算法导论————EXKMP
【例题传送门:caioj1461】
【EXKMP】最长共同前缀长度
【题意】
给出模板串A和子串B,长度分别为lenA和lenB,要求在线性时间内,对于每个A[i](1<=i<=lenA),求出A[i..lenA]与B的最长公共前缀长度
【输入文件】
输入A,B两个串,(lenB<=lenA<=1000000)
【输出文件】
输出lenA个数,表示A[i...lenA]与B的最长公共前缀长度,每个数之前有空格
【样例输入】
aabbabaaab
aabb
【样例输出】
4 1 0 0 1 0 2 3 1 0
算法分析:
学EXKMP前,必须将KMP学透,如果仍未学KMP,请出门左转【传送门】
我们在KMP算法中可以理解,p数组是KMP的核心,p[i]代表着以i为结尾和以开头为首的最长公共子串长度,也就是说对于st字符串数组的p[i]代表的就是st字符串数组从1开始到p[i]和从i-p[i]+1到i是完全相同的(st[1...p[i]]=st[i-p[i]+1...i])
那么扩展KMP就高级了。一样还是p数组(还是原来的配方,还是熟悉的味道!),但是既然是扩展KMP就不要用p,我就改成extend数组了,表示的意义与普通KMP就大有不同。extend[i]表示的是以i为首和以开头为首的最长前缀,也就是说对于st字符串数组中的extend[i]表示的就是st字符串数组从1开始到extend[i]和从i到i+extend[i]-1是完全相同的(st[1...extend[i]]=st[i...i+extend[i]-1])
首先extend[1]就不用说了,直接等于len这个没有问题吧,那么因为extend[1]这个是具有一定性,所以我们基本把这东西废掉..那么我们就直接从extend[2]开始。然后我们就定义一个k,这个k表示的就是在当前搜索过的范围以内(因为这是线性算法,所以是从1到len)能到达最远(也就是说k+extend[k]-1最大的)的编号,为什么要定义一个这样子的东西,等下你们就知道了。
我们先定义一个p,让它等于k+extend[k]-1,那么由extend这个数组的定义我们就可以得到一个等式:st[1...extend[k]]=st[k...p]。因为p=k+extend[k]-1,所以我们又可以得到一条等式:extend[k]=p-k+1,把这个代换到上一条等式上,就会——瞬间爆炸!(好吧开个玩笑..)就会变成:st[1...p-k+1]=st[k...p],如下图:
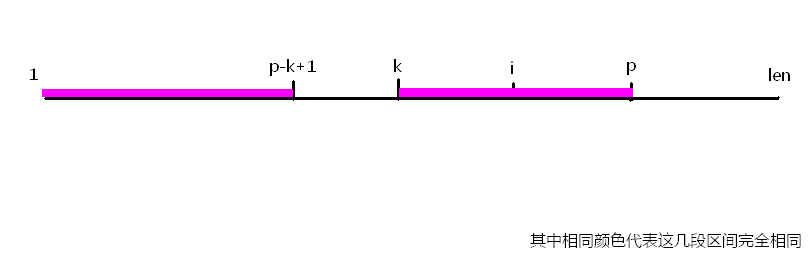
因为我们现在要求从extend[i],那么由上面这条等式又可以得到另一条等式:st[i-k+1...p-k+1]=st[i...p],如下图: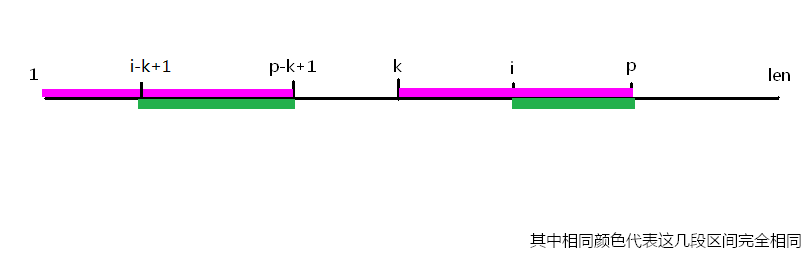
在看此证明过程中请各位一直记住extend数组所表达的含义,不然会有很多地方不懂的。那么我们再定义一个L=extend[i-k+1],我们又可以得到一条等式:st[i-k+1...i-k+L](注意:本来得到的应该是i-k+1+L-1,我直接把+1-1省略了)=st[1...L],如下图:

这个时候有人就会问了:为什么你上面的图不和前几个合在一起呢?这个就是本算法的一个难点了!因为L的不定性,这个时候我们需要考虑i-k+L和p-k+1的大小!那我们就来分开来考虑。
(1)i-k+L<p-k+1,如下图:

从上图我们可以看到因为st[1...L]=st[i-k+1...i-k+L],st[i-k+1...p-k+1]=st[i...p],所以在st[i...p]中肯定含有一段(从i开始)和st[1...L]是完全相同的,也就是上图标出来的蓝色部分st[i...i+L-1]。因为st[i-k+1...p-k+1]=st[i...p]又因为i-k+L<p-k+1,所以我们又可以得到:st[i-k+L+1]=st[i+L](也就是上图所标的黄色位置),而因为extend[i-k+1]的定义,所以st[L+1](也就是上图所标棕色位置)!=st[i-k+L+1],所以我们可以得到:st[i+L]!=st[L+1],那么extend[i]就直接等于L了。
(2)i-k+L>p-k+1,如下图:
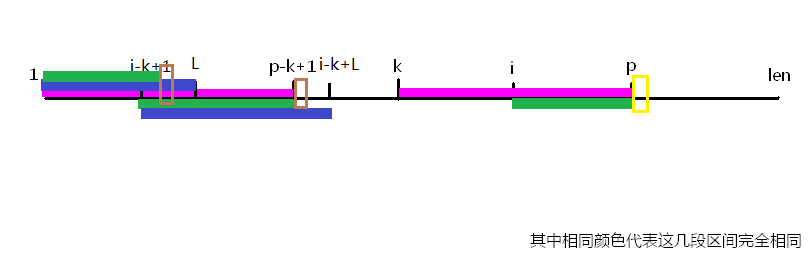
从上图中我们看到因为st[1...L]=st[i-k+1...i-k+L],又因为i-k+L>p-k+1,所以在st[1...L]中肯定含有一段和st[i-k+1...p-k+1]完全相同的(图中绿色部分)。因为extend[k]的意义,所以st[p+1]!=st[p-k+2](图中第二个棕色和黄色位置,为什么不相同不用解释吧),又因为st[1...L]=st[i-k+1...i-k+L],所以st[p-i+2](图中并未标出,第一个棕色位置)=st[p-k+2],那么就会得到:st[p-i+2]!=st[p+1],所以extend[i]就等于p-i+1了。
(3)i-k+L=p-k+1,如下图:
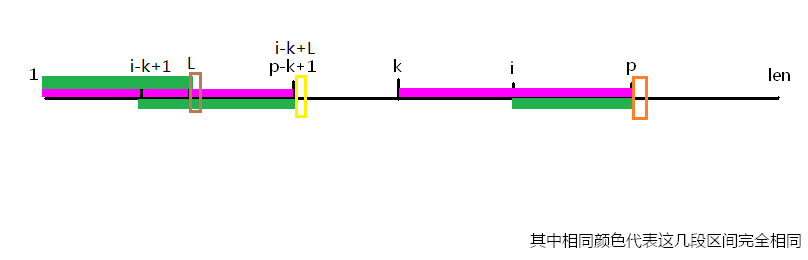
从上图我们可以发现因为st[i-k+1...i-k+L]=st[1..L],st[i-k+1...p-k+1]=st[i...p],又因为i-k+L=p-k+1,所以st[1...L]=st[i-k+1...p-k+1(可换成i-k+L)]=st[i...p](也就是指上图中三段绿色部分)。那么由于extend[i-k+1]和extend[k]的意义表达,我们可以得到:st[L+1]!=st[i-k+L+1],st[i-k+L+1]!=st[p+1],但是我们不能确定st[L+1]和st[p+1]是否相同,我们只能确定从i开始和从1开始有p-i+1这么长的公共前缀但并不一定是最长的(这句话要好好理解,这很重要)。
那么我们就设一个变量j=p-i+1,表示当前从i开始和从1开始的公共前缀长度,由于上面加粗的那句话,我们可以直接从st[j+1]和st[i+j]来累加j的值来得出最长的公共前缀。
注意事项:
因为p是一个不定的数(由k和extend[k]来定),所以说有可能p-i+1是有可能为负数,那么第二种情况显然不对,公共前缀怎么样也不能等于负数吧,最小也会是0吧!这个时候也许你就会冒出一个想法,在第二种情况下取p-i+1和0的最大值。很显然这是不对的。请看下图:

从上图我们可以发现,因为p-i+1是负数,所以上面所有条件都用不了,因为对i后面的字符没有作任何的计算,但这个时候是绝对不可以肯定st[1]和st[i]是不同的(也就是最长公共前缀为0),那么我们需要从st[1]和st[i]开始继续判断后面的字符是否相同。于是我们把第二种情况和第三种情况归纳为一种情况,因为两者都是要暴力处理未知的点,只是起始点不同
这仅仅是求extend数组的证明,也仅仅是在同一个字符串里的基本操作,接下来我就来讲下扩展KMP(简称EXKMP)的实际用途。EXKMP主要是利用于解决处理两个字符串的最长公共前缀长度,假如A是主串,B是副串,那么这时我们定义一个ex数组,ex[i]就表示A[i...Alen]和B[1...Blen]的最长公共前缀长度(这个概念需要好好注意)
其实在处理两者的匹配时,只需要注意将A串中的子串转移到B串中进行处理,那么这样我们实际上在求ex数组时,操作仍与上面的步骤相似
参考代码:
#include<cstdio>
#include<cstring>
#include<cstdlib>
#include<algorithm>
#include<cmath>
using namespace std;
char sa[],sb[];
int lena,lenb;
int p[],ex[];
//p数组是用来让B串自己匹配自己的
void exkmp()
{
p[]=lenb;
int x=;
while(sb[x]==sb[x+]&&x+<=lenb) x++;//因为我们p[1]是具有一定性,所以我们不能直接用,所以要先暴力求出p[2]
p[]=x-;
int k=;
for(int i=;i<=lenb;i++)
{
int pp=k+p[k]-,L=p[i-k+];//pp实际上是p
if(i+L<pp+) p[i]=L;//i-k+L<pp-k+1化简后i+L<pp
else
{
int j=pp-i+;
if(j<) j=;
while(sb[j+]==sb[i+j]&&i+j<=lenb) j++;
p[i]=j;
k=i;
}
}
x=;
while(sa[x]==sb[x]&&x<=lenb) x++;//ex[1]并不具有一定性,所以我们暴力求出ex[1]
ex[]=x-;
k=;
for(int i=;i<=lena;i++)
{
int pp=k+ex[k]-,L=p[i-k+];
if(i+L<pp+) ex[i]=L;
else
{
int j=pp-i+;
if(j<) j=;
while(sb[j+]==sa[i+j]&&i+j<=lena&&j<=lenb) j++;
ex[i]=j;
k=i;
}
}
}
int main()
{
scanf("%s%s",sa+,sb+);
lena=strlen(sa+);lenb=strlen(sb+);
exkmp();
for(int i=;i<lena;i++) printf("%d ",ex[i]);
printf("%d\n",ex[lena]);
return ;
}
算法导论————EXKMP的更多相关文章
- B树——算法导论(25)
B树 1. 简介 在之前我们学习了红黑树,今天再学习一种树--B树.它与红黑树有许多类似的地方,比如都是平衡搜索树,但它们在功能和结构上却有较大的差别. 从功能上看,B树是为磁盘或其他存储设备设计的, ...
- 红黑树——算法导论(15)
1. 什么是红黑树 (1) 简介 上一篇我们介绍了基本动态集合操作时间复杂度均为O(h)的二叉搜索树.但遗憾的是,只有当二叉搜索树高度较低时,这些集合操作才会较快:即当树的高度较高(甚至一种极 ...
- 基本数据结构(2)——算法导论(12)
1. 引言 这一篇博文主要介绍链表(linked list),指针和对象的实现,以及有根树的表示. 2. 链表(linked list) (1) 链表介绍 我们在上一篇中提过,栈与队 ...
- 堆排序与优先队列——算法导论(7)
1. 预备知识 (1) 基本概念 如图,(二叉)堆是一个数组,它可以被看成一个近似的完全二叉树.树中的每一个结点对应数组中的一个元素.除了最底层外,该树是完全充满的,而且从左向右填充.堆的数组 ...
- quickSort算法导论版实现
本文主要实践一下算法导论上的快排算法,活动活动. 伪代码图来源于 http://www.cnblogs.com/dongkuo/p/4827281.html // imp the quicksort ...
- [算法导论]二叉查找树的实现 @ Python
<算法导论>第三版的BST(二叉查找树)的实现: class Tree: def __init__(self): self.root = None # Definition for a b ...
- 算法导论第十八章 B树
一.高级数据结构 本章以后到第21章(并查集)隶属于高级数据结构的内容.前面还留了两章:贪心算法和摊还分析,打算后面再来补充.之前的章节讨论的支持动态数据集上的操作,如查找.插入.删除等都是基于简单的 ...
- 算法导论----VLSI芯片测试; n个手机中过半是好的,找出哪些是好手机
对于分治(Divide and Conquer)的题目,最重要是 1.如何将原问题分解为若干个子问题, 2.子问题中是所有的都需要求解,还是选择一部分子问题即可. 还有一点其实非常关键,但是往往会被忽 ...
- [置顶] 《算法导论》习题解答搬运&&学习笔记 索引目录
开始学习<算法导论>了,虽然是本大部头,可能很难一下子看完,我还是会慢慢地研究的. 课后的习题和思考有些是很有挑战性的题目,我等蒻菜很难独立解决. 然后发现了Google上有挺全的algo ...
随机推荐
- css 遮照镂空效果
实现这个效果有以下几种方式.(欢迎指出不足之处!!!) 一:最简单最粗暴的方法!截图! 实现原理:先截一张图片,然后写一个遮罩层,再把图片放上去就可以了! 过程过于简单,就别写代码跟截图效果了! 优 ...
- [洛谷P3982]龙盘雪峰信息解析器
题目大意:给你一串代码,要求进行解码.解码规则详见题目. 解题思路:这是一道字符串处理的题目. 首先,有这么几种情况输出Error: 1.代码中出现除了0和1外的字符. 2.代码长度不是8的倍数. 3 ...
- c traps and pitfalls reading note(1)
1. 一直知道char *p = 'a';这样写是错误的,但是为什么是错的,没想过,今天看书解惑. p指向一个字符,但是在c中,''引起来的一个字符代表一个整数,这样指针能不报错.o(^▽^)o 2. ...
- asp.net C# 获取网页源代码的几种方式
1 方法 System.Net.WebClient aWebClient = new System.Net.WebClient(); aWebClient.Encoding = System.Text ...
- POJ 3122 Pie 二分答案
题意:给你n个派,每个派都是高为一的圆柱体,把它等分成f份,每份的最大体积是多少. 思路: 明显的二分答案题-- 注意π的取值- 3.14159265359 这样才能AC,,, //By Sirius ...
- BootStrap--from 表单
1 垂直表单(默认) 2 内联表单 3 水平表单 使用 class .sr-only,您可以隐藏内联表单的标签. 垂直或基本表单 基本的表单结构是 Bootstrap 自带的,个别的表单控件自动接收一 ...
- POJ 2251 Dungeon Master【BFS】
题意:给出一个三维坐标的牢,给出起点st,给出终点en,问能够在多少秒内逃出. 学习的第一题三维的广搜@_@ 过程和二维的一样,只是搜索方向可以有6个方向(x,y,z的正半轴,负半轴) 另外这一题的输 ...
- 如何知道 CPU 是否支持虚拟化技术(VT)
作者: Sk 译者: LCTT geekpi 我们已经知道如何检查你的 Linux 操作系统是 32 位还是 64 位以及如何知道你的 Linux 系统是物理机还是虚拟机.今天,我们将学习另一个有用的 ...
- vue的鼠标移入和移出
vue的鼠标移入和移出 需求(鼠标到预约二维码显示,预约添加背景色) 实现 <!--html部分--> <ul class="person_list"> / ...
- caioj 1072 动态规划入门(二维一边推5:最长公共子序列 LCSS加强版)
在51nod刷到过同样的题,直接秒杀 见https://blog.csdn.net/qq_34416123/article/details/81697683 #include<cstdio> ...