MapReduce 经典案例手机流量排序的分析
在进行流量排序之前,先要明白排序是发生在map阶段,排序之后(排序结束后map阶段才会显示100%完成)才会到reduce阶段(事实上reduce也会排序),.此外排序之前要已经完成了手机流量的统计工作,即把第一次mr的结果作为本次排序的输入.也就是说读取的数据格式为 手机号 上行流量 下行流量 总流量
1,map阶段,读取并封装流量信息,不同的是context.write()时key必须是封装的实体类,而不再是手机号
/**
* 输入key 行号
* 输入value 流量信息
* 输出key 封装了流量信息的FlowBean
* 输出value 手机号
* @author tele
*
*/
public class FlowSortMapper extends Mapper<LongWritable,Text,FlowBean,Text>{
FlowBean flow = new FlowBean();
Text v = new Text();
//读取的内容格式 手机号 上行流量 下行流量 总流量
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, FlowBean, Text>.Context context)
throws IOException, InterruptedException { //1.读取
String line = value.toString(); //2.切割
String[] split = line.split("\t");
String upFlow = split[1];
String downFlow = split[2];
String phoneNum = split[0]; //3.封装流量信息
flow.set(Long.parseLong(upFlow),Long.parseLong(downFlow)); v.set(phoneNum); //4.写出
context.write(flow,v); }
}
2.map之后会根据key进行排序,因此如果要实现自定义排序,必须让定义的bean实现WritableComparable接口,并重写其中的compare方法,我们只需要告诉MapReduce根据什么排序,升序还是降序就可以了
具体的排序过程由MapReduce完成
public class FlowBean implements WritableComparable<FlowBean>{
private long upFlow;
public long getUpFlow() {
return upFlow;
}
public void setUpFlow(long upFlow) {
this.upFlow = upFlow;
}
public long getDownFlow() {
return downFlow;
}
public void setDownFlow(long downFlow) {
this.downFlow = downFlow;
}
public long getSumFlow() {
return sumFlow;
}
public void setSumFlow(long sumFlow) {
this.sumFlow = sumFlow;
}
private long downFlow;
private long sumFlow;
/**
* 反序列化时需要通过反射调用空参构造方法.必须有空参构造
*/
public FlowBean() {
super();
}
public FlowBean(long upFlow, long downFlow) {
super();
this.upFlow = upFlow;
this.downFlow = downFlow;
this.sumFlow = upFlow + downFlow;
}
public void set(long upFlow, long downFlow) {
this.upFlow = upFlow;
this.downFlow = downFlow;
this.sumFlow = upFlow + downFlow;
}
/**
* 序列化与反序列化顺序必须一致
*/
//序列化
@Override
public void write(DataOutput output) throws IOException {
output.writeLong(upFlow);
output.writeLong(downFlow);
output.writeLong(sumFlow);
}
//反序列化
@Override
public void readFields(DataInput input) throws IOException {
upFlow = input.readLong();
downFlow = input.readLong();
sumFlow = input.readLong();
}
/**
* reduce context.write()会调用此方法
*/
@Override
public String toString() {
return upFlow + "\t" + downFlow + "\t" + sumFlow;
}
@Override
public int compareTo(FlowBean o) {
// -1表示不交换位置,即降序,1表示交换位置,升序
return this.sumFlow > o.getSumFlow() ? -1:1;
}
}
3.reduce阶段,map阶段会对输出的value根据key进行分组,具有相同key的value会被划分到一组,这样reduce阶段执行一次reduce()读取一组,由于map阶段输出的key是定义的FlowBean,因此key是唯一的,从而
每组只有一个值,即Iterable<Text> value中只有一个值,也就是只有一个手机号
/**
* 输出的格式仍然为 手机号 上行流量 下行流量 总流量
* @author tele
*
*/
public class FlowSortReducer extends Reducer<FlowBean,Text,Text,FlowBean>{
/**
* reduce阶段读入的仍然是一组排好序的数据
* 前面map阶段输出的结果已根据key(FlowBean)进行分组,但由于此处key的唯一
* 所以一组只有一个数据,即 Iterable<Text> value 中只有一个值
*/
@Override
protected void reduce(FlowBean key, Iterable<Text> value, Reducer<FlowBean, Text, Text, FlowBean>.Context context)
throws IOException, InterruptedException { //输出
Text phone = value.iterator().next();
context.write(phone,key); }
}
下面进行debug,在map(),reduce()方法的开始与结束均打上断点,在FlowBean的compareTo()中也打上断点
map读取的内容
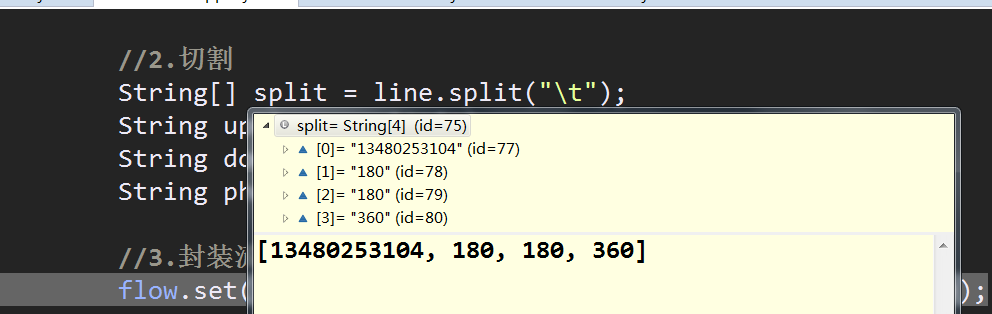
写出,注意key是FlowBean对象
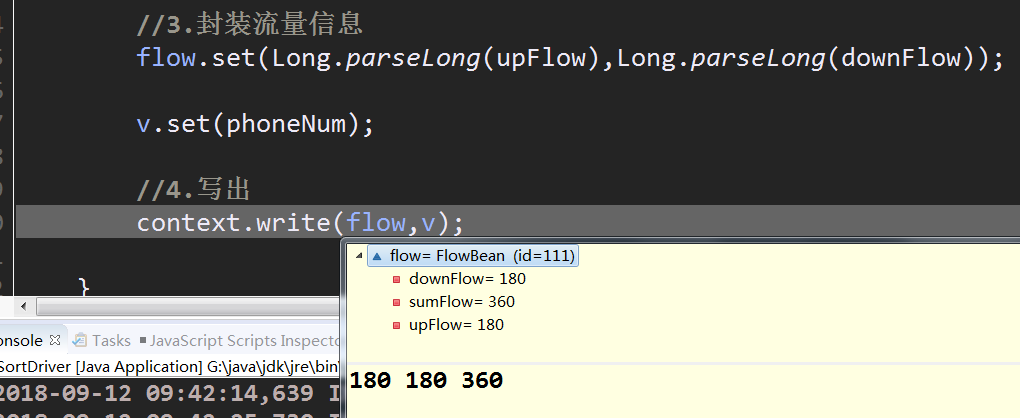
接下来是排序,可以看到排序时map仍然不是100%,也就是说map阶段进行了排序(reduce阶段也会进行排序)

排序之后进入reduce阶段,reduce时write会调用FlowBean的toString()把结果输出到磁盘上
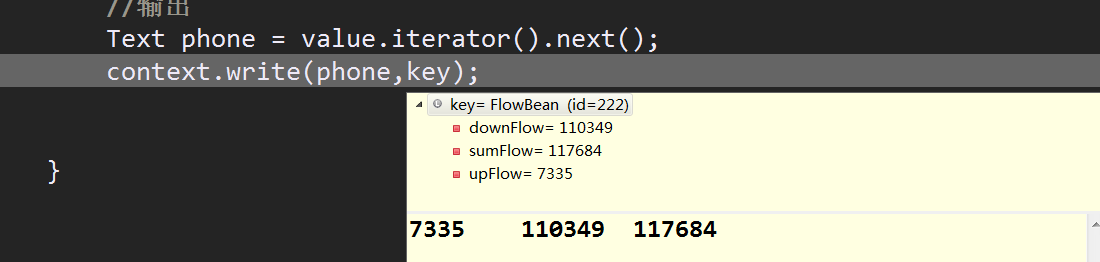

reduce除了归并排序之外,在执行write时同样会进行一次排序,执行第一组的write,(会调用FlowBean的toString()).但接下来还会去执行compareTo方法,此时在磁盘上生成的是临时目录,并且生成的part000文件是0KB,在执行完第二组的write之后才会真正把第一组数据写出到磁盘上
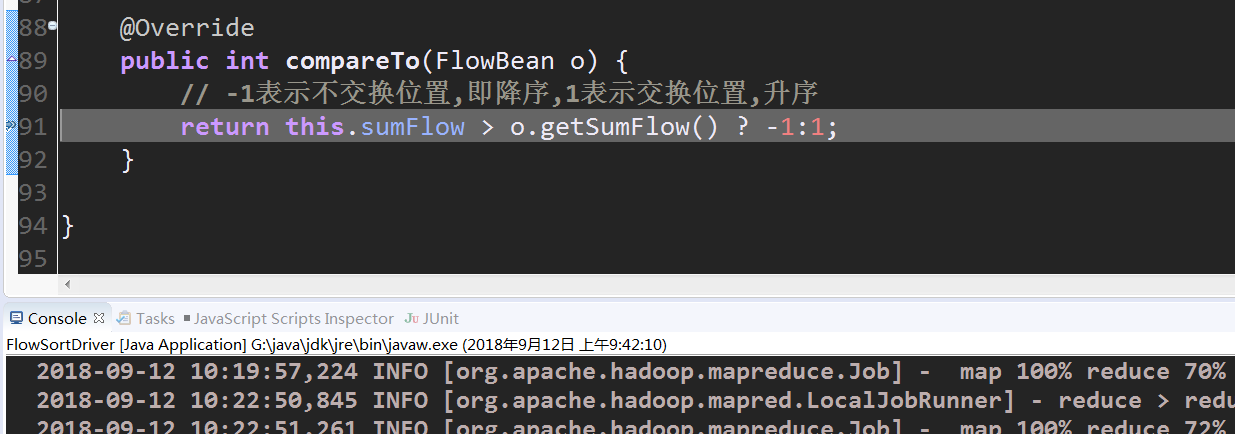


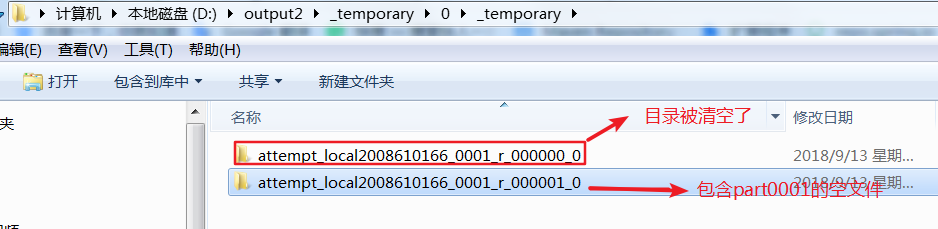
part000此时有了数据
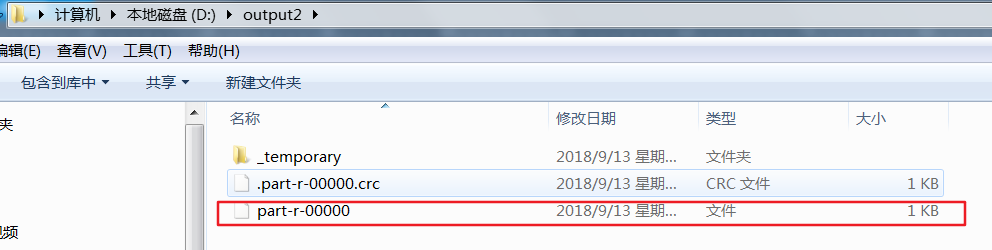
这样看来我们重写的compareTo方法无论在map阶段还是reduce阶段都被调用了
MapReduce 经典案例手机流量排序的分析的更多相关文章
- Hadoop Mapreduce 案例 wordcount+统计手机流量使用情况
mapreduce设计思想 概念:它是一个分布式并行计算的应用框架它提供相应简单的api模型,我们只需按照这些模型规则编写程序,即可实现"分布式并行计算"的功能. 案例一:word ...
- 第2节 mapreduce深入学习:9、手机上行流量排序
还是上次那个例子,需求二:上行流量倒序排序(递减排序) 分析,以需求一的输出数据作为排序的输入数据,自定义FlowBean,以FlowBean为map输出的key,以手机号作为Map输出的value, ...
- 023_数量类型练习——Hadoop MapReduce手机流量统计
1) 分析业务需求:用户使用手机上网,存在流量的消耗.流量包括两部分:其一是上行流量(发送消息流量),其二是下行流量(接收消息的流量).每种流量在网络传输过程中,有两种形式说明:包的大小,流量的大小. ...
- 阿里云资深DBA专家罗龙九:云数据库十大经典案例分析【转载】
阿里云资深DBA专家罗龙九:云数据库十大经典案例分析 2016-07-21 06:33 本文已获阿里云授权发布,转载具体要求见文末 摘要:本文根据阿里云资深DBA专家罗龙九在首届阿里巴巴在线峰会的&l ...
- 第2节 mapreduce深入学习:8、手机流量汇总求和
第2节 mapreduce深入学习:8.手机流量汇总求和 例子:MapReduce综合练习之上网流量统计. 数据格式参见资料夹 需求一:统计求和 统计每个手机号的上行流量总和,下行流量总和,上行总流量 ...
- Linux运维之道(大量经典案例、问题分析,运维案头书,红帽推荐)
Linux运维之道(大量经典案例.问题分析,运维案头书,红帽推荐) 丁明一 编 ISBN 978-7-121-21877-4 2014年1月出版 定价:69.00元 448页 16开 编辑推荐 1 ...
- 小记--------spark-Wordcount经典案例之对结果根据词频进行倒序排序
还是以经典案例Wordcount为例: 逻辑思路: 1.先把文本按空格切分成每个单词 flatMap() 2.将每个单词都转换成Tuple2类型(hello ,1) map() 3.将 ...
- 猴子吃桃问题之《C语言经典案例分析》
猴子吃桃问题之<C语言经典案例分析>一.[什么是猴子吃桃] 猴子吃桃问题:猴子第一天摘下若干个桃子,当即吃了一半,还不过瘾,又多吃了一个.第二天早上又将第一天剩下的桃子吃掉一半 ...
- MapReduce应用案例--简单排序
1. 设计思路 在MapReduce过程中自带有排序,可以使用这个默认的排序达到我们的目的. MapReduce 是按照key值进行排序的,我们在Map过程中将读入的数据转化成IntWritable类 ...
随机推荐
- 13. 关于IDEA工具在springboot整合mybatis中出现的Invalid bound statement (not found)问题
在一切准备就绪之后,测试test,却出现了org.apache.ibatis.binding.BindingException: Invalid bound statement (not found) ...
- jquery的滚动事件
$(selector).scroll(function);当滚动到合适的条件下,就触发某个函数. 现在基本就是前端利用AJAX对数据进行拼接操作,渲染进html的DOM结构中.
- @EnableAsync和@Async开始异步任务支持
Spring通过任务执行器(TaskExecutor)来实现多线程和并发编程.使用ThreadPoolTaskExecutor可实现一个基于线程池的TaskExecutor.在开发中实现异步任务,我们 ...
- GTK入门学习:glade的使用
搭建好环境后,在终端敲 glade 就可以启动glade工具. glade的总体框图: 经常使用控件选择区:列举了经常使用的控件,经常使用的有三类:顶层(主窗体等).容器(各种布局容器等).控制和显示 ...
- swift项目第五天:swift中storyBoard Reference搭建主界面
一:StoryBoard Reference的介绍 StoryBoard Reference是Xcode7,iOS9出现的新功能 目的是让我们可以更好的使用storyboard来开发项目 在之前的开发 ...
- swift项目第三天:手写代码搭建主框架
一:先配置环境:自定义Log输出(DEBUG 和 release模式),并屏蔽后台多余的打印信息 1:屏蔽后台多余的打印信息:如果写了OS_ACTIVITY_MODE = disable 还是不行.把 ...
- 安装hadoop2.6.0伪分布式环境 分类: A1_HADOOP 2015-04-27 18:59 409人阅读 评论(0) 收藏
集群环境搭建请见:http://blog.csdn.net/jediael_lu/article/details/45145767 一.环境准备 1.安装linux.jdk 2.下载hadoop2.6 ...
- iOS数据存储简要笔记
1. 数据存储常用的方式 (1)XML 属性列表(plist)归档 (2)preference(偏好设置) (3)NSKeyedArchiver归档(NSCoding) (4) SQLite3 ...
- [Angular2 Form] Validation message for Reactive form
<div class="form-field"> <label>Confirm Password: </label> <input typ ...
- C語言 rand函数 进阶探讨与实现
C语言中随机函数应用 可能大家都知道C语言中的随机函数random,但是random函数并非ANSI C标准,所以说.random函数不能在gcc,vc等编译器下编译通过. 那么怎么实现 ...