阙乃祯:网龙在教育领域Cassandra的使用
网龙是一家游戏公司,以前是做网络在线游戏的,现在开始慢慢转型,开始从事在线教育。 在线教育已经做了5-6年时间了。为什么我们会用Cassandra呢?那我们就来介绍今天的议题。 首先介绍我们的业务背景, 第二部分深入介绍使用场景,然后介绍运维监控。 最后,我们实践过程中有踩一些坑,这些坑我们拿来分享一下。
关于业务背景。网龙现在是一家在线教育公司。我们的很多app, 比如说“网教通” IM推送服务,还有一些针对智慧校园和智慧教室的物联网服务, 这些服务每天会产生数据达十亿条, 我们设计选型上曾经考虑过MongoDB,但是它无法处理这样大的数据量,所以我们就需要上一套大规模支持这种业务场景的NoSQL集群,因此选择了 Cassandra数据库。
Cassandra数据库部署灵活。 我们有些To G 项目是针对海外的国家或地方政府,他们对数据安全性要求非常高,他们都要求我们去他们当地做私有化部署。私有化部署的出差成本比较高。用一些其他比较复杂的NoSQL数据库,比如HBase的话,运维和部署会比较困难。Cassandra在这方面比较灵活,部署比较简单, 可以节约很多部署成本。还有,我们的业务需要一些混部, 比如私有云和公有云的混部,或是跨数据中心的全球化部署, Cassandra在数据同步和跨DC 混合部署方面是比较灵活的。
还有就是它极致的写性能。针对我们的产品IM、PUSH、IOT,这种带有时间序列的数据,写性能要求非常高,可能达到每秒几十万的写性能。但我们又不需要太复杂的查询, 就是做一些KV或者范围的查询。这些查询Cassandra是可以轻松应付的。针对这个场景,Cassandra是非常适合我们的,所以我们选择了它。

下面介绍我们的存储场景。存储有用户和设备的数据,有用户信息和设备信息。我们IM的收件箱,像微信等app, 每个用户有自己的收件箱。我们会把收件箱写在Cassandra里面。还有通信产生的消息内容,这也是海量的,我们也把它存储到Cassandra里面。还有IoT设备上报的监控数据,比如学生的平板电脑,学生的手表,或是智慧教室的其他IoT (灯, 投影仪,会议系统,还有其他边缘计算的设备)。它们会实时产生一些监控数据,对这些数据我们要保存一段时间, 这些我们也收集到Cassandra里面来。

下面介绍我们的设备表是如何设计的。设备信息表,里面有app_id, shard_idx, dev_token。下面这一列是设备的一些属性,比如说token, 别名,还有标签,订阅的主题, 包名。 还有ack_id。 我们设计的主键是app_id, 和shard_idx作为副维主键。 添加shard_idx是为避免热点和分区数据过大问题。通过shard分区,把它打散。比如某一个app_id数据量非常大,一个app_id可以分成64份,这样可以解决这个问题。
一些查找会根据设备码查找设备信息,这样就没有建立二级索引,我们通过逆范式新增设备查找表。如果使用Cassandra二级索引,用起来会有一些问题,比如写失败。在扩容时,二级索引会非常困难。所以我们没有使用二级索引。
还有,我们使用了map来存储比较灵活的KV数据,比如标签数据。我们会给设备打一个标签,比如地区的标签、版本的标签、语言的标签、或者用户自定义的标签。我们也可以把订阅的主题以map的形式组织起来。这是我们的设备信息表。

我们的收件箱表分成两份,一个是“广播收件箱表”, 一个是“个人收件箱表”。 广播收件箱是对整个app_id进行推送的时候, 这个app_id下的所有设备或所有的用户都能收到的信息。这样的话,只需要写一条收件箱,不需要写每个人的收件箱,避免了一条消息被无限地放大。我们对收件箱按月份进行了分表,一年分成12个月,我们会有12张表保存1年的数据。为什么这么做?主要是因为表太大的话,归档起来会比较困难。 如果没有分表的话,可能好几年好几月的数据都放在一起了。(分表了的话,)早一些年的数据你想随时调出来,或把它删掉,或把它清理出去,就可以根据这些归档好的分表进行操作,只需要针对一张表操作就可以了,不会影响线上的业务。
我们也会添加shard_idx,避免热点问题。对于分区大小和值的数量,Cassandra有一些限制:分别是100MB和20亿的限制。(我们的)排序键DESC是逆序的形式,保证读到最新数据,在range scan时可以减轻磁盘压力,提升读性能。时间序列数据大部分场景都是这样设计的。
“个人收件箱”的设计和“广播收件箱”是差不多的。每个人有一个收件箱。一对一的聊天时把消息发给对方的话,只有一个人会收到。“个人收件箱”也和“广播收件箱”一样,这里和广播收件箱表一样,app_id和shard_idx也是作为复合主键,而稍有不同的是,dev_token和msg_id作为副键。

“消息表“有2种。一种是消息原文表,一种是IoT监控表。消息表我们也是通过年份进行归档,防止表太大导致运维困难。数据过期时可以直接TRUNCATE整张表。
对Msg_data,我们先压缩完再写入,因为数据太大的话对磁盘空间还是有影响的。 我们希望磁盘可以节约空间,不必经常扩容。
我们设置ttl, 可以让数据自动过期。 这些是可以和业务绑定的ttl。 有些用户推完消息后,希望接收方一天内收到消息是有效的,或者是1个月内收到消息是有效的,所以这张表就有ttl了。ttl就有墓碑的问题,我们需要及时清理掉这些墓碑。 我们把gc_grace_seconds设置为1天。默认是10天。 我们尽早在压缩时及时清理墓碑数据。
Flag 由QoS & retain flag 两列合并成一列。Cassandra是列存储的,写入的时候列越多,实际的性能是越差的,所以我们把能合并的列尽量合并成一列。(这样可以节约空间和提升写入性能。)
我们的IoT监控表也是差不多的设计。为了更节约空间,直接把列缩写成2个字母,这样的好处是也能节约一部分的空间。但是这张表的可读性就更差了,自己还需要一个数据字典去对照。

我们怎么连接数据库? 我们现在是用 Driver 3.x 版本。 Driver 3.x 版本我们已经用了好几年了,不敢把它替换掉,它相对比较稳定。连接数据库时, 我们一般会开启线程池,最大节点会设置4个连接,一个连接最大请求配置为9120,默认是1024,(默认)可能会不够用。
负载均衡默认 DCAwareRoundRobinPolicy ,看一致性级别配置shuffleReplicas。如果为false,就是同一个token的数据都请求到同一节点,这样可以在一定程度上解决数据一致性问题。为什们这么说呢? 比如说, 我删除 UID=1, 时间是2的数据,删除完后我又写,写完我又再读, 读完之后如果没有配置的话,它可能会飘到其他节点。因为时间非常短, 前面写入,到另一个节点去读的时候, 会读到不一样的数据。 如果把数据请求到同一节点,读到的数据就是最新的。
但这有个问题,如果机器出现问题,它会重试,当你出错的时候,你还是会请求到这个节点, 所以无论你如何重试, 还是会失败的。 所以有一个默认是 true, 适合超时重试的场景, 需要通过其他的方式解决数据一致性问题。比如使用QUORUM读写,也就是写的时候先写2个副本,读的时候再读2个副本, 来解决这样的问题。
下面看一下Driver 4.x版本的高性能客户端。 这个客户端,我们希望集群能支持设置代理服务。当Cassandra集群部署到内网,想在公网去访问它的时候,可以通过设置代理地址来实现。Driver 4.x是高性能客户端,默认开启线程池,它对此进行了一些优化,全部都是异步请求的。
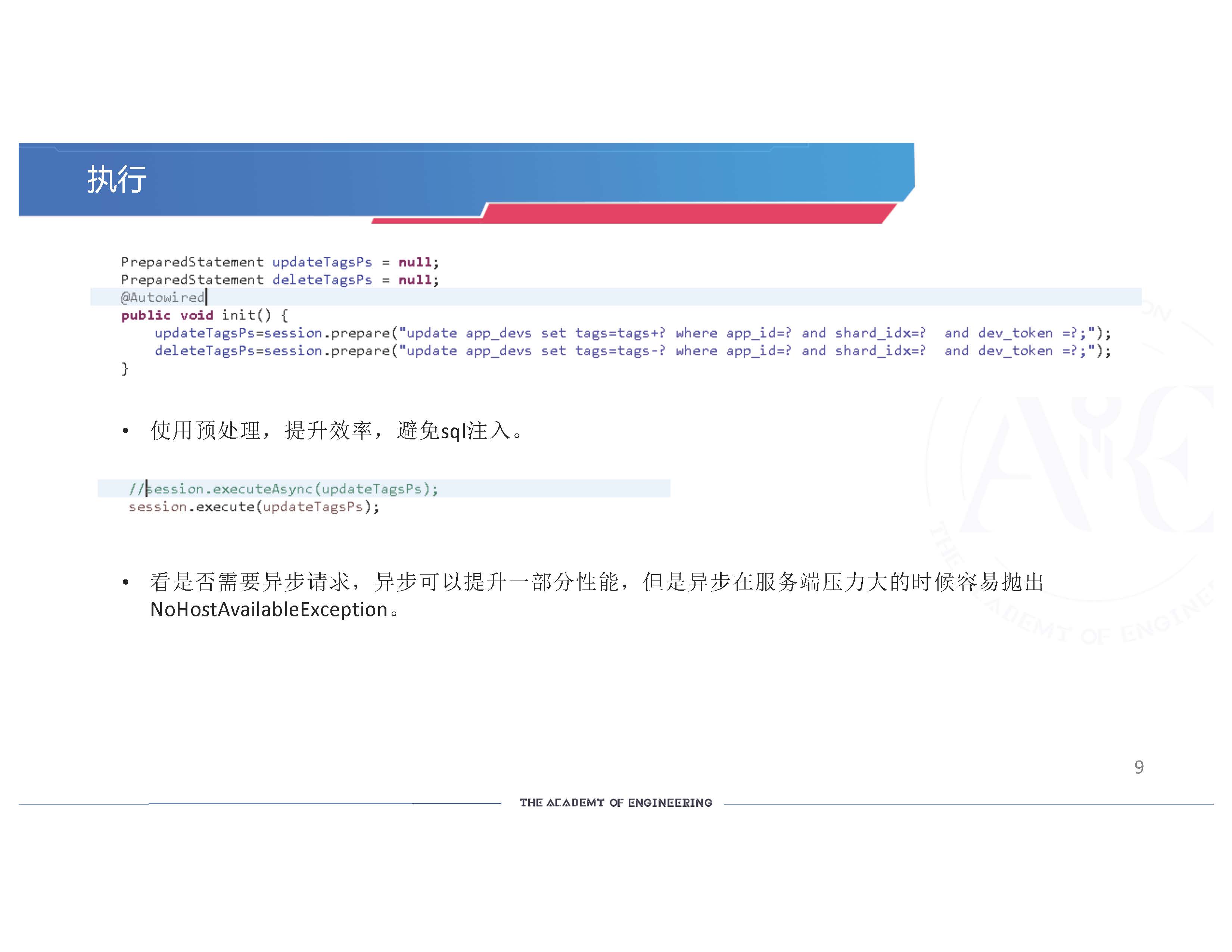
连接完数据库,我们进行执行操作。使用预处理,提升效率,避免SQL注入。我们没有使用异步请求,因为我们觉得同步请求的性能已经足够了。 如果使用异步请求的话,异步可以提升一部分性能,可能10-20%, 但是异步在服务端压力大的时候容易抛出异常- NoHostAvailableException 主机不可用。这是我们实际遇到的问题,别人可能不一定遇到。

写入和查询有一个很重要的慢查询诊断工具。像MySQL或者Postgres其他数据库有查询分析器,用来诊断查询语句,有没有走索引等问题。这些利器可以帮助诊断线上的问题。 比如你经常抛出超长时间的请求, 有这个工具就可以查看在哪个阶段出现这样的问题, Cassandra的driver 提供了这个查询跟踪功能。 怎么用? 要开启tracing就能使用,看示例代码 -- stmt.enableTracing( )。
当你开启的时候,每个请求就会产生 session id 和 event id,这个id 会带我们跟踪的,会把每个请求的阶段,数据打印出来,比如解析这条语句花了55微秒, prepare statement 花了93微秒, 从其他节点读数据过来花了200多微秒,这一整串数据下来我们就知道我们这个请求发送到Cassandra服务端它是怎么处理的, 处理的每个步骤耗费了多少时间, 就一目了然了。 当我们线上出现慢查询的时候, 就可以通过这种方式写代码,探测一下发生了什么事情, 为什么会这么慢。

写入和查询的时候要避免一些东西。 比如,避免使用批处理。 批处理Batch,就是一次提交多个修改操作,节省传输请求的资源消耗。同时也可以理解为一种事务的解决方案——all or nothing,这些操作可以保证要么都成功,要么都不成功,即原子性。但Cassandra 的批处理Batch这个功能不是用来提升性能使用的,特别是提交到不同分区,性能会有一定拖累。如果数据不是很重要,没有必要原子性, 代码就可以这么写,但要关闭batchlog或者改成异步提交。
怎么关闭batchlog? 就用BatchStatement batch = new BatchStatement (Type.UNLOGGED), 这样就不记录batchlog, 它就通过异步提交的形式提交上去。这时候它在性能方面就会好一点。但我还是建议,如果你的业务场景一定要求你是原子性的,你就用批处理;但如果你的业务场景不是原子性的,只是单纯的为了提升性能,就没有必要,会得不偿失。
我们可以看到我们的日志里,经常会有一些警告,我们的业务, 比如说收件箱它提交的5520大小的批处理, 超过了它的默认配置,日志里就会看到一堆的警告,到一定程度上, 到集群负载比较高的时候,它会拖累整个集群, 造成整个集群性能的下降。所以我们不建议这么用。

还有就是查询的时候,我们经常会很不负责任地去写一个查询,SELECT * FROM表,WHERE, 然后ORDER BY 它的时间序, LIMIT 1。这看似一个很简单的查询,我们只读最小的一条数据或最大的一条数据。 一条很简单的语句,实际看起来不会有什么性能问题,我们的业务有很多人这样使用。大家刚开始这么用的时候很开心,写代码很简单,也没有什么性能问题。但是运行久了之后, 比如运行了1年,2年之后,就会发现这条语句怎么变得越来越慢?
那是因为这条语句本身就是有问题的。 因为它没有明确指定这条数据的范围, 没有指定这条数据在哪个 sstable 里。 这样写的话, 像这条语句ORDER BY inserttime, 只要每个分区里有这个userid =2, 每个sstable 都有可能被读到。这时你就会被无限地放大。 比如说这张 inbox表,本来在集群里每个节点上可能有100个sstable,你可能每个sstable都要去读,你就会放大100倍。这样读出来就很慢。
因为读的时候, 它首先会被过滤一下。 过滤失败,它会在 db.index 里去找, 在 db.index 里首先寻找分区键, 分区键里只要查找到userid =2的数据, 它就会到数据库sstable 里把最小和最大的查出来, 可能会把每个sstable都查出来,查100条数据,然后再进行对比, 极易导致GC。
我们在这边的截图可以看到,“Select * FROM exam.inbox WHERE userid=2 ORDER BY insertime ASC LIMIT 1”。我们测试的这个数据库有3个sstable, 但是这3个sstable都被命中了, “skipped 0”, 就是说,它查了3个sstable。
(另一个截图里,) 这边是,ORDER BY insertime DSC。它也是3个都命中了。 所以说,在这种情况下就把查的结果放大了好几倍。 这样极易导致GC。这里我们给Cassandra提一个建议,能否优化查询, SliceQueryFilter可以根据上次sstable查询结果的key值拿到下一个sstable,把下一个过滤一下,这样避免查找下一个 sstable 。

我们建议在写入和查询的时候,使用ORDER BY 的时候尽量指定 key range。像前面那条语句, “SELECT * FROM exam.inbox WHERE userid =2 AND insertime >3 ORDER BY insertime DESC LIMIT 1”, 这里我们就指定了”insertime >3”的范围。 这里我们可以看到结果,它可以skip 2个sstable, 性能有所提升。 因为它只查找了1个sstable, 只到一个sstable上去读数据,没有读3个sstable。

最精准的查询,我们可以指定一个完整的key,就是KV查询。这时候 Bloom Filter就可以很好地起作用了,会把每一个sstable先作一次过滤。这条数据有没有? 没有的话就不会继续查找了。
我们可以看到Cassandra数据库的SSTable的组成文件,这里有Filter.db和Index.db。 查找数据先是Bloom Filter过滤一下,过滤完之后如果存在,它会通过Index.db去查找一下这个数据的边缘范围。所以查找的时候, 我们要尽量使Filter.db和Index.db帮我们作一个前置判断,帮我们做一些数据的过滤,使我们的查询更精准。越精准的话,我们查询的性能就越好,就不会发生一些线上的问题。

前面讲完了建表和查询的一些使用,现在讲一些运维的事情。运维可以分成几项。 首先考虑安全性。 安全永远是所有工作里第0项工作, 最重要的一项工作。 首先权限最小化。 只能有一个superuser, 一个用户对应一个库名,不能跨库访问。这样的话,防君子不防小人。我们根据用户的业务控制最小权限,生产环境禁止DROP权限。因为一旦执行了DROP,可能后面恢复,七七八八就会遇到一些很大的问题。这是一般其他所有的数据库都有的限制。
JMX 端口内网只开放于本机,有条件开启证书验证。JMX 除了可以读取一些监控指标,还可以对你的集群做一些操作,所以这个端口开放还是有一定危险的。
还有就是Opscenter。这是DataStax提供基于Web的监控运维操作的工具。我们曾经用过,但发生了一些不愉快的事情。Opscenter 权限非常大,可以删表删库清快照,若被入侵,后果不堪设想。如果非得使用Opscenter,必须禁止把它开放到公网,要定时监控Nginx日志,看看是否有入侵痕迹。
为什么要慎用?因为我们的一个线上集群曾经Opscenter被入侵过,后果就是我们这个集群上有一个库,所有的数据都被删掉了, 我们配置的用户名密码也被泄露了。只有运维人员才知道, 但我们不知道对方是如何黑进来的。 我们根据查询Nginx日志发现,从美国过来的IP对我们的密码进行了不断的探测, 然后做了一些端口穿透。所以用Opscenter还是挺危险的, 因为我们不知道它隐藏了什么样的漏洞。 所以建议不要用。

关于监控。没有Opscenter,我们就要靠自己的一些系统。 我们现在用的是小米开源的open-falcon,通过jmx采集集群的基本指标,通过IM/邮件/短信/电话通知责任人。我们采集的一些(服务器)指标是磁盘空间,网络,和CPU 。根据我们的经验,磁盘是60%预警,网络超过20MB预警,CPU超过80%预警。
磁盘为什么是60%预警? 因为sstable很大的时候, 它的压缩需要很大的空间。如果磁盘80%才报警,一个超大的sstable可能就没有办法进行压缩,它就会一直存在里面。所以磁盘60%要预警,然后及时扩容。
服务的可用性监控我们也要做,监控一下它的进程,监控这些默认端口9042,7000的服务可用性。
还有性能的监控。 我们要实时地监控每秒的读/写请求数,读/写延迟,比如P99,以便实时的知道线上集群的质量和访问情况。
表监控。比如表的墓碑情况,表的 sstable有多少,最大的sstable有多少,表的设计会不会有问题,运行久了之后会不会有热点和超大分区等问题。 右图是我们采用的Cassandra的一些监控指标。我们可以看到DownEndpointCount, UpEndpointCount, 这个指标可以知道我们集群里面挂了几台。
(另外,)这里(还)有Heap的一些信息。 这是监控具体的一张表,invalid access token。这是sstable有多少,空间用了多少,读请求使用了多少,读延迟,写延迟等等。所以说,这些监控指标我们都要把它们采集下来。
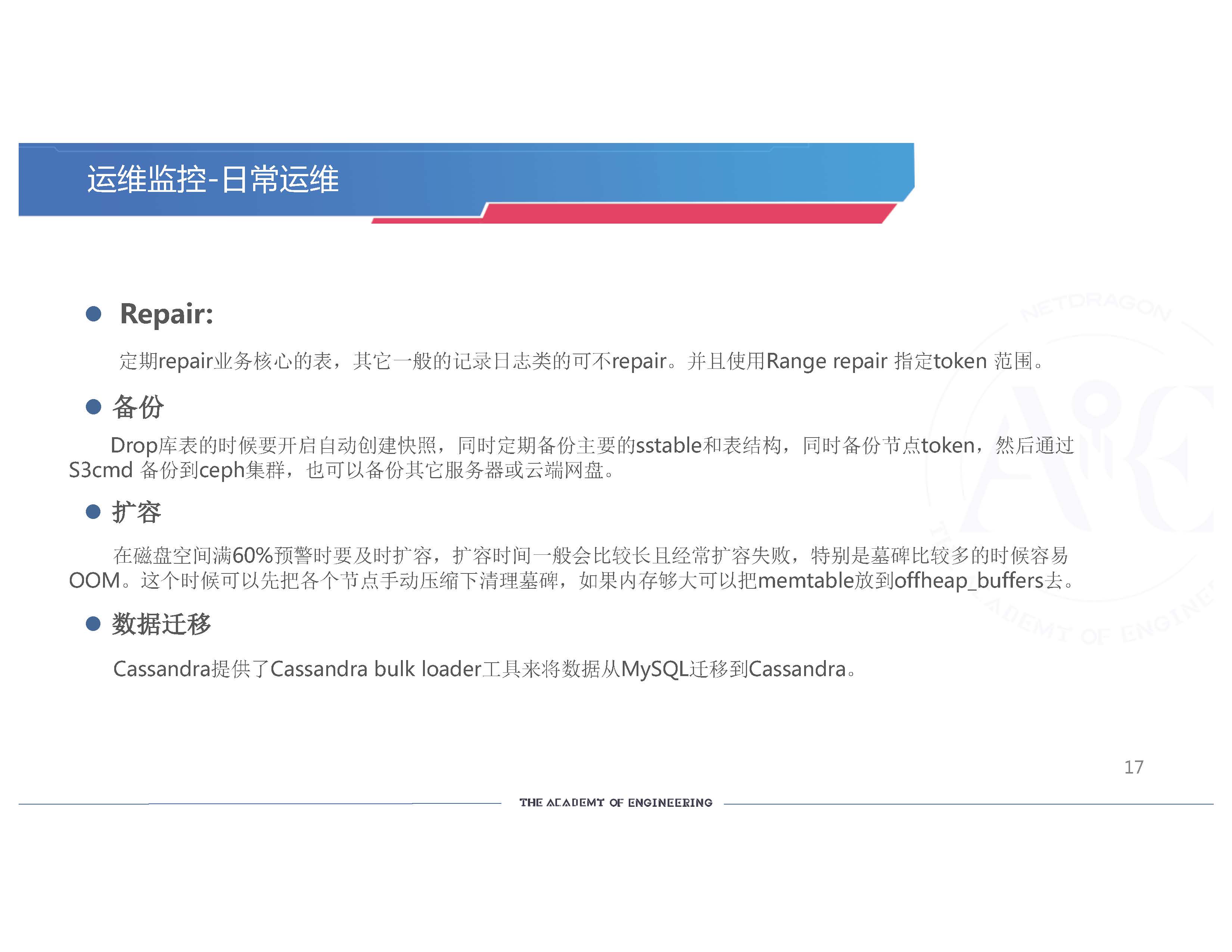
日常运维。我们要定期repair业务核心的表,其它一般日志类的表可以不repair。因为repair非常耗资源,而且时间可能会非常长,但是它又不得不做。所以我们就把业务比较重要的表做repair。Repair的时候我们要指定范围,使用Range repair 指定token范围。当它repair到你的范围失败的时候,你可以从那里重新开始,不用做一些重复的操作。而且 Range Repair的压力没那么大,可以适当控制,今天修几个,明天修几个,这样的话不用一次性指定几个节点修的话,极有可能导致线上的一些性能的问题。
备份。我们的sstable要进行备份。我们在删表的时候,要开启自动创建快照,同时定期备份主要的表,表的结构,还有节点token。我们是通过S3cmd备份到ceph集群。如果在其他的环境上,比如说在AWS或Azure的环境,我们就备份到AWS S3或云端网盘或其它服务器上。
扩容。在磁盘空间满60%预警时要及时扩容。扩容的时间一般会比较长, 而且经常扩容失败,这是在线上之前经常遇到的一个问题。我们大致分析了一下扩容失败的原因,就是墓碑比较多。墓碑比较多的时候, 我们扩容写数据的时候会把墓碑先加到memtable里去,然后再写入磁盘,这时memtable会非常大,很容易导致OOM。这个时候,根据我们的经验,如果我们的内存够大,就把memtable放到offheap_buffers去,就可以充分利用大内存的优势, 把这些东西加进去,防止内存溢出。
数据迁移。Cassandra提供了Cassandra bulk loader工具来将数据从MySQL迁移到Cassandra。如果你没用Cassandra的话,想用它,我可以推荐你使用一些工具来做迁移,把你的数据从异构数据库迁移过来。

最后我们来分享我们用Cassandra的时候遇到的坑。这些坑有大有小。有些是低级的错误。比如说,第一个,System_auth系统副本数没修改。系统用户表默认副本数为1,当挂一个节点时就会导致部分账号无法验证通过。这个我相信我们都遇到过。所以集群部署完了之后,我们第一件事要做的就是把这个副本改成3。
第二点就是插入一些空值。空值Cassandra会当成墓碑处理。在repair的时候也会读入大量墓碑。如果空值非常多非常大的话,可能会引发一些内存溢出的问题。所以写入一行的时候如果某个列为空值,必须给他指定一个默认的值,比如写入这样一个空字符串符号(‘ ’)进去,这样Cassandra不会当作空值处理,业务上可以让客户端去处理。
最令人头疼的就是墓碑问题。墓碑太多会造成各种问题,如慢查询、repair的时候OOM。所以要把墓碑控制在一个可控制的范围。墓碑会在压缩的时候被从磁盘上擦除,所以我们在建表的时候要把GC_GRACE_SECONDS 的时间设短一点。默认是10天。如果你经常 repair或者保证你的集群不会出什么问题的话,可以把时间再缩短一点。这样在压缩的时候它就会及时清理掉。还有一种策略就是配置时间窗压缩策略,把旧的墓碑及时清理。但是这个策略也有一定问题,也有一定局限性。
还有二级索引。我的建议是能不用就尽量不用,特别是有墓碑的表和数据量大的表。我们遇到的问题是,我们用户中心有一张 token表,记录每个用户的 token。 这个token我们建了一个二级索引。那张表数据量非常大,token的特性是7天会过期,有的是一个月过期。所以这张表的数据量又大,墓碑又多,扩容的时候这张表会不断地抛出,墓碑非常多,扩容失败。
还有就是我们有一些拨测账号,一分钟去请求一个token, 一分钟之内又删除这个token, 久而久之,几个月之后这个拨测账号就会生成几十万,上百万的token。 这个账号再拨的时候,一拨服务就挂了,一拨服务就挂了。所以二级索引,还有有墓碑的二级索引尽量不要使用。
高并发的时候慎用计数器couter功能。一个是它不是很精准,因为你可能会超时。超时的时候会重发,重发的时候它会额外多计一次。比如说这条数据是增加1的,因为超时会变成增加2。还有就是,计数器是ACID, 它的一致性很高,在高并发的情况下性能也不好。
阙乃祯:网龙在教育领域Cassandra的使用的更多相关文章
- Cassandra与职业发展 | 阿里云栾小凡 × 蔚来汽车张旭东 × 网龙阙乃祯
# 活动精彩实录 | Cassandra与职业发展 点击此处观看完整活动录像 大家好,我叫邓为,我目前在DataStax担任领航架构师.我在DataStax工作了7年多的时间,也有7年多的Cassa ...
- 网龙“MAD技术论坛”在榕举办 200余位技术人才共话“改变教育”
9月16日,由网龙网络公司主办.msup协办的“MAD技术论坛”在榕举办,来自美国.香港.苏州等地的技术大牛受邀来到福州,围绕“Make a difference to education”这一论坛主 ...
- VR虚拟现实技术在教育领域的前景展望
VR虚拟现实技术在教育领域的前景展望 VR虚拟现实技术能迅速火起来,是基于它突破了人们对三维空间在时间与地域上的感知限制,以及市场需求愿景的升级.此技术可广泛地应用到城市规划.室内设计.工业仿真.古迹 ...
- atitit.无为而治在企业管理,国家治理,教育领域的具体思想与实践
atitit.无为而治在企业管理,国家治理,教育领域的具体思想与实践 1. 什么是无为而治 1 2. 无为而治的三个原则 1 3. 抓大放小 1 4. 治理国家 2 5. 企业管理 2 6. 教育领域 ...
- 最新 网龙网络java校招面经 (含整理过的面试题大全)
从6月到10月,经过4个月努力和坚持,自己有幸拿到了网易雷火.京东.去哪儿.网龙网络等10家互联网公司的校招Offer,因为某些自身原因最终选择了网龙网络公司.6.7月主要是做系统复习.项目复盘.Le ...
- typeof应该注意的地方(网龙公司校招笔试题)
<script language="javascript" type="text/javascript"> alert(new String('a' ...
- 腾讯网2016回响中国:华清远见荣获2016年度知名IT培训品牌
12月1日,由腾讯网主办的“2016回响中国·腾讯网教育年度盛典”上,揭晓了“2016腾讯网教育年度总评榜”榜单.高端IT就业培训专家——华清远见教育集团凭借自身优质的高薪IT就业服务优势成功入围,荣 ...
- 龙芯将两款 CPU 核开源,这意味着什么?
10月21日,教育部计算机类教学指导委员会.中国计算机学会教育专委会将2016 CNCC期间在山西太原举办“面向计算机系统能力培养的龙芯CPU高校开源计划”活动,在活动中,龙芯中科宣布将GS132和G ...
- 教育类APP开发现新增长,多款APP该如何突围?
"十二五"以来,国家共出台相关的重大教育政策文件741个,而进入到"十三五"时期教育领域综合改革深入推进的关键期,不断促进教育现代化的实现.加快迈入人力资源强国 ...
随机推荐
- GEDIT外部工具
首先通过编辑-首选项-插件-外部命令来打开外部命令,然后在工具-Manage External Tools来添加新工具,工具代码使用bash语言. 代码使用方式:+添加新插件,在编辑框中粘贴代码,快捷 ...
- javascript原型:写一个合并后数组去掉同类项的方法
<!DOCTYPE html> <html> <head> <title>test013_Array_prototype_unique()</ti ...
- Makefile中的目标
Makefile中的目标 一般目标 目标就是我们需要的最终文件,也是make的最终输出 Makefile的运行机制是:先将目标当成文件,查看文件是否存在,如果存在且是最新,那么直接结束,如果文件不存在 ...
- 来了,来了,你们要的Nginx教程来了
一 Nginx简介 1.1 什么是Nginx Nginx是一个高性能的http和反向代理服务器,其特点是占用内存小,并发能力强.Nginx专为性能优化而开发,性能是其最重要的考量,能经受高负载的考验, ...
- java io流根据url读取图片
//获取图片大小 public void readFileSize(String url,HttpServletRequest request){ //根路径 File file = new File ...
- asp.net core 动态更新 appsetting.json方法
如何将值更新到appsetting.json? 我正在使用官方文档中IOptions描述的模式. 当我从中读取值时appsetting.json,这可以正常工作,但是如何更新值并将更改保存回来apps ...
- 看了这篇你就会手写RPC框架了
一.学习本文你能学到什么? RPC的概念及运作流程 RPC协议及RPC框架的概念 Netty的基本使用 Java序列化及反序列化技术 Zookeeper的基本使用(注册中心) 自定义注解实现特殊业务逻 ...
- PHP easter_date() 函数
------------恢复内容开始------------ 实例 输出不同年份的复活节日期: <?phpecho easter_date() . "<br />" ...
- Skill 如何翻转一个list
https://www.cnblogs.com/yeungchie/ code 发现已经有内置了reverse(l_list) unless(fboundp('reverse) procedure(y ...
- 2020牛客暑期多校训练营 第二场 B Boundary 计算几何 圆 已知三点求圆心
LINK:Boundary 计算几何确实是弱项 因为好多东西都不太会求 没有到很精通的地步. 做法很多,先说官方题解 其实就是枚举一个点 P 然后可以发现 再枚举一个点 然后再判断有多少个点在圆上显然 ...