Hadoop 三剑客之 —— 集群资源管理器 YARN
一、hadoop yarn 简介
Apache YARN (Yet Another Resource Negotiator) 是hadoop 2.0 引入的集群资源管理系统。用户可以将各种服务框架部署在YARN上,由YARN进行统一地管理和资源分配。
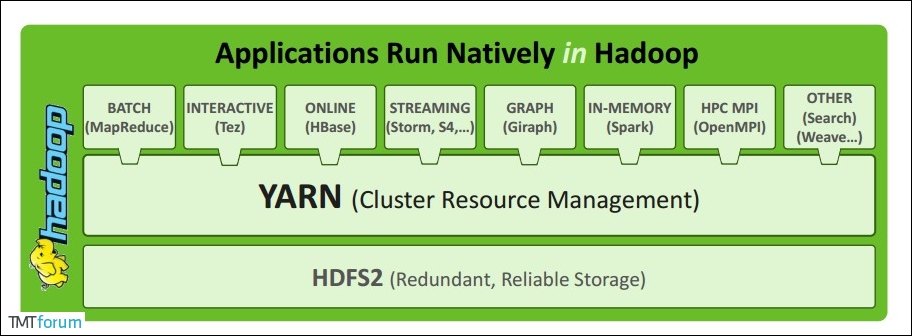
二、YARN架构
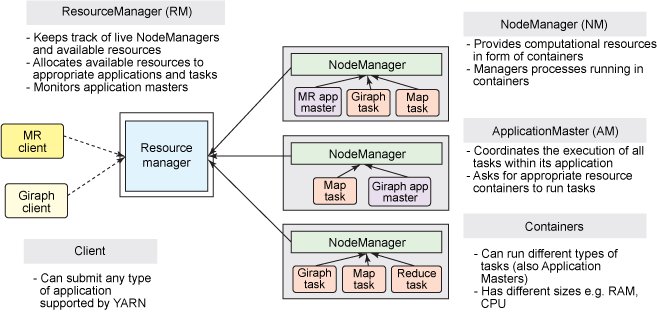
1. ResourceManager
ResourceManager通常在独立的机器上以后台进程的形式运行,它是整个集群资源的主要协调者和管理者。ResourceManager负责给用户提交的所有应用程序分配资源,它根据应用程序优先级、队列容量、ACLs、数据位置等信息,做出决策,然后以共享的、安全的、多租户的方式制定分配策略,调度集群资源。
2. NodeManager
NodeManager是YARN集群中的每个具体节点的管理者。主要负责该节点内所有容器的生命周期的管理,监视资源和跟踪节点健康。具体如下:
- 启动时向
ResourceManager注册并定时发送心跳消息,等待ResourceManager的指令; - 维护
Container的生命周期,监控Container的资源使用情况; - 管理任务运行时的相关依赖,根据
ApplicationMaster的需要,在启动Container之前将需要的程序及其依赖拷贝到本地。
3. ApplicationMaster
在用户提交一个应用程序时,YARN会启动一个轻量级的进程ApplicationMaster。ApplicationMaster负责协调来自 ResourceManager的资源,并通过NodeManager 监视容器内资源的使用情况,同时还负责任务的监控与容错。具体如下:
- 根据应用的运行状态来决定动态计算资源需求;
- 向
ResourceManager申请资源,监控申请的资源的使用情况; - 跟踪任务状态和进度,报告资源的使用情况和应用的进度信息;
- 负责任务的容错。
4. Contain
Container是YARN中的资源抽象,它封装了某个节点上的多维度资源,如内存、CPU、磁盘、网络等。当AM向RM申请资源时,RM为AM返回的资源是用Container表示的。YARN会为每个任务分配一个Container,该任务只能使用该Container中描述的资源。ApplicationMaster可在Container内运行任何类型的任务。例如,MapReduce ApplicationMaster请求一个容器来启动 map 或 reduce 任务,而Giraph ApplicationMaster请求一个容器来运行 Giraph 任务。
三、YARN工作原理简述
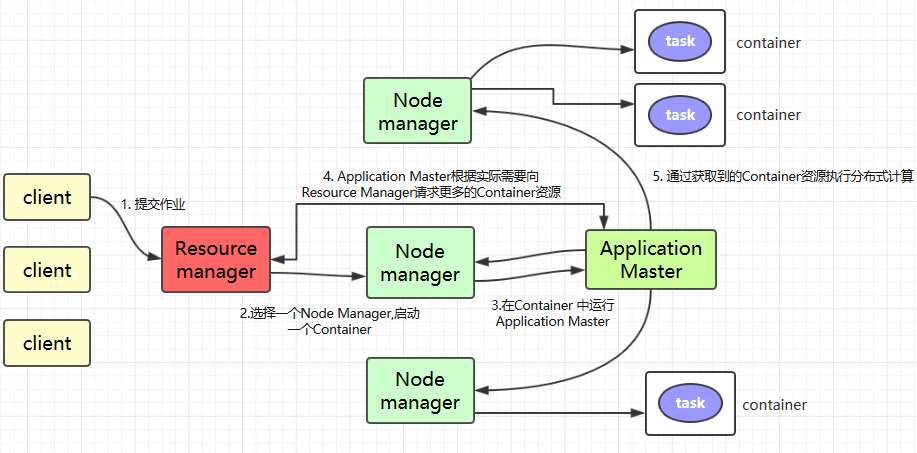
Client提交作业到YARN上;Resource Manager选择一个Node Manager,启动一个Container并运行Application Master实例;Application Master根据实际需要向Resource Manager请求更多的Container资源(如果作业很小, 应用管理器会选择在其自己的JVM中运行任务);Application Master通过获取到的Container资源执行分布式计算。
四、YARN工作原理详述
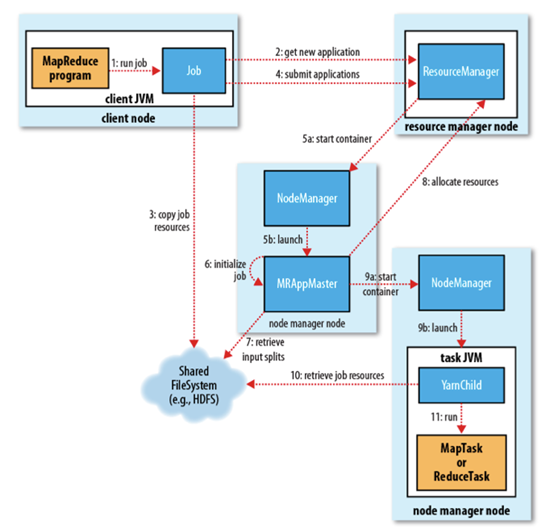
1. 作业提交
client调用job.waitForCompletion方法,向整个集群提交MapReduce作业 (第1步) 。新的作业ID(应用ID)由资源管理器分配(第2步)。作业的client核实作业的输出, 计算输入的split, 将作业的资源(包括Jar包,配置文件, split信息)拷贝给HDFS(第3步)。 最后, 通过调用资源管理器的submitApplication()来提交作业(第4步)。
2. 作业初始化
当资源管理器收到submitApplciation()的请求时, 就将该请求发给调度器(scheduler), 调度器分配container, 然后资源管理器在该container内启动应用管理器进程, 由节点管理器监控(第5步)。
MapReduce作业的应用管理器是一个主类为MRAppMaster的Java应用,其通过创造一些bookkeeping对象来监控作业的进度, 得到任务的进度和完成报告(第6步)。然后其通过分布式文件系统得到由客户端计算好的输入split(第7步),然后为每个输入split创建一个map任务, 根据mapreduce.job.reduces创建reduce任务对象。
3. 任务分配
如果作业很小, 应用管理器会选择在其自己的JVM中运行任务。
如果不是小作业, 那么应用管理器向资源管理器请求container来运行所有的map和reduce任务(第8步)。这些请求是通过心跳来传输的, 包括每个map任务的数据位置,比如存放输入split的主机名和机架(rack),调度器利用这些信息来调度任务,尽量将任务分配给存储数据的节点, 或者分配给和存放输入split的节点相同机架的节点。
4. 任务运行
当一个任务由资源管理器的调度器分配给一个container后,应用管理器通过联系节点管理器来启动container(第9步)。任务由一个主类为YarnChild的Java应用执行, 在运行任务之前首先本地化任务需要的资源,比如作业配置,JAR文件, 以及分布式缓存的所有文件(第10步。 最后, 运行map或reduce任务(第11步)。
YarnChild运行在一个专用的JVM中, 但是YARN不支持JVM重用。
5. 进度和状态更新
YARN中的任务将其进度和状态(包括counter)返回给应用管理器, 客户端每秒(通mapreduce.client.progressmonitor.pollinterval设置)向应用管理器请求进度更新, 展示给用户。
6. 作业完成
除了向应用管理器请求作业进度外, 客户端每5分钟都会通过调用waitForCompletion()来检查作业是否完成,时间间隔可以通过mapreduce.client.completion.pollinterval来设置。作业完成之后, 应用管理器和container会清理工作状态, OutputCommiter的作业清理方法也会被调用。作业的信息会被作业历史服务器存储以备之后用户核查。
五、提交作业到YARN上运行
这里以提交Hadoop Examples中计算Pi的MApReduce程序为例,相关Jar包在Hadoop安装目录的share/hadoop/mapreduce目录下:
# 提交格式: hadoop jar jar包路径 主类名称 主类参数
# hadoop jar hadoop-mapreduce-examples-2.6.0-cdh5.15.2.jar pi 3 3参考资料
更多大数据系列文章可以参见个人 GitHub 开源项目: 大数据入门指南
Hadoop 三剑客之 —— 集群资源管理器 YARN的更多相关文章
- Hadoop 学习之路(二)—— 集群资源管理器 YARN
一.hadoop yarn 简介 Apache YARN (Yet Another Resource Negotiator) 是hadoop 2.0 引入的集群资源管理系统.用户可以将各种服务框架部署 ...
- Hadoop 系列(二)—— 集群资源管理器 YARN
一.hadoop yarn 简介 Apache YARN (Yet Another Resource Negotiator) 是 hadoop 2.0 引入的集群资源管理系统.用户可以将各种服务框架部 ...
- Hadoop分布式资源管理器Yarn、MR运行机制剖析
介绍YARN组件的功能及应用场景 1.ResourceManager(RM) RM是一个全局的资源管理器,集群中只有一个.它负责整个Hadoop系统的资源管理和分配,包括处理客户端请求.启动监控 Ap ...
- Hadoop(三)手把手教你搭建Hadoop全分布式集群
前言 上一篇介绍了伪分布式集群的搭建,其实在我们的生产环境中我们肯定不是使用只有一台服务器的伪分布式集群当中的.接下来我将给大家分享一下全分布式集群的搭建! 其实搭建最基本的全分布式集群和伪分布式集群 ...
- Hadoop(三)搭建Hadoop全分布式集群
原文地址:http://www.cnblogs.com/zhangyinhua/p/7652686.html 阅读目录(Content) 一.搭建Hadoop全分布式集群前提 1.1.网络 1.2.安 ...
- Hadoop+Hbase分布式集群架构“完全篇”
本文收录在Linux运维企业架构实战系列 前言:本篇博客是博主踩过无数坑,反复查阅资料,一步步搭建,操作完成后整理的个人心得,分享给大家~~~ 1.认识Hadoop和Hbase 1.1 hadoop简 ...
- 【Hadoop】2、Hadoop高可用集群部署
1.服务器设置 集群规划 Namenode-Hadoop管理节点 10.25.24.92 10.25.24.93 Datanode-Hadoop数据存储节点 10.25.24.89 10.25.24. ...
- Spark的集群管理器
上篇文章谈到Driver节点和Executor节点,但是如果想要运行Driver节点和Executor节点,就不能不说spark的集群管理器.spark的集群管理器大致有三种,一种是自带的standa ...
- Spark集群管理器介绍
Spark可以运行在各种集群管理器上,并通过集群管理器访问集群中的其他机器.Spark主要有三种集群管理器,如果只是想让spark运行起来,可以采用spark自带的独立集群管理器,采用独立部署的模式: ...
随机推荐
- Extensible File System
An extensible file system format for portable storage media is provided. The extensible file system ...
- C++中的模板编程
一,函数模板 1.函数模板的概念 C++中提供了函数模板,所谓函数模板,实际上是建立一个通用函数,其函数的返回值类型和函数的参数类型不具体指定,用一个虚拟的类型来表示.这个通用函数就被称为函数的模板. ...
- 【转】解决yum安装软件报Couldn't resolve host 'mirrorlist.centos.org问题
转自:http://blog.51cto.com/oldcat1981/1719825 今天在linux环境通过yum安装软件报了以下错误: [root@multi-mysql yum.rep ...
- jxl导出Excel
首先先在自己工程中导入jxl的jar包: 疯狂google后找到一段别人的导出excel方法,先备份于下面: import java.io.File; import java.io.FileOutpu ...
- wpf控件设计时支持(3)
原文:wpf控件设计时支持(3) wpf设计时调试 编辑模型 装饰器 1.wpf设计时调试 为了更好的了解wpf设计时框架,那么调试则非常重要,通过以下配置可以调试控件的设计时代码 (1)将启动项目配 ...
- AvalonDock的基本用法
原文:AvalonDock的基本用法 AvalonDock是优秀的开源项目,用于创建可停靠式布局,能够在WPF中方便开发出类似VS2010的软件界面.对于复杂的软件系统,大量控件的使用 ...
- 安装mysql5.7.17
参见 网易云课堂的视频教程 :mysql视频教程
- 数学公式的规约(reduce)和简化(simplify)
to simplify notation, 1. 增广(augment) xi=[xi;1],减少一个常数项: 2. 多个求和号 ∥x∥2=xTx 向量 ⇒ 矩阵: 求和号本身也可化为向量矩阵运算: ...
- 微信小程序之登录页实例
项目效果图: 目录结构: login.wxml: <view class="container"> <view class="login-icon&qu ...
- 怎么给罗技K480 增加Home、End键
最近看张大妈上很多人分享了我的桌面,有感于整天低头码字不利健康,隧鼓捣起自己的电脑桌了. 此处省略N字... 进入正文,我码字用的是罗技的K480蓝牙键盘 码了几行代码,发现没有Home.End键,这 ...