[论文理解] Good Semi-supervised Learning That Requires a Bad GAN
Good Semi-supervised Learning That Requires a Bad GAN
恢复博客更新,最近没那么忙了,记录一下学习。
Intro
本文是一篇稍微偏理论的半监督学习的文章,通过证明一个能够生成非目标分布的、低样本密度的样本的生成器,对半监督学习的效果有很大的提升,这样的生成器作者称之为Complement Generator,而提升的原因是生成的bad样本填充了特征空间的低密度区域,从而使得分类的分类面在低密度区域,从而避免了分类面穿过流形的情况,因而能够提升分类的精度。为了得到这样的生成器,首先利用最大熵使得生成器的熵最大,一方面最大熵可以防止mode collapse,第二方面可以增加生成样本的丰富度,从而保证生成器能够生成低密度区域的样本;然后,利用pixel cnn来估计生成样本的概率密度,惩罚过于接近流形的生成器生成的样本。
参考了官方的代码,复现了一下本文的算法。
Theoretical Analysis
GAN-Based Semi-Supervised Learning
GAN-Based半监督学习一般采用K+1分类的方式来训练,与传统的两分类的GAN不同的是,用于半监督学习的GAN前K个类别负责预测具体类别,最后一个(K+1)负责预测true or fake。
因此,对于有标签的样本,我们大可将其分为前K类中的一类,对于无标签的样本,我们认为它们是真实样本,因此可以将前K个类别的和和第K+1类看成是二分类问题,对于生成的fake样本同理。
因此,GAN-Based半监督学习的Loss一般为:
\]
其中\(\ell\) 代表有标签的数据,\(p\)代表无标签的数据,\(p_G\)代表生成器生成的数据。
而“Improved techniques for training gans”中则提到,可以将第K+1类的权重设为0,这样可以减少全连接的参数,事实上,这样会让第K+1类的概率的分子项变为常值1,仍然满足K+1个类别的和为1.所以与原来K+1分类是等价的。
这里我记得代码里还有个trick是,计算log softmax可以减去一个值防止上溢,即:
LogSoftmax(x_i) = Log \frac{exp(x_i - c + c)}{\sum exp(x_j - c + c)} \\
= Log \frac{exp(x_i - c)}{\sum exp(x_j - c)} \cdot \frac{exp(c)}{exp(c)} \\
= Log \frac{exp(x_i - c)}{\sum exp(x_j - c)} \\
= (x_i - c) - Log \sum exp(x_j - c)
\]
Perfect Generator
一个完美的生成器,当然是生成图像的概率分布\(p_G\)和真实图像的概率分布\(p\)完全一致,即\(p_G = p\),此时作者给出了命题1:
Proposition 1
如果一个生成器是Perfect Generator,并且D有infinite capacity,那么对其实下式Loss的任意一个最优解D,都可以找到上面的Loss的最优解\(D^*\),使得\(P_D(y|x,y \le K) = P_{D^*}(y|x,y \leq K)\)。而下式的Loss则完全只包含分类的Loss,因此当生成器很完美的时候,很容易退化为下面的Loss,则相当于只做了有监督部分,而无标签的数据并没有得到充分利用。
\]
命题1的证明也很简单:

可以看出来,我们要让\(J_D\)取得最大值,所以要同时使得\(L_D\)和后面那一项最大,而后面那一项取得最大值的结果就是\(P_D(K+1|x) = \frac{1}{2}\),然后根据(6),是可以找到这样一组解的。因此证明了可以得到一组解,可以使得只用有监督部分的Loss和两者都用的Loss一样,从而证明了其实存在局部解可以使半监督部分失去意义。
Complement Generator
假定映射\(f\)可以将输入空间映射到特征空间,令\(p_k(f)\)表示第k类样本在特征空间的概率密度,给定一个阈值\(\epsilon_k\),令\(F_k = {f:p_k(f) > \epsilon_k}\),并且假定给定\(\{\epsilon_k\}_{k=1}^{K}\),\(F_k\)之间都有一个margin,这就可以理解为,可以找到一组\(\epsilon\)使得任意两个分类面的流形完全分开,分开的距离是一个margin,当然,最好的情况就是\(\epsilon\)足够小,这样才能保证泛化性能。那么Complement Generator做的就是生成这些流形之外的样本,也就是流形与流形之间的样本。
以一维为例,则就是下图所示的样子了:
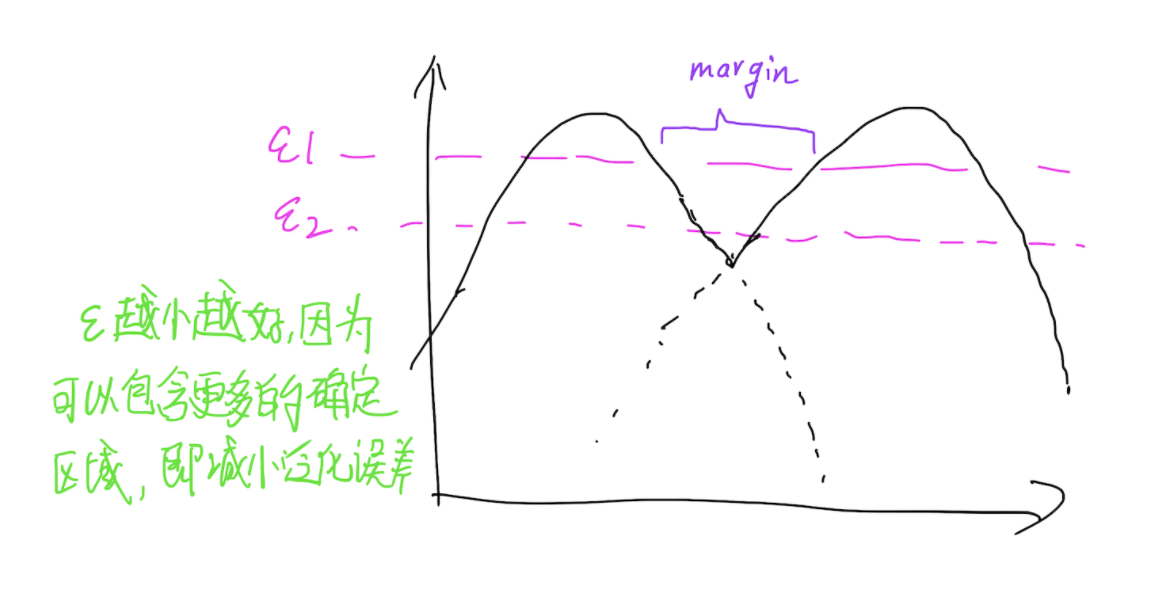
Assumption 1. Convergence conditions.
当\(D\)收敛之后,认为\(D\)能够学习到一个很好的分类面使得所有的训练的不同类别样本都可以分开,也就是说,必须满足以下三个条件:
- 对于任意的\((x,y) \in \ell\)均有\(w^T_yf(x) > w_k^Tf(x)\)成立,k表示其他类别(\(k \neq y\))
- 对于任意的\(x \in \mathcal{G}\),均有\(\max_{k=1}^Kw_k^Tf(x)<0\)成立
- 对于任意的\(x\in \mathcal{U}\),均有\(\max_{k=1}^Kw_k^Tf(x) > 0\)成立
由此,提出引理1
Lemma 1
假设对于所有的k,都有\(||w_k||_2 \leq C\),假设存在一\(\epsilon >0\),使得对于任意的\(f_G \in F_G\),存在一\(f'_G \in \mathcal{G}\)使得\(||f_G - f_G'||_2 \leq \epsilon\), 根据假设1,则有对任意\(k \leq K\),都有\(w_k^T < C\epsilon\)。
证明比较简单:
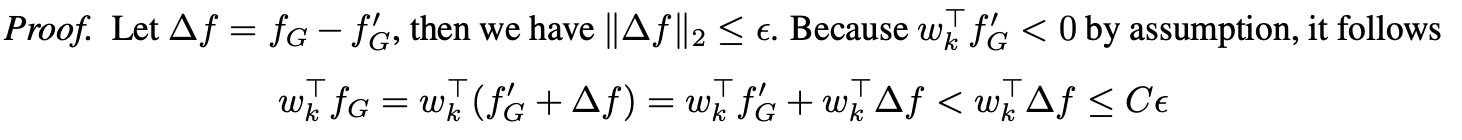
因此可以得到下面的推论
Corollary 1
如果能够生成无穷的样本,则有\(\lim_{|\mathcal{G}| \to \infty}w_k^Tf_G <0\)
Proposition 2
在引理1的条件下,对于任意类别\(k \leq K\),对于任意特征空间中的点\(f_k \in F_k\),都有\(w_k^T f_k > w_j^Tf_k\)成立,其中\(j \neq k\)
可以用反证法来证明,如果假设\(w_k^T f_k \leq w_j^Tf_j\),那么一定存在一个\(\alpha\),得到一个特征空间中的点\(f_G = \alpha w^T_kf_k + (1 - \alpha)w^T_j f_j\)在流形之外,则有\(w_j^Tf_G \leq 0\),而\(w_k^Tf_k >0\)并且\(w_j^Tf_j>0\)矛盾了。
事实上,如果生成的样本把流形之外的空间填充的足够好,这样相当于强行让分类面落在流形的边界处,从而避免了分类面穿过流形的情况。
Case Study on Synthetic Data
上面都是偏理论的分析,然后作者以简单的demo来浅显的说明上述观点的可行性。
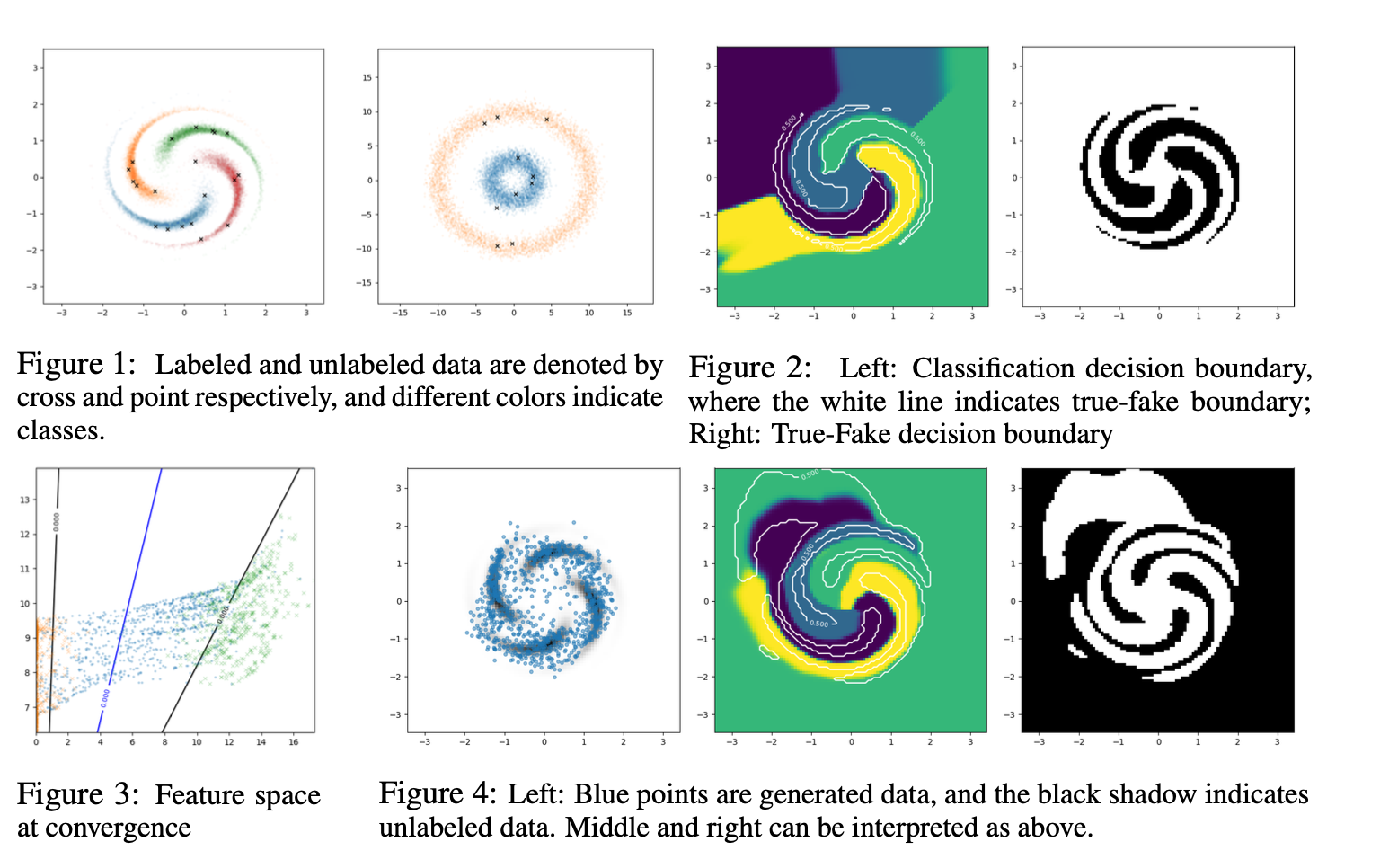
以如图所示的2D demo为例,fig 1中每种颜色代表一种流形,点代表有标签的数据。
fig 2 是 Complement Generator生成的样本点去分类之后的分类面,可以看出无论是真假样本分类还是具体类别的分类,分类面都比较完美。
fig 3是特征空间的demo 可视化,是以fig 1中第二个图为例展示的,可以看出生成的样本基本都在流形之间,并且可以找到最佳的分类面,也就是蓝色的线,将流形分开。
fig 4 是直接使用feature matching方式生成样本的结果,可以看到大多数样本其实都生成在来流形内部,右边的分类面也不完美,因此传统的feature matching方法是存在很大的问题的。
Approach
为了得到这样的生成器,本文依据feature matching GAN的不足,提出以下几点改进:
- 使用最大熵防止collapse,并且生成流形之外的样本
- 估计生成样本的概率并将生成的太接近流形的样本去掉
对于最大熵,本文提出两种方式实现,
第一种是通过变分的方式,将输入空间编码到高斯分布,由于生成器的熵的负值具有变分上界,即\(-\mathcal{H}(p_G(x)) \leq - \mathbb{E}_{x,z \backsim p_G}log q(z|x)\),通过限定高斯分布的方差范围从而避免任意分布,这样就可以利用高斯分布的熵来达到最大化生成器熵的目的。
第二种是通过使用pull-away term的辅助loss来实现,尽量让生成的样本之间的距离增大,从而增大生成器的熵。
为了保证生成样本都在低密度区域,必须把生成样本接近流形的点去掉。而去掉不会帮助生成器来优化生成的样本,因此可以加惩罚项惩罚接近流形的样本,继而优化生成器。
\]
此外,文章对无标签的数据加了个条件熵最小化的Loss,因为这类样本没有标签,可能学习到一个对所有标签均匀分布的结果,因此最小化标签的熵,可以让网络D尽量将概率分布变为一个确定的分布,最确定的情况也就是熵最小的情况,就是某一类的概率为1,其他皆为0.
复现和实验
参考官方的代码,复现了一下MNIST上的结果,没有加PT和PixelCNN,但是结果已经相当不错了,仅仅几个epoch,在每类只给5个样本下的MNIST上就能达到95%的TOP1 ACC。

[论文理解] Good Semi-supervised Learning That Requires a Bad GAN的更多相关文章
- Machine Learning Algorithms Study Notes(2)--Supervised Learning
Machine Learning Algorithms Study Notes 高雪松 @雪松Cedro Microsoft MVP 本系列文章是Andrew Ng 在斯坦福的机器学习课程 CS 22 ...
- A brief introduction to weakly supervised learning(简要介绍弱监督学习)
by 南大周志华 摘要 监督学习技术通过学习大量训练数据来构建预测模型,其中每个训练样本都有其对应的真值输出.尽管现有的技术已经取得了巨大的成功,但值得注意的是,由于数据标注过程的高成本,很多任务很难 ...
- [翻译] TensorFlow 分布式之论文篇 "TensorFlow : Large-Scale Machine Learning on Heterogeneous Distributed Systems"
[翻译] TensorFlow 分布式之论文篇 "TensorFlow : Large-Scale Machine Learning on Heterogeneous Distributed ...
- A Brief Review of Supervised Learning
There are a number of algorithms that are typically used for system identification, adaptive control ...
- 读论文系列:Deep transfer learning person re-identification
读论文系列:Deep transfer learning person re-identification arxiv 2016 by Mengyue Geng, Yaowei Wang, Tao X ...
- Supervised Learning and Unsupervised Learning
Supervised Learning In supervised learning, we are given a data set and already know what our correc ...
- 论文笔记(1):Deep Learning.
论文笔记1:Deep Learning 2015年,深度学习三位大牛(Yann LeCun,Yoshua Bengio & Geoffrey Hinton),合作在Nature ...
- 监督学习Supervised Learning
In supervised learning, we are given a data set and already know what our correct output should look ...
- 学习笔记之Supervised Learning with scikit-learn | DataCamp
Supervised Learning with scikit-learn | DataCamp https://www.datacamp.com/courses/supervised-learnin ...
随机推荐
- 力扣Leetcode 3. 无重复字符的最长子串
无重复字符的最长子串 给定一个字符串,请你找出其中不含有重复字符的 最长子串 的长度. 示例 示例 1: 输入: "abcabcbb" 输出: 3 解释: 因为无重复字符的最长子串 ...
- 理解Word2Vec
一.简介 Word2vec 是 Word Embedding 的方法之一,属于NLP 领域.它是将词转化为「可计算」「结构化」的向量的过程.它是 2013 年由谷歌的 Mikolov 提出了一套新的词 ...
- Mac 安装多个版本jdk
JDK默认安装路径为/Library/Java/JavaVirtualMachines 多版本安装后效果为: 设置 1.执行以下命令 cd ~ open -e .bash_profile #打开.ba ...
- 面试【JAVA基础】集合类
1.ArrayList的扩容机制 每次扩容是原来容量的1.5倍,通过移位的方法实现. 使用copyOf的方式进行扩容. 扩容算法是首先获取到扩容前容器的大小.然后通过oldCapacity (oldC ...
- 深入了解Netty【八】TCP拆包、粘包和解决方案
1.TCP协议传输过程 TCP协议是面向流的协议,是流式的,没有业务上的分段,只会根据当前套接字缓冲区的情况进行拆包或者粘包: 发送端的字节流都会先传入缓冲区,再通过网络传入到接收端的缓冲区中,最终由 ...
- 剑指 Offer 42. 连续子数组的最大和
题目描述 输入一个整型数组,数组中的一个或连续多个整数组成一个子数组.求所有子数组的和的最大值. 要求时间复杂度为\(O(n)\). 示例1: 输入: nums = [-2,1,-3,4,-1,2,1 ...
- 小白也能弄懂的目标检测YOLO系列之YOLOV1 - 第二期
上期给大家展示了用VisDrone数据集训练pytorch版YOLOV3模型的效果,介绍了什么是目标检测.目标检测目前比较流行的检测算法和效果比较以及YOLO的进化史,这期我们来讲解YOLO最原始V1 ...
- Python学习—Anaconda详细 下载、安装与使用,以及如何创建虚拟环境,不仅仅只有安装步骤哦
上一期我们介绍了Python.Pycharm.Anaconda三者之间的关系以及使用,这一期主要详细介绍如何在Windows上下载和安装工具Anaconda,然后使用其自带的conda管理不同项目的虚 ...
- C015:十进制转8进制
程序: #include "stdafx.h" #include <string.h> int _tmain(int argc, _TCHAR* argv[]) { i ...
- 你会Spring Cloud吗?
如果有人问你这句话,你不要急着回答,因为答语和问者的关系莫大. 如果问你的是个老板或管理者,那么他多半不了解这项技术,很有可能只是知道这个技术名词而已,你知道的一定比他们深,你大可夸夸其谈的.在口若悬 ...