大数据专栏 - 基础1 Hadoop安装配置
Hadoop安装配置
环境
1, JDK8 --> 位置: /opt/jdk8
2, Hadoop2.10: --> 位置: /opt/bigdata/hadoop210
3, CentOS 7虚拟机试验集群规划
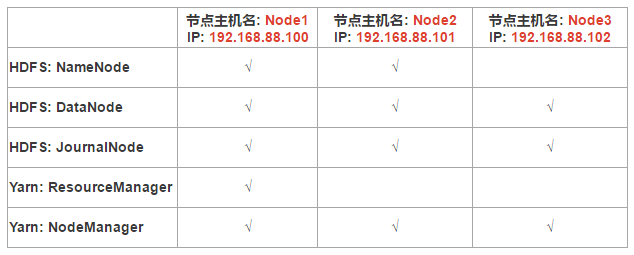
一,安装步骤
1, 解压缩
cd /opt/bigdata
tar -zxvf hadoop-2.10.1.tar.gz
mv ./hadoop-2.10.1 hadoop210
2, 配置
cd /opt/bigdata/hadoop210/etc/hadoop/
2.1 修改hadoop-env.sh
[root@node1 hadoop27]# echo $JAVA_HOME
/opt/jdk8
vim hadoop-env.sh
export JAVA_HOME=/opt/jdk8
2.2 修改core-site.xml
[root@node1 hadoop210]# pwd
/opt/bigdata/hadoop210
[root@node1 hadoop210]# mkdir hadoopDatas
[root@node1 hadoop210]# cd /opt/bigdata/hadoop210/etc/hadoop/
[root@node1 hadoop210]# vim core-site.xml
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://node1:8020</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/bigdata/hadoop210/hadoopDatas/tempDatas</value>
</property>
<!-- 缓冲区大小,实际工作中根据服务器性能动态调整 -->
<property>
<name>io.file.buffer.size</name>
<value>4096</value>
</property>
<!-- 开启hdfs的垃圾桶机制,删除掉的数据可以从垃圾桶中回收,单位分钟 -->
<property>
<name>fs.trash.interval</name>
<value>10080</value>
</property>
</configuration>
2.3 修改hdfs-site.xml
[root@node1 hadoop]# cd /opt/bigdata/hadoop210/etc/hadoop/
[root@node1 hadoop]# vi hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>node1:50090</value>
</property>
<property>
<name>dfs.namenode.http-address</name>
<value>node1:50070</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///opt/bigdata/hadoop210/hadoopDatas/namenodeDatas</value>
</property>
<!-- 定义dataNode数据存储的节点位置,实际工作中,一般先确定磁盘的挂载目录,然后多个目录用,进行分割 -->
<property>
<name>dfs.datanode.data.dir</name>
<value>file:///opt/bigdata/hadoop210/hadoopDatas/datanodeDatas</value>
</property>
<property>
<name>dfs.namenode.edits.dir</name>
<value>file:///opt/bigdata/hadoop210/hadoopDatas/nn/edits</value>
</property>
<property>
<name>dfs.namenode.checkpoint.dir</name>
<value>file:///opt/bigdata/hadoop210/hadoopDatas/snn/name</value>
</property>
<property>
<name>dfs.namenode.checkpoint.edits.dir</name>
<value>file:///opt/bigdata/hadoop210/hadoopDatas/dfs/snn/edits</value>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
<property>
<name>dfs.blocksize</name>
<value>134217728</value>
</property>
</configuration>
2.4 修改yarn-site.xml
[root@node1 hadoop]# vi yarn-site.xml
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>node1</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>20480</value>
</property>
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>2048</value>
</property>
<property>
<name>yarn.nodemanager.vmem-pmem-ratio</name>
<value>2.1</value>
</property>
</configuration>
2.5 修改mapred-env.sh
[root@node1 hadoop]# vi mapred-env.sh
export JAVA_HOME=/opt/jdk8
2.6 修改mapred-site.xml
[root@node1 hadoop]# mv mapred-site.xml.template ./mapred-site.xml
[root@node1 hadoop]# vi mapred-site.xml
<configuration>
<property>
<name>mapreduce.job.ubertask.enable</name>
<value>true</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>node1:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>node1:19888</value>
</property>
</configuration>
2.7 修改slaves
[root@node1 hadoop]# vi slaves
node1
node2
node3
2.8 配置Hadoop环境变量
[root@node1 hadoop]# vi /etc/profile
export HADOOP_HOME=/opt/bigdata/hadoop210
export PATH=:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$FINDBUGS_HOME/bin:$MAVEN_HOME/bin:$JAVA_HOME/bin:$PATH
[root@node1 hadoop]# source /etc/profile
2.9 分发安装包
[root@node1 hadoop210]# cd /opt/bigdata/hadoop210/
[root@node1 hadoop210]# scp -r hadoop210 node2:$PWD
[root@node1 hadoop210]# scp -r hadoop210 node3:$PWD
[root@node1 hadoop210]# scp /etc/profile node2:/etc/
[root@node1 hadoop210]# scp /etc/profile node3:/etc/
分别在node2,node3节点机器执行以下命令: 刷新加载/etc/profile
source /etc/profile
3, 启动集群
前提: 3台机器上安装好了zookeeper, 并启动
zkServer.sh start
要启动 Hadoop 集群,需要启动 HDFS 和 YARN 两个模块。 注意: 首次启动 HDFS 时,必须对其进行格式化操作。 本质上是一些清理和 准备工作,因为此时的 HDFS 在物理上还是不存在的。
在node1节点机器执行以下命令
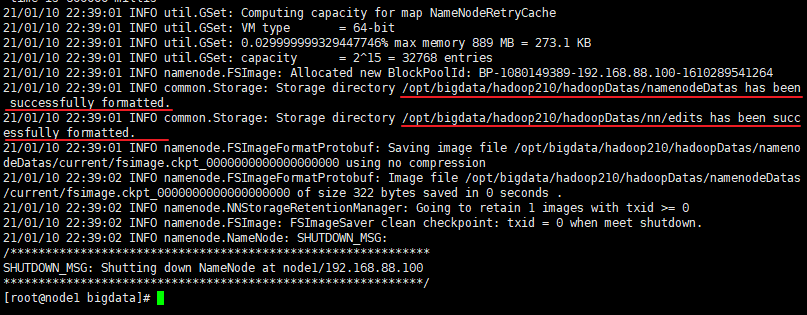
[root@node1 bigdata]# hdfs namenode -format
[root@node1 bigdata]# start-dfs.sh

[root@node1 bigdata]# start-yarn.sh

[root@node1 bigdata]# mr-jobhistory-daemon.sh start historyserver

启动完成之后, 可以通过jsp查看
大数据专栏 - 基础1 Hadoop安装配置的更多相关文章
- 大数据笔记13:Hadoop安装之Hadoop的配置安装
1.准备Linux环境 1.0点击VMware快捷方式,右键打开文件所在位置 -> 双击vmnetcfg.exe -> VMnet1 host-only ->修改subnet ip ...
- 大数据学习系列之七 ----- Hadoop+Spark+Zookeeper+HBase+Hive集群搭建 图文详解
引言 在之前的大数据学习系列中,搭建了Hadoop+Spark+HBase+Hive 环境以及一些测试.其实要说的话,我开始学习大数据的时候,搭建的就是集群,并不是单机模式和伪分布式.至于为什么先写单 ...
- 大数据系列之数据仓库Hive安装
Hive系列博文,持续更新~~~ 大数据系列之数据仓库Hive原理 大数据系列之数据仓库Hive安装 大数据系列之数据仓库Hive中分区Partition如何使用 大数据系列之数据仓库Hive命令使用 ...
- 大数据实时计算工程师/Hadoop工程师/数据分析师职业路线图
http://edu.51cto.com/roadmap/view/id-29.html http://my.oschina.net/infiniteSpace/blog/308401 大数据实时计算 ...
- 大数据学习笔记之Hadoop(一):Hadoop入门
文章目录 大数据概论 一.大数据概念 二.大数据的特点 三.大数据能干啥? 四.大数据发展前景 五.企业数据部的业务流程分析 六.企业数据部的一般组织结构 Hadoop(入门) 一 从Hadoop框架 ...
- 大数据平台搭建(hadoop+spark)
大数据平台搭建(hadoop+spark) 一.基本信息 1. 服务器基本信息 主机名 ip地址 安装服务 spark-master 172.16.200.81 jdk.hadoop.spark.sc ...
- 大数据学习系列之四 ----- Hadoop+Hive环境搭建图文详解(单机)
引言 在大数据学习系列之一 ----- Hadoop环境搭建(单机) 成功的搭建了Hadoop的环境,在大数据学习系列之二 ----- HBase环境搭建(单机)成功搭建了HBase的环境以及相关使用 ...
- 大数据学习系列之六 ----- Hadoop+Spark环境搭建
引言 在上一篇中 大数据学习系列之五 ----- Hive整合HBase图文详解 : http://www.panchengming.com/2017/12/18/pancm62/ 中使用Hive整合 ...
- 大数据入门基础系列之Hadoop1.X、Hadoop2.X和Hadoop3.X的多维度区别详解(博主推荐)
不多说,直接上干货! 在前面的博文里,我已经介绍了 大数据入门基础系列之Linux操作系统简介与选择 大数据入门基础系列之虚拟机的下载.安装详解 大数据入门基础系列之Linux的安装详解 大数据入门基 ...
随机推荐
- 第 6 篇 Scrum 冲刺博客
每天举行会议 会议照片: 昨天已完成的工作与今天计划完成的工作及工作中遇到的困难: 成员姓名 昨天完成工作 今天计划完成的工作 工作中遇到的困难 蔡双浩 实现关注,被关注功能 补充注释,初步查找bug ...
- 四、git学习之——远程仓库
Git是分布式版本控制系统,同一个Git仓库,可以分布到不同的机器上.怎么分布呢?最早,肯定只有一台机器有一个原始版本库,此后,别的机器可以"克隆"这个原始版本库,而且每台机器的版 ...
- 微信小程序图片保存到本地
微信小程序图片保存到本地是一个常用功能: 这里讲解下完整实现思路: 因为微信官方的授权只弹一次,用户拒绝后再次调用,就需要结合button组件的微信开放能力来调起,以下方案在微信各种授权中可参考. w ...
- Pycharm github登录 Invalid authentication data. Connection refused.
在github.com前加上 https:// 注意登录时使用的是用户名不是邮箱
- mycat配置MySQL主从读写分离
1.安装java 1.8 mycat 1.6要求的Java需要Java 1.8或1.8以上,安装Java参考以下链接: https://blog.csdn.net/weixin_43893397/ar ...
- OGG报错:Cannot load ICU resource bundle 'ggMessage', error code 2 - No such file or directory
[oracle@dgdb1 ~]$ ggsci Oracle GoldenGate Command Interpreter for OracleVersion 11.2.1.0.3 14400833 ...
- Java 8 新特性:Lambda、Stream和日期处理
1. Lambda 简介 Lambda表达式(Lambda Expression)是匿名函数,Lambda表达式基于数学中的λ演算得名,对应于其中的Lambda抽象(Lambda Abstract ...
- C#跳过工作日,计算几个工作日之后到期的方法
需求:消费者投诉企业,企业在2个工作日之内做出应答. 分析:1.工作日要刨去周末和法定节假日,而且每年的节假日不一样. 2.消费者可以在任意时间发起投诉,如果在非工作日发起了投诉,那么计算时间应该从工 ...
- js下 Day17、综合案例
一.面向对象轮播 效果图:
- Javascript JQuery select选择之Safari与Firefox
发现在苹果IOS手机及Safari浏览其中,如下代码不工作. $("#users option[value='hello']").attr("selected" ...