WebRTC的VAD 过程解读
摘要:
在上一篇的文档中,分析unimrcp中vad算法的诸多弊端,但是有没有一种更好的算法来取代呢。目前有两种方式 1. GMM 2. DNN。
其中鼎鼎大名的WebRTC VAD就是采用了GMM 算法来完成voice active dector。今天笔者重点介绍WebRTC VAD算法。在后面的文章中,
我们在刨析DNN在VAD的中应用。下面的章节中,将介绍WebRTC的检测原理。
原理:
首先呢,我们要了解一下人声和乐器的频谱范围,下图是音频的频谱。
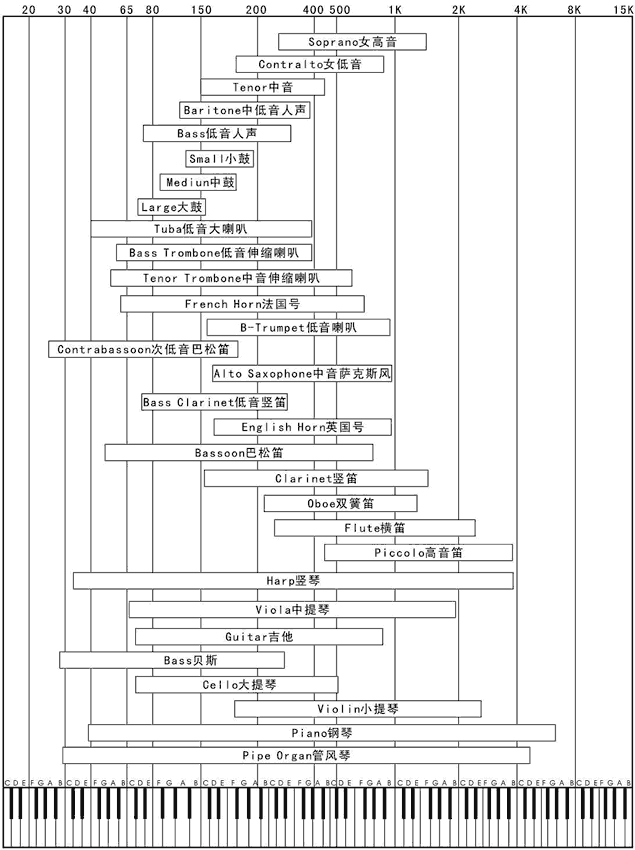
本图来源于网络
根据音频的频谱划分了6个子带,80Hz~250Hz,250Hz~500Hz,500Hz~1K,1K~2K,2K~3K,3K~4K,分别计算出每个子带的特征。
步骤:
1. 准备工作
1.1 WebRTC的检测模式分为了4种:
0: Normal, 1. low Bitrate 2.Aggressive 3. Very Aggressive ,其激进程序与数值大小相关,可以根据实际的使用在初始化的时候可以配置。
// Set aggressiveness mode
int WebRtcVad_set_mode_core(VadInstT *self, int mode) {
int return_value = ; switch (mode) {
case :
// Quality mode.
memcpy(self->over_hang_max_1, kOverHangMax1Q,
sizeof(self->over_hang_max_1));
memcpy(self->over_hang_max_2, kOverHangMax2Q,
sizeof(self->over_hang_max_2));
memcpy(self->individual, kLocalThresholdQ,
sizeof(self->individual));
memcpy(self->total, kGlobalThresholdQ,
sizeof(self->total));
break;
case :
// Low bitrate mode.
memcpy(self->over_hang_max_1, kOverHangMax1LBR,
sizeof(self->over_hang_max_1));
memcpy(self->over_hang_max_2, kOverHangMax2LBR,
sizeof(self->over_hang_max_2));
memcpy(self->individual, kLocalThresholdLBR,
sizeof(self->individual));
memcpy(self->total, kGlobalThresholdLBR,
sizeof(self->total));
break;
case :
// Aggressive mode.
memcpy(self->over_hang_max_1, kOverHangMax1AGG,
sizeof(self->over_hang_max_1));
memcpy(self->over_hang_max_2, kOverHangMax2AGG,
sizeof(self->over_hang_max_2));
memcpy(self->individual, kLocalThresholdAGG,
sizeof(self->individual));
memcpy(self->total, kGlobalThresholdAGG,
sizeof(self->total));
break;
case :
// Very aggressive mode.
memcpy(self->over_hang_max_1, kOverHangMax1VAG,
sizeof(self->over_hang_max_1));
memcpy(self->over_hang_max_2, kOverHangMax2VAG,
sizeof(self->over_hang_max_2));
memcpy(self->individual, kLocalThresholdVAG,
sizeof(self->individual));
memcpy(self->total, kGlobalThresholdVAG,
sizeof(self->total));
break;
default:
return_value = -;
break;
} return return_value;
}
set mode code
1.2 vad 支持三种帧长,80/10ms 160/20ms 240/30ms
采样这三种帧长,是由语音信号的特点决定的,语音信号是短时平稳信号,在10ms-30ms之间被看成平稳信号,高斯马尔可夫等比较信号处理方法基于的前提是信号是平稳的。
1.3 支持频率: 8khz 16khz 32khz 48khz
WebRTC 支持8kHz 16kHz 32kHz 48kHz的音频,但是WebRTC首先都将16kHz 32kHz 48kHz首先降频到8kHz,再进行处理。
int16_t speech_nb[]; // 30 ms in 8 kHz.
const size_t kFrameLen10ms = (size_t) (fs / );
const size_t kFrameLen10ms8khz = ;
size_t num_10ms_frames = frame_length / kFrameLen10ms;
int i = ;
for (i = ; i < num_10ms_frames; i++) {
resampleData(audio_frame, fs, kFrameLen10ms, &speech_nb[i * kFrameLen10ms8khz],
);
}
size_t new_frame_length = frame_length * / fs;
// Do VAD on an 8 kHz signal
vad = WebRtcVad_CalcVad8khz(self, speech_nb, new_frame_length);
2. 通过高斯模型计算子带能量,并且计算静音和语音的概率。
WebRtcVad_CalcVad8khz 函数计算特征量,其特征包括了6个子带的能量。计算后的特征存在feature_vector中。
int16_t WebRtcVad_CalculateFeatures(VadInstT *self, const int16_t *data_in,
size_t data_length, int16_t *features) {
int16_t total_energy = ;
// We expect |data_length| to be 80, 160 or 240 samples, which corresponds to
// 10, 20 or 30 ms in 8 kHz. Therefore, the intermediate downsampled data will
// have at most 120 samples after the first split and at most 60 samples after
// the second split.
int16_t hp_120[], lp_120[];
int16_t hp_60[], lp_60[];
const size_t half_data_length = data_length >> ;
size_t length = half_data_length; // |data_length| / 2, corresponds to
// bandwidth = 2000 Hz after downsampling. // Initialize variables for the first SplitFilter().
int frequency_band = ;
const int16_t *in_ptr = data_in; // [0 - 4000] Hz.
int16_t *hp_out_ptr = hp_120; // [2000 - 4000] Hz.
int16_t *lp_out_ptr = lp_120; // [0 - 2000] Hz. RTC_DCHECK_LE(data_length, );
RTC_DCHECK_LT(, kNumChannels - ); // Checking maximum |frequency_band|. // Split at 2000 Hz and downsample.
SplitFilter(in_ptr, data_length, &self->upper_state[frequency_band],
&self->lower_state[frequency_band], hp_out_ptr, lp_out_ptr); // For the upper band (2000 Hz - 4000 Hz) split at 3000 Hz and downsample.
frequency_band = ;
in_ptr = hp_120; // [2000 - 4000] Hz.
hp_out_ptr = hp_60; // [3000 - 4000] Hz.
lp_out_ptr = lp_60; // [2000 - 3000] Hz.
SplitFilter(in_ptr, length, &self->upper_state[frequency_band],
&self->lower_state[frequency_band], hp_out_ptr, lp_out_ptr); // Energy in 3000 Hz - 4000 Hz.
length >>= ; // |data_length| / 4 <=> bandwidth = 1000 Hz. LogOfEnergy(hp_60, length, kOffsetVector[], &total_energy, &features[]); // Energy in 2000 Hz - 3000 Hz.
LogOfEnergy(lp_60, length, kOffsetVector[], &total_energy, &features[]);
// For the lower band (0 Hz - 2000 Hz) split at 1000 Hz and downsample.
frequency_band = ;
in_ptr = lp_120; // [0 - 2000] Hz.
hp_out_ptr = hp_60; // [1000 - 2000] Hz.
lp_out_ptr = lp_60; // [0 - 1000] Hz.
length = half_data_length; // |data_length| / 2 <=> bandwidth = 2000 Hz.
SplitFilter(in_ptr, length, &self->upper_state[frequency_band],
&self->lower_state[frequency_band], hp_out_ptr, lp_out_ptr); // Energy in 1000 Hz - 2000 Hz.
length >>= ; // |data_length| / 4 <=> bandwidth = 1000 Hz.
LogOfEnergy(hp_60, length, kOffsetVector[], &total_energy, &features[]); // For the lower band (0 Hz - 1000 Hz) split at 500 Hz and downsample.
frequency_band = ;
in_ptr = lp_60; // [0 - 1000] Hz.
hp_out_ptr = hp_120; // [500 - 1000] Hz.
lp_out_ptr = lp_120; // [0 - 500] Hz.
SplitFilter(in_ptr, length, &self->upper_state[frequency_band],
&self->lower_state[frequency_band], hp_out_ptr, lp_out_ptr); // Energy in 500 Hz - 1000 Hz.
length >>= ; // |data_length| / 8 <=> bandwidth = 500 Hz.
LogOfEnergy(hp_120, length, kOffsetVector[], &total_energy, &features[]); // For the lower band (0 Hz - 500 Hz) split at 250 Hz and downsample.
frequency_band = ;
in_ptr = lp_120; // [0 - 500] Hz.
hp_out_ptr = hp_60; // [250 - 500] Hz.
lp_out_ptr = lp_60; // [0 - 250] Hz.
SplitFilter(in_ptr, length, &self->upper_state[frequency_band],
&self->lower_state[frequency_band], hp_out_ptr, lp_out_ptr); // Energy in 250 Hz - 500 Hz.
length >>= ; // |data_length| / 16 <=> bandwidth = 250 Hz.
LogOfEnergy(hp_60, length, kOffsetVector[], &total_energy, &features[]); // Remove 0 Hz - 80 Hz, by high pass filtering the lower band.
HighPassFilter(lp_60, length, self->hp_filter_state, hp_120); // Energy in 80 Hz - 250 Hz.
LogOfEnergy(hp_120, length, kOffsetVector[], &total_energy, &features[]); return total_energy;
}
WebRtcVad_GaussianProbability计算噪音和语音的分布概率,对于每一个特征,求其似然比,计算加权对数似然比。如果6个特征中其中有一个超过了阈值,就认为是语音。
int32_t WebRtcVad_GaussianProbability(int16_t input,
int16_t mean,
int16_t std,
int16_t *delta) {
int16_t tmp16, inv_std, inv_std2, exp_value = ;
int32_t tmp32; // Calculate |inv_std| = 1 / s, in Q10.
// 131072 = 1 in Q17, and (|std| >> 1) is for rounding instead of truncation.
// Q-domain: Q17 / Q7 = Q10.
tmp32 = (int32_t) + (int32_t) (std >> );
inv_std = (int16_t) DivW32W16(tmp32, std); // Calculate |inv_std2| = 1 / s^2, in Q14.
tmp16 = (inv_std >> ); // Q10 -> Q8.
// Q-domain: (Q8 * Q8) >> 2 = Q14.
inv_std2 = (int16_t) ((tmp16 * tmp16) >> );
// TODO(bjornv): Investigate if changing to
// inv_std2 = (int16_t)((inv_std * inv_std) >> 6);
// gives better accuracy. tmp16 = (input << ); // Q4 -> Q7
tmp16 = tmp16 - mean; // Q7 - Q7 = Q7 // To be used later, when updating noise/speech model.
// |delta| = (x - m) / s^2, in Q11.
// Q-domain: (Q14 * Q7) >> 10 = Q11.
*delta = (int16_t) ((inv_std2 * tmp16) >> ); // Calculate the exponent |tmp32| = (x - m)^2 / (2 * s^2), in Q10. Replacing
// division by two with one shift.
// Q-domain: (Q11 * Q7) >> 8 = Q10.
tmp32 = (*delta * tmp16) >> ; // If the exponent is small enough to give a non-zero probability we calculate
// |exp_value| ~= exp(-(x - m)^2 / (2 * s^2))
// ~= exp2(-log2(exp(1)) * |tmp32|).
if (tmp32 < kCompVar) {
// Calculate |tmp16| = log2(exp(1)) * |tmp32|, in Q10.
// Q-domain: (Q12 * Q10) >> 12 = Q10.
tmp16 = (int16_t) ((kLog2Exp * tmp32) >> );
tmp16 = -tmp16;
exp_value = (0x0400 | (tmp16 & 0x03FF));
tmp16 ^= 0xFFFF;
tmp16 >>= ;
tmp16 += ;
// Get |exp_value| = exp(-|tmp32|) in Q10.
exp_value >>= tmp16;
} // Calculate and return (1 / s) * exp(-(x - m)^2 / (2 * s^2)), in Q20.
// Q-domain: Q10 * Q10 = Q20.
return inv_std * exp_value;
}
3. 最后更新模型方差
3.1 通过WebRtcVad_FindMinimum 求出最小值更新方差,计算噪声加权平均值。
3.2 更新模型参数,噪音模型均值更新、语音模型均值更新、噪声模型方差更新、语音模型方差更新。
// Update the model parameters.
maxspe = ;
for (channel = ; channel < kNumChannels; channel++) { // Get minimum value in past which is used for long term correction in Q4.
feature_minimum = WebRtcVad_FindMinimum(self, features[channel], channel); // Compute the "global" mean, that is the sum of the two means weighted.
noise_global_mean = WeightedAverage(&self->noise_means[channel], ,
&kNoiseDataWeights[channel]);
tmp1_s16 = (int16_t) (noise_global_mean >> ); // Q8 for (k = ; k < kNumGaussians; k++) {
gaussian = channel + k * kNumChannels; nmk = self->noise_means[gaussian];
smk = self->speech_means[gaussian];
nsk = self->noise_stds[gaussian];
ssk = self->speech_stds[gaussian]; // Update noise mean vector if the frame consists of noise only.
nmk2 = nmk;
if (!vadflag) {
// deltaN = (x-mu)/sigma^2
// ngprvec[k] = |noise_probability[k]| /
// (|noise_probability[0]| + |noise_probability[1]|) // (Q14 * Q11 >> 11) = Q14.
delt = (int16_t) ((ngprvec[gaussian] * deltaN[gaussian]) >> );
// Q7 + (Q14 * Q15 >> 22) = Q7.
nmk2 = nmk + (int16_t) ((delt * kNoiseUpdateConst) >> );
} // Long term correction of the noise mean.
// Q8 - Q8 = Q8.
ndelt = (feature_minimum << ) - tmp1_s16;
// Q7 + (Q8 * Q8) >> 9 = Q7.
nmk3 = nmk2 + (int16_t) ((ndelt * kBackEta) >> ); // Control that the noise mean does not drift to much.
tmp_s16 = (int16_t) ((k + ) << );
if (nmk3 < tmp_s16) {
nmk3 = tmp_s16;
}
tmp_s16 = (int16_t) (( + k - channel) << );
if (nmk3 > tmp_s16) {
nmk3 = tmp_s16;
}
self->noise_means[gaussian] = nmk3; if (vadflag) {
// Update speech mean vector:
// |deltaS| = (x-mu)/sigma^2
// sgprvec[k] = |speech_probability[k]| /
// (|speech_probability[0]| + |speech_probability[1]|) // (Q14 * Q11) >> 11 = Q14.
delt = (int16_t) ((sgprvec[gaussian] * deltaS[gaussian]) >> );
// Q14 * Q15 >> 21 = Q8.
tmp_s16 = (int16_t) ((delt * kSpeechUpdateConst) >> );
// Q7 + (Q8 >> 1) = Q7. With rounding.
smk2 = smk + ((tmp_s16 + ) >> ); // Control that the speech mean does not drift to much.
maxmu = maxspe + ;
if (smk2 < kMinimumMean[k]) {
smk2 = kMinimumMean[k];
}
if (smk2 > maxmu) {
smk2 = maxmu;
}
self->speech_means[gaussian] = smk2; // Q7. // (Q7 >> 3) = Q4. With rounding.
tmp_s16 = ((smk + ) >> ); tmp_s16 = features[channel] - tmp_s16; // Q4
// (Q11 * Q4 >> 3) = Q12.
tmp1_s32 = (deltaS[gaussian] * tmp_s16) >> ;
tmp2_s32 = tmp1_s32 - ;
tmp_s16 = sgprvec[gaussian] >> ;
// (Q14 >> 2) * Q12 = Q24.
tmp1_s32 = tmp_s16 * tmp2_s32; tmp2_s32 = tmp1_s32 >> ; // Q20 // 0.1 * Q20 / Q7 = Q13.
if (tmp2_s32 > ) {
tmp_s16 = (int16_t) DivW32W16(tmp2_s32, ssk * );
} else {
tmp_s16 = (int16_t) DivW32W16(-tmp2_s32, ssk * );
tmp_s16 = -tmp_s16;
}
// Divide by 4 giving an update factor of 0.025 (= 0.1 / 4).
// Note that division by 4 equals shift by 2, hence,
// (Q13 >> 8) = (Q13 >> 6) / 4 = Q7.
tmp_s16 += ; // Rounding.
ssk += (tmp_s16 >> );
if (ssk < kMinStd) {
ssk = kMinStd;
}
self->speech_stds[gaussian] = ssk;
} else {
// Update GMM variance vectors.
// deltaN * (features[channel] - nmk) - 1
// Q4 - (Q7 >> 3) = Q4.
tmp_s16 = features[channel] - (nmk >> );
// (Q11 * Q4 >> 3) = Q12.
tmp1_s32 = (deltaN[gaussian] * tmp_s16) >> ;
tmp1_s32 -= ; // (Q14 >> 2) * Q12 = Q24.
tmp_s16 = (ngprvec[gaussian] + ) >> ;
tmp2_s32 = (tmp_s16 * tmp1_s32);
// tmp2_s32 = OverflowingMulS16ByS32ToS32(tmp_s16, tmp1_s32);
// Q20 * approx 0.001 (2^-10=0.0009766), hence,
// (Q24 >> 14) = (Q24 >> 4) / 2^10 = Q20.
tmp1_s32 = tmp2_s32 >> ; // Q20 / Q7 = Q13.
if (tmp1_s32 > ) {
tmp_s16 = (int16_t) DivW32W16(tmp1_s32, nsk);
} else {
tmp_s16 = (int16_t) DivW32W16(-tmp1_s32, nsk);
tmp_s16 = -tmp_s16;
}
tmp_s16 += ; // Rounding
nsk += tmp_s16 >> ; // Q13 >> 6 = Q7.
if (nsk < kMinStd) {
nsk = kMinStd;
}
self->noise_stds[gaussian] = nsk;
}
} // Separate models if they are too close.
// |noise_global_mean| in Q14 (= Q7 * Q7).
noise_global_mean = WeightedAverage(&self->noise_means[channel], ,
&kNoiseDataWeights[channel]); // |speech_global_mean| in Q14 (= Q7 * Q7).
speech_global_mean = WeightedAverage(&self->speech_means[channel], ,
&kSpeechDataWeights[channel]); // |diff| = "global" speech mean - "global" noise mean.
// (Q14 >> 9) - (Q14 >> 9) = Q5.
diff = (int16_t) (speech_global_mean >> ) -
(int16_t) (noise_global_mean >> );
if (diff < kMinimumDifference[channel]) {
tmp_s16 = kMinimumDifference[channel] - diff; // |tmp1_s16| = ~0.8 * (kMinimumDifference - diff) in Q7.
// |tmp2_s16| = ~0.2 * (kMinimumDifference - diff) in Q7.
tmp1_s16 = (int16_t) (( * tmp_s16) >> );
tmp2_s16 = (int16_t) (( * tmp_s16) >> ); // Move Gaussian means for speech model by |tmp1_s16| and update
// |speech_global_mean|. Note that |self->speech_means[channel]| is
// changed after the call.
speech_global_mean = WeightedAverage(&self->speech_means[channel],
tmp1_s16,
&kSpeechDataWeights[channel]); // Move Gaussian means for noise model by -|tmp2_s16| and update
noise_global_mean = WeightedAverage(&self->noise_means[channel],
-tmp2_s16,
&kNoiseDataWeights[channel]);
} // Control that the speech & noise means do not drift to much.
maxspe = kMaximumSpeech[channel];
tmp2_s16 = (int16_t) (speech_global_mean >> );
if (tmp2_s16 > maxspe) {
// Upper limit of speech model.
tmp2_s16 -= maxspe; for (k = ; k < kNumGaussians; k++) {
self->speech_means[channel + k * kNumChannels] -= tmp2_s16;
}
} tmp2_s16 = (int16_t) (noise_global_mean >> );
if (tmp2_s16 > kMaximumNoise[channel]) {
tmp2_s16 -= kMaximumNoise[channel]; for (k = ; k < kNumGaussians; k++) {
self->noise_means[channel + k * kNumChannels] -= tmp2_s16;
}
}
}
WebRTC的VAD 过程解读的更多相关文章
- 提纲挈领webrtc之vad检测
顾名思义,VAD(Voice Activity Detection)算法的作用是检测是否是人的语音,它的使用 范围极广,降噪,语音识别等领域都需要有vad检测.vad检测有很多方法,这里我们之介绍一 ...
- WebRTC学习之 Intel® Collaboration Suite for WebRTC源码流程解读
年后回来,因为新项目的需求,开始了解WebRTC相关的知识.目前接触的是Intel® Collaboration Suite for WebRTC.刚开始看SDK发现很多概念是我目前不知道的,于是恶补 ...
- STM32启动过程解读与跟踪验证
经过查阅各种官方文献和对代码进行单步跟踪,详细地叙述了STM32加电启动的具体过程.对于关键性的语句都指明了出处.下面将学习成果分享给大家,由于笔者知识有限,不当之处敬请指出. 为了更好的说明问题,先 ...
- FreeSWITCH 加载模块过程解读
今天来学习FreeSWITCH 加载模块过程. 哪些模块需要编译,是由源码下的 modules.conf 文件决定的. 哪些模块在程序启动时自动加载,是由 freeswitch/conf/autolo ...
- DBUtil内部实现过程解读
python数据库连接工具DBUtils DBUtils是一个允许在多线程python应用和数据库之间安全及高效连接的python模块套件. 模块 DBUtils套件包含两个模块子集,一个适用于兼容D ...
- WebRTC 音视频开发
WebRTC 音视频开发 webrtc Android IOS WebRTC 音视频开发总结(七八)-- 为什么WebRTC端到端监控很关键? 摘要: 本文主要介绍WebRTC端到端监控(我们翻译 ...
- 转:Android IOS WebRTC 音视频开发总结 (系列文章集合)
随笔分类 - webrtc Android IOS WebRTC 音视频开发总结(七八)-- 为什么WebRTC端到端监控很关键? 摘要: 本文主要介绍WebRTC端到端监控(我们翻译和整理的,译 ...
- webrtc进阶-信令篇-之三:信令、stun、turn、ice
webRTC支持点对点通讯,但是webRTC仍然需要服务端: . 协调通讯过程中客户端之间需要交换元数据, 如一个客户端找到另一个客户端以及通知另一个客户端开始通讯. . 需要处理NAT(网 ...
- webrtc编译之libcommonaudio
[170/1600] CXX obj/webrtc/common_audio/common_audio.audio_util.o[171/1600] CXX obj/webrtc/common_aud ...
随机推荐
- C/C++编程笔记:C语言制作情侣必备《爱情电子相册》,源码解析!
今天是521,就分享一个程序员必会的——情侣回忆杀<爱情电子相册>吧!话不多说,先上思路,后接源码! 具备能力: 1.基本可视化编程 1.1 initgraph(800,600); 1.2 ...
- Qt 之 Graphics View Framework 简介
Graphics View Framework 交互式 2D 图形的 Graphics View 框架概述.自 Qt4.2 中引入了 Graphics View,以取代其前身 QCanvas.Grap ...
- 面试必问的volatile关键字
原文: 卡巴拉的树 https://juejin.im/post/5a2b53b7f265da432a7b821c 在Java相关的岗位面试中,很多面试官都喜欢考察面试者对Java并发的了解程度, ...
- fastjson JSON.toJavaObject() 实体类首字母大写属性无法解析问题
fastjson JSON.toJavaObject() 实体类首字母大写属性无法解析问题
- (恐怕是)写得最通俗易懂的一篇关于HashMap的文章——xx大佬这样说
先看再点赞,给自己一点思考的时间,微信搜索[沉默王二]关注这个有颜值却假装靠才华苟且的程序员. 本文 GitHub github.com/itwanger 已收录,里面还有一线大厂整理的面试题,以及我 ...
- Azure Application Gateway(一)对后端 Web App 进行负载均衡
一,引言 今天,我们学习一个新的知识点-----Azure Application Gateway,通过Azure 应用程序网关为我么后端的服务提供负载均衡的功能.我们再文章头中大概先了解一下什么是应 ...
- react中iconfont如何使用
一.配置 this.state={ tabs:[ { path:"/home", icon:"\ue628", name:"首页", }, ...
- ngnix.conf的配置结构
1.ngnix.conf的配置结构 2.部分配置文件说明 #worker进程可操作的用户 #user nobody; #设置worker的个数 worker_processes 1; #错误日志 #e ...
- 封装react antd的upload上传组件
上传文件也是我们在实际开发中常遇到的功能,比如上传产品图片以供更好地宣传我们的产品,上传excel文档以便于更好地展示更多的产品信息,上传zip文件以便于更好地收集一些资料信息等等.至于为何要把上传组 ...
- 【SDOI2009】 HH的项链 - 莫队
题目描述 HH 有一串由各种漂亮的贝壳组成的项链.HH 相信不同的贝壳会带来好运,所以每次散步完后,他都会随意取出一段贝壳,思考它们所表达的含义.HH 不断地收集新的贝壳,因此,他的项链变得越来越长. ...