用python爬虫监控CSDN博客阅读量
作为一个博客新人,对自己博客的访问量也是很在意的,刚好在学python爬虫,所以正好利用一下,写一个python程序来监控博客文章访问量
效果
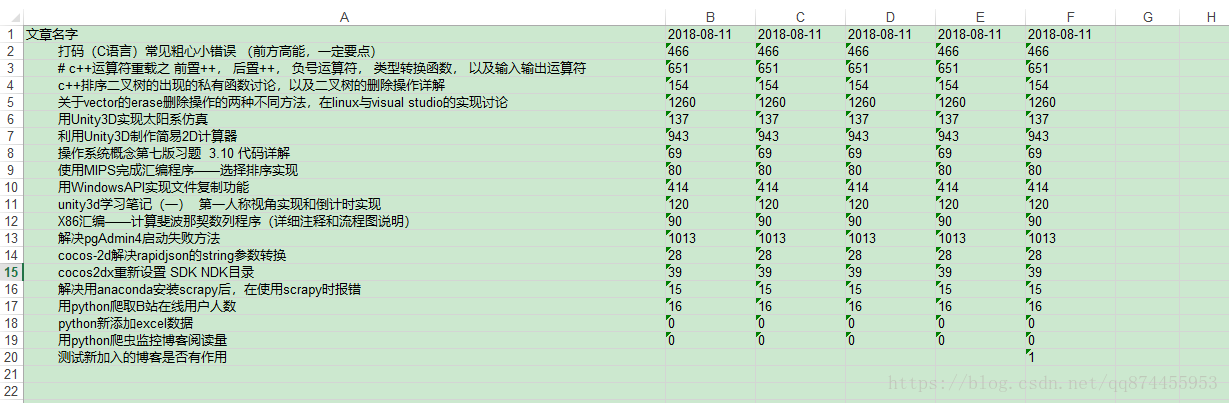
代码会自动爬取文章列表,并且获取标题和访问量,写入excel,并且对新加入的文章也有作用
解析HTML
html通过beautifulsoup来解析,由于是静态的网页,数据直接在网页中,而不是生成的,所以直接提取出来就可以
提取文章标题和访问量
通过观察HTML 我们发现每一个文章都存储在一个类名为‘article-item-box csdn-tracking-statistics’的div中, 所以找到类名为这个的div
发现文章标题藏在此div的h4下的a下,所以提取出来即可
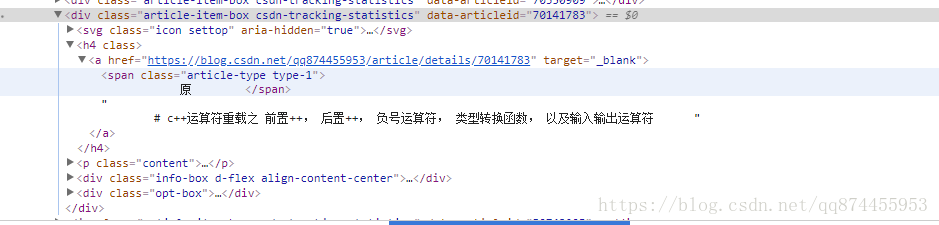
提取代码如下
articleList = soup.find_all('div', attrs={'class': 'article-item-box csdn-tracking-statistics'})
readBar = soup.find_all('div', attrs={'class': 'info-box d-flex align-content-center'})
articleListLen = len(articleList)
#把数据写入到表格里
for i in range(articleListLen):
articleName = articleList[i].h4.a.contents[2]
articleReadCount = readBar[i].contents[3].span.string.split(":")[1]
存储信息格式
存储信息通过一个表格来存储,结构如下
| 标题 | 日期1 | 日期2 | ··· |
|---|---|---|---|
| 文章1 | 访问量1 | 访问量2 | ··· |
| 文章2 | 访问量1 | 访问量2 | ··· |
| 文章3 | 访问量1 | 访问量2 | ··· |
| 文章4 | 访问量1 | 访问量2 | ··· |
| … | 访问量1 | 访问量2 | ··· |
每次调用程序就会生成一列数据
存储过程
利用xlwt, xlrd 进行表格的读写
#如果excel表格不存在,则创建
if not os.path.exists("ReadRecord.xls"):
workbook = xlwt.Workbook()
worksheet = workbook.add_sheet('My ReadRecord')
worksheet.write(0, 0, "1")
workbook.save("ReadRecord.xls")
# 打开excel, 为rexcel
rexcel = xlrd.open_workbook("ReadRecord.xls")
# 拷贝原来的rexcel, 变成excel
excel = copy(rexcel)
# 得到工作表
worksheet = excel.get_sheet(0)
# 得到列数
read_time = rexcel.sheets()[0].ncols
###写入操作
#保存表格
excel.save('ReadRecord.xls')需要注意的地方
- 表格新添加的列的列数是根据原来的表格列数来的
- 因为是进行更新,所以先要拷贝原来的表格,不然直接用write是进行覆盖
因为用户有可能会继续发布博客, 所以最新的博客信息,应该存在最后一行, url改为经过时间排序的html(比如https://blog.csdn.net/qq874455953?orderby=UpdateTime), 而且默认是按新旧排序,所以加入的时候,从最后一行来写入表格
代码源码
代码如下, 会生成一个excel表格,存储了所有文章的阅读量,
import requests
import datetime
import os
import xlwt
import xlrd
from xlutils.copy import copy
from bs4 import BeautifulSoup
#获取HTML
def get_page_source(url):
try:
r = requests.get(url, timeout=30)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
return "failed"
def main():
#url = input("请输入博客主页网址, 比如:https://blog.csdn.net/qq874455953\n")
url = "https://blog.csdn.net/qq874455953"
#改为你的博客主页地址
html = get_page_source(url + '?orderby=UpdateTime')
#解析HTML 使用BeautifulSoup
soup = BeautifulSoup(html, 'html.parser')
articleList = soup.find_all('div', attrs={'class': 'article-item-box csdn-tracking-statistics'})
readBar = soup.find_all('div', attrs={'class': 'info-box d-flex align-content-center'})
#如果excel表格不存在,则创建
if not os.path.exists("ReadRecord.xls"):
workbook = xlwt.Workbook()
worksheet = workbook.add_sheet('My ReadRecord')
worksheet.write(0, 0, "1")
workbook.save("ReadRecord.xls")
# 打开excel, 为rexcel
rexcel = xlrd.open_workbook("ReadRecord.xls")
# 拷贝原来的rexcel, 变成excel
excel = copy(rexcel)
# 得到工作表
worksheet = excel.get_sheet(0)
# 得到列数
read_time = rexcel.sheets()[0].ncols
#得到当前日期
nowTime = str(datetime.datetime.now().strftime('%Y-%m-%d'))
#写好第一列 说明
worksheet.write(0, 0, "文章名字")
worksheet.write(0, read_time, nowTime)
#获取文章列数
articleListLen = len(articleList)
#把数据写入到表格里
for i in range(articleListLen):
articleName = articleList[i].h4.a.contents[2]
articleReadCount = readBar[i].contents[3].span.string.split(":")[1]
worksheet.write(articleListLen - i, 0, articleName)
worksheet.write(articleListLen - i, read_time, articleReadCount)
#保存表格
excel.save('ReadRecord.xls')
if __name__=="__main__":
main()总结
最后你可以把这个代码挂到服务器上, 然后每天定时运行一次,就可以看到你的具体文章的访问量变化了!
不过需要修改的地方就是 我这个只能读一页的, 其实博客不止这么多,需要考虑不同页的问题
用python爬虫监控CSDN博客阅读量的更多相关文章
- Python爬取CSDN博客文章
0 url :http://blog.csdn.net/youyou1543724847/article/details/52818339Redis一点基础的东西目录 1.基础底层数据结构 2.win ...
- Python 爬取CSDN博客频道
初次接触python,写的很简单,开发工具PyCharm,python 3.4很方便 python 部分模块安装时需要其他的附属模块之类的,可以先 pip install wheel 然后可以直接下载 ...
- 通过爬虫代理IP快速增加博客阅读量——亲测CSDN有效!
写在前面 题目所说的并不是目的,主要是为了更详细的了解网站的反爬机制,如果真的想要提高博客的阅读量,优质的内容必不可少. 了解网站的反爬机制 一般网站从以下几个方面反爬虫: 1. 通过Headers反 ...
- (最新)使用爬虫刷CSDN博客访问量——亲测有效
说明:该篇博客是博主一字一码编写的,实属不易,请尊重原创,谢谢大家! 1.概述 前言:前两天刚写了第一篇博客https://blog.csdn.net/qq_41782425/article/deta ...
- 关于写作那些事之利用 js 统计各大博客阅读量
在日常文章数据统计的过程中,纯手动方式已经难以应付,于是乎,逐步开始了程序介入方式进行统计. 在上一节中,探索利用 csv 文件格式进行文章数据统计,本来以为能够应付一阵子,没想到仅仅一天我就放弃了. ...
- 利用Python抓取CSDN博客
这两天发现了一篇好文章,陈皓写的makefile的教程,具体地址在这里<跟我一起写makefile> 这篇文章一共分成了14个部分,我看东西又习惯在kindle上面看,感觉一篇一篇地复制成 ...
- Python爬虫小实践:爬取任意CSDN博客所有文章的文字内容(或可改写为保存其他的元素),间接增加博客访问量
Python并不是我的主业,当初学Python主要是为了学爬虫,以为自己觉得能够从网上爬东西是一件非常神奇又是一件非常有用的事情,因为我们可以获取一些方面的数据或者其他的东西,反正各有用处. 这两天闲 ...
- Python 实用爬虫-04-使用 BeautifulSoup 去水印下载 CSDN 博客图片
Python 实用爬虫-04-使用 BeautifulSoup 去水印下载 CSDN 博客图片 其实没太大用,就是方便一些,因为现在各个平台之间的图片都不能共享,比如说在 CSDN 不能用简书的图片, ...
- Python爬虫简单实现CSDN博客文章标题列表
Python爬虫简单实现CSDN博客文章标题列表 操作步骤: 分析接口,怎么获取数据? 模拟接口,尝试提取数据 封装接口函数,实现函数调用. 1.分析接口 打开Chrome浏览器,开启开发者工具(F1 ...
随机推荐
- 02 安装net-tools工具
01 登录虚拟机,没错,还是那个熟悉的黑窗口 02 输入用户名密码(我还是习惯使用root用户,因为,它可以为所欲为) 小知识:注意红色框内的符号: 一般用户为限制用户,符号为:$ 超级用户,为无限制 ...
- Ubuntu查看和设置Root账户
前言: 要在Linux中运行管理任务,必须要具有root(也称为超级用户)访问权限.在大多数Linux发行版中,拥有一个单独的root账户是很常见的,但是Ubuntu默认禁用root账户.这可以防止用 ...
- Teambition如何使用二次验证码/虚拟MFA/两步验证/谷歌验证器?
一般点账户名——设置——安全设置中开通虚拟MFA两步验证 具体步骤见链接 Teambition如何使用二次验证码/虚拟MFA/两步验证/谷歌验证器? 二次验证码小程序于谷歌身份验证器APP的优势 1 ...
- Terminal终端控制台常用操作命令
新建文件夹和文件 cd .. 返回上一级 md test 新建test文件夹 md d:\test\my d盘下新建文件夹 cd test 进入test文件夹 cd.>cc.txt 新建cc.t ...
- 小书MybatisPlus第8篇-逻辑删除实现及API细节精讲
本文为Mybatis Plus系列文章的第8篇,前7篇访问地址如下: 小书MybatisPlus第1篇-整合SpringBoot快速开始增删改查 小书MybatisPlus第2篇-条件构造器的应用及总 ...
- getprop与dumpsys命令
拿到Android手机以后, 想查看一些手机信息. 其实Android获取手机信息就是两个命令, 一个是getprop 一个是dumpsys. dumpsys iphonesubinfo Phone ...
- vj map
/* * 换行好烦人呀! */ #include <iostream> #include <map> #include <string> using namespa ...
- Java语言概述_章节练习题及面试
学于尚硅谷开源课程 宋洪康老师主讲 感恩 尚硅谷官网:http://www.atguigu.com 尚硅谷b站:https://space.bilibili.com/302417610?from=se ...
- matplotlib示例
plt.plot 内只有一个列表示例 import matplotlib.pyplot as plt lst = [4.53,1.94,4.75,0.43,2.02,1.22,2.13,2.77] p ...
- 再见了Antirez永远的Redis之神
其实antirez(Redis作者)退出Redis维护一发布我就在很多咨询网站上面看到了,当时也没太多感慨. 今天比较有空想去看看霉霉Twitter的,然后看到了antirez,我就又一次回顾了他的退 ...