0807再整理SQL执行流程
转自http://www.cnblogs.com/annsshadow/p/5037667.html
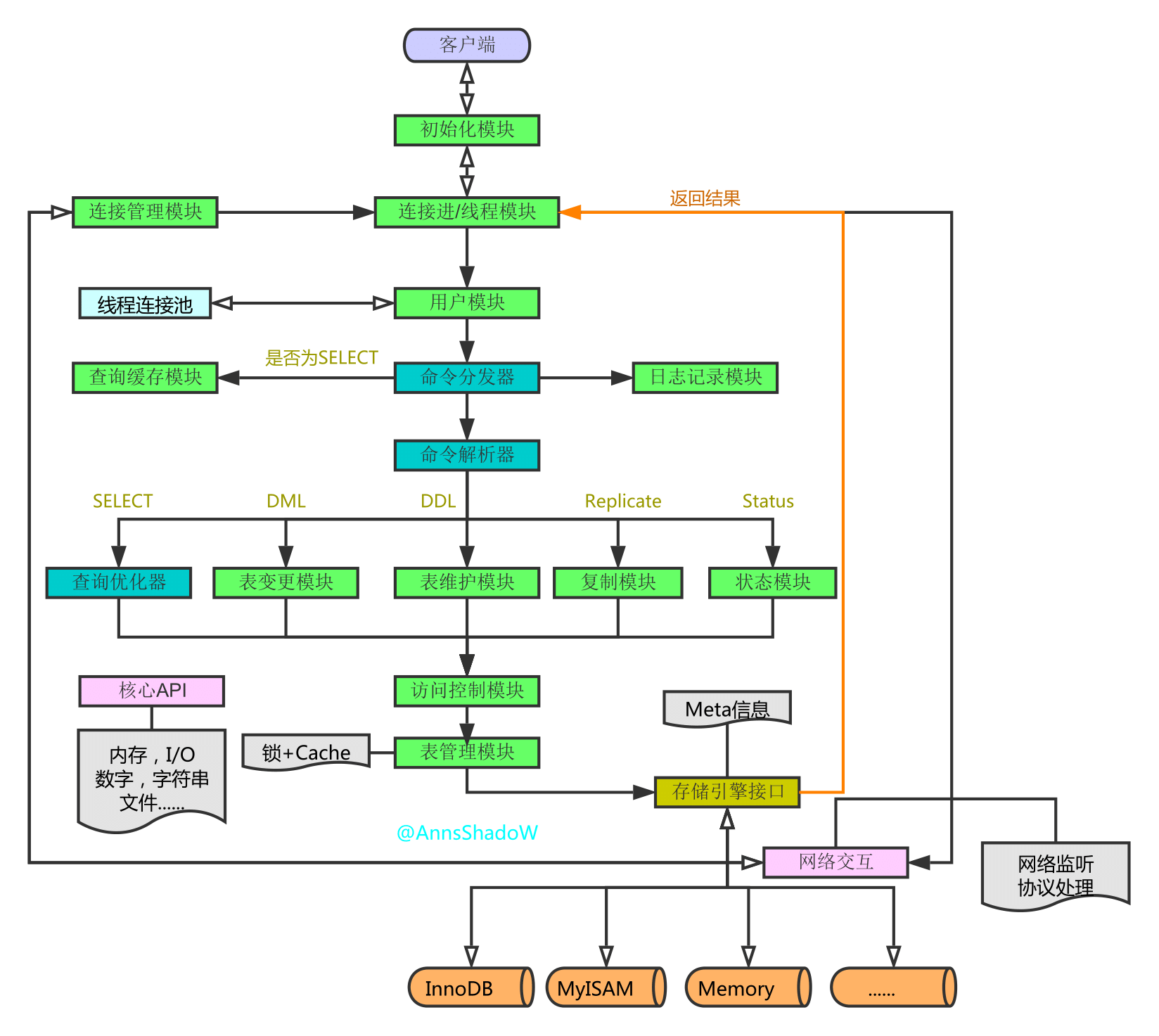
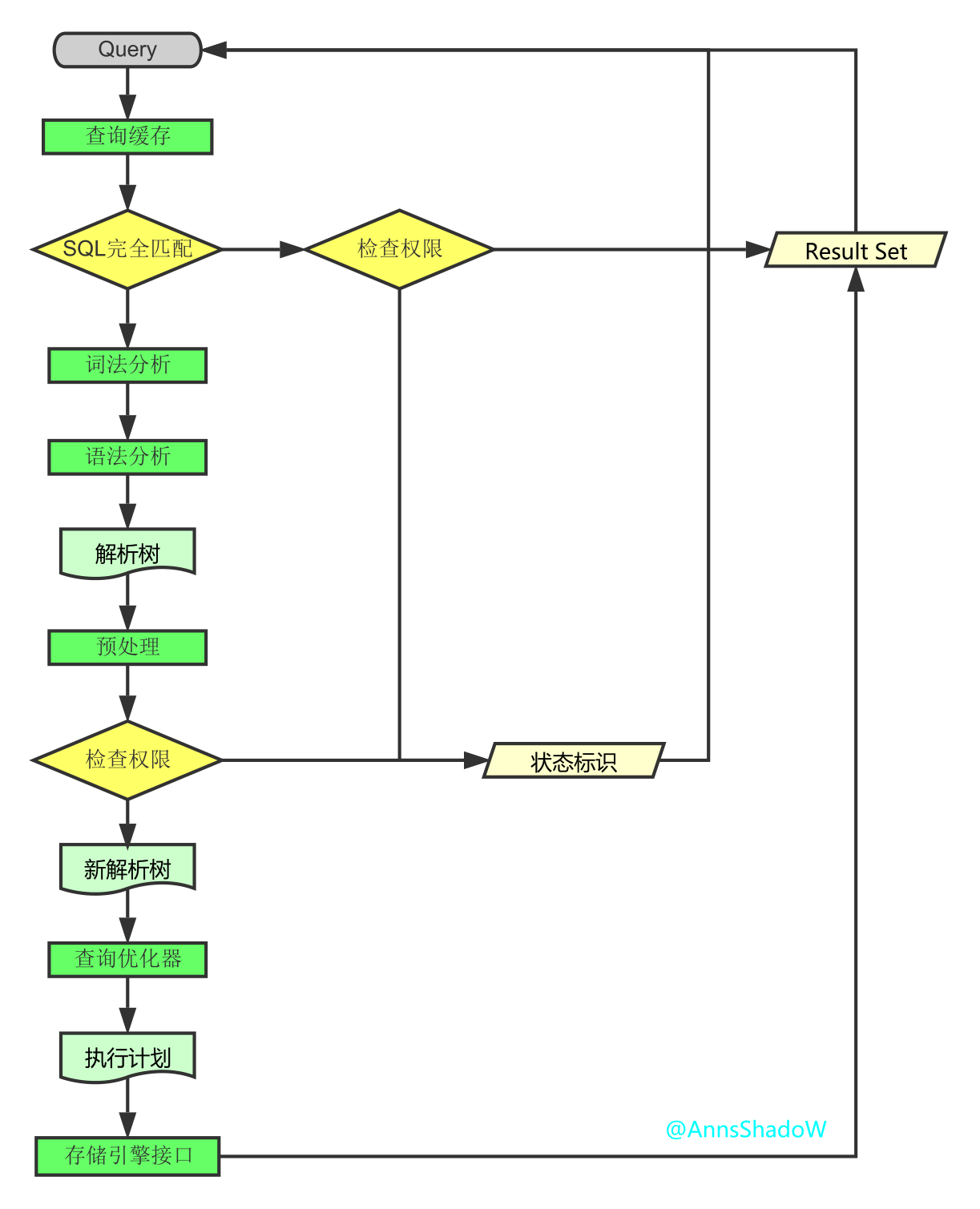
MySQL架构总览->查询执行流程->SQL解析顺序

SELECT DISTINCT
< select_list >
FROM
< left_table > < join_type >
JOIN < right_table > ON < join_condition >
WHERE
< where_condition >
GROUP BY
< group_by_list >
HAVING
< having_condition >
ORDER BY
< order_by_condition >
LIMIT < limit_number >
1 FROM <left_table>
2 ON <join_condition>
3 <join_type> JOIN <right_table>
4 WHERE <where_condition>
5 GROUP BY <group_by_list>
6 HAVING <having_condition>
7 SELECT
8 DISTINCT <select_list>
9 ORDER BY <order_by_condition>
10 LIMIT <limit_number>
create database testQuery
CREATE TABLE table1
(
uid VARCHAR(10) NOT NULL,
name VARCHAR(10) NOT NULL,
PRIMARY KEY(uid)
)ENGINE=INNODB DEFAULT CHARSET=UTF8; CREATE TABLE table2
(
oid INT NOT NULL auto_increment,
uid VARCHAR(10),
PRIMARY KEY(oid)
)ENGINE=INNODB DEFAULT CHARSET=UTF8;
INSERT INTO table1(uid,name) VALUES('aaa','mike'),('bbb','jack'),('ccc','mike'),('ddd','mike');
INSERT INTO table2(uid) VALUES('aaa'),('aaa'),('bbb'),('bbb'),('bbb'),('ccc'),(NULL);
SELECT
a.uid,
count(b.oid) AS total
FROM
table1 AS a
LEFT JOIN table2 AS b ON a.uid = b.uid
WHERE
a. NAME = 'mike'
GROUP BY
a.uid
HAVING
count(b.oid) < 2
ORDER BY
total DESC
LIMIT 1;
mysql> select * from table1,table2;
+-----+------+-----+------+
| uid | name | oid | uid |
+-----+------+-----+------+
| aaa | mike | 1 | aaa |
| bbb | jack | 1 | aaa |
| ccc | mike | 1 | aaa |
| ddd | mike | 1 | aaa |
| aaa | mike | 2 | aaa |
| bbb | jack | 2 | aaa |
| ccc | mike | 2 | aaa |
| ddd | mike | 2 | aaa |
| aaa | mike | 3 | bbb |
| bbb | jack | 3 | bbb |
| ccc | mike | 3 | bbb |
| ddd | mike | 3 | bbb |
| aaa | mike | 4 | bbb |
| bbb | jack | 4 | bbb |
| ccc | mike | 4 | bbb |
| ddd | mike | 4 | bbb |
| aaa | mike | 5 | bbb |
| bbb | jack | 5 | bbb |
| ccc | mike | 5 | bbb |
| ddd | mike | 5 | bbb |
| aaa | mike | 6 | ccc |
| bbb | jack | 6 | ccc |
| ccc | mike | 6 | ccc |
| ddd | mike | 6 | ccc |
| aaa | mike | 7 | NULL |
| bbb | jack | 7 | NULL |
| ccc | mike | 7 | NULL |
| ddd | mike | 7 | NULL |
+-----+------+-----+------+
28 rows in set (0.00 sec)
mysql> SELECT
-> *
-> FROM
-> table1,
-> table2
-> WHERE
-> table1.uid = table2.uid
-> ;
+-----+------+-----+------+
| uid | name | oid | uid |
+-----+------+-----+------+
| aaa | mike | 1 | aaa |
| aaa | mike | 2 | aaa |
| bbb | jack | 3 | bbb |
| bbb | jack | 4 | bbb |
| bbb | jack | 5 | bbb |
| ccc | mike | 6 | ccc |
+-----+------+-----+------+
6 rows in set (0.00 sec)
mysql> SELECT
-> *
-> FROM
-> table1 AS a
-> LEFT OUTER JOIN table2 AS b ON a.uid = b.uid;
+-----+------+------+------+
| uid | name | oid | uid |
+-----+------+------+------+
| aaa | mike | 1 | aaa |
| aaa | mike | 2 | aaa |
| bbb | jack | 3 | bbb |
| bbb | jack | 4 | bbb |
| bbb | jack | 5 | bbb |
| ccc | mike | 6 | ccc |
| ddd | mike | NULL | NULL |
+-----+------+------+------+
7 rows in set (0.00 sec)

mysql> SELECT
-> *
-> FROM
-> table1 AS a
-> LEFT OUTER JOIN table2 AS b ON a.uid = b.uid
-> WHERE
-> a. NAME = 'mike';
+-----+------+------+------+
| uid | name | oid | uid |
+-----+------+------+------+
| aaa | mike | 1 | aaa |
| aaa | mike | 2 | aaa |
| ccc | mike | 6 | ccc |
| ddd | mike | NULL | NULL |
+-----+------+------+------+
4 rows in set (0.00 sec)
mysql> SELECT
-> *
-> FROM
-> table1 AS a
-> LEFT OUTER JOIN table2 AS b ON a.uid = b.uid
-> WHERE
-> a. NAME = 'mike'
-> GROUP BY
-> a.uid;
+-----+------+------+------+
| uid | name | oid | uid |
+-----+------+------+------+
| aaa | mike | 1 | aaa |
| ccc | mike | 6 | ccc |
| ddd | mike | NULL | NULL |
+-----+------+------+------+
3 rows in set (0.00 sec)
mysql> SELECT
-> *
-> FROM
-> table1 AS a
-> LEFT OUTER JOIN table2 AS b ON a.uid = b.uid
-> WHERE
-> a. NAME = 'mike'
-> GROUP BY
-> a.uid
-> HAVING
-> count(b.oid) < 2;
+-----+------+------+------+
| uid | name | oid | uid |
+-----+------+------+------+
| ccc | mike | 6 | ccc |
| ddd | mike | NULL | NULL |
+-----+------+------+------+
2 rows in set (0.00 sec)
mysql> SELECT
-> a.uid,
-> count(b.oid) AS total
-> FROM
-> table1 AS a
-> LEFT OUTER JOIN table2 AS b ON a.uid = b.uid
-> WHERE
-> a. NAME = 'mike'
-> GROUP BY
-> a.uid
-> HAVING
-> count(b.oid) < 2;
+-----+-------+
| uid | total |
+-----+-------+
| ccc | 1 |
| ddd | 0 |
+-----+-------+
2 rows in set (0.00 sec)
mysql> SELECT
-> a.uid,
-> count(b.oid) AS total
-> FROM
-> table1 AS a
-> LEFT OUTER JOIN table2 AS b ON a.uid = b.uid
-> WHERE
-> a. NAME = 'mike'
-> GROUP BY
-> a.uid
-> HAVING
-> count(b.oid) < 2
-> ORDER BY
-> total DESC;
+-----+-------+
| uid | total |
+-----+-------+
| ccc | 1 |
| ddd | 0 |
+-----+-------+
2 rows in set (0.00 sec)
mysql> SELECT
-> a.uid,
-> count(b.oid) AS total
-> FROM
-> table1 AS a
-> LEFT JOIN table2 AS b ON a.uid = b.uid
-> WHERE
-> a. NAME = 'mike'
-> GROUP BY
-> a.uid
-> HAVING
-> count(b.oid) < 2
-> ORDER BY
-> total DESC
-> LIMIT 1;
+-----+-------+
| uid | total |
+-----+-------+
| ccc | 1 |
+-----+-------+
1 row in set (0.00 sec)

0807再整理SQL执行流程的更多相关文章
- Hive SQL执行流程分析
转自 http://www.tuicool.com/articles/qyUzQj 最近在研究Impala,还是先回顾下Hive的SQL执行流程吧. Hive有三种用户接口: cli (Command ...
- Spark修炼之道(进阶篇)——Spark入门到精通:第九节 Spark SQL执行流程解析
1.总体执行流程 使用下列代码对SparkSQL流程进行分析.让大家明确LogicalPlan的几种状态,理解SparkSQL总体执行流程 // sc is an existing SparkCont ...
- MySQL架构与SQL执行流程
MySQL架构设计 下面是一张MySQL的架构图: 上方各个组件的含义如下: Connectors 指的是不同语言中与SQL的交互 Management Serveices & Utiliti ...
- MySQL笔记(5)-- SQL执行流程,MySQL体系结构
MySQL的体系结构,可以清楚地看到 SQL 语句在 MySQL 的各个功能模块中的执行过程:Server层包括连接层.查询缓存.分析器.优化器.执行器等,涵盖MySQL的大多数核心服务功能,以及所有 ...
- 深入浅出Mybatis系列(十)---SQL执行流程分析(源码篇)
最近太忙了,一直没时间继续更新博客,今天忙里偷闲继续我的Mybatis学习之旅.在前九篇中,介绍了mybatis的配置以及使用, 那么本篇将走进mybatis的源码,分析mybatis 的执行流程, ...
- 深入浅出Mybatis系列十-SQL执行流程分析(源码篇)
注:本文转载自南轲梦 注:博主 Chloneda:个人博客 | 博客园 | Github | Gitee | 知乎 最近太忙了,一直没时间继续更新博客,今天忙里偷闲继续我的Mybatis学习之旅.在前 ...
- [源码分析] 带你梳理 Flink SQL / Table API内部执行流程
[源码分析] 带你梳理 Flink SQL / Table API内部执行流程 目录 [源码分析] 带你梳理 Flink SQL / Table API内部执行流程 0x00 摘要 0x01 Apac ...
- spark-sql执行流程分析
spark-sql 架构 图1 图1是sparksql的执行架构,主要包括逻辑计划和物理计划几个阶段,下面对流程详细分析. sql执行流程 总体流程 parser:基于antlr框架对 sql解析,生 ...
- 3、myql的逻辑架构和sql的执行流程
msyql逻辑架构 逻辑架构的解析 逻辑架构图如下(序号代表的是:服务器处理客户端请求的流程) 1.1connectors connectors是指使用不同语言的客户端与mysql server服务器 ...
随机推荐
- luogu1726 上白泽慧音
题目大意 求一个有向图含节点数最多且结点编号从小到大排列字典序最小的强连通分量. 注意事项 HDU1269那道题题面.数据太弱,在这道题上把我害惨了... Dfs点u时,如果与u相连的一个点v有Dfs ...
- 88. [ExtJS2.1教程-5]ToolBar(工具栏)
转自:https://llying.iteye.com/blog/324681 面板中可以有工具栏,工具栏可以位于面板顶部或底部,Ext中工具栏是由Ext.Toolbar类来表示.工具栏上可以放按钮. ...
- Python中的math和保留小数位数方法
转载自 http://xukaizijian.blog.163.com/blog/static/17043311920111163272414/ math模块实现了许多对浮点数的数学运算函数. 这些 ...
- java 格式化日期
SimpleDateFormat simpleDateFormat=new SimpleDateFormat("yyyy-MM-dd HH:mm:ss"); simpleDat ...
- js返回16位随机数
public string GetDataRandom() { string strData=DateTime.Now.ToString(); ...
- git clone 出现错误
看了好多资料终于搞定了git 中clone命令报错这个问题,废话不多说直接上步骤希望对大家有帮助. 1 删除.ssh文件夹(直接搜索该文件夹)下的known_hosts(手动删除即可,不需要git ...
- JPA新增entity时自动填充时间,例创建时间,修改时间
背景:springboot项目,集成JPA,与数据库交互的entity,与用户交互的DTO 问题:添加酒店时,两个字段create_time,update_time,前端不传数据,如果赋值 解决: 1 ...
- 快速搭建ELK集中化日志管理平台
由于我们的项目是分布式,服务分布于多个服务器上,每次查看日志都要登录不同服务器查看,而且查看起来还比较麻烦,老大让搭一个集中化日志管理的东西,然后就在网上找到了这个东西ELK ELK就是elastic ...
- Blender之UILayout
目标 [x] 总结Blender面板布局 总结 Blender面板中界面组件是通过UILayout进行组织的. 其主要属性如下: row() 定义横向子布局. column() 定义竖向子布局. sp ...
- HBase编程 API入门系列之get(客户端而言)(2)
心得,写在前面的话,也许,中间会要多次执行,连接超时,多试试就好了. 前面是基础,如下 HBase编程 API入门系列之put(客户端而言)(1) package zhouls.bigdata.Hba ...