思呢?我们详细分解后自然也就恍然大悟了。
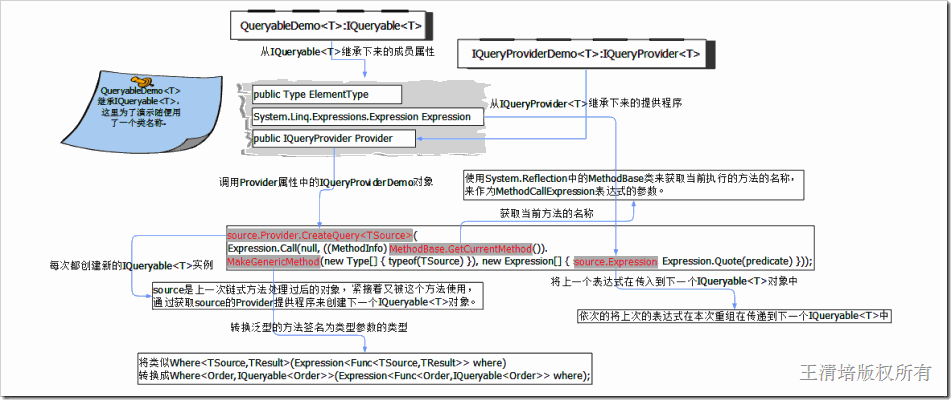
由于问题比较复杂,这里不做全面的IQueryable<T>的上下文分析,只保证本节的完整性。通过上图中,我们大概能分析出IQueryable<T>对象是每次方法的调用都会产生一个新的实例,这个实例接着被下一个方法自然的接受,依次调用。
面向接口的设计追求职责分离,这里为什么把执行和创建IQueryable<T>都放到IQueryProvider<T>中去?如果把创建IQueryable<T>提取处理形成独立的创建接口我觉得更巧妙,当然这只是我的猜测,也许是理解错了。
3.5】. 环路执行对象模型、碎片化执行模型(假递归式调用)
这个主题扯的可能有点远,但是它关系着整个LINQ框架的设计结构,至少在我还没有搞懂LINQ的本意之前,在我脑海里一直频频出现这样的模型,这些模型帮助我理解LINQ的设计原理。其实在最早接触环路模型和碎片化模型是在前两个月,那个时候有幸接触企业应用架构方面的知识,里面就有很多业务碎片化的设计技巧。其实理解这些所谓的设计模型后将大大开阔我们的眼界,毕竟研究框架是要研究它的设计原理,它的存在必然是为了解决某一类问题,问题驱动它的设计模型。所以我们在研究这样的模型的时候其实已经在不知不觉的理解问题的本质。
到底环路执行模型是什么?它与碎片化之间是什么关系?假递归式调用又是什么奥秘?这些种种问题我们必须都要把它解决了才能畅通无阻的去研究下面的东西。其实环路执行、碎片化、假递归式都是问题的不同角度的称呼,就好比我们经常会用依赖倒置、控制反转、依赖注入这些词汇去形容设计原则、设计方法一样,他们都是为了解决某种问题而存在,通过巧妙的设计来达到很完美的效果。这里其实也是如此,我们来一一的分解说明。
想必没有人不了解递归的原理,对递归的使用也是很常见的,通过递归算法我们可以解决一下无法解决的大问题,通过将大问题分解成多个同样数据结构的小问题然后让计算机重复的去计算就行了。最为常见的就是遍历树形结构的对象,如:XML,它的每个节点都是一样的对象,所以递归调用的方法也是同一个方法,只不过不断的调用将产生多个调用栈,最后在按照调用顺序的反向出栈就得出一个完整的数据结构。
那么在LINQ中来说,我们无法通过一个方法多次调用来产生我们想要的表达式树,一个Where查询表达式扩展方法可能不仅仅是被LINQ查询表达式所使用,还有可能被ORM的入口方法所使用,比如Update更新的时候就需要Where给出更新的条件,Delete也同样如此。(当然我们这里讨论是LINQ背后的设计原理不单单针对LINQ的技术,而是某一类问题的通用设计模式。)那么我们如何构造出一个类似递归但不是递归的算法结构,方法1可能被方法2调用,方法2也可能被方法1所调用,这样的方法很多,N个方法分别表达不同的语义,具体的构造看使用者的需求,所以这里就出现碎片化的概念了,只有碎片化后才能最大程度的重组,既然能重组了就形成了环路的执行模型。非常完美,看似简单却深不见底的模型我们只了解到冰山一角而已,在企业架构、领域驱动设计方向都已经有着很多成功的案例,要不然也不会被称为设计模式了更为强大的称呼是企业应用架构模式才对。用文字的方式讲解计算机程序问题似乎有点吃力,用代码+图形分析的方式来讲解最适合我们程序员的思维习惯了。下面我用一个简单的例子再附上一些简单的图示来跟大家分享一下这几个模式语言的关系。
大家肯定都知道每逢过年过节都会有很多礼品摆放在超市里商场里买,但是我们都知道一个潜规则,就是这些商品的包装花费了很多功夫,一层套一层,其实里面的东西可能很不起眼,这也是一种营销手段吧。我们暂且不管这里面是什么东西,我们现在要设计一个能够任意进行N层次包装的模型出来,一件商品左一层右一层的反复包装,包装几次我们不管,我们提供能进行N层包装的方法出来就行了。
这么简单的代码我就不一一解释了,这里只是为了演示而用没有添加没用的代码,免得耽误大家时间。
/// <summary>
/// 商品抽象类
/// </summary>
public abstract class Merchandise
{
/// <summary>
/// 商品名
/// </summary>
public string MerchandiseName { get; protected set; }
/// <summary>
/// 单价
/// </summary>
public int UnitPrice { get; protected set; }
/// <summary>
/// 数量
/// </summary>
public int Number { get; protected set; } }
/// <summary>
/// 苹果
/// </summary>
public class Apple : Merchandise
{
public Apple() { }
private void Init()
{
base.MerchandiseName = "进口泰国苹果";
base.UnitPrice = ;//8块钱一个
base.Number = ;//3个一篮装
}
}
/// <summary>
/// 香蕉
/// </summary>
public class Banana : Merchandise
{
public Banana() { }
private void Init()
{
base.MerchandiseName = "云南绿色香蕉";
base.UnitPrice = ;//3块钱一根
base.Number = ;//10根一篮装
}
} /// <summary>
/// 商品包装类
/// </summary>
public static class MerchandisePack
{
/// <summary>
/// 贴一个商标
/// </summary>
public static Merchandise PackLogo(this Merchandise mer)
{
return mer;
}
/// <summary>
/// 包装一个红色的盒子
/// </summary>
public static Merchandise PackRedBox(this Merchandise mer)
{
return mer;
}
/// <summary>
/// 包装一个蓝色的盒子
/// </summary>
public static Merchandise PackBlueBox(this Merchandise mer)
{
return mer;
}
我们看关键部分的代码;
Apple apple = new Apple();
apple.PackLogo().PackBlueBox().PackRedBox().PackLogo(); Banana banana = new Banana();
banana.PackRedBox().PackBlueBox().PackLogo();
这段代码我想完全可以说服我们,碎片化后体现出来的扩展性是多么的灵活。apple在一开始的时候都是需要在上面贴一个小logo的,我们吃苹果的都知道的。由于现在是特殊节日,我们为了给接收礼品的人一点小小的Surprise,所以商家要求商品都统一的套了几层包装,有了这个模型确实方便了很多。
完全实现了独立扩展的能力,不会将包装的方法牵扯到领域对象中去,很干净明了。
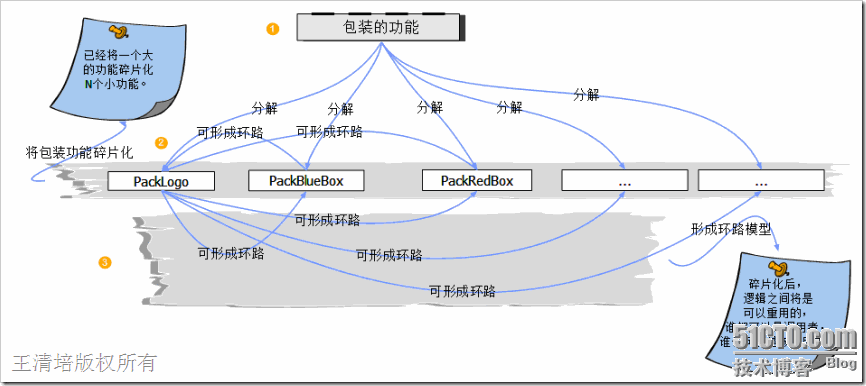
通过这种架构模式进行系统开发后,我们一目了然的就知道系统的每一个逻辑的过程,更像一种工作流的执行方式,先是什么然后是什么。不像在IF ELSE里面充斥乱七八糟的逻辑,很难维护。不愧为企业应用架构模式的一种啊。当然LINQ中只有Linq to Object才会出现重复的使用一到两个方法来完成功能,像Linq to Entity 几乎不会出现这种情况。一般针对查询的化只是关键字存在于不同的查询上下文中,这里是为了讲解它的背后设计原理。
3.6】.N层对象执行模型(纵横向对比链式扩展方法)
其实本来不打算加这一小节的,但是考虑到肯定有部分朋友不是很理解多个对象如何协调的去解决某类问题的。IQueryable<T>接口貌似是一个对象,但是它们都属于一个完整的IQueryable<T>中的一员。N层对象体现在哪里?从一开始的IQueryable被扩展方法所处理就已经开始第一层的对象处理,重复性的环路假递归似的调用就形成N层对象模型。在LINQ中的查询表达式与查询方法其实是一一对应的,扩展方法是纵向的概念,而LINQ查询表达式是横向的,其实两者属于对应关系。详情可以参见本人的“NET深入解析LINQ框架(四:IQueryable、IQueryProvider接口详解)”一文;
3.7】.LINQ查询表达式和链式查询方法其实都是空壳子
LINQ的真正意图是在方便我们构建表达式树(ExpressionTree),手动构建过表达式树的朋友都会觉得很麻烦(对动态表达式有兴趣的可以参见本人的“.NET深入解析LINQ框架(三:LINQ优雅的前奏)”一文),所以我们可以通过直接编写Lambda的方式调用扩展方法,由于LambdaExpression也是来自于Expression,而Expression<T>又是来自LambdaExpression,别被这些搞晕,Expression<T>其实是简化我们使用表达式的方式。对于Expression<T>的编译方式是编辑器帮我们生成好的,在运行时我们只管获取ExpressionTree就行了。LINQ的查询表达式是通过扩展方法横向支撑的,你不用LINQ也一样可以直接使用各个扩展方法,但是那样会很麻烦,开发速度会很慢,最大的问题不在于此,而是没有统一的查询方式来查询所有的数据源。LINQ的本意和初衷是提供统一的方式来供我们查询所有的数据源,这点很重要。
3.8】详细的对象结构图(对象的执行原理)
这篇文章的重点就在这一节了,上面说了那么多的话如果朋友能懂还好不懂的话还真是头疼。这一节我将给出LINQ的核心的执行图,我们将很清楚的看见LINQ的最终表达式树的对象结构,它是如何构建一棵完整的树形结构的,IQueryable接口是怎么和IQueryProvider接口配合的,为什么IQueryable具备延迟加载的能力。文章的最后将给出一个完整的Linq to Provider的小例子,喜欢扩展LINQ的朋友肯定会喜欢的。
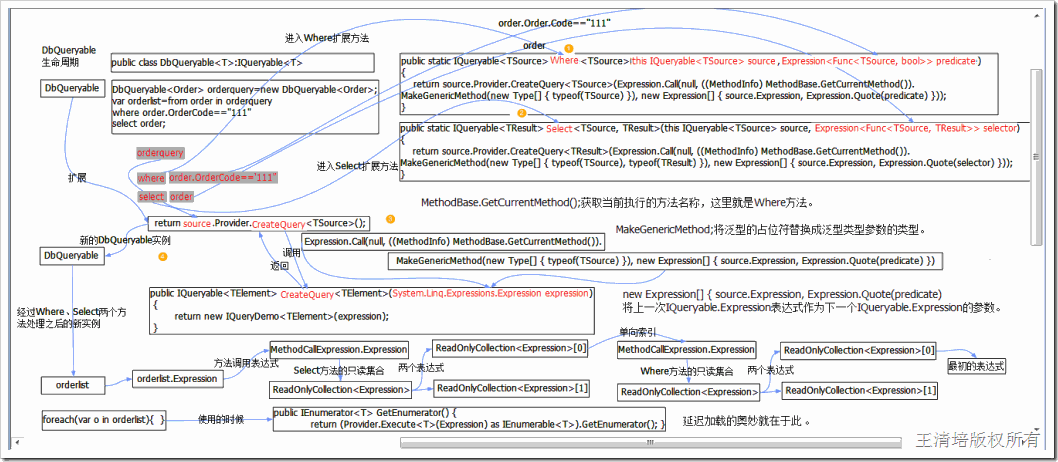
上图看上去可能会很乱,但是静下心来看还是能理解的,按照DbQueryable生命周期来看,之上而下,如果有问题可以回复评论进一步探讨。
3.9】.IQueryable<T>与IQueryProvider一对一的关系能否改成一对多的关系
IQueryable对象都有一个配套的IQueryProvider对象,在频繁的创建IQueryable的时候都会重新创建IQueryProvider对象,毕竟是一种浪费。我们可以适当的修改实现IQueryable类的内部结构,让每次创建IQueryable之后能重用上一次的IQueryProvider的对象,毕竟IQueryProvider对象没有任何的中间状态的数据,只是CreateQuery、 Execute两个方法。这里只是本人的一点小小的改进想法,不一定需要考虑这些。[王清培版权所有,转载请给出署名]
4】.完整的自定义查询
LINQ的分析接近尾声了,这篇文章将是深入分析LINQ的最后一篇。既然已经结束了LINQ的全部分析,那么我们动手写一个小例子,作为想扩展LINQ的小雏形。该例子不会涉及到对表达式树的分析,毕竟表达式树的分析并非易事,后面会有专本的文章来剖析表达式树的完整结构,这里只是全盘的IQueryable和IQueryProvider的实现。
ORM一直是我们比较喜欢去写的框架,这里就使用自定义的IQueryable来查询相应的对象实体。首先我们需要继承IQueryable<T>接口来让LINQ能查询我们自己的数据上下文。
public class DbQuery<T> : IQueryable<T>, IDisposable
{
public DbQuery()
{
Provider = new DbQueryProvider();
Expression = Expression.Constant(this);//最后一个表达式将是第一IQueryable对象的引用。
}
public DbQuery(Expression expression)
{
Provider = new DbQueryProvider();
Expression = expression;
} public Type ElementType
{
get { return typeof(T); }
private set { ElementType = value; }
} public System.Linq.Expressions.Expression Expression
{
get;
private set;
} public IQueryProvider Provider
{
get;
private set;
} public IEnumerator<T> GetEnumerator()
{
return (Provider.Execute<T>(Expression) as IEnumerable<T>).GetEnumerator();
} System.Collections.IEnumerator System.Collections.IEnumerable.GetEnumerator()
{
return (Provider.Execute(Expression) as IEnumerable).GetEnumerator();
} public void Dispose()
{ }
}下面需要实现提供程序。 public class DbQueryProvider : IQueryProvider
{
public IQueryable<TElement> CreateQuery<TElement>(System.Linq.Expressions.Expression expression)
{
return new DbQuery<TElement>();
} public IQueryable CreateQuery(System.Linq.Expressions.Expression expression)
{
//这里牵扯到对表达式树的分析,就不多说了。
throw new NotImplementedException();
} public TResult Execute<TResult>(System.Linq.Expressions.Expression expression)
{
return default(TResult);//强类型数据集
} public object Execute(System.Linq.Expressions.Expression expression)
{
return new List<object>();//弱类型数据集
}
}
我们看看如何使用; using (DbQuery<Order> dbquery = new DbQuery<Order>())
{
var OrderList = from order in dbquery where order.OrderName == "" select order;
OrderList.Provider.Execute<List<Order>>(OrderList.Expression);//立即执行
foreach (var o in OrderList)
{
//延迟执行
}
}喜欢编写ORM框架的朋友完全值得花点时间搞一套自己的LINQ TO ORM,这里只是让你高兴一下
.NET深入解析LINQ框架2的更多相关文章
- .NET深入解析LINQ框架1
1.LINQ简述 2.LINQ优雅前奏的音符 2.1.隐式类型 (由编辑器自动根据表达式推断出对象的最终类型) 2.2.对象初始化器 (简化了对象的创建及初始化的过程) 2.3.Lambda表达式 ( ...
- atitit. groupby linq的实现(1)-----linq框架选型 java .net php
atitit. groupby linq的实现(1)-----linq框架选型 java .net php 实现方式有如下 1. Dsl/ Java8 Streams AP ,对象化的查询api , ...
- [LINQ2Dapper]最完整Dapper To Linq框架(五)---查看Linq实际执行的SQL
此例子是使用LINQ2Dapper封装,效率优于EntityFramwork,并且支持.NetFramework和.NetCore框架,只依赖于Dapper支持.net framework4.6.1及 ...
- 未能解析目标框架“.NETFramework,Version=v4.0”的 mscorlib的解决方法
本人菜鸟一个,在编码过程中遇到的问题记录下以备忘,高手别笑.最近在做一个项目,公司的VS版本是2010,家里的VS版本是2012.把公司的项目用2012打开后再用2010打开就出现 未能解析目标框架“ ...
- JSON 解析第三方框架
常见的 JSON 解析第三方框架 JSONKit(最快) SBJson TouchJSON 以上三个框架的性能依次降低! 介绍 JSONKit 第三方框架的目的 JSON 的解析并不是表面上那么简单 ...
- Spring5源码解析-Spring框架中的单例和原型bean
Spring5源码解析-Spring框架中的单例和原型bean 最近一直有问我单例和原型bean的一些原理性问题,这里就开一篇来说说的 通过Spring中的依赖注入极大方便了我们的开发.在xml通过& ...
- [LINQ2Dapper]最完整Dapper To Linq框架(七)---仓储模式
目录 [LINQ2Dapper]最完整Dapper To Linq框架(一)---基础查询 [LINQ2Dapper]最完整Dapper To Linq框架(二)---动态化查询 [LINQ2Dapp ...
- [LINQ2Dapper]最完整Dapper To Linq框架(一)---基础查询
此例子是使用LINQ2Dapper封装,效率优于EntityFramwork,并且支持.NetFramework和.NetCore框架,只依赖于Dapper 支持.net framework4.5.1 ...
- [LINQ2Dapper]最完整Dapper To Linq框架(二)---动态化查询
目录 [LINQ2Dapper]最完整Dapper To Linq框架(一)---基础查询 [LINQ2Dapper]最完整Dapper To Linq框架(二)---动态化查询 [LINQ2Dapp ...
随机推荐
- QlikSense系列(1)——整体介绍
接触QlikSense(3.1 SR1)已经快一年了,在此记录自己的经验心得,为想了解QlikSense的小伙伴提供一个参考. 1.产品介绍 Qlik公司以QlikView产品成名,QlikSense ...
- thinkphp5 模板中截取中文字符串
TP5模板页截取中文字符串 {$vo.task_detail|mb_substr=###,0,15,'utf-8'}
- 页面定制CSS代码初探(五):给每篇文章最后加上'<完>'
前言 我刚写博客的时候,有几篇是手动在最后加了个<完> 今天在看别人CSS布局时,发现很多::before和::after标签,因为没学过CSS,从名字看大概是前边/后边 加上某个东西的意 ...
- Chrome添加Unity本地文档引擎
前提:输入Unity后出来的第一连接 浏览器的设置: 分别填入: UnityDocs unity3d.com/cn file:///Applications/Unity/Documentation/e ...
- ZBrush中Flatten展平笔刷介绍
本文我们来介绍ZBrush®中的Flatten展平笔刷,Flatten笔刷能增加粗糙的平面在模型表面,利用它能够制作出完全的平面. Flatten展平笔刷 Flatten(展平):Flatten笔刷可 ...
- ajax第一天总结
AJAX开发步骤 步一:创建AJAX异步对象,例如:createAJAX() 步二:准备发送异步请求,例如:ajax.open(method,url) 步三:如果是POST请求的话,一定要设置AJAX ...
- virtualenv和virtualenvwrapper的安装与使用
环境 Windows 10 python 3.6.7 virtualenv 安装 virtualenv用于创建虚拟环境,用于隔离不同的python版本的运行,是容器类软件.这里在Windows下通过p ...
- 【BZOJ5020】[LOJ2289]【THUWC2017】在美妙的数学王国中畅游 - LCT+泰勒展开
咕咕咕?咕咕咕! 题意: Description 数字和数学规律主宰着这个世界. 机器的运转, 生命的消长, 宇宙的进程, 这些神秘而又美妙的过程无不可以用数学的语言展现出来. 这印证了一句古老的名言 ...
- git--客户端管理工具初步使用
说点废话哈 小白一枚, 今年3月份进入自己的第一家公司, 开始成为前端中的一份子,好在公司里有位和我一同进来的一位老哥带着我,从老哥身上学到的知识不多,(因为和老哥只相处工作了三个月,因为家里的事情, ...
- 【洛谷4941】War2 状压Dp
简单的状压DP,和NOIP2017 Day2 找宝藏 代码几乎一样.(比那个稍微简单一点) f[i][j] ,i代表点的状态,j是当前选择的点,枚举上一个选到的点k 然后从f[i-(1<< ...