Mapreduce实例--去重
数据去重”主要是为了掌握和利用并行化思想来对数据进行有意义的筛选。统计大数据集上的数据种类个数、从网站日志中计算访问地等这些看似庞杂的任务都会涉及数据去重。
数据去重的最终目标是让原始数据中出现次数超过一次的数据在输出文件中只出现一次。在MapReduce流程中,map的输出<key,value>经过shuffle过程聚集成<key,value-list>后交给reduce。我们自然而然会想到将同一个数据的所有记录都交给一台reduce机器,无论这个数据出现多少次,只要在最终结果中输出一次就可以了。具体就是reduce的输入应该以数据作为key,而对value-list则没有要求(可以设置为空)。当reduce接收到一个<key,value-list>时就直接将输入的key复制到输出的key中,并将value设置成空值,然后输出<key,value>。
MaprReduce去重流程如下图所示:
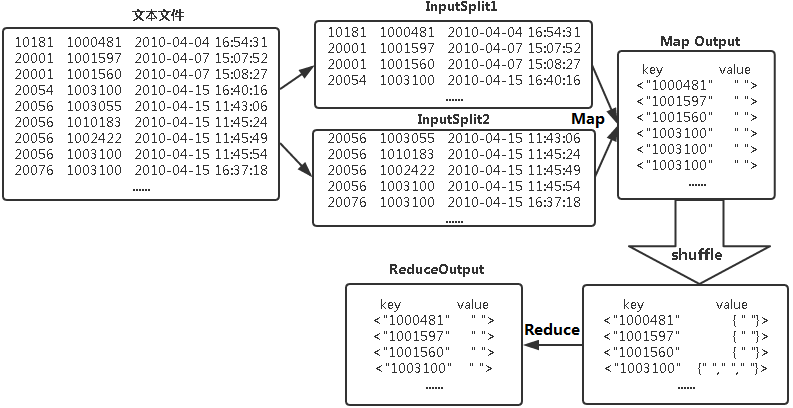
操作环境
Centos 7 #搭建有Hadoop集群
jdk1.8
hadoop 3.2.0
IDEA 2019
操作任务:
现有含有三个元素的数据集,它们通过"\t"分割,下面截取部分数据仅供参考
用户id 商品id 收藏日期
10181 1000481 2010-04-04 16:54:31
20001 1001597 2010-04-07 15:07:52
20001 1001560 2010-04-07 15:08:27
20042 1001368 2010-04-08 08:20:30
20067 1002061 2010-04-08 16:45:33
20056 1003289 2010-04-12 10:50:55
20056 1003290 2010-04-12 11:57:35
20056 1003292 2010-04-12 12:05:29
20054 1002420 2010-04-14 15:24:12
20055 1001679 2010-04-14 19:46:04
20054 1010675 2010-04-14 15:23:53
20054 1002429 2010-04-14 17:52:45
20076 1002427 2010-04-14 19:35:39
20054 1003326 2010-04-20 12:54:44
20056 1002420 2010-04-15 11:24:49
20064 1002422 2010-04-15 11:35:54
20056 1003066 2010-04-15 11:43:01
20056 1003055 2010-04-15 11:43:06
20056 1010183 2010-04-15 11:45:24
20056 1002422 2010-04-15 11:45:49
20056 1003100 2010-04-15 11:45:54
20056 1003094 2010-04-15 11:45:57
20056 1003064 2010-04-15 11:46:04
20056 1010178 2010-04-15 16:15:20
20076 1003101 2010-04-15 16:37:27
20076 1003103 2010-04-15 16:37:05
20076 1003100 2010-04-15 16:37:18
20076 1003066 2010-04-15 16:37:31
20054 1003103 2010-04-15 16:40:14
20054 1003100 2010-04-15 16:40:16
操作要求用java编写Mapreduce程序,根据Id进行去重,统计用户收藏商品中都有哪些商品被收藏,统计数据如下:
商品id
1000481
1001368
1001560
1001597
1001679
1002061
1002420
1002422
1002427
1002429
1003055
1003064
1003066
1003094
1003100
1003101
1003103
1003289
1003290
1003292
1003326
1010178
1010183
1010675
操作步骤:
首先启动Hadoop集群,将数据集上传到Hdfs
./start-all.sh
hadoop fs -mkdir -p /mymapreduce2/in
hadoop fs -put /data/mapreduce2/buyer_favorite1 /mymapreduce2/in
在IDEA中建立Java工程,为了避免错误,我们使用hadoop安装文件中的Jar包。
再编写代码,数据去重的目的是让原始数据中出现次数超过一次的数据在输出文件中只出现一次。那么就将相同的key值的所有value记录到一台reduce机器,让其无论出现多少次,最终结果只输出一次,具体就是reduce的输出应该以数据作为key,而value-key没有要求,当reduce接收到一个时,就直接将Key复制到key中,将value设置为空。
具体代码:
package mapreduce;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
public class Filter{ public static class Map extends Mapper<Object , Text , Text , NullWritable>{
//map将输入中个value复制到输出数据的Key上,并直接输出
//从输入中得到的每行的数据的类型
private static Text newKey=new Text();
public void map(Object key,Text value,Context context) throws IOException, InterruptedException{
//实现map函数
//获取并输出每一次的处理过程
String line=value.toString();
System.out.println(line);
String arr[]=line.split("\t");
newKey.set(arr[1]);
context.write(newKey, NullWritable.get());
System.out.println(newKey);
}
}
public static class Reduce extends Reducer<Text, NullWritable, Text, NullWritable>{
public void reduce(Text key,Iterable<NullWritable> values,Context context) throws IOException, InterruptedException{
//获得并输出每一次的处理过程
context.write(key,NullWritable.get());
}
}
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException{
Configuration conf=new Configuration();
System.out.println("start");
Job job =new Job(conf,"filter");
job.setJarByClass(Filter.class);
job.setMapperClass(Map.class);
job.setReducerClass(Reduce.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(NullWritable.class);
job.setInputFormatClass(TextInputFormat.class);
job.setOutputFormatClass(TextOutputFormat.class);
Path in=new Path("hdfs://localhost:9000/mymapreduce2/in/buyer_favorite1");
Path out=new Path("hdfs://localhost:9000/mymapreduce2/out");
FileInputFormat.addInputPath(job,in);
FileOutputFormat.setOutputPath(job,out);
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
当执行完毕后查看结果:
hadoop fs -ls /mymapreduce2/out
hadoop fs -cat /mymapreduce2/out/part-r-00000

Mapreduce实例--去重的更多相关文章
- MapReduce实例2(自定义compare、partition)& shuffle机制
MapReduce实例2(自定义compare.partition)& shuffle机制 实例:统计流量 有一份流量数据,结构是:时间戳.手机号.....上行流量.下行流量,需求是统计每个用 ...
- MapReduce实例&YARN框架
MapReduce实例&YARN框架 一个wordcount程序 统计一个相当大的数据文件中,每个单词出现的个数. 一.分析map和reduce的工作 map: 切分单词 遍历单词数据输出 r ...
- MapReduce实例(数据去重)
数据去重: 原理(理解):Mapreduce程序首先应该确认<k3,v3>,根据<k3,v3>确定<k2,v2>,原始数据中出现次数超过一次的数据在输出文件中只出现 ...
- MapReduce实例
1.WordCount(统计单词) 经典的运用MapReuce编程模型的实例 1.1 Description 给定一系列的单词/数据,输出每个单词/数据的数量 1.2 Sample a is b is ...
- MapReduce实例浅析
在文章<MapReduce原理与设计思想>中,详细剖析了MapReduce的原理,这篇文章则通过实例重点剖析MapReduce 本文地址:http://www.cnblogs.com/ar ...
- mapreduce (六) MapReduce实现去重 NullWritable的使用
习题来源:http://www.cnblogs.com/xia520pi/archive/2012/06/04/2534533.htmlfile1 2012-3-1 a 2012-3-2 b 2012 ...
- MapReduce实例-基于内容的推荐(一)
环境: Hadoop1.x,CentOS6.5,三台虚拟机搭建的模拟分布式环境 数据:下载的amazon产品共同采购网络元数据(需FQ下载)http://snap.stanford.edu/data/ ...
- MapReduce实例-倒排索引
环境: Hadoop1.x,CentOS6.5,三台虚拟机搭建的模拟分布式环境 数据:任意数量.格式的文本文件(我用的四个.java代码文件) 方案目标: 根据提供的文本文件,提取出每个单词在哪个文件 ...
- MapReduce实例-NASA博客数据频度简单分析
环境: Hadoop1.x,CentOS6.5,三台虚拟机搭建的模拟分布式环境,gnuplot, 数据:http://ita.ee.lbl.gov/html/contrib/NASA-HTTP.htm ...
随机推荐
- Python中sort、sorted的cmp参数废弃之后使用cmp_to_key实现类似功能
Python2.1以前的排序比较方法只提供一个cmp比较函数参数,没有__lt__等6个富比较方法, Python 2.1引入了富比较方法,Python3.4之后作废了cmp参数.相应地从Python ...
- 第11.8节 Python正则表达式的重复匹配模式及元字符“?”、 “*”、 “+”功能介绍
符号"?".""."+"这三个元字符修饰符在Python中都表示重复匹配的模式,即要求匹配的字符串满足重复次数的要求,但具体重复次数要求不同 ...
- PyQt学习随笔:自定义Qt事件可以使用的事件类型的常量值范围
除了<PyQt学习随笔:Qt事件QEvent.type类型常量及其含义资料速查>介绍的Qt已经定义的事件外,Qt还支持自定义事件. 为了方便起见,可以使用 registerEventTyp ...
- 使用 webpack 手动搭建 vue 项目
webpack 是一个前端工程化打包工具,对于前端工程师来说 webpack 是一项十分重要的技能.下面我们就通过搭建一个 vue 项目来学习使用 webpack 主要环境: node v14.15. ...
- Markdown 公式指导手册
本文为 Markdown 环境下的常用语法指引.Typora 编辑阅读器支持 \(\LaTeX\) 编辑显示支持,例如:\(\sum_{i=1}^n a_i=0\),访问 MathJax 以参考更多使 ...
- Codeforces Edu Round 55 A-E
A. Vasya and Book 简单的取余运用. #include <iostream> #include <cstdio> #include <limits.h&g ...
- Vue组件化开发(原有项目的改造)
将组件定义成一个js和css,然后供其他页面进行调用 demo.html <!DOCTYPE html> <html> <head> <meta charse ...
- DBeaver连接MySQ报错
遇错情况:第一次使用DBaver连接MySQL遇到以下问题: 报错信息:Public Key Retrieval is not allowed 截图如下: 解决方案步骤: 一.已有连接的情况:F4或者 ...
- 珍藏的C语言编程系列教程
本文有332个文字,大小约为2KB,预计阅读时间1分钟 这是本人珍藏的C语言.C++系列教程. 相信每个Coder的第一门编程语言就是C语言吧, 现在也依然很热门,不谈了.直接上链接,感兴趣的直接存, ...
- 深入LUA脚本语言,让你彻底明白调试原理
这是道哥的第008篇原创 一.前言 上篇文章我们聊了gdb的底层调试机制,明白了gdb是利用操作系统提供的系统信号来调试目标程序的.很多朋友私下留言了,看到能帮助到大家,我心里还是很开心的,其实这也是 ...