kafka(三)原理剖析
一、生产者消息分区机制原理剖析
在使用Kafka 生产和消费消息的时候,肯定是希望能够将数据均匀地分配到所有服务器上。比如很多公司使用 Kafka 收集应用服务器的日志数据,这种数据都是很多的,特别是对于那种大批量机器组成的集群环境,每分钟产生的日志量都能以 GB 数,因此如何将这么大的数据量均匀地分配到 Kafka 的各个 Broker 上,就成为一个非常重要的问题。
1.1、kafka为什么分区?
kafka有主题(Topic)的概念,它是承载真实数据的逻辑容器,而在主题之下还分为若干个分区,kafka的消息组织方式是三级结构:主题 - 分区 - 消息。主题下的每条消息只会保存在某个分区中,而不会在多个分区中被保存多份。

分区的作用就是提供负载均衡的能力,就是为了实现系统的高伸缩性。不同的分区能够被放置在不同节点的机器上,而数据的读写操作也都是针对分区这个粒度而进行的,这样每个节点的机器都能独立地执行各自的分区的读写请求处理。还可以添加新的节点机器来增加整体系统的吞吐量。
利用分区也可以实现其他一些业务级别的需求,比如实现业务级别的消息顺序的问题。
1.2、kafka生产者分区策略
所谓分区策略是决定生产者将消息发送到哪个分区的算法。kafka为我们提供了默认的分区策略,同时也支持自定义分区策略。自定义分区策略需要显式地配置生产者端的参数partitioner.class。
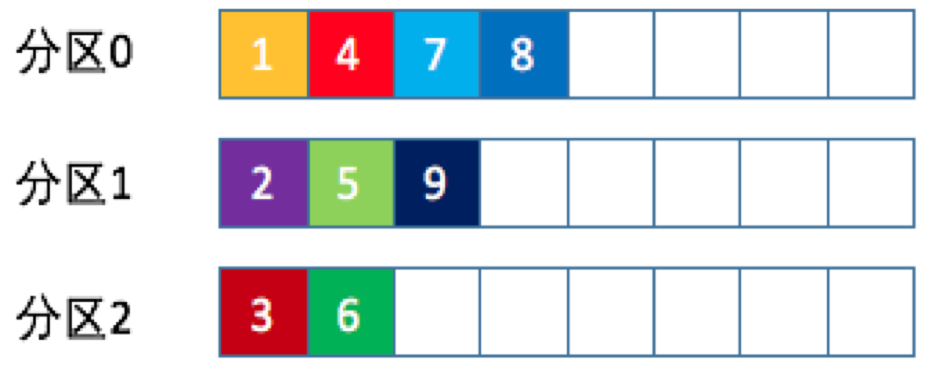
1.2.1、轮询策略
也称Round-robin策略,即顺序分配。比如一个主题下有3个分区,那么第一条消息被发送到分区0,第二条消息被发送到分区1,第三条被发送到分区2,以此类推。当第四条消息时又会重新开始,即分配到分区0。

轮询策略是kafka java生产者API默认提供的分区策略。如果未指定partitioner.class参数,那么你的生产者程序会按照轮询的方式在主题的所有分区均匀地“码放”消息。
轮询策略有非常优秀的负载均衡表现,它总是能保证消息最大限度地被平均分配到所有分区上,故默认情况下它是最合理的分区策略,也是最常用的分区策略之一。
1.2.2、随机策略
也称Randomness策略。所谓随机就是随意地将消息放置到任意一个分区上。
要实现随机策略只需要:先计算出该主题总分区数,然后随机返回一个小于它的整数值。从实际表现看,随机策略要逊于轮询策略,所以如果追求数据的均匀分布,还是使用轮询策略比较好。事实上,随机策略是老版本生产者使用的分区策略,在新版中已经改为轮询。
1.2.3、按消息键保序策略
kafka允许为每条消息定义消息键,简称Key。它可以是一个有着明确业务含义的字符串,比如客户代码、部门编号或是业务ID等;也可以用来表征消息元数据,特别是在kafka不支持时间戳的年代,在一些场景中,直接将消息创建时间封装进Key里面。
一旦消息被定义了Key,那么你就可以保证同一个Key的所有消息都进入到相同的分区里面,每个分区下的消息处理都是有顺序的,如下图所示:
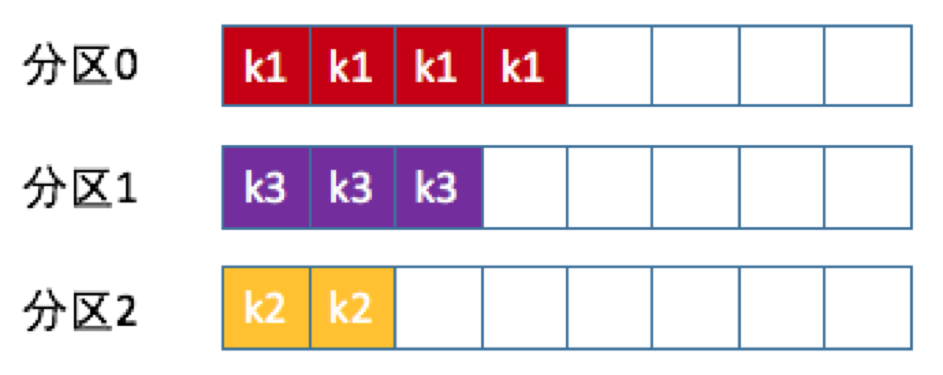
前面提到的kafka默认分区策略实际上同时实现了两种策略:如果指定了Key,那么默认实现按消息键保序策略;如果没有指定Key,则使用轮询策略。
kafka(三)原理剖析的更多相关文章
- Kafka底层原理剖析(近万字建议收藏)
Kafka 简介 Apache Kafka 是一个分布式发布-订阅消息系统.是大数据领域消息队列中唯一的王者.最初由 linkedin 公司使用 scala 语言开发,在2010年贡献给了Apache ...
- 《java学习三》并发编程 -------线程池原理剖析
阻塞队列与非阻塞队 阻塞队列与普通队列的区别在于,当队列是空的时,从队列中获取元素的操作将会被阻塞,或者当队列是满时,往队列里添加元素的操作会被阻塞.试图从空的阻塞队列中获取元素的线程将会被阻塞,直到 ...
- 开源 serverless 产品原理剖析 - Kubeless
背景 Serverless 架构的出现让开发者不用过多地考虑传统的服务器采购.硬件运维.网络拓扑.资源扩容等问题,可以将更多的精力放在业务的拓展和创新上. 随着 serverless 概念的深入人心, ...
- ASP.NET Core 运行原理剖析1:初始化WebApp模版并运行
ASP.NET Core 运行原理剖析1:初始化WebApp模版并运行 核心框架 ASP.NET Core APP 创建与运行 总结 之前两篇文章简析.NET Core 以及与 .NET Framew ...
- 【Xamarin挖墙脚系列:Xamarin.IOS机制原理剖析】
原文:[Xamarin挖墙脚系列:Xamarin.IOS机制原理剖析] [注意:]团队里总是有人反映卸载Xamarin,清理不完全.之前写过如何完全卸载清理剩余的文件.今天写了Windows下的批命令 ...
- 【Xamarin 跨平台机制原理剖析】
原文:[Xamarin 跨平台机制原理剖析] [看了请推荐,推荐满100后,将发补丁地址] Xamarin项目从喊口号到现在,好几个年头了,在内地没有火起来,原因无非有三,1.授权费贵 2.贵 3.原 ...
- iPhone/Mac Objective-C内存管理教程和原理剖析
http://www.cocoachina.com/bbs/read.php?tid-15963.html 版权声明 此文版权归作者Vince Yuan (vince.yuan#gmail.com)所 ...
- 【Xamain 跨平台机制原理剖析】
原文:[Xamain 跨平台机制原理剖析] [看了请推荐,推荐满100后,将发补丁地址] Xamarin项目从喊口号到现在,好几个年头了,在内地没有火起来,原因无非有三,1.授权费贵 2.贵 3.原生 ...
- ASP.NET Core 运行原理剖析
1. ASP.NET Core 运行原理剖析 1.1. 概述 1.2. 文件配置 1.2.1. Starup文件配置 Configure ConfigureServices 1.2.2. appset ...
随机推荐
- js上 十八、字符串
十八.字符串 #18.1.认识字符串 #什么是字符串 字符串可以是引号中的任意文本.字符串可以由双引号(")或单引号(')表示 ,如 'hello' , "中国" #为什 ...
- kubernetes环境搭建 -k8s笔记(一)
一.环境准备 1.硬件及版本信息: cpu&内存:2核心,2G 网络: 每台vm主机2块网卡,一块NAT用于上网,别一块配置成 "仅主机模式",网段为192.168.100 ...
- Python爬取房天下二手房信息
一.相关知识 BeautifulSoup4使用 python将信息写入csv import csv with open("11.csv","w") as csv ...
- 老吕教程--02后端KOA2框架自动重启编译服务(nodemon)
上一篇讲完搭建Typescritp版的Koa框架后,F5运行服务端,页面进行正常显示服务. 今天要分享的是,如果要修改服务端代码,如果让编译服务自动重启,免去手动结束服务再重启的过程. 自动重启服务需 ...
- 什么是可变参数?如何创建不可变集合?Steam三类方法是什么?获取流方法特点?流中间方法特点?终结流方法特点?
==知识梳理== ==重难点梳理== ==今日目标== 1.能够了解什么是可变参数 2.能够了解如何去创建不可变集合 3.能够掌握Stream流的使用 ==知识点== 1.可变参数 2.Stream流 ...
- 使用OpenOffice实现文档预览
概述 使用OpenOffice将 office文档转为pdf,然后再将pdf转为图片,实现文档预览的功能. 依赖组件 OpenOffice.org或者LibreOffice JODConverter ...
- Linux腾讯云下安装mysql
百度云盘下载地址https://pan.baidu.com/s/1MqUEdeqZuQbq-veLuVItQQ 将下载好的mysql-5.7.14-linux-glibc2.5-x86_64.tar. ...
- Spring Boot中初始化资源的几种方式
CommandLineRunner 定义初始化类 MyCommandLineRunner 实现 CommandLineRunner接口,并实现它的 run()方法,在该方法中编写初始化逻辑 注册成Be ...
- jq 右键菜单在弹出菜单前如果需要显示与否的判断相关操作
菜单插件(ContextMenu)接收一个额外的参数对象来设置菜单项的样式和绑定鼠标事件. 菜单插件(ContextMenu)支持一下参数设置: bindings 包含id的对象:函数组. 当关联的菜 ...
- hive on spark:return code 30041 Failed to create Spark client for Spark session原因分析及解决方案探寻
最近在Hive中使用Spark引擎进行执行时(set hive.execution.engine=spark),经常遇到return code 30041的报错,为了深入探究其原因,阅读了官方issu ...