Go Http包解析:为什么需要response.Body.Close()
简单来讲就是:为了提高效率,http.Get 等请求的 TCP 连接是不会关闭的(再次向同一个域名请求时,复用连接),所以必须要手动关闭。
2019-01-24 10:43:32 更新
不管是否使用 Resp 的内容都需要手动关闭,否则会导致进程打开的 fd 一直变多,最终系统杀掉进程,报错类似: http: Accept error: accept tcp [::]:4200: accept4: too many open files; retrying in 1s
参考: http://www.zhangjiee.com/blog/2018/go-http-get-close-body.html
最近线上的一个项目遇到了内存泄露的问题,查了heap之后,发现 http包的 dialConn函数竟然占了内存使用的大头,这个有点懵逼了,后面在网上查询资料的时候无意间发现一句话
10次内存泄露,有9次是goroutine泄露。
结果发现,正是我认为的不可能的goroutine泄露导致了这次的内存泄露,而goroutine泄露的原因就是 没有调用 response.Body.Close()
实验
既然发现是 response.Body.Close() 惹的祸,那就做个实验证实一下
不close response.Body
func main() {
for true {
requestWithNoClose()
time.Sleep(time.Microsecond * 100)
}
}
func requestWithNoClose() {
_, err := http.Get("https://www.baidu.com")
if err != nil {
fmt.Printf("error occurred while fetching page, error: %s", err.Error())
}
fmt.Println("ok")
}close response.Body
func main() {
for true {
requestWithClose()
time.Sleep(time.Microsecond * 10)
}
}
func requestWithClose() {
resp, err := http.Get("https://www.baidu.com")
if err != nil {
fmt.Printf("error occurred while fetching page, error: %s", err.Error())
return
}
defer resp.Body.Close()
fmt.Println("ok")
}结果
同样的代码,区别只有 是否resp.Body.Close() 是否被调用,我们运行一段时间后,发现内存差距如此之大

后面,我们就带着问题,深入一下Http包的底层实现来找出具体原因
结构体
只分析我们可能用会用到的
Transport
type Transport struct {
idleMu sync.Mutex
wantIdle bool // user has requested to close all idle conns
// 空闲的连接 缓存的地方
idleConn map[connectMethodKey][]*persistConn // most recently used at end
// connectMethodKey => 空闲连接的chan 形成的map
// 有空闲连接放入的时候,首先尝试放入这个chan,方便另一个可能需要连接的goroutine直接使用,如果没有goroutine需要连接,就放入到上面的idleConn里面,便于后面的请求连接复用
idleConnCh map[connectMethodKey]chan *persistConn
// DisableKeepAlives, if true, disables HTTP keep-alives and
// will only use the connection to the server for a single
// HTTP request.
//
// This is unrelated to the similarly named TCP keep-alives.
// 是否开启 keepAlive,为true的话,连接不会被复用
DisableKeepAlives bool
// MaxIdleConns controls the maximum number of idle (keep-alive)
// connections across all hosts. Zero means no limit.
// 所有hosts对应的最大的连接总数
MaxIdleConns int
// 每一个host对应的最大的空闲连接数
MaxIdleConnsPerHost int
// 每一个host对应的最大连接数
MaxConnsPerHost int
}pconnect
type persistConn struct {
// alt optionally specifies the TLS NextProto RoundTripper.
// This is used for HTTP/2 today and future protocols later.
// If it's non-nil, the rest of the fields are unused.
alt RoundTripper
t *Transport
cacheKey connectMethodKey
conn net.Conn
tlsState *tls.ConnectionState
br *bufio.Reader // from conn
bw *bufio.Writer // to conn
nwrite int64 // bytes written
// roundTrip 往 这个chan 里写入request,readLoop从这个 chan 读取request
reqch chan requestAndChan // written by roundTrip; read by readLoop
// roundTrip 往 这个chan 里写入request 和 writeErrCh,writeLoop从这个 chan 读取request写入大盘 连接 里,并写入 err 到 writeErrCh chan
writech chan writeRequest // written by roundTrip; read by writeLoop
closech chan struct{} // closed when conn closed
// 判断body是否读取完
sawEOF bool // whether we've seen EOF from conn; owned by readLoop
// writeErrCh passes the request write error (usually nil)
// from the writeLoop goroutine to the readLoop which passes
// it off to the res.Body reader, which then uses it to decide
// whether or not a connection can be reused. Issue 7569.
// writeLoop 写入 err的 chan
writeErrCh chan error
// writeLoop 结束的时候关闭
writeLoopDone chan struct{} // closed when write loop ends
}writeRequest
type writeRequest struct {
req *transportRequest
ch chan<- error
// Optional blocking chan for Expect: 100-continue (for receive).
// If not nil, writeLoop blocks sending request body until
// it receives from this chan.
continueCh <-chan struct{}
}requestAndChan
type requestAndChan struct {
req *Request
ch chan responseAndError // unbuffered; always send in select on callerGone
// whether the Transport (as opposed to the user client code)
// added the Accept-Encoding gzip header. If the Transport
// set it, only then do we transparently decode the gzip.
addedGzip bool
// Optional blocking chan for Expect: 100-continue (for send).
// If the request has an "Expect: 100-continue" header and
// the server responds 100 Continue, readLoop send a value
// to writeLoop via this chan.
continueCh chan<- struct{}
callerGone <-chan struct{} // closed when roundTrip caller has returned
}请求流程
这里的函数没有太多的逻辑,贴出来主要是为了追踪过程
这里用一个简单的例子表示
func main() {
// 调用 Http 包的 Get 函数处理
resp, err := http.Get("https://www.baidu.com")
if err != nil {
panic(err)
}
resp.Body.Close()
}client.Get
var DefaultClient = &Client{}
....
// 使用默认的 client, 调用 client.Get 来处理
func Get(url string) (resp *Response, err error) {
return DefaultClient.Get(url)
}func (c *Client) Get(url string) (resp *Response, err error) {
// request这里的创建忽略
req, err := NewRequest("GET", url, nil)
if err != nil {
return nil, err
}
// 调用 client.Do 函数来处理, 然后 client.Do 调用 client.do 来处理,不懂为啥非要多一层嵌套
return c.Do(req)
}client.do
func (c *Client) do(req *Request) (retres *Response, reterr error) {
// URL 及 hook检测,忽略...
var (
deadline = c.deadline()
reqs []*Request
resp *Response
copyHeaders = c.makeHeadersCopier(req)
reqBodyClosed = false // have we closed the current req.Body?
// Redirect behavior:
redirectMethod string
includeBody bool
)
// 错误自定义处理,忽略....
for {
// 省略无关的代码....
reqs = append(reqs, req)
var err error
var didTimeout func() bool
// 调用 client.send 方法来获取response,主要逻辑
if resp, didTimeout, err = c.send(req, deadline); err != nil {
// c.send() always closes req.Body
reqBodyClosed = true
if !deadline.IsZero() && didTimeout() {
err = &httpError{
// TODO: early in cycle: s/Client.Timeout exceeded/timeout or context cancelation/
err: err.Error() + " (Client.Timeout exceeded while awaiting headers)",
timeout: true,
}
}
return nil, uerr(err)
}
// 判断是否需要跳转,进而进一步请求
var shouldRedirect bool
redirectMethod, shouldRedirect, includeBody = redirectBehavior(req.Method, resp, reqs[0])
if !shouldRedirect {
return resp, nil
}
req.closeBody()
}
client.send
func (c *Client) send(req *Request, deadline time.Time) (resp *Response, didTimeout func() bool, err error) {
if c.Jar != nil {
for _, cookie := range c.Jar.Cookies(req.URL) {
req.AddCookie(cookie)
}
}
// 调用 send 方法来获取 response
resp, didTimeout, err = send(req, c.transport(), deadline)
if err != nil {
return nil, didTimeout, err
}
if c.Jar != nil {
if rc := resp.Cookies(); len(rc) > 0 {
c.Jar.SetCookies(req.URL, rc)
}
}
return resp, nil, nil
}send
func send(ireq *Request, rt RoundTripper, deadline time.Time) (resp *Response, didTimeout func() bool, err error) {
req := ireq // req is either the original request, or a modified fork
// URL Hader 等判断及请求fork,忽略....
stopTimer, didTimeout := setRequestCancel(req, rt, deadline)
// 调用 Transport.RoundTrip 来处理请求
resp, err = rt.RoundTrip(req)
if err != nil {
stopTimer()
if resp != nil {
log.Printf("RoundTripper returned a response & error; ignoring response")
}
if tlsErr, ok := err.(tls.RecordHeaderError); ok {
// If we get a bad TLS record header, check to see if the
// response looks like HTTP and give a more helpful error.
// See golang.org/issue/11111.
if string(tlsErr.RecordHeader[:]) == "HTTP/" {
err = errors.New("http: server gave HTTP response to HTTPS client")
}
}
return nil, didTimeout, err
}
if !deadline.IsZero() {
resp.Body = &cancelTimerBody{
stop: stopTimer,
rc: resp.Body,
reqDidTimeout: didTimeout,
}
}
return resp, nil, nil
}Transport.roundTrip
这里开始接近重点区域了
这个函数主要就是湖区连接,然后获取response返回
func (t *Transport) roundTrip(req *Request) (*Response, error) {
t.nextProtoOnce.Do(t.onceSetNextProtoDefaults)
ctx := req.Context()
trace := httptrace.ContextClientTrace(ctx)
// URL, header schema 等判断,与主流程无关,忽略...
for {
// 判断context 是否完成,超时等
select {
case <-ctx.Done():
req.closeBody()
return nil, ctx.Err()
default:
}
// treq gets modified by roundTrip, so we need to recreate for each retry.
// treq会被 roundTrip 方法修改,所有每一次循环需要创建一个新的
treq := &transportRequest{Request: req, trace: trace}
// 根据当前的请求获取 connectMethod,包含schema和address,方便请求的复用,这里不重要,不做详细分析
cm, err := t.connectMethodForRequest(treq)
if err != nil {
req.closeBody()
return nil, err
}
// Get the cached or newly-created connection to either the
// host (for http or https), the http proxy, or the http proxy
// pre-CONNECTed to https server. In any case, we'll be ready
// to send it requests.
// 根据请求和connectMethod获取一个可用的连接,重要,后面会具体分析
pconn, err := t.getConn(treq, cm)
if err != nil {
t.setReqCanceler(req, nil)
req.closeBody()
return nil, err
}
var resp *Response
if pconn.alt != nil {
// HTTP/2 path.
// http2 使用,这里不展开
t.decHostConnCount(cm.key()) // don't count cached http2 conns toward conns per host
t.setReqCanceler(req, nil) // not cancelable with CancelRequest
resp, err = pconn.alt.RoundTrip(req)
} else {
// 获取response,这里是重点,后面展开
resp, err = pconn.roundTrip(treq)
}
// 判断获取response是否有误及错误处理等操作,无关紧要,忽略
}
}接下来,进入重点分析了 getConn persistConn.roundTrip Transport.dialConn 以及内存泄露的罪魁祸首 persistConn.readLoop persistConn.writeLoop
Transport.getConn
这个方法根据connectMethod,也就是 schema和addr(忽略proxy代理),复用连接或者创建一个新的连接,同时开启了两个goroutine,分别 读取response 和 写request
func (t *Transport) getConn(treq *transportRequest, cm connectMethod) (*persistConn, error) {
// trace相关的忽略...
req := treq.Request
trace := treq.trace
ctx := req.Context()
if trace != nil && trace.GetConn != nil {
trace.GetConn(cm.addr())
}
// 从idleConn里面获取一个 connectMethod对应的空闲的 连接,获取到了直接返回
if pc, idleSince := t.getIdleConn(cm); pc != nil {
if trace != nil && trace.GotConn != nil {
trace.GotConn(pc.gotIdleConnTrace(idleSince))
}
// set request canceler to some non-nil function so we
// can detect whether it was cleared between now and when
// we enter roundTrip
t.setReqCanceler(req, func(error) {})
return pc, nil
}
type dialRes struct {
pc *persistConn
err error
}
// 没有获取到空闲连接,定义一个 dialRes 结构体,用于接收 自身创建的另一个goroutine创建的 连接
dialc := make(chan dialRes)
cmKey := cm.key()
// Copy these hooks so we don't race on the postPendingDial in
// the goroutine we launch. Issue 11136.
testHookPrePendingDial := testHookPrePendingDial
testHookPostPendingDial := testHookPostPendingDial
// 处理 dialc 中暂时用不到的连接的方法,后面会讲到为什么有可能创建的连接是没有人使用的
handlePendingDial := func() {
testHookPrePendingDial()
go func() {
if v := <-dialc; v.err == nil {
t.putOrCloseIdleConn(v.pc)
} else {
t.decHostConnCount(cmKey)
}
testHookPostPendingDial()
}()
}
cancelc := make(chan error, 1)
t.setReqCanceler(req, func(err error) { cancelc <- err })
// 忽略部分判断...
// 开启一个goroutine,去创建一个连接,dialConn 是重点,后面深入分析
go func() {
pc, err := t.dialConn(ctx, cm)
dialc <- dialRes{pc, err}
}()
// 获取 idleChan中对应connectMethod的 channel
idleConnCh := t.getIdleConnCh(cm)
// 从多个chan中获取连接,获取取消信号,先来的先处理
select {
case v := <-dialc:
// 上面 goroutine首先创建完成了一个连接,使用这个链接
// Our dial finished.
if v.pc != nil {
if trace != nil && trace.GotConn != nil && v.pc.alt == nil {
trace.GotConn(httptrace.GotConnInfo{Conn: v.pc.conn})
}
return v.pc, nil
}
// Our dial failed. See why to return a nicer error
// value.
t.decHostConnCount(cmKey)
select {
case <-req.Cancel:
// It was an error due to cancelation, so prioritize that
// error value. (Issue 16049)
return nil, errRequestCanceledConn
case <-req.Context().Done():
return nil, req.Context().Err()
case err := <-cancelc:
if err == errRequestCanceled {
err = errRequestCanceledConn
}
return nil, err
default:
// It wasn't an error due to cancelation, so
// return the original error message:
return nil, v.err
}
case pc := <-idleConnCh:
// 另一个goroutine的request首先完成了,然后会把这个链接首先尝试放入对应connectMethod对应的 chan,如果放入不了,则放入idleConns的map中,进入这里说明,另一个goroutine把连接放入了chan,并被当前goroutine捕获了,那么上面
// go func() {
// pc, err := t.dialConn(ctx, cm)
// dialc <- dialRes{pc, err}
// }()
// 生成的连接就暂时没用了,这时候就用到上面 handlePendingDial 定义的方法,去处理这个多余的连接
// Another request finished first and its net.Conn
// became available before our dial. Or somebody
// else's dial that they didn't use.
// But our dial is still going, so give it away
// when it finishes:
handlePendingDial()
if trace != nil && trace.GotConn != nil {
trace.GotConn(httptrace.GotConnInfo{Conn: pc.conn, Reused: pc.isReused()})
}
return pc, nil
case <-req.Cancel:
handlePendingDial()
return nil, errRequestCanceledConn
case <-req.Context().Done():
handlePendingDial()
return nil, req.Context().Err()
case err := <-cancelc:
handlePendingDial()
if err == errRequestCanceled {
err = errRequestCanceledConn
}
return nil, err
}
}上面的 handlePendingDial 方法中,调用了 putOrCloseIdleConn,这个方法到底干了什么,跟 idleConnCh 和 idleConn 有什么关系?
Transport.putOrCloseIdleConn
func (t *Transport) putOrCloseIdleConn(pconn *persistConn) {
if err := t.tryPutIdleConn(pconn); err != nil {
pconn.close(err)
}
}Transport.tryPutIdleConn
func (t *Transport) tryPutIdleConn(pconn *persistConn) error {
if t.DisableKeepAlives || t.MaxIdleConnsPerHost < 0 {
return errKeepAlivesDisabled
}
if pconn.isBroken() {
return errConnBroken
}
// http2判断
if pconn.alt != nil {
return errNotCachingH2Conn
}
// 标记为 reused
pconn.markReused()
// cacheKey是由 connectMethod得到的
key := pconn.cacheKey
t.idleMu.Lock()
defer t.idleMu.Unlock()
// 获取connectMethod对应的 idleConnCh
waitingDialer := t.idleConnCh[key]
select {
case waitingDialer <- pconn:
// 在这里尝试将 连接 放到 connectMethod对应的chan里面,如果没有另一个goroutine接收就算了
// We're done with this pconn and somebody else is
// currently waiting for a conn of this type (they're
// actively dialing, but this conn is ready
// first). Chrome calls this socket late binding. See
// https://insouciant.org/tech/connection-management-in-chromium/
return nil
default:
// 没有另一个goroutine接收的chan,从map中删除,便于垃圾回收
if waitingDialer != nil {
// They had populated this, but their dial won
// first, so we can clean up this map entry.
delete(t.idleConnCh, key)
}
}
if t.wantIdle {
return errWantIdle
}
if t.idleConn == nil {
t.idleConn = make(map[connectMethodKey][]*persistConn)
}
idles := t.idleConn[key]
// 设定了每个 connectMethod对应的最大空闲连接数,超过就不再往里面填充
if len(idles) >= t.maxIdleConnsPerHost() {
return errTooManyIdleHost
}
for _, exist := range idles {
if exist == pconn {
log.Fatalf("dup idle pconn %p in freelist", pconn)
}
}
// 后面就是清理多有的连接,及重置timer等操作,与主流程无关,不展开分析
t.idleConn[key] = append(idles, pconn)
t.idleLRU.add(pconn)
if t.MaxIdleConns != 0 && t.idleLRU.len() > t.MaxIdleConns {
oldest := t.idleLRU.removeOldest()
oldest.close(errTooManyIdle)
t.removeIdleConnLocked(oldest)
}
if t.IdleConnTimeout > 0 {
if pconn.idleTimer != nil {
pconn.idleTimer.Reset(t.IdleConnTimeout)
} else {
pconn.idleTimer = time.AfterFunc(t.IdleConnTimeout, pconn.closeConnIfStillIdle)
}
}
pconn.idleAt = time.Now()
return nil
}Transport.dialConn
跑偏了一会,现在接着 getConn分析 dialConn 这个函数
这个函数主要就是创建了一个 连接,然后 创建了两个goroutine,分别去往这个连接写入请求(writeLoop函数)和读取响应(readLoop函数)
而这两个函数,又会与 persistConn.roundTrip 通过chan进行关联,这里先对函数进行分析,分析完成后,再画出对应的关联图示
func (t *Transport) dialConn(ctx context.Context, cm connectMethod) (*persistConn, error) {
pconn := &persistConn{
t: t,
cacheKey: cm.key(),
reqch: make(chan requestAndChan, 1),
writech: make(chan writeRequest, 1),
closech: make(chan struct{}),
writeErrCh: make(chan error, 1),
writeLoopDone: make(chan struct{}),
}
trace := httptrace.ContextClientTrace(ctx)
wrapErr := func(err error) error {
if cm.proxyURL != nil {
// Return a typed error, per Issue 16997
return &net.OpError{Op: "proxyconnect", Net: "tcp", Err: err}
}
return err
}
// 构建一个 TLS的连接
if cm.scheme() == "https" && t.DialTLS != nil {
var err error
pconn.conn, err = t.DialTLS("tcp", cm.addr())
if err != nil {
return nil, wrapErr(err)
}
if pconn.conn == nil {
return nil, wrapErr(errors.New("net/http: Transport.DialTLS returned (nil, nil)"))
}
if tc, ok := pconn.conn.(*tls.Conn); ok {
// Handshake here, in case DialTLS didn't. TLSNextProto below
// depends on it for knowing the connection state.
if trace != nil && trace.TLSHandshakeStart != nil {
trace.TLSHandshakeStart()
}
if err := tc.Handshake(); err != nil {
go pconn.conn.Close()
if trace != nil && trace.TLSHandshakeDone != nil {
trace.TLSHandshakeDone(tls.ConnectionState{}, err)
}
return nil, err
}
cs := tc.ConnectionState()
if trace != nil && trace.TLSHandshakeDone != nil {
trace.TLSHandshakeDone(cs, nil)
}
pconn.tlsState = &cs
}
} else {
// 构建一个普通的tcp连接
conn, err := t.dial(ctx, "tcp", cm.addr())
if err != nil {
return nil, wrapErr(err)
}
pconn.conn = conn
if cm.scheme() == "https" {
var firstTLSHost string
if firstTLSHost, _, err = net.SplitHostPort(cm.addr()); err != nil {
return nil, wrapErr(err)
}
if err = pconn.addTLS(firstTLSHost, trace); err != nil {
return nil, wrapErr(err)
}
}
}
// proxy 设置、 协议转换等,忽略...
if t.MaxConnsPerHost > 0 {
pconn.conn = &connCloseListener{Conn: pconn.conn, t: t, cmKey: pconn.cacheKey}
}
pconn.br = bufio.NewReader(pconn)
pconn.bw = bufio.NewWriter(persistConnWriter{pconn})
go pconn.readLoop()
go pconn.writeLoop()
return pconn, nil
}persistConn.readLoop
readLoop 这里从连接中读取 response,然后通过chan发送给persistConn.roundTrip,最后等待结束
func (pc *persistConn) readLoop() {
closeErr := errReadLoopExiting // default value, if not changed below
defer func() {
// 关闭这个链接,这里的关闭函数 相当于 close(pc.closech),然后 writeLoop 的 <-pc.closech 就不会阻塞,而正常退出了,这样就可以理解,为什么readLoop函数退出后,writeLoop函数也就退出了
pc.close(closeErr)
pc.t.removeIdleConn(pc)
}()
// 这个函数同上面分析的 Transport.tryPutIdleConn
tryPutIdleConn := func(trace *httptrace.ClientTrace) bool {
if err := pc.t.tryPutIdleConn(pc); err != nil {
closeErr = err
if trace != nil && trace.PutIdleConn != nil && err != errKeepAlivesDisabled {
trace.PutIdleConn(err)
}
return false
}
if trace != nil && trace.PutIdleConn != nil {
trace.PutIdleConn(nil)
}
return true
}
// eofc is used to block caller goroutines reading from Response.Body
// at EOF until this goroutines has (potentially) added the connection
// back to the idle pool.
eofc := make(chan struct{})
defer close(eofc) // unblock reader on errors
// 省略部分...
alive := true
for alive {
pc.readLimit = pc.maxHeaderResponseSize()
_, err := pc.br.Peek(1)
pc.mu.Lock()
if pc.numExpectedResponses == 0 {
pc.readLoopPeekFailLocked(err)
pc.mu.Unlock()
return
}
pc.mu.Unlock()
// 从当前连接中获取request, 这里标记为 m1
rc := <-pc.reqch
trace := httptrace.ContextClientTrace(rc.req.Context())
var resp *Response
if err == nil {
// 从请求中获取response,就是那么简单
resp, err = pc.readResponse(rc, trace)
} else {
err = transportReadFromServerError{err}
closeErr = err
}
// 如果读取response失败,则包装错误返回给 上层,即 persistConn.roundTrip 函数
if err != nil {
if pc.readLimit <= 0 {
err = fmt.Errorf("net/http: server response headers exceeded %d bytes; aborted", pc.maxHeaderResponseSize())
}
select {
case rc.ch <- responseAndError{err: err}:
case <-rc.callerGone:
return
}
return
}
pc.readLimit = maxInt64 // effictively no limit for response bodies
pc.mu.Lock()
pc.numExpectedResponses--
pc.mu.Unlock()
hasBody := rc.req.Method != "HEAD" && resp.ContentLength != 0
if resp.Close || rc.req.Close || resp.StatusCode <= 199 {
// Don't do keep-alive on error if either party requested a close
// or we get an unexpected informational (1xx) response.
// StatusCode 100 is already handled above.
alive = false
}
// body为空的处理,忽略....
waitForBodyRead := make(chan bool, 2)
body := &bodyEOFSignal{
body: resp.Body,
// resp.Body.Close() 的最终调用的函数, Close()影响readLoop 和 writeLoop 两个goroutine 这两个goroutine的关闭,在后面讲close的时候具体介绍
earlyCloseFn: func() error {
waitForBodyRead <- false
<-eofc // will be closed by deferred call at the end of the function
return nil
},
// 上面函数出错后,会调用这个函数,这个函数影响readLoop 和 writeLoop 两个goroutine的形式,与上面的逻辑大致相同
fn: func(err error) error {
isEOF := err == io.EOF
waitForBodyRead <- isEOF
if isEOF {
<-eofc // see comment above eofc declaration
} else if err != nil {
if cerr := pc.canceled(); cerr != nil {
return cerr
}
}
return err
},
}
// 组装resp
resp.Body = body
if rc.addedGzip && strings.EqualFold(resp.Header.Get("Content-Encoding"), "gzip") {
resp.Body = &gzipReader{body: body}
resp.Header.Del("Content-Encoding")
resp.Header.Del("Content-Length")
resp.ContentLength = -1
resp.Uncompressed = true
}
// 将resp通过chan返回给 persistConn.roundTrip 函数
select {
case rc.ch <- responseAndError{res: resp}:
case <-rc.callerGone:
return
}
// Before looping back to the top of this function and peeking on
// the bufio.Reader, wait for the caller goroutine to finish
// reading the response body. (or for cancelation or death)
// 阻塞在这里,等待 请求 body close 或 请求cancel 或 context done 或 pc.closech
select {
case bodyEOF := <-waitForBodyRead:
pc.t.setReqCanceler(rc.req, nil) // before pc might return to idle pool
alive = alive &&
bodyEOF &&
!pc.sawEOF &&
pc.wroteRequest() &&
tryPutIdleConn(trace)
if bodyEOF {
eofc <- struct{}{}
}
case <-rc.req.Cancel:
alive = false
pc.t.CancelRequest(rc.req)
case <-rc.req.Context().Done():
alive = false
pc.t.cancelRequest(rc.req, rc.req.Context().Err())
case <-pc.closech:
alive = false
}
testHookReadLoopBeforeNextRead()
}
}persistConn.writeLoop
相对于persistConn.readLoop, 这个函数就简单很多,其主要功能也就是往连接里面写request请求
func (pc *persistConn) writeLoop() {
defer close(pc.writeLoopDone)
for {
select {
// 首先通过pc.writech chan 从 persistConn.roundTrip 函数中获取 writeRequest, 可以简单理解为 request
case wr := <-pc.writech:
startBytesWritten := pc.nwrite
err := wr.req.Request.write(pc.bw, pc.isProxy, wr.req.extra, pc.waitForContinue(wr.continueCh))
if bre, ok := err.(requestBodyReadError); ok {
err = bre.error
// Errors reading from the user's
// Request.Body are high priority.
// Set it here before sending on the
// channels below or calling
// pc.close() which tears town
// connections and causes other
// errors.
wr.req.setError(err)
}
if err == nil {
err = pc.bw.Flush()
}
if err != nil {
wr.req.Request.closeBody()
if pc.nwrite == startBytesWritten {
err = nothingWrittenError{err}
}
}
// 把 err 通过 chan 返回给 persistConn.roundTrip 函数,persistConn.roundTrip 函数判断 err是否为 nil及相应的处理
pc.writeErrCh <- err // to the body reader, which might recycle us
wr.ch <- err // to the roundTrip function
if err != nil {
// 如果 写入请求出现错误,这里关闭,pc.closech chan,readLoop的第151行就会停止阻塞,将alive设为false,进而结束循环,终止 readLoop的goroutine
pc.close(err)
return
}
case <-pc.closech:
// 这里结束阻塞,是由 readLoop 结束是,调用 第3行的 defer函数,关闭 pc.closech chan 导致的
return
}
}
}persistConn.roundTrip
无论是 persistConn.readLoop 还是 persistConn.writeLoop 都避免不了和这个函数交互,这个函数的重要性也就不言而喻了
但是 这个函数的主要逻辑就是 创建个连接的 writeRequest chan, 也就是 writeLoop 用到的chan,然后把request 通过这个 chan 传给 persistConn.writeLoop ,然后 在创建一个 responseAndError chan,也就是 readLoop 用到的chan,从 这个chan中获取 persistConn.readLoop 获取到的 response,最后把 response返回给上层函数
func (pc *persistConn) roundTrip(req *transportRequest) (resp *Response, err error) {
// 设置 request的头信息,cancel函数,省略....
var continueCh chan struct{}
if req.ProtoAtLeast(1, 1) && req.Body != nil && req.expectsContinue() {
continueCh = make(chan struct{}, 1)
}
gone := make(chan struct{})
defer close(gone)
defer func() {
if err != nil {
pc.t.setReqCanceler(req.Request, nil)
}
}()
const debugRoundTrip = false
// Write the request concurrently with waiting for a response,
// in case the server decides to reply before reading our full
// request body.
startBytesWritten := pc.nwrite
writeErrCh := make(chan error, 1)
// 把 request 放入 writech chan 里面,这样, `persistConn.writeLoop` 的第6行就可以拿到 request,往 连接 里面写入请求信息了
pc.writech <- writeRequest{req, writeErrCh, continueCh}
// 定义responseAndError chan,并放入 reqch chan 里面,这样 `persistConn.readLoop` 的第46行,也就是 m1标记的地方,就可以解除阻塞,开始获取 response的逻辑了
resc := make(chan responseAndError)
pc.reqch <- requestAndChan{
req: req.Request,
ch: resc,
addedGzip: requestedGzip,
continueCh: continueCh,
callerGone: gone,
}
var respHeaderTimer <-chan time.Time
cancelChan := req.Request.Cancel
ctxDoneChan := req.Context().Done()
// 阻塞在这里,直到 获取 writeLoop 返回的写入错误或 pc.closech的关闭信息,连接超时的信息或 readLoop的 resp或cancel或ctx done的信息
for {
testHookWaitResLoop()
select {
// 这里获取到 writeLoop的写入信息,可能是err,也可能不是,下面做对应的处理
case err := <-writeErrCh:
if debugRoundTrip {
req.logf("writeErrCh resv: %T/%#v", err, err)
}
if err != nil {
pc.close(fmt.Errorf("write error: %v", err))
return nil, pc.mapRoundTripError(req, startBytesWritten, err)
}
// 写入request没有问题,判断是否有超时
if d := pc.t.ResponseHeaderTimeout; d > 0 {
if debugRoundTrip {
req.logf("starting timer for %v", d)
}
timer := time.NewTimer(d)
defer timer.Stop() // prevent leaks
respHeaderTimer = timer.C
}
// 到此获取到了 writeLoop的信息,但是并没有return,进入下一个循环
case <-pc.closech:
// closech的关闭信息
if debugRoundTrip {
req.logf("closech recv: %T %#v", pc.closed, pc.closed)
}
return nil, pc.mapRoundTripError(req, startBytesWritten, pc.closed)
case <-respHeaderTimer:
// 等待超时的信息
if debugRoundTrip {
req.logf("timeout waiting for response headers.")
}
pc.close(errTimeout)
return nil, errTimeout
case re := <-resc:
// 从 readLoop获取到 response
if (re.res == nil) == (re.err == nil) {
panic(fmt.Sprintf("internal error: exactly one of res or err should be set; nil=%v", re.res == nil))
}
if debugRoundTrip {
req.logf("resc recv: %p, %T/%#v", re.res, re.err, re.err)
}
if re.err != nil {
return nil, pc.mapRoundTripError(req, startBytesWritten, re.err)
}
// 返回 response,这里结束循环
return re.res, nil
case <-cancelChan:
pc.t.CancelRequest(req.Request)
cancelChan = nil
case <-ctxDoneChan:
pc.t.cancelRequest(req.Request, req.Context().Err())
cancelChan = nil
ctxDoneChan = nil
}
}
}交互图示
上面 persistConn.roundTrip persistConn.readLoop persistConn.writeLoop 之间的数据交互,可能靠语言比较苍白,这里画一下图示
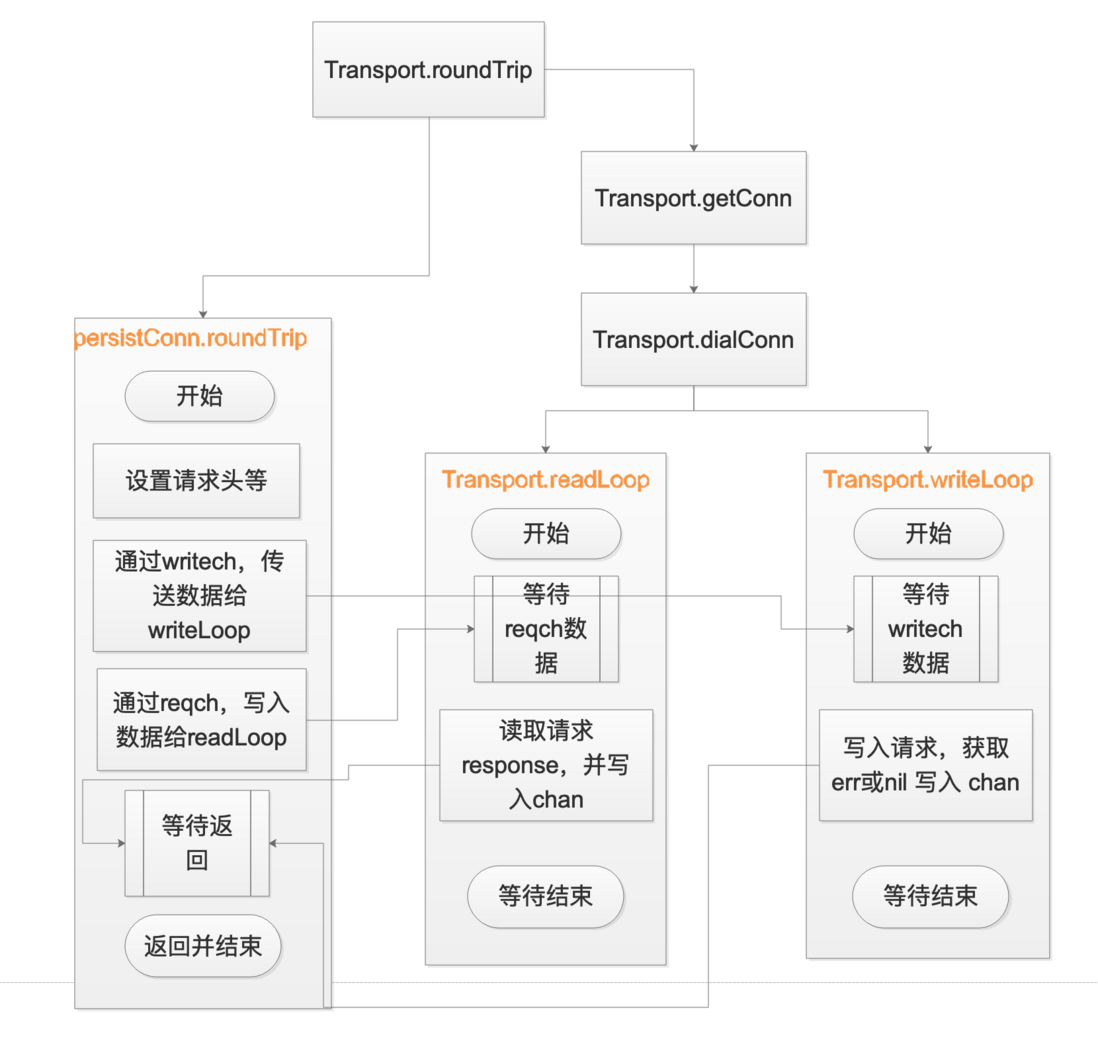
小结
综上分析,可以发现,readLoop和 writeLoop 两个goroutine在 写入请求并获取response返回后,并没有跳出for循环,而继续阻塞在 下一次for循环的select 语句里面,所以,两个函数所在的goroutine并没有运行结束,导致了最开的现象: goroutine持续增加导致内存持续增加
转自: https://segmentfault.com/a/1190000020086816
Go Http包解析:为什么需要response.Body.Close()的更多相关文章
- Wireshark-过滤器-数据包解析
目录 过滤器 数据包解析 参考 推荐阅读: https://www.cnblogs.com/zwtblog/tag/计算机网络/ 过滤器 显示过滤器 和 捕获过滤器,俩者使用非常类似. 在Wiresh ...
- java jar包解析:打包文件,引入文件
java jar包解析:打包文件,引入文件 cmd下: jar命令:package包打包 javac命令:普通类文件打包 Hello.java: package org.lxh.demo; publi ...
- Android做法说明(3)---Fragment使用app袋或v4包解析
Android做法说明(3)---Fragment使用app袋或v4包解析 1)问题简述 相信非常多的朋友在调用Fragment都会遇到以下的情况: watermark/2/text/aHR0cDov ...
- Spring (3.2.4) 常用jar 包解析
Spring (3.2.4) 常用jar 包解析 基本jar包 spring-aop-3.2.4.RELEASE.jar spring-aspects-3.2.4.RELEASE.jar spring ...
- 使用Charles进行网络请求抓包解析
使用Charles进行网络请求抓包解析 0. 懒人的福音(⌐■_■)(破解版下载地址,记得安装java库支持) http://pan.baidu.com/s/1c08ksMW 1. 查看电脑的ip地址 ...
- GPS数据包格式及数据包解析
GPS数据包解析 GPS数据包解析 目的 GPS数据类型及格式 数据格式 数据解释 解析代码 结构体定义 GPRMC解析函数 GPGGA解析函数 测试样例输出 gps数据包格式 gps数据解析 车联网 ...
- 蓝牙4.0BLE抓包(二) – 广播包解析
版权声明:本文为博主原创文章,转载请注明作者和出处. 作者:强光手电[艾克姆科技-无线事业部] 在使用EN-Dongle捕获和解析广播包之前,我们先了解一下BLE报文的结构,之后,再对捕获的广播 ...
- Caffe实战三(依赖包解析及环境配置)
前面的文章使用的软件环境是开始时通过apt-get命令所安装的,本文将通过编译源码的方式重新配置一个可迁移的软件环境.(参考:<深度学习 21天实战Caffe> 第五天 Caffe依赖包解 ...
- 蓝牙4.0 BLE 广播包解析
在使用EN-Dongle捕获和解析广播包之前,我们先了解一下BLE报文的结构,之后,再对捕获的广播包进行分析.在学习BLE的时候,下面两个文档是极其重要的,这是SIG发布的蓝牙的核心协议和核心协议增补 ...
- 使用parquet-hadoop.jar包解析hive parquet文件时,遇到FIXED_LEN_BYTE_ARRAY转换为Decimal 以及 INT96转换为timestamp问题
在使用parquet-hadoop.jar包解析parquet文件时,遇到decimal类型的数据为乱码,具体解决方法如下: 使用parquet-Hadoop.jar解析httpfs服务提供的parq ...
随机推荐
- 【Linux】linux history命令执行后显示历史命令执行时间
vim ~/.bashrc 或者 ~/.bash_profile 或者 获取root权限修改vim /etc/profile 最后添加 export HISTTIMEFORMAT="%F ...
- 【Linux】zookeeper-3.5.6启动失败8080端口被占用
通过查看zookeeper的官方文档 1. 可以禁用adminServer 2.可以删除jetty服务
- C#算法设计查找篇之01-顺序查找
顺序查找(Sequential Search) 该文章的最新版本已迁移至个人博客[比特飞],单击链接 https://www.byteflying.com/archives/697 访问. 顺序查找也 ...
- 解Bug之路-dubbo流量上线时的非平滑问题
前言 笔者最近解决了一个困扰了业务系统很久的问题.这个问题只在发布时出现,每次只影响一两次调用,相较于其它的问题来说,这个问题有点不够受重视.由于种种原因,使得这个问题到了业务必须解决的程度,于是就到 ...
- 【ZJOI2012】灾难 - LCA+拓扑排序
题目描述 阿米巴是小强的好朋友. 阿米巴和小强在草原上捉蚂蚱.小强突然想,如果蚂蚱被他们捉灭绝了,那么吃蚂蚱的小鸟就会饿死,而捕食小鸟的猛禽也会跟着灭绝,从而引发一系列的生态灾难. 学过生物的阿米巴告 ...
- 一些Java中不为人知的特殊方法,学完后面试官可能都没你知道的多!
如果你用过反射并且执行过getDeclaredMethods方法的话,你可能会感到很吃惊.你会发现出现了很多源代码里没有的方法.如果你看一下这些方法的修饰符的话,可能会发现里面有些方法是volatil ...
- AS 新安装Android Studio运行项目前报错:Unable to access Android SDK add-on list
新安装Android Studio运行项目前报错:Unable to access Android SDK add-on list AS启动后,会在默认路径下检测是否有Android SDK,如果没有 ...
- JAVA字符串的替换replace、replaceAll、replaceFirst的区别解析。
String str = "i.like.cat"; System.out.println(str.replace(".", "!")); ...
- JavaScript学习系列博客_17_JavaScript中的函数的参数、返回值
数的形参(形式参数) - 定义函数时,可以在()中定义一个或多个形参,形参之间使用英文逗号隔开:定义形参就相当于在函数内声明了对应的变量但是并不赋值,形参会在调用时才赋值. 函数的实参(实际参数) - ...
- 1.Oracle数据库简介
Oracle数据库简介 Oracle Database,又名Oracle RDBMS,或简称Oracle.是甲骨文公司的一款关系数据库管理系统.它是在数据库领域一直处于领先地位的产品.可以说Oracl ...