Zookeeper笔记分享
Zookeeper简介
分布式应用
Zookeeper 架构图
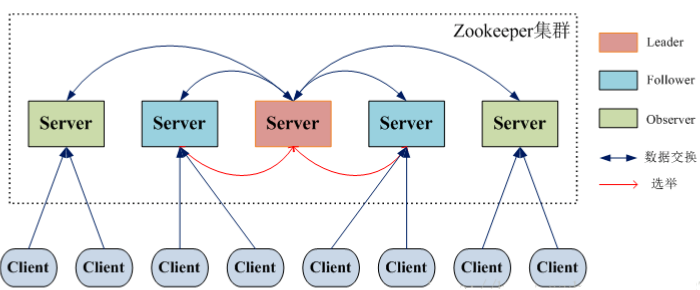
Zookeeper集群角色介绍
- Leader: ZooKeeper 集群工作的核心 事务请求(写操作)的唯一调度和处理者,保证集群事务处理的顺序性;集群内部各个服务的调度者。 对于 create,setData,delete 等有写操作的请求,则需要统一转发给 leader 处理,leader 需要决定编号、执行操作,这个过程称为一个事务。
- Follower: 处理客户端非事务(读操作)请求 转发事务请求给 Leader 参与集群 leader 选举投票2n-1台可以做集群投票 此外,针对访问量比较大的 zookeeper 集群,还可以新增观察者角色
- Observer: 观察者角色,观察ZooKeeper集群的最新状态变化并将这些状态同步过来,其对于非事务请求可以进行独立处理,对于事务请求,则会转发给Leader服务器处理 不会参与任何形式的投票只提供服务,通常用于在不影响集群事务处理能力的前提下提升集群的非事务处理能力 通常来说就是增加并发的请求
ZooKeeper当中的主从与主备:
- 主从:主节点少,从节点多,主节点分配任务,从节点具体执行任务
- 主备:主节点与备份节点,主要用于解决我们主机节点挂掉以后,如何选出来一个新的主节点的问题,保证我们的主节点不会宕机
- 很多时候,主从与主备没有太明显的分界线,很多时候都是一起出现
Zookeeper的特性
- 全局数据的一致:每个 server 保存一份相同的数据副本,client 无论链接到哪个 server,展示的数据都是一致的
- 可靠性:如果消息被其中一台服务器接受,那么将被所有的服务器接受
- 顺序性:包括全局有序和偏序两种:全局有序是指如果在一台服务器上消息 a 在消息 b 前发布,则在所有 server 上消息 a 在消息 b 前被发布,偏序是指如果以个消息 b 在消息 a 后被同一个发送者发布,a 必须将排在 b 前面
- 数据更新原子性:一次数据更新要么成功,要么失败,不存在中间状态
- 实时性:ZooKeeper 保证客户端将在一个时间间隔范围内获得服务器的更新信息,或者服务器失效的信息
分布式应用的优点
- 可靠性 - 单个或几个系统的故障不会使整个系统出现故障。
- 可扩展性 - 可以在需要时增加性能,通过添加更多机器,在应用程序配置中进行微小的更改,而不会有停机时间。
- 透明性 - 隐藏系统的复杂性,并将其显示为单个实体/应用程序。
分布式应用的挑战
- 竞争条件 - 两个或多个机器尝试执行特定任务,实际上只需在任意给定时间由单个机器完成。例如,共享资源只能在任意给定时间由单个机器修改。
- 死锁 - 两个或多个操作等待彼此无限期完成。
- 不一致 - 数据的部分失败。
什么是Apache ZooKeeper?
- 命名服务 - 按名称标识集群中的节点。它类似于DNS,但仅对于节点。
- 配置管理 - 加入节点的最近的和最新的系统配置信息。
- 集群管理 - 实时地在集群和节点状态中加入/离开节点。
- 选举算法 - 选举一个节点作为协调目的的leader。
- 锁定和同步服务 - 在修改数据的同时锁定数据。此机制可帮助你在连接其他分布式应用程序(如Apache HBase)时进行自动故障恢复。
- 高度可靠的数据注册表 - 即使在一个或几个节点关闭时也可以获得数据。
以下是使用ZooKeeper的好处:
- 简单的分布式协调过程
- 同步 - 服务器进程之间的相互排斥和协作。此过程有助于Apache HBase进行配置管理。
- 有序的消息
- 序列化 - 根据特定规则对数据进行编码。确保应用程序运行一致。这种方法可以在MapReduce中用来协调队列以执行运行的线程。
- 可靠性
- 原子性 - 数据转移完全成功或完全失败,但没有事务是部分的。
Zookeeper的应用场景
- 分布式锁
- 集群选主
- 统一命名服务
- 统一配置管理(监听配置)
- 携程配置中心 阿波罗
- 统一集群管理(监听集群中节点变化)
- 服务器节点动态上下线
- 负载均衡
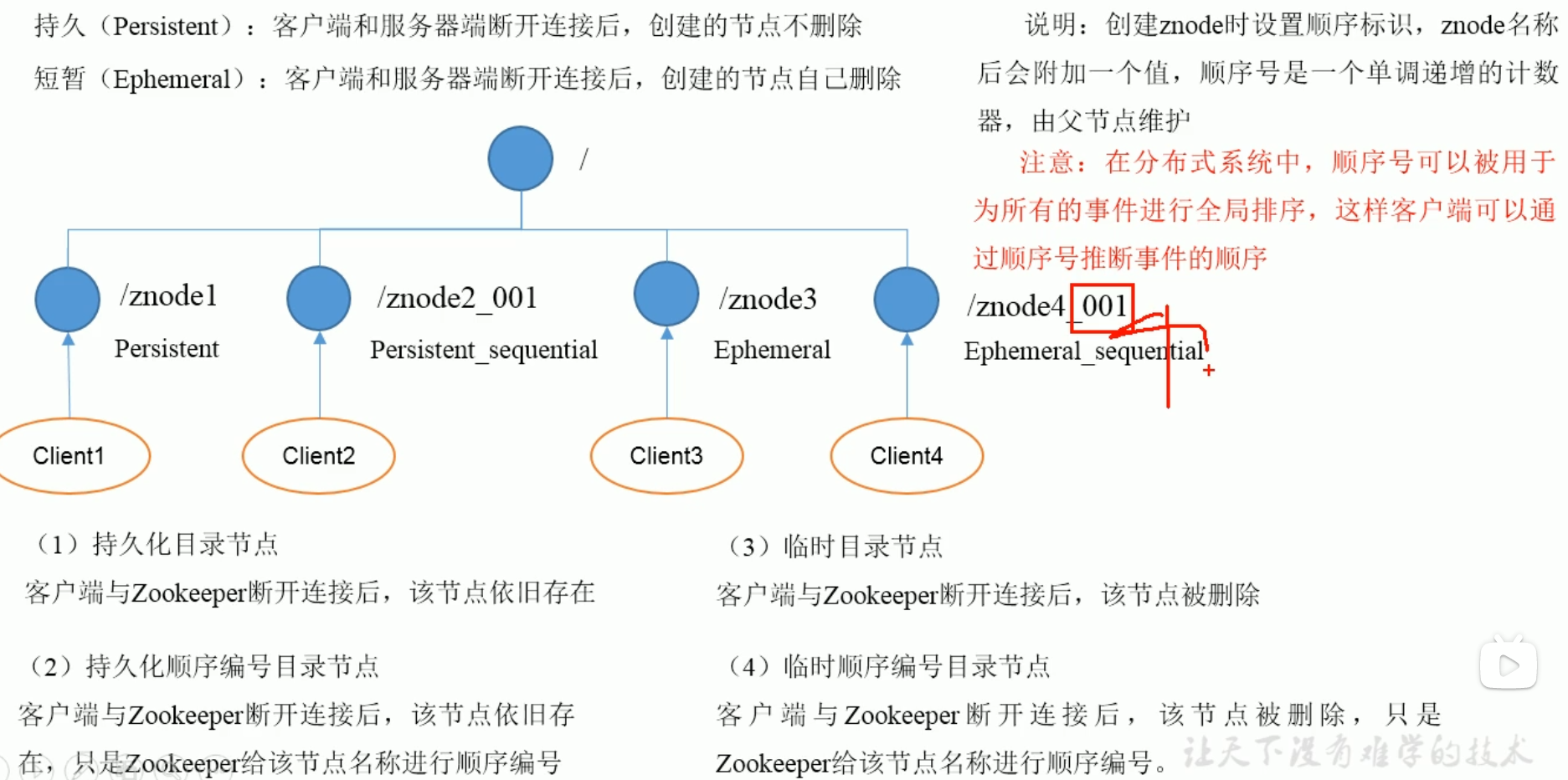
zkCli指令
- C(一致性):所有的节点上的数据时刻保持同步
- A(可用性):每个请求都能接受到一个响应,无论响应成功或失败
- P(分区容错):系统应该能持续提供服务,即使系统内部有消息丢失(分区)
- CA without P:如果不要求P(不允许分区),则C(强一致性)和A(可用性)是可以保证的。但其实分区不是你想不想的问题,而是始终会存在,因此CA的系统更多的是允许分区后各子系统依然保持CA。
- CP without A:如果不要求A(可用),相当于每个请求都需要在Server之间强一致,而P(分区)会导致同步时间无限延长,如此CP也是可以保证的。很多传统的数据库分布式事务都属于这种模式。
- AP wihtout C:要高可用并允许分区,则需放弃一致性。一旦分区发生,节点之间可能会失去联系,为了高可用,每个节点只能用本地数据提供服务,而这样会导致全局数据的不一致性。现在众多的NoSQL都属于此类。
Zookeeper怎么保证数据的一致性?
Zookeeper笔记分享的更多相关文章
- (转)ZooKeeper 笔记(1) 安装部署及hello world
ZooKeeper 笔记(1) 安装部署及hello world 先给一堆学习文档,方便以后查看 官网文档地址大全: OverView(概述) http://zookeeper.apache.or ...
- C#面试题(转载) SQL Server 数据库基础笔记分享(下) SQL Server 数据库基础笔记分享(上) Asp.Net MVC4中的全局过滤器 C#语法——泛型的多种应用
C#面试题(转载) 原文地址:100道C#面试题(.net开发人员必备) https://blog.csdn.net/u013519551/article/details/51220841 1. . ...
- Zookeeper笔记之命令行操作
$ZOOKEEPER_HOME/bin下的zkCli.sh进入命令行界面,使用help可查看支持的所有命令: 一.节点相关操作 create [-s] [-e] path data acl creat ...
- 1C课程笔记分享_StudyJams_2017
课程1C 概述 课程1C是创建一个生日贺卡应用的实践课程,所以本篇笔记分享主要记录个人的实践过程,此外分享一些比较零散的知识点. Drawable文件夹 Drawable文件夹是Android项目统一 ...
- uml精粹——11.活动图(及整个读书笔记分享)
11.活动图activity diagram 活动图是描写叙述过程化逻辑procedural logic.业务过程business process和工作流work flow的技术. 他和流程图fl ...
- 学习笔记分享之汇编---3. 堆栈&标志寄存器
前言: 此文章收录在本人的<学习笔记分享>分类中,此分类记录本人的学习心得体会,现全部分享出来希望和大家共同交流学习成长.附上分类链接: https://www.cnblogs.c ...
- zookeeper笔记(一)
title: zookeeper笔记(一) zookeeper 安装简记 解压文件 $ tar -zxvf zookeeper-3.4.10.tar.gz -C 安装目录 创建软连接(进入安装目录) ...
- zookeeper笔记(二)
title: zookeeper笔记(二) zookeeper ALC权限控制 getAcl path 可以查看某个node的权限 设置权限: 2. world方式 setAcl <path&g ...
- Zookeeper笔记3——原理及其安装使用
Zookeeper到底能干什么? 1.配置管理:这个好理解.分布式系统都有好多机器,Zookeeper提供了这样的一种服务:一种集中管理配置的方法,我们在这个集中的地方修改了配置,所有对这个配置感兴趣 ...
随机推荐
- SpringCloud 源码系列(3)—— 注册中心 Eureka(下)
十一.Eureka Server 集群 在实际的生产环境中,可能有几十个或者几百个的微服务实例,Eureka Server 承担了非常高的负载,而且为了保证注册中心高可用,一般都要部署成集群的,下面就 ...
- Python中可迭代对象是什么?
Python中可迭代对象(Iterable)并不是指某种具体的数据类型,它是指存储了元素的一个容器对象,且容器中的元素可以通过__iter__( )方法或__getitem__( )方法访问. __i ...
- 第8.26节 重写Python类中的__getattribute__方法实现实例属性访问捕获
一. 引言 在<第7.23节 Python使用property函数定义属性简化属性访问的代码实现>和<第7.26节 Python中的@property装饰器定义属性访问方法gette ...
- Shiro remeberMe反序列化漏洞复现(Shiro-550)
Apache Shiro是一个强大易用的Java安全框架,提供了认证.授权.加密和会话管理等功能.Shiro框架直观.易用,同时也能提供健壮的安全性.在Apache Shiro编号为550的 issu ...
- SSH无密码登陆
http://blog.chinaunix.net/uid-26284395-id-2949145.html
- 一文看懂 Kubernetes 服务发现: Service
Service 简介 K8s 中提供微服务的实体是 Pod,Pod 在创建时 docker engine 会为 pod 分配 ip,"外部"流量通过访问该 ip 获取微服务.但 ...
- maven私有仓库搭建(nexus)
搭建是参考博客:https://blog.csdn.net/zn353010922/article/details/79441122 切换到nexus目录的bin下 启动.状态.停止:./nexus ...
- web前端常用js插件
第一款:截图插件html2Canvas.js html2是一款强大的截图插件,只需引入js文件,依照官方给定的截图方法,就能截取对应DOM区域的内容.对于有些截图出现模糊偏移的问题,网上也有一堆解决方 ...
- 新手入门 : Windows Phone 8.1 开发 视频学习地址
本视频资源来自Microsoft Virtual Academy http://www.microsoftvirtualacademy.com/ 下面为视频下载地址! 新手入门 : Windows P ...
- linux环境下jdk安装以及配置
linux 环境安装jdk和配置环境变量: (此处以root用户安装,此方式安装一台虚拟机装一个jdk即可,所有普通用户可以共用) 1.下载安装jdk 链接: https://pan.baidu.co ...