HDFS的数据流读写数据 (面试开发重点)
1 HDFS写数据流程
1.1 剖析文件写入
HDFS写数据流程,如图所示
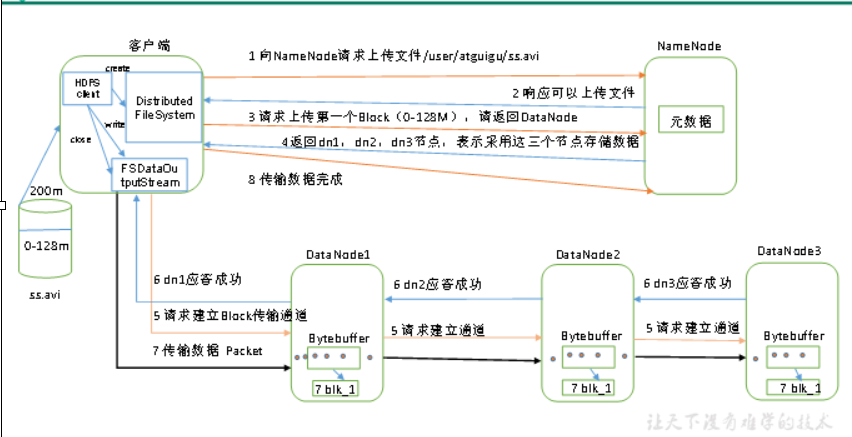
1)客户端通过Distributed FileSystem模块向NameNode请求上传文件,NameNode检查目标文件是否已存在,父目录是否存在。
2)NameNode返回是否可以上传。
3)客户端请求第一个 Block上传到哪几个DataNode服务器上。
4)NameNode返回3个DataNode节点,分别为dn1、dn2、dn3。
5)客户端通过FSDataOutputStream模块请求dn1上传数据,dn1收到请求会继续调用dn2,然后dn2调用dn3,将这个通信管道建立完成。
6)dn1、dn2、dn3逐级应答客户端。
7)客户端开始往dn1上传第一个Block(先从磁盘读取数据放到一个本地内存缓存),以Packet为单位,dn1收到一个Packet就会传给dn2,dn2传给dn3;dn1每传一个packet会放入一个应答队列等待应答。
8)当一个Block传输完成之后,客户端再次请求NameNode上传第二个Block的服务器。(重复执行3-7步)。
1.2 网络拓扑-节点距离计算
在HDFS写数据的过程中,NameNode会选择距离待上传数据最近距离的DataNode接收数据。那么这个最近距离怎么计算呢?
节点距离:两个节点到达最近的共同祖先的距离总和。
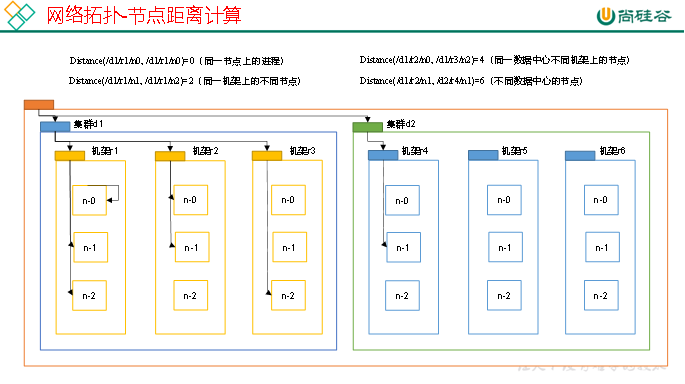
例如,假设有数据中心d1机架r1中的节点n1。该节点可以表示为/d1/r1/n1。利用这种标记,这里给出四种距离描述,如上图所示。
大家算一算每两个节点之间的距离,如下图所示。

1.3 机架感知(副本存储节点选择)
1. 官方ip地址
- For the common case, when the replication factor is three, HDFS’s placement policy is to put one replica on one node in the local rack, another on a different node in the local rack, and the last on a different node in a different rack.
2. Hadoop2.7.2副本节点选择

4.2 HDFS读数据流程
HDFS的读数据流程,如图所示。
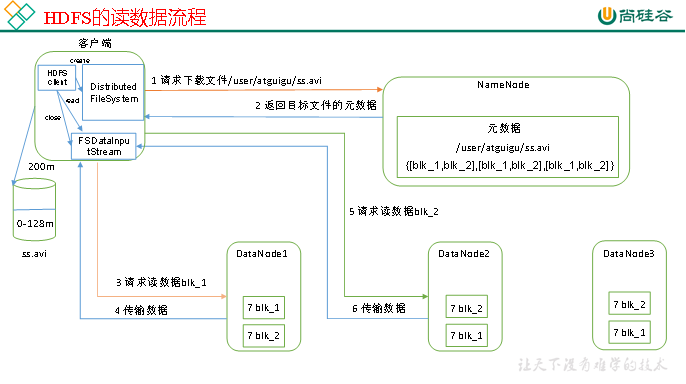
1)客户端通过Distributed FileSystem向NameNode请求下载文件,NameNode通过查询元数据,找到文件块所在的DataNode地址。
2)挑选一台DataNode(就近原则,然后随机)服务器,请求读取数据。
3)DataNode开始传输数据给客户端(从磁盘里面读取数据输入流,以Packet为单位来做校验)。
4)客户端以Packet为单位接收,先在本地缓存,然后写入目标文件。
HDFS的数据流读写数据 (面试开发重点)的更多相关文章
- NameNode和SecondaryNameNode(面试开发重点)
NameNode和SecondaryNameNode(面试开发重点) 1 NN和2NN工作机制 思考:NameNode中的元数据是存储在哪里的? 首先,我们做个假设,如果存储在NameNode节点的磁 ...
- DataNode(面试开发重点)
1 DataNode工作机制 DataNode工作机制,如图所示. 1)一个数据块在DataNode上以文件形式存储在磁盘上,包括两个文件,一个是数据本身,一个是元数据包括数据块的长度,块数据的校验和 ...
- HDFS读写数据块--${dfs.data.dir}选择策略
最近工作需要,看了HDFS读写数据块这部分.不过可能跟网上大部分帖子不一样,本文主要写了${dfs.data.dir}的选择策略,也就是block在DataNode上的放置策略.我主要是从我们工作需要 ...
- Hadoop基础-HDFS集群中大数据开发常用的命令总结
Hadoop基础-HDFS集群中大数据开发常用的命令总结 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 本盘博客仅仅列出了我们在实际生成环境中常用的hdfs命令,如果想要了解更多, ...
- C# .Net 多进程同步 通信 共享内存 内存映射文件 Memory Mapped 转 VC中进程与进程之间共享内存 .net环境下跨进程、高频率读写数据 使用C#开发Android应用之WebApp 分布式事务之消息补偿解决方案
C# .Net 多进程同步 通信 共享内存 内存映射文件 Memory Mapped 转 节点通信存在两种模型:共享内存(Shared memory)和消息传递(Messages passing). ...
- 面试系列二:精选大数据面试真题JVM专项-附答案详细解析
公众号(五分钟学大数据)已推出大数据面试系列文章-五分钟小面试,此系列文章将会深入研究各大厂笔面试真题,并根据笔面试题扩展相关的知识点,助力大家都能够成功入职大厂! 大数据笔面试系列文章分为两种类型: ...
- Hadoop(八)Java程序访问HDFS集群中数据块与查看文件系统
前言 我们知道HDFS集群中,所有的文件都是存放在DN的数据块中的.那我们该怎么去查看数据块的相关属性的呢?这就是我今天分享的内容了 一.HDFS中数据块概述 1.1.HDFS集群中数据块存放位置 我 ...
- .net环境下跨进程、高频率读写数据
一.需求背景 1.最近项目要求高频次地读写数据,数据量也不是很大,多表总共加起来在百万条上下. 单表最大的也在25万左右,历史数据表因为不涉及所以不用考虑, 难点在于这个规模的热点数据,变化非常频繁. ...
- Python中异常和JSON读写数据
异常可以防止出现一些不友好的信息返回给用户,有助于提升程序的可用性,在java中通过try ... catch ... finally来处理异常,在Python中通过try ... except .. ...
随机推荐
- 推荐一款技术人必备的接口测试神器:Apifox
1. 背景 作为互联网行业技术从业者,接口调试是必不可少的一项技能,通常我们都会选择使用 Postman 这类工具来进行接口调试,在接口调试方面 Postman 做的确实非常出色.当然除了Postma ...
- PHP array_map() 函数
实例 将函数作用到数组中的每个值上,每个值都乘以本身,并返回带有新的值的数组: <?phpfunction myfunction($v){return($v*$v);} $a=array(1,2 ...
- PHP idate() 函数
------------恢复内容开始------------ 实例 格式化本地时间/日期为整数.测试所有不同的格式: <?phpecho idate("B") . " ...
- PHP convert_uuencode() 函数
实例 编码字符串: <?php$str = "Hello world!";echo convert_uuencode($str);?>高佣联盟 www.cgewang. ...
- Skill 脚本演示 ycAlignAll.il
https://www.cnblogs.com/yeungchie/ ycAlignAll.il 将版图整体对齐至 指定象限 / 原点,可以忽略 Label 干扰带来的 offGrid 的风险. 回到 ...
- win10 64位 汇编环境
masm6或者masm5 下载. dosbox 下载安装 为何要用这个呢,因为 机子是64位的,dosbox 模拟32位的用来执行生成的exe文件 masm 安装好后,有个bin文件:个人建议将其设置 ...
- Elasticsearch权威指南(中文版)
Elasticsearch权威指南(中文版) 下载地址: https://pan.baidu.com/s/1bUGJmwS2Gp0B32xUyXxCIw 扫码下面二维码关注公众号回复100010 获取 ...
- Docker 快速搭建 MySQL8 开发环境
使用 Docker 快速搭建一个 MySQL8 开发环境 步骤 获取镜像 docker pull mysql:8 启动容器,密码 123456,映射 3306 端口 docker run --name ...
- Bytom DAPP 开发流程
从目前已经发布的DAPP来看,DAPP架构大致可以分成3种类型:插件钱包模式.全节点钱包模式和兼容模式. 插件钱包模式是借助封装了钱包的浏览器插件通过RPC协议与区块链节点通信,插件在运行时会将Web ...
- 咕咕咕清单(SCOI2020前)
本篇博客已停更 本篇博客已停更 本篇博客已停更 吐槽区: 2020.04.15: 从今天起我做过的题目都记录一下,想不想写题解就另说了 2020.04.17: 写了两天之后真实的发现这是博主的摸鱼日记 ...