深度神经网络(DNN)
深度神经网络(DNN)
深度神经网络(Deep Neural Networks, 以下简称DNN)是深度学习的基础,而要理解DNN,首先我们要理解DNN模型,下面我们就对DNN的模型与前向传播算法做一个总结。
1. 从感知机到神经网络
在感知机原理小结中,我们介绍过感知机的模型,它是一个有若干输入和一个输出的模型,如下图:
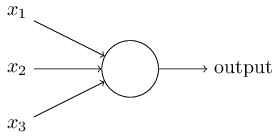
输出和输入之间学习到一个线性关系,得到中间输出结果:
接着是一个神经元激活函数:
从而得到我们想要的输出结果1或者-1。
这个模型只能用于二元分类,且无法学习比较复杂的非线性模型,因此在工业界无法使用。
而神经网络则在感知机的模型上做了扩展,总结下主要有三点:
1)加入了隐藏层,隐藏层可以有多层,增强模型的表达能力,如下图实例,当然增加了这么多隐藏层模型的复杂度也增加了好多。
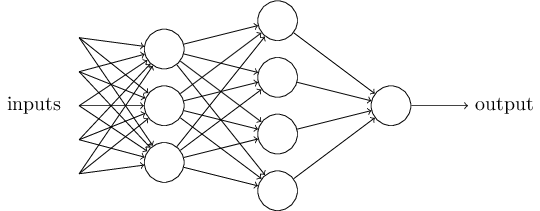
2)输出层的神经元也可以不止一个输出,可以有多个输出,这样模型可以灵活的应用于分类回归,以及其他的机器学习领域比如降维和聚类等。多个神经元输出的输出层对应的一个实例如下图,输出层现在有4个神经元了。
3) 对激活函数做扩展,感知机的激活函数是sign(z)sign(z),虽然简单但是处理能力有限,因此神经网络中一般使用的其他的激活函数,比如我们在逻辑回归里面使用过的Sigmoid函数,即:
还有后来出现的tanx, softmax,和ReLU等。通过使用不同的激活函数,神经网络的表达能力进一步增强。对于各种常用的激活函数,我们在后面再专门讲。
2. DNN的基本结构
上一节我们了解了神经网络基于感知机的扩展,而DNN可以理解为有很多隐藏层的神经网络。这个很多其实也没有什么度量标准, 多层神经网络和深度神经网络DNN其实也是指的一个东西,当然,DNN有时也叫做多层感知机(Multi-Layer perceptron,MLP), 名字实在是多。后面我们讲到的神经网络都默认为DNN。
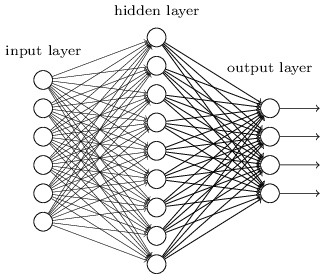
从DNN按不同层的位置划分,DNN内部的神经网络层可以分为三类,输入层,隐藏层和输出层,如下图示例,一般来说第一层是输出层,最后一层是输出层,而中间的层数都是隐藏层。
层与层之间是全连接的,也就是说,第i层的任意一个神经元一定与第i+1层的任意一个神经元相连。虽然DNN看起来很复杂,但是从小的局部模型来说,还是和感知机一样,即一个线性关系z=∑wixi+bz=∑wixi+b加上一个激活函数σ(z)σ(z)。
由于DNN层数多,则我们的线性关系系数ww和偏倚bb的数量也就是很多了。具体的参数在DNN是如何定义的呢?
首先我们来看看线性关系系数ww的定义。以下图一个三层的DNN为例,第二层的第4个神经元到第三层的第2个神经元的线性系数定义为w324w243。上标3代表线性系数ww所在的层数,而下标对应的是输出的第三层索引2和输入的第二层索引4。你也许会问,为什么不是w342w423, 而是w324w243呢?这主要是为了便于模型用于矩阵表示运算,如果是w324w243而每次进行矩阵运算是wTx+bwTx+b,需要进行转置。将输出的索引放在前面的话,则线性运算不用转置,即直接为wx+bwx+b。总结下,第l−1l−1层的第k个神经元到第ll层的第j个神经元的线性系数定义为wljkwjkl。注意,输入层是没有ww参数的。
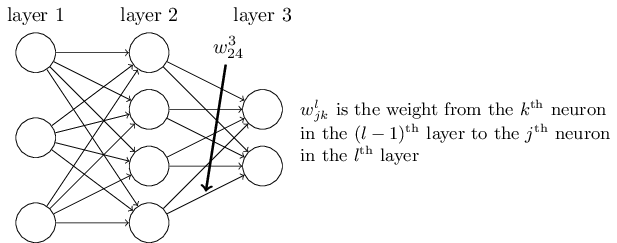
再来看看偏倚bb的定义。还是以这个三层的DNN为例,第二层的第三个神经元对应的偏倚定义为b23b32。其中,上标2代表所在的层数,下标3代表偏倚所在的神经元的索引。同样的道理,第三个的第一个神经元的偏倚应该表示为b31b13。同样的,输入层是没有偏倚参数bb的。
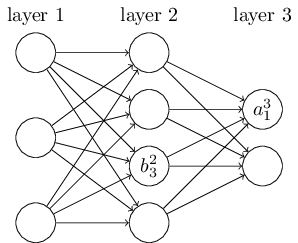
3. DNN前向传播算法数学原理
在上一节,我们已经介绍了DNN各层线性关系系数ww,偏倚bb的定义。假设我们选择的激活函数是σ(z)σ(z),隐藏层和输出层的输出值为aa,则对于下图的三层DNN,利用和感知机一样的思路,我们可以利用上一层的输出计算下一层的输出,也就是所谓的DNN前向传播算法。
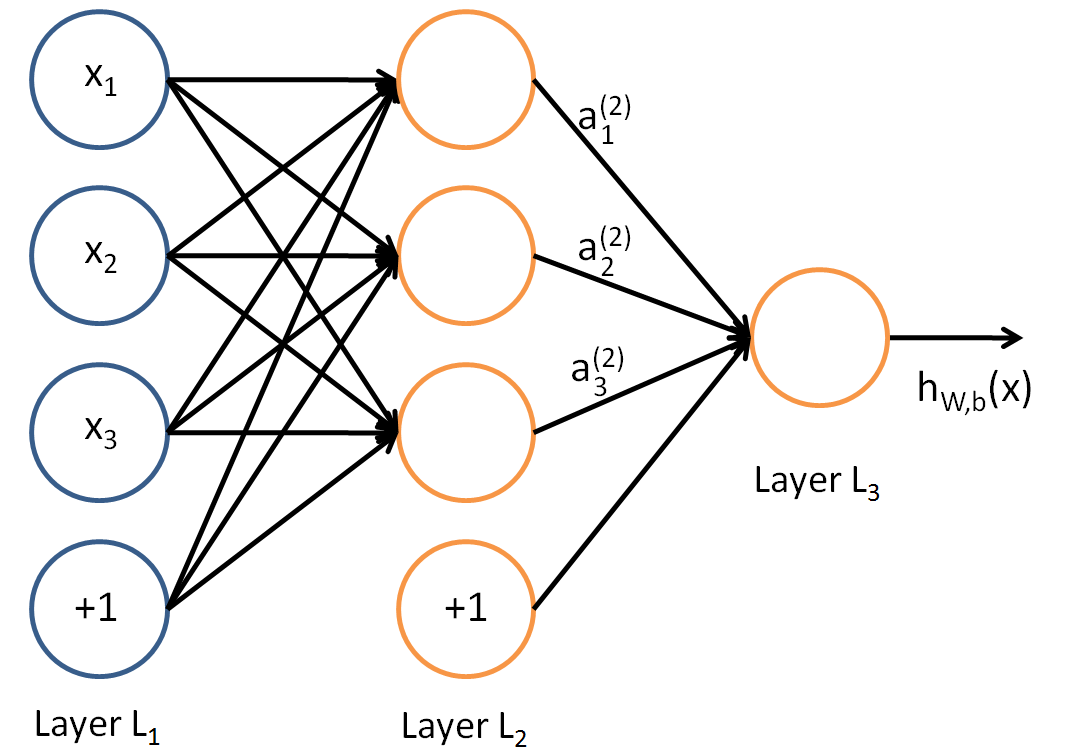
对于第二层的的输出a21,a22,a23a12,a22,a32,我们有:
对于第三层的的输出a31a13,我们有:
将上面的例子一般化,假设第l−1l−1层共有m个神经元,则对于第ll层的第j个神经元的输出aljajl,我们有:
其中,如果l=2l=2,则对于的a1kak1即为输入层的xkxk。
从上面可以看出,使用代数法一个个的表示输出比较复杂,而如果使用矩阵法则比较的简洁。假设第l−1l−1层共有m个神经元,而第ll层共有n个神经元,则第ll层的线性系数ww组成了一个n×mn×m的矩阵WlWl, 第ll层的偏倚bb组成了一个n×1n×1的向量blbl , 第l−1l−1层的的输出aa组成了一个m×1m×1的向量al−1al−1,第ll层的的未激活前线性输出zz组成了一个n×1n×1的向量zlzl, 第ll层的的输出aa组成了一个n×1n×1的向量alal。则用矩阵法表示,第l层的输出为:
这个表示方法简洁漂亮,后面我们的讨论都会基于上面的这个矩阵法表示来。
4. DNN前向传播算法
有了上一节的数学推导,DNN的前向传播算法也就不难了。所谓的DNN的前向传播算法也就是利用我们的若干个权重系数矩阵WW,偏倚向量bb来和输入值向量xx进行一系列线性运算和激活运算,从输入层开始,一层层的向后计算,一直到运算到输出层,得到输出结果为值。
输入: 总层数L,所有隐藏层和输出层对应的矩阵WW,偏倚向量bb,输入值向量xx
输出:输出层的输出aLaL
1) 初始化a1=xa1=x
2) for l=2l=2 to LL, 计算:
最后的结果即为输出aLaL。
5. DNN前向传播算法小结
单独看DNN前向传播算法,似乎没有什么大用处,而且这一大堆的矩阵WW,偏倚向量bb对应的参数怎么获得呢?怎么得到最优的矩阵WW,偏倚向量bb呢?这个我们在讲DNN的反向传播算法时再讲。而理解反向传播算法的前提就是理解DNN的模型与前向传播算法。这也是我们这一篇先讲的原因。
(欢迎转载,转载请注明出处。欢迎沟通交流: pinard.liu@ericsson.com)
参考资料:
1) Neural Networks and Deep Learning by By Michael Nielsen
2) Deep Learning, book by Ian Goodfellow, Yoshua Bengio, and Aaron Courville
深度神经网络(DNN)的更多相关文章
- 深度神经网络DNN的多GPU数据并行框架 及其在语音识别的应用
深度神经网络(Deep Neural Networks, 简称DNN)是近年来机器学习领域中的研究热点,产生了广泛的应用.DNN具有深层结构.数千万参数需要学习,导致训练非常耗时.GPU有强大的计算能 ...
- 一天搞懂深度学习-训练深度神经网络(DNN)的要点
前言 这是<一天搞懂深度学习>的第二部分 一.选择合适的损失函数 典型的损失函数有平方误差损失函数和交叉熵损失函数. 交叉熵损失函数: 选择不同的损失函数会有不同的训练效果 二.mini- ...
- 深度神经网络(DNN)模型与前向传播算法
深度神经网络(Deep Neural Networks, 以下简称DNN)是深度学习的基础,而要理解DNN,首先我们要理解DNN模型,下面我们就对DNN的模型与前向传播算法做一个总结. 1. 从感知机 ...
- 神经网络6_CNN(卷积神经网络)、RNN(循环神经网络)、DNN(深度神经网络)概念区分理解
sklearn实战-乳腺癌细胞数据挖掘(博客主亲自录制视频教程,QQ:231469242) https://study.163.com/course/introduction.htm?courseId ...
- 云中的机器学习:FPGA 上的深度神经网络
人工智能正在经历一场变革,这要得益于机器学习的快速进步.在机器学习领域,人们正对一类名为“深度学习”算法产生浓厚的兴趣,因为这类算法具有出色的大数据集性能.在深度学习中,机器可以在监督或不受监督的方式 ...
- CNN(卷积神经网络)、RNN(循环神经网络)、DNN(深度神经网络)的内部网络结构有什么区别?
https://www.zhihu.com/question/34681168 CNN(卷积神经网络).RNN(循环神经网络).DNN(深度神经网络)的内部网络结构有什么区别?修改 CNN(卷积神经网 ...
- 深度神经网络(DNN)反向传播算法(BP)
在深度神经网络(DNN)模型与前向传播算法中,我们对DNN的模型和前向传播算法做了总结,这里我们更进一步,对DNN的反向传播算法(Back Propagation,BP)做一个总结. 1. DNN反向 ...
- 深度神经网络(DNN)损失函数和激活函数的选择
在深度神经网络(DNN)反向传播算法(BP)中,我们对DNN的前向反向传播算法的使用做了总结.里面使用的损失函数是均方差,而激活函数是Sigmoid.实际上DNN可以使用的损失函数和激活函数不少.这些 ...
- 深度神经网络(DNN)的正则化
和普通的机器学习算法一样,DNN也会遇到过拟合的问题,需要考虑泛化,这里我们就对DNN的正则化方法做一个总结. 1. DNN的L1&L2正则化 想到正则化,我们首先想到的就是L1正则化和L2正 ...
随机推荐
- java程序猿经常使用的工具名称--知道中文意思吗
在学习java的时候常常会碰到一些单词,可是一般的时候也不是非常在意这个单词的意思,而是能够了解到这个工具或者框架能够做什么就能够了.偶尔总结了一下还蛮有意思的.例如以下, 假设有遗漏,各位能够帮忙补 ...
- wepy小程序实现列表分页上拉加载(2)
第一篇:wepy小程序实现列表分页上拉加载(1) 本文接着上一篇内容: 4.优化-添加加载动画 (1)首先写加载动画的结构和样式 打开list.wpy文件 template结构代码: <temp ...
- 2、opencv2.4.13.6安装
一. 卸载opencv3.3.0: Going to the "build" folder directory of opencv from terminal, and execu ...
- TOP全异步模式
Top全异步方式调用技术方案 背景:目前top通过servlet3.0技术结合异步管道化框架做到半异步调用,半异步调用采用异步线程同步调用后端的方式来做api call @飞不起的奥特曼 的部分文档) ...
- Cocos2dx 小技巧(十六)再谈visit(getDescription)
之前两篇都是介绍与Value相关的,这篇我继续这个话题吧,正好凑个"Value三板斧系列...".在非常久非常久曾经.我用写过一篇博客,关于怎样查看CCArray与CCDictio ...
- License控制实现原理(20140808)
近期须要做一个License控制的实现,做了一个设计,设计图例如以下: watermark/2/text/aHR0cDovL2Jsb2cuY3Nkbi5uZXQvdGVjX2Zlbmc=/font/5 ...
- HDU 1248 寒冰王座 完全背包
传送门:http://acm.hdu.edu.cn/showproblem.php?pid=1248 中文题,大意就不说了. 第一道完全背包题,跟着背包九讲做的. 和0-1背包的区别在于所不同的是每种 ...
- Yii Framework2.0开发教程(1)配置环境及第一个应用HelloWorld
准备工作: 我用的开发环境是windows下的apache+mysql+php 编辑器不知道该用哪个好.临时用dreamweaver吧 我自己的http://localhost/相应的根文件夹是E:/ ...
- js进阶课程ajax简介(ajax是浏览器来实现的)
js进阶课程ajax简介(ajax是浏览器来实现的) 一.总结 1.ajax使用需要服务器支持,比如phpstudy 2.ajax是浏览器支持的功能:ajax有个核心对象XMLHttpRequest, ...
- 【44.10%】【codeforces 723B】Text Document Analysis
time limit per test1 second memory limit per test256 megabytes inputstandard input outputstandard ou ...