数据可视化之PowerQuery篇(十四)产品关联度分析
https://zhuanlan.zhihu.com/p/64510355
逛超市的时候,面对货架上琳琅满目的商品,你会觉得这些商品的摆放,或者不同品类的货架分布是随机排列的吗,当然不是。
应该都听说过啤酒与尿布的故事,这两个表面上毫不相关的商品,在超市中摆放在一起时二者的销量都大幅度提升。这里不论这个案例的真实性如何,但它对理解产品之间的关联十分形象,好的故事总是更有传播度。
购买某种商品的客户,对另一种商品,相对于其他商品,有更大的购买概率,这两种商品就具有更高的关联度,为了提高销售额,应尽可能将二者摆放到一起;网店也可以将一种产品放在另一种产品的推荐页中。
而要实现这个目的,首先就要挖掘出哪些商品之间存在更大的关联度。
下面用PowerBI来进行关联度分析。
假设一家超市的十几个产品的销售数据,我们要计算出购买产品A的客户中,有多少客户也同时购买了产品B?这些客户购买了产品B的金额有多大?
客户关联度
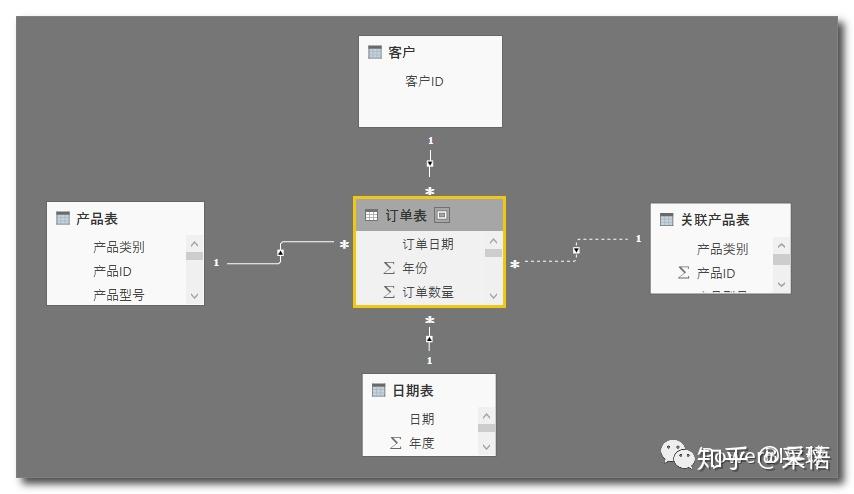
由于要分析的产品A和产品B都在产品表中,为了分别计算相互不影响,复制一个产品表,这里命名为'关联产品表',与订单表建立虚线关系,数据模型如下图,
将产品表中的产品名称拖入到表格中,作为产品A,然后利用下面这个度量值计算产品A的客户数量,
[客户数]=COUNTROWS(VALUES('订单表'[客户ID]))
然后利用关联产品表中的产品名称,生成一个切片器,以便选择不同的产品,关联产品假设为产品B。
下面这个是计算关联分析的重点,购买了A的客户中,有多少客户也购买了产品B?
也就是同时购买A和B的客户数,度量值如下:
同时购买A和B的客户数 =
VAR Bcustomer=
CALCULATETABLE(
VALUES('订单表'[客户ID]),
USERELATIONSHIP('关联产品表'[产品ID],'订单表'[产品ID]),
ALL('产品表')
)
RETURN CALCULATE([客户数],Bcustomer)
通过以上两个度量值相除,就可以计算出关联产品的客户占比,
关联客户占比 = DIVIDE([同时购买A和B的客户数],[客户数])
把上面这几个度量值放入表格中,通过点击不同的关联产品,就可以自动计算出产品A和产品B之间的重复客户占比,
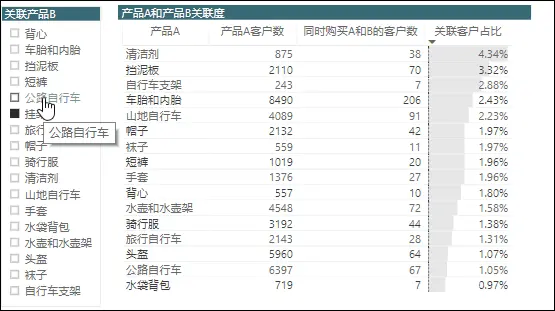
但是两个产品的客户的重合度高,不代表带来的销售额就更高,所以还要分析一下,购买A的客户中,同时购买的产品B销售额有多少?通过金额这个维度来分析一下关联性。
销售金额关联性
先来写两个简单的度量值,产品A的销售额和产品B的销售额:
产品A的销售额:
销售额=SUM('订单表'[销售金额])
产品B的销售额,
关联产品B的销售额 =
CALCULATE([销售额],
USERELATIONSHIP('关联产品表'[产品ID],'订单表'[产品ID]),
ALL('产品表') )
由于产品B来自于关联客户表,而关联客户表与订单表是虚线关系,所以用 USERELATIONSHIP来激活关系。它主要是为了计算购买产品A的客户中,购买了产品B的金额有多少?
然后就可以计算同时购买A和B的客户中,购买产品B的金额。
A客户购买B的金额 =
VAR Acustomer=
CALCULATETABLE(VALUES('订单表'[客户ID]))
VAR Bcustomer=
CALCULATETABLE(
VALUES('订单表'[客户ID]),
USERELATIONSHIP('关联产品表'[产品ID],'订单表'[产品ID]),
ALL('产品表'))
RETURN
CALCULATE([关联产品B的销售额],
NATURALINNERJOIN(Acustomer,Bcustomer)))
这个度量值的含义是,先找出产品A和产品B的客户列表,然后通过 NATURALINNERJOIN函数找出这两个客户列表的交集,也就是同时购买了这两种产品的客户,然后计算这些客户的产品B销售额就可以了。
同样把这个度量值放到表格中,可以看出关联销售额,
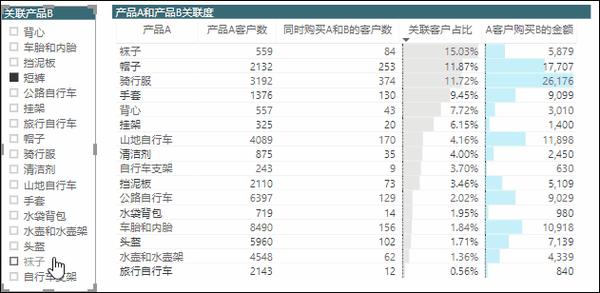
通过这个表格也可以看出,客户重合比例高的两个产品,带来的关联产品的销售额并不一定高,这个跟产品价格、购买数量都有关系。
关联度四象限分析
通过上面的几个度量值,获得了相关分析的数据,为了更直观的展示出产品之间的关联度,这里使用四象限分析法来展示。
其实就是制作一个散点图,将两个维度:客户占比作为Y轴,关联产品销售额作为X轴,并按客户占比、关联产品销售额的平均线作为恒线,切割出四个象限,并利用动态配色(请参考:利用这个新功能,轻松实现图表的动态配色)分别为每个象限的数据设置不同的颜色,显示效果如下:
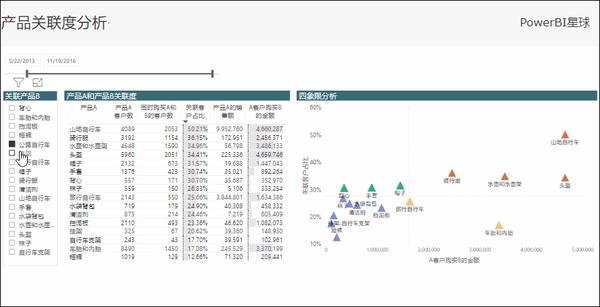
出现在第一象限(右上角)的产品,就是与切片器选中的产品不仅客户重合度高,而且带来的销售额也更高,具有高相关性,应该特别关注。
该模型还可以接着分析某一段时间的关联性,比如促销期间、节假日期间,客户的购买特征很可能与平时是不同的。
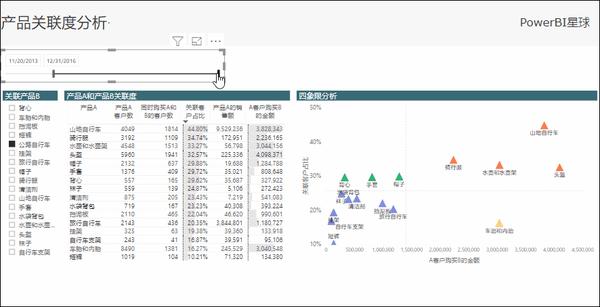
至此,一个简单的关联分析模型建立完成,根据关联产品的不同,动态显示不同的高相关度产品,并且可以随着时间段的变化而变化,
如果有客户画像、销售地点等数据,还可以将这些数据作为外部筛选器,挖掘出不同客户、不同地域的关联产品组合。
当然,这个模型挖掘的关联产品只是初步结果,还应对这个结果进行进一步验证,避免因偶然或人为因素导致的关联性,比如是否有某两种商品的捆绑销售活动等。
关联分析是非常有用的数据挖掘方式,能够帮助企业进行精准产品营销、产品组合以及发现更多潜在客户,真正的利用数据,为企业创造价值。
数据可视化之PowerQuery篇(十四)产品关联度分析的更多相关文章
- 数据可视化之PowerQuery篇(四)二维表转一维表,看这篇文章就够了
https://zhuanlan.zhihu.com/p/69187094 数据分析的源数据应该是规范的,而规范的其中一个标准就是数据源应该是一维表,它会让之后的数据分析工作变得简单高效. 在之前的文 ...
- 数据可视化之 图表篇(四) 那些精美的Power BI可视化图表
之前使用自定义图表,每次新打开一个新文件时,都需要重新添加,无法保存,在PowerBI 6月更新中,这个功能得到了很大改善,可以将自定义的图表固定在内置图表面板上了. 添加自定义图表后,右键>固 ...
- 数据可视化之PowerQuery篇(十一)使用Power BI进行动态帕累托分析
https://zhuanlan.zhihu.com/p/57763423 上篇文章介绍了帕累托图的用处以及如何制作一个简单的帕累托图,在 PowerBI 中可以很方便的生成,但若仅止于此,并不足以体 ...
- 数据可视化之PowerQuery篇(十八)Power BI数据分析应用:结构百分比分析法
https://zhuanlan.zhihu.com/p/113113765 本文为星球嘉宾"海艳"的PowerBI数据分析工作实践系列分享之二,她深入浅出的介绍了PowerBI ...
- 数据可视化之PowerQuery篇(十九)PowerBI数据分析实践第三弹 | 趋势分析法
https://zhuanlan.zhihu.com/p/133484654 本文为星球嘉宾"海艳"的PowerBI数据分析工作实践系列分享之三,她深入浅出的介绍了PowerBI ...
- 数据可视化之PowerQuery篇(十)如何将Excel的PowerQuery查询导入到Power BI中?
https://zhuanlan.zhihu.com/p/78537828 最近碰到星友的一个问题,他是在Excel的PowerQuery中已经把数据处理好了,但是处理后的数据又想用PowerBI来分 ...
- 数据可视化之PowerQuery篇(十六)使用Power BI进行流失客户分析
https://zhuanlan.zhihu.com/p/73358029 为了提升销量,在不断吸引新客户的同时,还要防止老客户离你而去,但每一个顾客不可能永远是你的客户,不可避免的都会经历新客户.活 ...
- 数据可视化之PowerQuery篇(十二)客户购买频次分布
https://zhuanlan.zhihu.com/p/100070260 商业数据分析通常都可以简化为对数据进行筛选.分组.汇总的过程,本文通过一个实例来看看PowerBI是如何快速完成整个过程的 ...
- 数据可视化之PowerQuery篇(二十)如何计算在职员工数量?
https://zhuanlan.zhihu.com/p/128652582 经常碰到的一类问题是,如何根据起止日期来计算某个时间点的数量,比如: 已知合同的生效日期和到期日期,特定日期的有效合同有 ...
随机推荐
- unittest实现用例运行失败截图
把这个方法放到父类basecase(unittest.TestCase)就行了 #coding: utf-8 import unittest, random, os, traceback from s ...
- 【01JMeter基础】线程组
线程组 我们存在接口请求的地方,在JMeter中我们使用最多的模块,分为 setUp线程组.线程组.tearDown线程组 setUp线程组:不论如何排序,都会在所有的线程组中被最早执行,如果有多个s ...
- vc6.0代码转vs2017相关问题
vc6.0代码转vs2017相关问题 命令行 error D8016: “/ZI”和“/Gy-”命令行选项不兼容fatal error C1083: 无法打开包括文件: “WinSock2.h”: N ...
- cc4a-c++类定义与struct定义方式代码示范
cc4a-c++类定义与struct定义方式代码示范 #include <iostream> #include <string> using namespace std; st ...
- 新老单点的改造——-理解Cookie、Session、Token
近期参与了新老单点的改造,一直想总结一下,发现这篇文章比较贴切. 整理了如下: 随着交互式Web应用的兴起,像在线购物网站,需要登录的网站等等,马上就面临一个问题,那就是要管理会话,必须记住哪些人登录 ...
- skywalking学习ppt
和传统应用监控的区别,Dapper论文 监控图
- 尚学堂 213_尚学堂_高淇_java300集最全视频教程_反射机制_提高反射效率_操作泛型_操作注解_合并文件.mp4
在反射的时候如果去掉了安全性检测机制,能够大大的提高反射的执行效率,我们来看下面的代码进行比较 package com.bjsxt.test; import java.lang.reflect.Met ...
- 如何在项目开发中应用好“Deadline 是第一生产力”?
我想也许你早就听说过"Deadline是第一生产力"这句话,哪怕以前没听说过,我相信看完本文后,再也不会忘记这句话,甚至时不时还要感慨一句:"Deadline是第一生产力 ...
- ref和out的使用及区别
1. ref的使用:使用ref进行参数的传递时,该参数在创建时,必须设置其初始值,且ref侧重于修改: 2. out的使用: 采用out参数传递时,该参数在创建时,可以不设置初始值,但是在方法中必须 ...
- 浏览器的回流与重绘 (Reflow & Repaint)
写在前面 在讨论回流与重绘之前,我们要知道: 浏览器使用流式布局模型 (Flow Based Layout). 浏览器会把HTML解析成DOM,把CSS解析成CSSOM,DOM和CSSOM合并就产生了 ...