(数据科学学习手札95)elyra——jupyter lab最强插件
本文示例文件已上传至我的
Github仓库https://github.com/CNFeffery/DataScienceStudyNotes
1 简介
jupyter lab是我最喜欢的编辑器,在过往的文章中也给大家介绍过很多相关资源和实用插件,但本文要给大家介绍的jupyter lab插件elyra,绝对是我使用过的最强大的jupyter lab插件没有之一,因为它的核心功能就是帮助我们解决数据分析工作中非常重要的问题——搭建工作流。
 图1
图1
2 利用elyra搭建工作流
在安装elyra插件集之前,请确保你的jupyter lab版本在2.0及以上,并且已经安装好了nodejs也就是所有jupyter lab拓展插件都需要的依赖。
不像常规的jupyter lab插件的安装方法,我们执行下列命令即可安装elyra下集成的多个插件:
pip install --upgrade elyra && jupyter lab build
安装完之后,你的jupyter lab操作界面外观会发生一些变化,我们先记住在安装elyra之前我们的jupyter lab界面长啥样(我使用的主题感兴趣的朋友可以通过jupyter labextension install jupyterlab-tailwind-theme来安装):
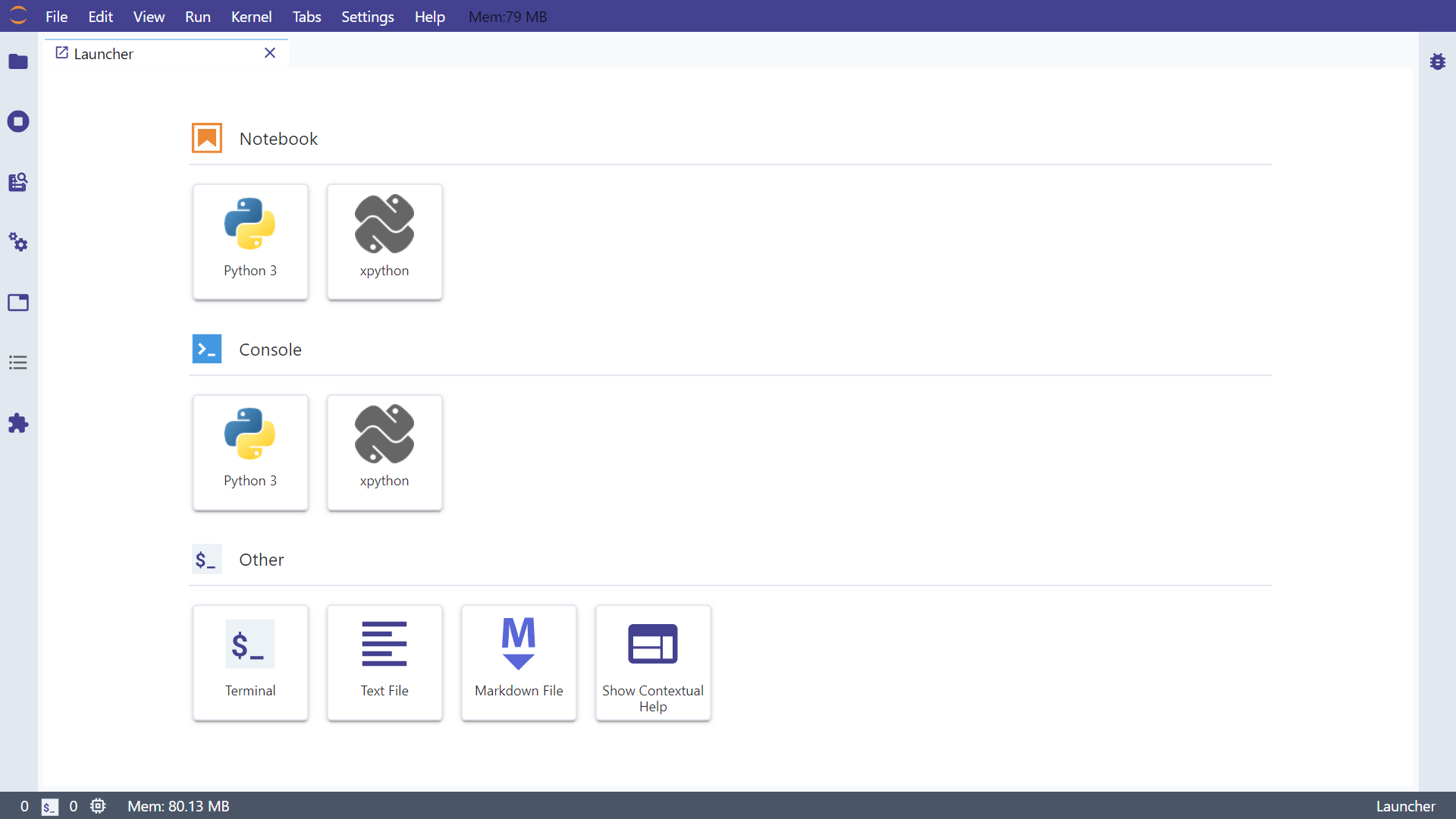 图2
图2
而在安装完成重启jupyter lab之后,除了左上角的jupyterlogo变化了之外,还新增了图中我用红框框选出来的地方:
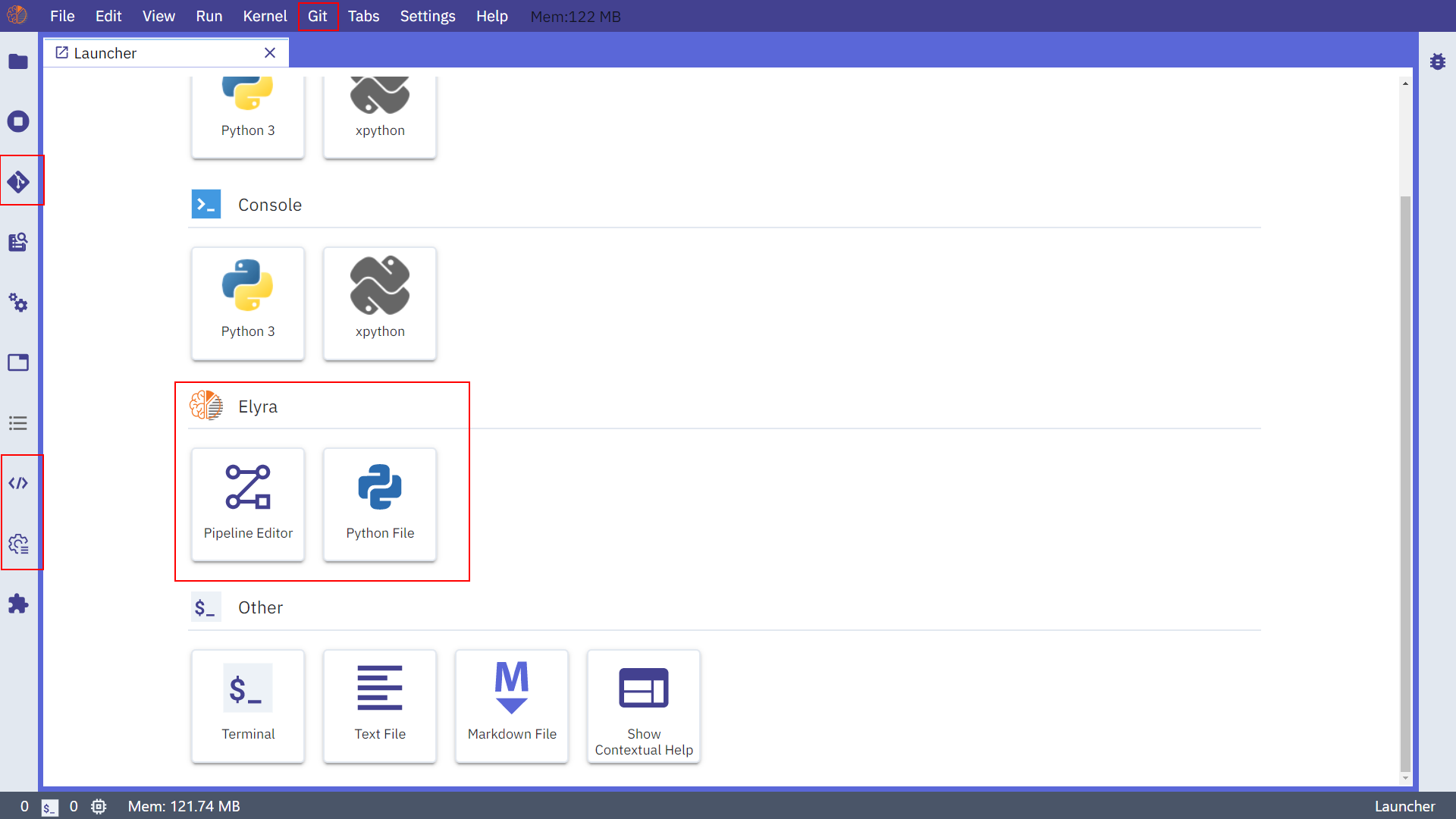 图3
图3
接下来我们就来介绍如何利用elyra交互式地搭建工作流。
elyra赋予了我们通过交互的方式将若干个ipynb文件组织成工作流的能力,为了方便演示,这里我们创建几个带有简单流程代码的ipynb文件:
 图4 step1.ipynb
图4 step1.ipynb
 图5 step2.ipynb
图5 step2.ipynb
 图6 step2-1.ipynb
图6 step2-1.ipynb
 图7 step2-2.ipynb
图7 step2-2.ipynb
接着我们在Launcher页面点击Pipeline Editor打开用来交互式编辑notebook流水线的界面:
 图8
图8
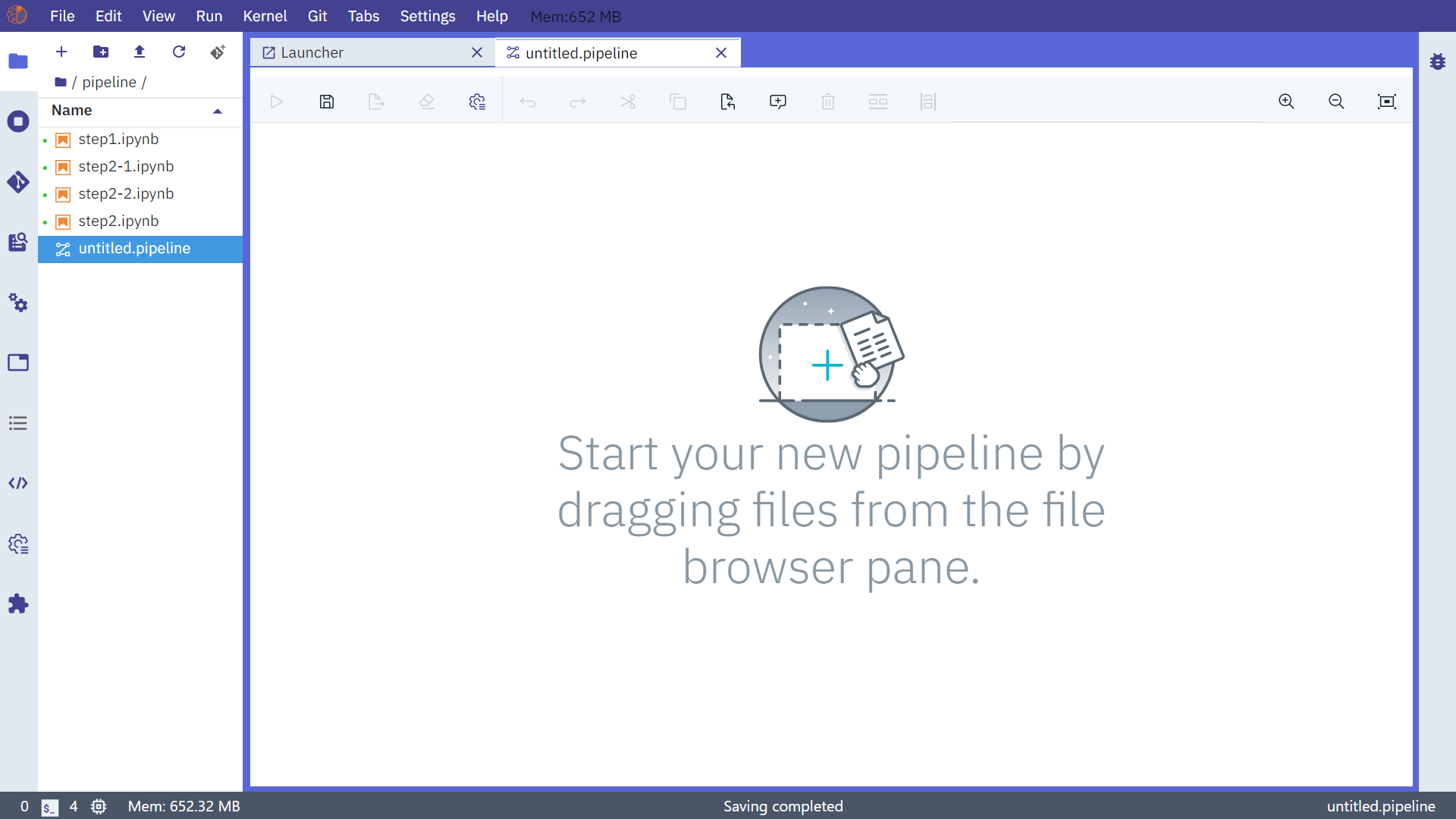 图9
图9
直接将侧边栏中对应的step1.ipynb文件拖拽进来:
 图10
图10
点击流水线界面中ipynb文件对应节点右侧的三个圆点,可以打开更多功能选项:
 图11
图11
因为我们是本地环境,所以这里只需要在properties下必填参数Runtime Image中随便选一个就行:
 图12
图12
保存之后,就完成了本地环境下单个节点的必要参数设置,同样的将其他ipynb文件拖拽进来,各自配置好必要参数再如图13所示将各节点联结起来:
 图13
图13
这样我们的流水线就搭建好了,是不是非常滴好玩~,接着点击左上角的运行按钮,输入流水线名称后即可开始运行我们的工作流:
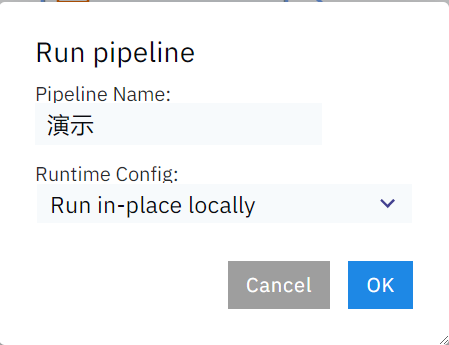 图14
图14
工作流执行成功之后也会有提示:
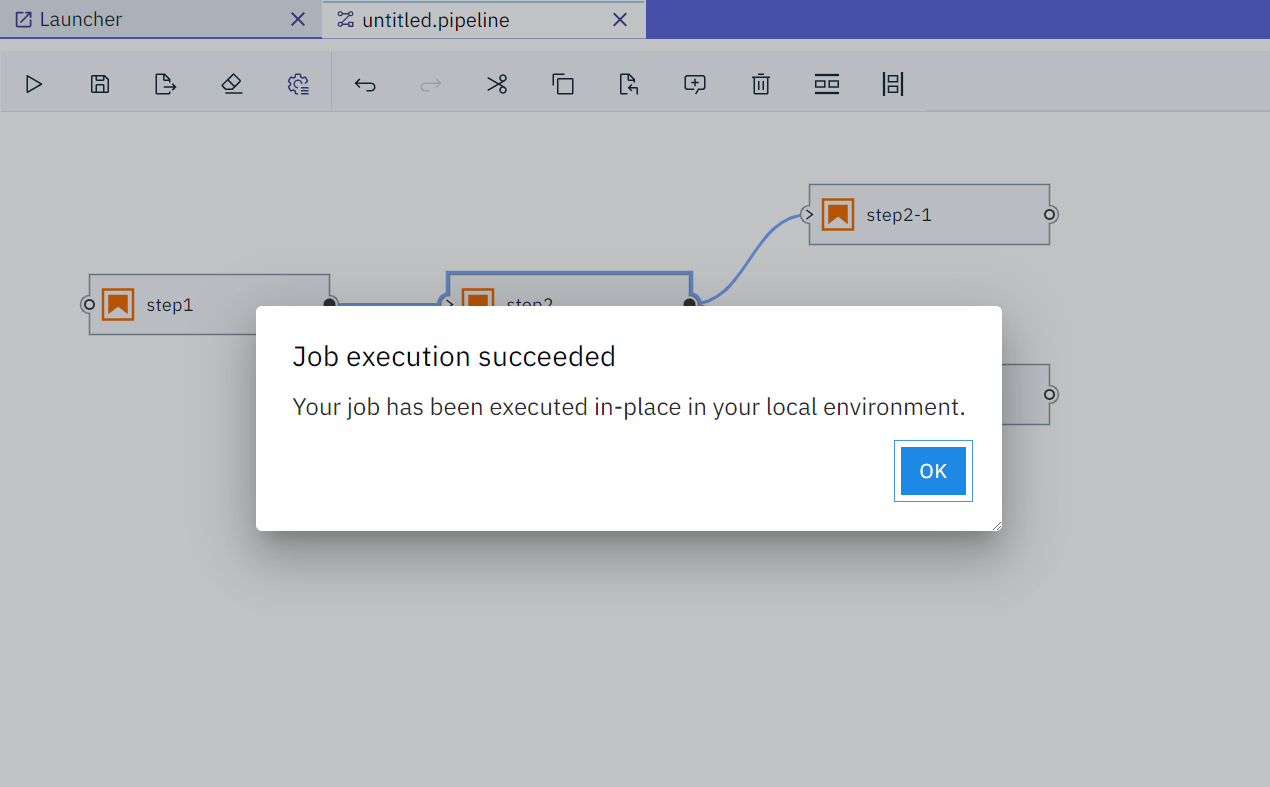 图15
图15
如果工作流执行到某个节点发生程序错误,也会有非常人性化的提示:
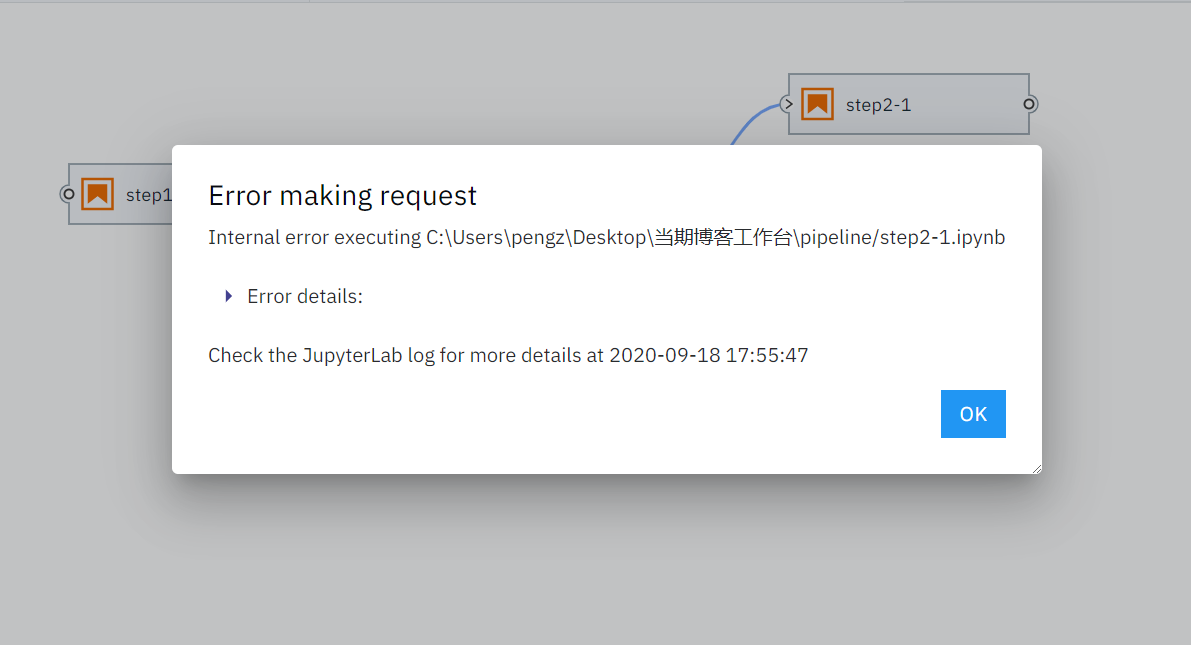 图16
图16
对应出错的ipynb错误代码块上方,elyra也会帮我们创建记录错误信息的markdown单元格:
 图17
图17
最好用的是,配合魔术命令%store,我们就可以跨notebook传递全局变量,而不需要再往外写出先前节点的结果文件:
利用%store 变量名将某个变量转化为跨kernel的全局变量:
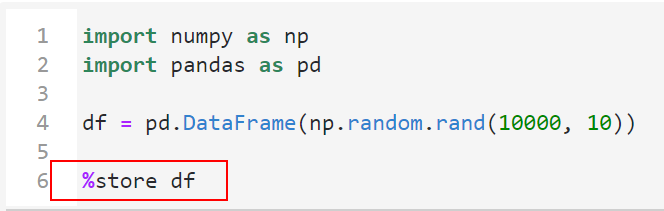 图18
图18
利用%store -r 变量名将跨kernel全局变量中的指定变量加载到当前kernel中:
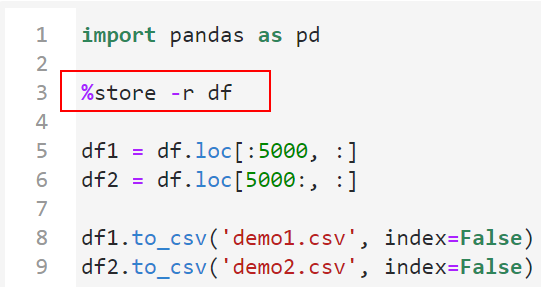 图19
图19
而除了搭建工作流这个核心功能外,elyra还有很多其他的实用功能,感兴趣的朋友可以前往官方文档(https://elyra.readthedocs.io/en/latest/)自行阅读学习。
 图20
图20
以上就是本文的全部内容,欢迎在评论区与我进行讨论~
(数据科学学习手札95)elyra——jupyter lab最强插件的更多相关文章
- (数据科学学习手札95)elyra——jupyter lab平台最强插件集
本文示例文件已上传至我的Github仓库https://github.com/CNFeffery/DataScienceStudyNotes 1 简介 jupyter lab是我最喜欢的编辑器,在过往 ...
- (数据科学学习手札69)详解pandas中的map、apply、applymap、groupby、agg
*从本篇开始所有文章的数据和代码都已上传至我的github仓库:https://github.com/CNFeffery/DataScienceStudyNotes 一.简介 pandas提供了很多方 ...
- (数据科学学习手札72)用pdpipe搭建pandas数据分析流水线
1 简介 在数据分析任务中,从原始数据读入,到最后分析结果出炉,中间绝大部分时间都是在对数据进行一步又一步的加工规整,以流水线(pipeline)的方式完成此过程更有利于梳理分析脉络,也更有利于查错改 ...
- (数据科学学习手札75)基于geopandas的空间数据分析——坐标参考系篇
本文对应代码已上传至我的Github仓库https://github.com/CNFeffery/DataScienceStudyNotes 1 简介 在上一篇文章中我们对geopandas中的数据结 ...
- (数据科学学习手札55)利用ggthemr来美化ggplot2图像
一.简介 R中的ggplot2是一个非常强大灵活的数据可视化包,熟悉其绘图规则后便可以自由地生成各种可视化图像,但其默认的色彩和样式在很多时候难免有些过于朴素,本文将要介绍的ggthemr包专门针对原 ...
- (数据科学学习手札50)基于Python的网络数据采集-selenium篇(上)
一.简介 接着几个月之前的(数据科学学习手札31)基于Python的网络数据采集(初级篇),在那篇文章中,我们介绍了关于网络爬虫的基础知识(基本的请求库,基本的解析库,CSS,正则表达式等),在那篇文 ...
- (数据科学学习手札49)Scala中的模式匹配
一.简介 Scala中的模式匹配类似Java中的switch语句,且更加稳健,本文就将针对Scala中模式匹配的一些基本实例进行介绍: 二.Scala中的模式匹配 2.1 基本格式 Scala中模式匹 ...
- (数据科学学习手札47)基于Python的网络数据采集实战(2)
一.简介 马上大四了,最近在暑期实习,在数据挖掘的主业之外,也帮助同事做了很多网络数据采集的内容,接下来的数篇文章就将一一罗列出来,来续写几个月前开的这个网络数据采集实战的坑. 二.马蜂窝评论数据采集 ...
- (数据科学学习手札44)在Keras中训练多层感知机
一.简介 Keras是有着自主的一套前端控制语法,后端基于tensorflow和theano的深度学习框架,因为其搭建神经网络简单快捷明了的语法风格,可以帮助使用者更快捷的搭建自己的神经网络,堪称深度 ...
随机推荐
- SSM整合 完美支持RESTful(Jsp和客户端<android ios...>)
一 RESTful简介 RESTful是一种网络应用程序的设计风格和开发方式 它结构清晰 符合标准 易于理解 扩展方便 REST 即Representational State Transfer的缩写 ...
- 解决SpringBoot页面跳转无法访问静态资源的问题
初学SpringBoot,写项目的时候遇到了问题,原本的页面是这样的 但启动项目后是这样的 这是因为thymeleaf中引入静态资源及模板需要使用到 th:xxx 属性,否则无法在动态资源中访问静态资 ...
- Magento 2 instantiate object by Factory Objects
magento2的Factory Objects是用来实例化non-injectable classes,目前还不知道什么叫non-injectable classes. 可以用它来实例化Helper ...
- 算法-图(1)Dijkstra求最短路径
数组dist[],是当前求到的顶点v到顶点j的最短路径长度 数组path[]存放求到的最短路径,如path[4]=2,path[2]=3,path[3]=0,则路径{0,3,2,4}就是0到4的最短路 ...
- 团队作业4:第一篇Scrum冲刺博客(歪瑞古德小队)
目录 一.Alpha阶段任务认领 二.明日任务安排 三.项目预期任务量 四.敏捷开发前的感想 五.团队期望 Author:歪瑞古德小队 Project:海岛漂流 集合贴:团队作业4:项目冲刺集合贴(歪 ...
- Communication-Efficient Learning of Deep Networks from Decentralized Data
郑重声明:原文参见标题,如有侵权,请联系作者,将会撤销发布! Proceedings of the 20th International Conference on Artificial Intell ...
- Java枚举简述
Java 枚举(enum) Java 枚举是一个特殊的类,一般表示一组常量,比如一年的 4 个季节,一个年的 12 个月份,一个星期的 7 天,方向有东南西北等. Java 枚举类使用 enum 关键 ...
- js区别对象和数组的三种方法
var arr = {}||[]; 区分arr是数组还是对象 1.arr.constructor ...
- ARM开发板实现双系统引导的一种方法——基于迅为iTOP-4412开发板
前言 本文所用的uboot代码为迅为官方提供,开发板是迅为iTOP-4412开发板.本文如有错误,欢迎指正. 首先,我们确定一下系统启动的流程:首先启动uboot,uboot启动内核并挂载rootfs ...
- java生成四位随机数,包含数字和字母 区分大小写,特别适合做验证码,android开发
private String generateWord() { String[] beforeShuffle = new String[] { "2", "3" ...