spark-2-RDD
RDD提供了一个抽象的数据架构,我们不必担心底层数据的分布式特性,只需将具体的应用逻辑表达为一系列转换处理,不同RDD之间的转换操作形成依赖关系,可以实现管道化,从而避免了中间结果的存储,大大降低了数据复制、磁盘IO和序列化开销。
一个RDD就是一个分布式对象集合,本质上是一个只读的分区记录集合,每个RDD可以分成多个分区,每个分区就是一个数据集片段,并且一个RDD的不同分区可以被保存到集群中不同的节点上,从而可以在集群中的不同节点上进行并行计算。
RDD提供了一种高度受限的共享内存模型,即RDD是只读的记录分区的集合,不能直接修改,只能基于稳定的物理存储中的数据集来创建RDD,或者通过在其他RDD上执行确定的转换操作(如map、join和groupBy)而创建得到新的RDD。RDD提供了一组丰富的操作以支持常见的数据运算,分为“行动”(Action)和“转换”(Transformation)两种类型,前者用于执行计算并指定输出的形式,后者指定RDD之间的相互依赖关系。
两类操作的主要区别是,转换操作(比如map、filter、groupBy、join等)接受RDD并返回RDD,而行动操作(比如count、collect等)接受RDD但是返回非RDD(即输出一个值或结果)。RDD提供的转换接口都非常简单,都是类似map、filter、groupBy、join等粗粒度的数据转换操作,而不是针对某个数据项的细粒度修改。因此,RDD比较适合对于数据集中元素执行相同操作的批处理式应用,而不适合用于需要异步、细粒度状态的应用(比如Web应用系统、增量式的网页爬虫等)。
RDD典型的执行过程:
- RDD读入外部数据源(或者内存中的集合)进行创建;
- RDD经过一系列的“转换”操作,每一次都会产生不同的RDD,供给下一个“转换”使用;
- 最后一个RDD经“行动”操作进行处理,并输出到外部数据源(或者变成Scala集合或标量)。
RDD采用了惰性调用,即在RDD的执行过程中,真正的计算发生在RDD的“行动”操作,对于“行动”之前的所有“转换”操作,Spark只是记录下“转换”操作应用的一些基础数据集以及RDD生成的轨迹,即相互之间的依赖关系,而不会触发真正的计算。
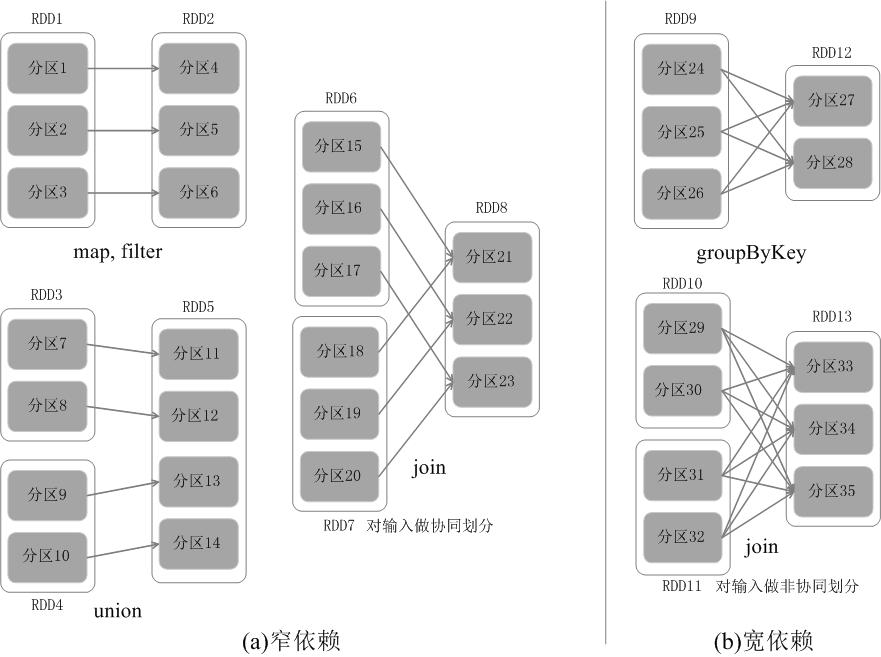
宽窄依赖:
(1)对输入进行协同划分,属于窄依赖。协同划分(co-partitioned)是指多个父RDD的某一分区的所有“键(key)”,落在子RDD的同一个分区内,不会产生同一个父RDD的某一分区,落在子RDD的两个分区的情况。
(2)对输入做非协同划分,属于宽依赖。对于窄依赖的RDD,可以以流水线的方式计算所有父分区,不会造成网络之间的数据混合。对于宽依赖的RDD,则通常伴随着Shuffle操作,即首先需要计算好所有父分区数据,然后在节点之间进行Shuffle。
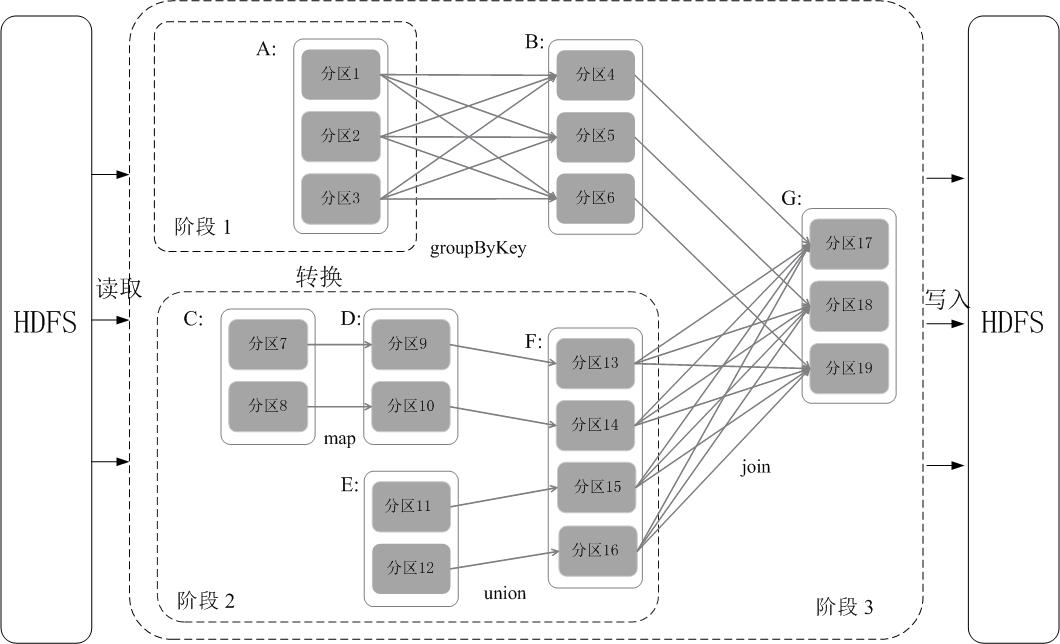
阶段的划分:
在DAG中进行反向解析,遇到宽依赖就断开,遇到窄依赖就把当前的RDD加入到当前的阶段中;将窄依赖尽量划分在同一个阶段中,可以实现流水线计算。
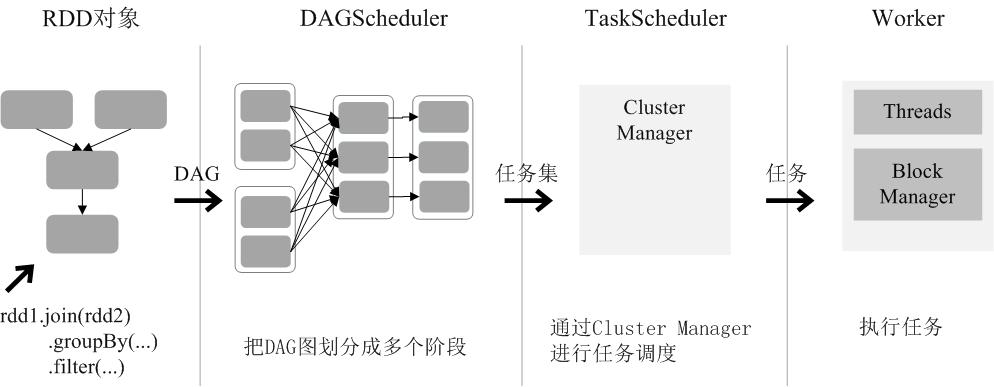
RDD的运行过程:
(1)创建RDD对象;
(2)SparkContext负责计算RDD之间的依赖关系,构建DAG;
(3)DAGScheduler负责把DAG图分解成多个阶段,每个阶段中包含了多个任务,每个任务会被任务调度器分发给各个工作节点(Worker Node)上的Executor去执行。
Source【厦门大学林子雨大数据实验室spark入门教程】http://dblab.xmu.edu.cn/blog/1709-2/
spark-2-RDD的更多相关文章
- [Spark] Spark的RDD编程
本篇博客中的操作都在 ./bin/pyspark 中执行. RDD,即弹性分布式数据集(Resilient Distributed Dataset),是Spark对数据的核心抽象.RDD是分布式元素的 ...
- Spark核心—RDD初探
本文目的 最近在使用Spark进行数据清理的相关工作,初次使用Spark时,遇到了一些挑(da)战(ken).感觉需要记录点什么,才对得起自己.下面的内容主要是关于Spark核心-RDD的相关 ...
- 关于Spark中RDD的设计的一些分析
RDD, Resilient Distributed Dataset,弹性分布式数据集, 是Spark的核心概念. 对于RDD的原理性的知识,可以参阅Resilient Distributed Dat ...
- [Spark][Python][RDD][DataFrame]从 RDD 构造 DataFrame 例子
[Spark][Python][RDD][DataFrame]从 RDD 构造 DataFrame 例子 from pyspark.sql.types import * schema = Struct ...
- spark中RDD的转化操作和行动操作
本文主要是讲解spark里RDD的基础操作.RDD是spark特有的数据模型,谈到RDD就会提到什么弹性分布式数据集,什么有向无环图,本文暂时不去展开这些高深概念,在阅读本文时候,大家可以就把RDD当 ...
- Spark核心RDD、什么是RDD、RDD的属性、创建RDD、RDD的依赖以及缓存、
1:什么是Spark的RDD??? RDD(Resilient Distributed Dataset)叫做弹性分布式数据集,是Spark中最基本的数据抽象,它代表一个不可变.可分区.里面的元素可并行 ...
- [转]Spark学习之路 (三)Spark之RDD
Spark学习之路 (三)Spark之RDD https://www.cnblogs.com/qingyunzong/p/8899715.html 目录 一.RDD的概述 1.1 什么是RDD? ...
- Spark学习之路 (三)Spark之RDD
一.RDD的概述 1.1 什么是RDD? RDD(Resilient Distributed Dataset)叫做弹性分布式数据集,是Spark中最基本的数据抽象,它代表一个不可变.可分区.里面的元素 ...
- Spark之 RDD
简介 RDD(Resilient Distributed Dataset)叫做弹性分布式数据集,是Spark中最基本的数据抽象,它代表一个不可变.可分区.里面的元素可并行计算的集合. Resilien ...
- 解读Spark Streaming RDD的全生命周期
本节主要内容: 一.DStream与RDD关系的彻底的研究 二.StreamingRDD的生成彻底研究 Spark Streaming RDD思考三个关键的问题: RDD本身是基本对象,根据一定时间定 ...
随机推荐
- AQI分析
A Q I 分 析 1.背景信息 AOI( Air Quality Index),指空气质量指数,用来衡量空气清洁或污染的程度.值越小,表示空气质量越好.近年来,因为环境问题,空气质量也越来越受到人 ...
- sha1sum校验方法
sha1sum校验方法,我们可以保存到一个文件中.还可以根据已经得到的hash来确认文件.MD5类似. [root@ffcs211 test_dir]# sha1sum New.EXE 3fe44e8 ...
- SpringBoot事务使用和回滚
Springboot中事务的使用: 1.启动类加上@EnableTransactionManagement注解,开启事务支持(其实默认是开启的). 2.在使用事务的public(只有public支持事 ...
- 关于SpringBoot集成JDBCTemplate的RowMapper问题
JdbcTemplate 是Spring提供的一套JDBC模板框架,利用AOP 技术来解决直接使用JDBC时大量重复代码的问题.JdbcTemplate虽然没有MyBatis 那么灵活,但是直接使用J ...
- hdu6704 2019CCPC网络选拔赛1003 K-th occurrence 后缀自动机+线段树合并
解题思路: fail树上用权值线段树合并求right/endpos集合,再用倍增找到待查询串对应节点,然后权值线段树求第k大. #include<bits/stdc++.h> using ...
- git 如何比较不同分支的差异
前两天,良许在做集成的时候碰到了一件闹心事.事情是这样的,良许的一位同事不小心把一个错误的 dev 分支 merge 到了 master 分支上,导致了良许编译不通过.于是,我们需要将版本回退到 me ...
- 10_Python的函数function
1.函数的概述 1.函数是可以重复执行的语句块且可以重复调用,函数封装了可重复执行的语句提高了语句的可重复性 2.函数的参数和返回值的作用流程图: https://www.processon. ...
- 安装与激活PhpStrom
1.下载安装PHPstorm(https://pan.baidu.com/s/1nwK3ew5 密码dhtr) 2.运行 3.下一步选择中间,在http://idea.lanyus.com/ 上获取激 ...
- 理解C#回调函数
序言 本篇主要学习了C#回调函数的定义使用.欢迎各位大牛的指导. 正文 回调函数是什么? 回调函数就是一个通过函数指针调用的函数.如果你把函数的指针(地址)作为参数传递给另一个函数,当这个指针被用来调 ...
- 虚拟机安装centos常见问题
一.centos下载安装 环境:win10系统,虚拟机vm12, centos6.5 http://vault.centos.org/ 链接打开 选择6.5=>isos/=>x86_64= ...