[2]R语言在数据处理上的禀赋之——可视化技术
本文目录
本文首发 https://program-dog.blogspot.com
注1:本文也曾在csdn发布,不过无法忍受csdn超长时间的审核,迁移到博客圆了。
注2 : 本文含有大量原创图,但本文首发在google的blogspot上,国内图片可能不可见,有时间我会换图床的。
本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。

R语言在可视化上可谓非常出众,想必这也是为什么R语言在数据处理方面受到追捧的原因之一。
上一节已经大体了解了R语言的基本数据类型,以及优势所在。R的可视化技术同样也是优势大大滴。这也是R的数据类型为可视化立下汗马功劳,为啥这样说呢?
Java的可视化技术
我们再拿Java开刀,和做一下对比。希望Java他老爹不要见怪。大家都知道,java做图真心说不上漂亮,为什么又拿java做对比呢?原因之一是我对java比较熟悉一点,之二是接下来对比的不是做图是否美观,而是做图的思路。而这个做图的思路,众语言都是大同小异,唯独R比较独特。
Java中,要想做出一副图,思路是,我想思考一下这附图上的 点、线、面可以怎样拆分,拆分好了我就分别画出 点、线、面,而要把点线面组合起来,要通过所谓的控件和容器。从而完成做图。下面举一个例子做出饼图:
代码来自这里,这个程序用了第三方包(否则程序更加复杂).
下面是代码:
import javax.swing.JPanel;
import org.jfree.chart.ChartFactory;
import org.jfree.chart.ChartPanel;
import org.jfree.chart.JFreeChart;
import org.jfree.data.general.DefaultPieDataset;
import org.jfree.data.general.PieDataset;
import org.jfree.ui.ApplicationFrame;
import org.jfree.ui.RefineryUtilities;
public class PieChart_AWT extends ApplicationFrame
{
public PieChart_AWT( String title )
{
super( title );
setContentPane(createDemoPanel( ));
}
private static PieDataset createDataset( )
{
DefaultPieDataset dataset = new DefaultPieDataset( );
dataset.setValue( "IPhone 5s" , new Double( 20 ) );
dataset.setValue( "SamSung Grand" , new Double( 20 ) );
dataset.setValue( "MotoG" , new Double( 40 ) );
dataset.setValue( "Nokia Lumia" , new Double( 10 ) );
return dataset;
}
private static JFreeChart createChart( PieDataset dataset )
{
JFreeChart chart = ChartFactory.createPieChart(
"Mobile Sales", // chart title
dataset, // data
true, // include legend
true,
false);
return chart;
}
public static JPanel createDemoPanel( )
{
JFreeChart chart = createChart(createDataset( ) );
return new ChartPanel( chart );
}
public static void main( String[ ] args )
{
PieChart_AWT demo = new PieChart_AWT( "Mobile Sales" );
demo.setSize( 560 , 367 );
RefineryUtilities.centerFrameOnScreen( demo );
demo.setVisible( true );
}
}
大家可以体会一下Java做图的复杂程度,如果你觉得Java还算简洁,那么且往下看。
R的可视化技术
牛刀小试
在R中做二维图有一个基本的函数plot 。比如我们有这样一组关于病人对不同药量(Dosage)和不同药物的反应的图表:

我们先创建三列数据:
dose <- c(20, 30, 40, 45, 60)
drugA <- c(16, 20, 27, 40, 60)
drugB <- c(15, 18, 25, 31, 40)
做图:
plot(dose, drugA,type="b")
title("Regression of MPG on Weight")
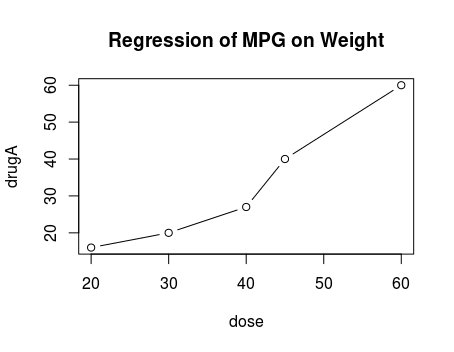
这样就做好了dose和drubA的一幅图。这里可以看出,dose和drubA 都被当作一个整体来对待了,又印证前面R在数据类型方面的优势。但是现在图表远没有那么漂亮,不用着急,plot自己就可以让图表变得漂亮,可定制化。
plot(dose, drugA,
type="b", # 图表类型,b为折线图
bg="green", # 背景颜色 绿色
fg="blue", # 前景颜色 蓝色
col="red", # 折线和点的颜色 红色
col.axis="grey", # 坐标轴文本颜色 灰色
col.lab="#3EB4EA", # 坐标轴标签颜色 我也叫不上来啥颜色
lty=3, # 线类型(line type)
lwd=3, # 线宽度 默认2
pch=15, # 点的类型 实心方块
cex=2, # 指定符号大小 2为 200%
col.main=rgb(1,1,1) # 标题的颜色
)
title("Regression of MPG on Weight(Colorful)")
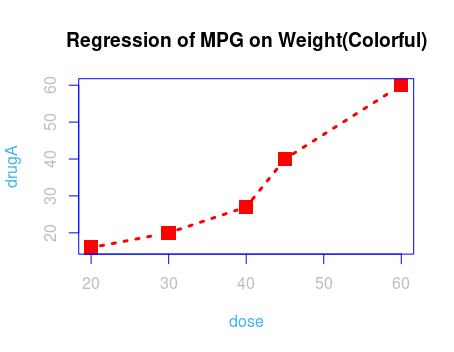
几个参数就把图装饰的漂漂亮亮的。那么,R是如何做到的呢?这与R的做图思路有相当大的关系,在R中讲求的是参数配置,而非点线面本身。
二维做图利器plot的参数配置
权限机制
R中做图函数的参数有一些是可以共有的,比如颜色,标题,注释坐标轴等都需要颜色,还有字体等,这些就被分配到了公共参数列表之中(如par),还有参数是函数本身独有的,比如画图的坐标轴就只有plot函数自己有。我们应当区分对待函数共有的和独有的参数,这样我运用起了就自如了。
plot独有的参数
plot的参数如下
plot(x, y = NULL, type = "p", xlim = NULL, ylim = NULL,
log = "", main = NULL, sub = NULL, xlab = NULL, ylab = NULL,
ann = par("ann"), axes = TRUE, frame.plot = axes,
panel.first = NULL, panel.last = NULL, asp = NA, ...)
看起来可能有一点晕。参数中除了最后的 ... (来自par) 和title有关的main,sub,xlab,ylab之外,其他都是独有的。下面结合例子来说明常用的参数怎么用,其他的请自行查手册.
先列出解释:
x, y = NULL, x,y坐标,y为空时候自动补上y
type = "p", 图的类型
xlim = NULL, x坐标轴的取值范围,如c(1,10)
ylim = NULL, y坐标轴的取值范围
ann = par("ann"), 要不要话标签
axes = TRUE, 要不要画轴
x=seq(1,10,len=100)
y=x^2
plot(x,y,
type="l",
xlim=c(-3,13),
ylim=c(-5,130),
ann=FALSE,
axes=FALSE
)
title("没有轴,没有标签")
效果图:

plot的type介绍
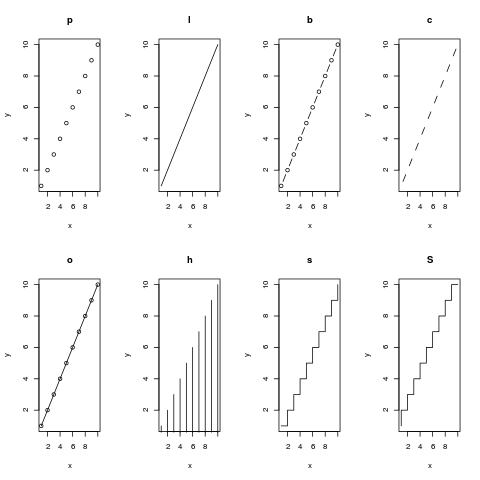
type指的是做图的类型,有必要介绍一下。
先列出参数:
"p" 点(points)
"l" 线(lines)
"b" 点和线(both)
"c" 线的部分(the lines part alone of "b")
"o" 线穿点 (both ‘overplotted’)
"h" 柱 (‘histogram’ like (or ‘high-density’) vertical lines)
"s" 阶梯(stair steps)
"S" 阶梯(other steps)
"n" 啥都不画 (no plotting)
做图:
opar <- par(no.readonly = TRUE)
par(mfrow=c(2,4)) #设置布局
x=1:10
y=x
plot(x,y,type="p",main="p")
plot(x,y,type="l",main="l")
plot(x,y,type="b",main="b")
plot(x,y,type="c",main="c")
plot(x,y,type="o",main="o")
plot(x,y,type="h",main="h")
plot(x,y,type="s",main="s")
plot(x,y,type="S",main="S")
par(opar)
效果图:
说完plot独有的参数,应该说一说其他的plot共有的或者plot也没有的参数了。
title介绍
title 不仅仅指的主(main)题目,还包括副(sub)题目,x,y轴的标签以及题目和图的距离(line)和题目是否在图内(outer).
title的参数如下:
title(main = NULL, sub = NULL, xlab = NULL, ylab = NULL,
line = NA, outer = FALSE, ...)
前四个参数的含义如下:
main 图像上面的主题目
sub 图像下面的副题目
xlab x轴标签
ylab y轴标签
这四个参数不仅在title中可用,在其他函数里面也可用(如plot直接可用)。
另外两个参数含义如下:
line 题目和图像的距离,距离太大就看不到题目了
outer 是一个布尔值,TRUE 的时候题目不会和图像在一起,默认FALSE
这两个参数是title独有,不可以在plot中直接用。
其他参数,诸如 ...代表的是,这些参数可以从par中取。
title中的main可接受list参数。
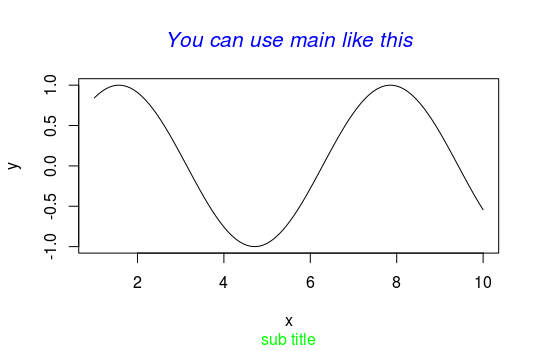
x=seq(1,10,len=100)
y=sin(x)
plot(x,y,type="l")
title(
main=list( # main can be a list or not ,up to you
"You can use main like this",
cex=1.3,
col="blue",
font=3
),
sub = "sub title",
col.sub="green" #from par
)
效果图:
公共参数集合——par
上面简单介绍了plot和title函数独有的部分,下面具体介绍一下公共参数集合par。这个函数包括了大多数plot的定制信息,简单举一个小例子:
par(no.readonly=TRUE)->opar #备份par
par(lty=2) #通过par设置参数
par(pch=17)
par(lty=2, pch=17)
dose <- c(20, 30, 40, 45, 60)
drugA <- c(16, 20, 27, 40, 60)
drugB <- c(15, 18, 25, 31, 40)
plot(dose, drugA, type="b")
title("Regression of MPG on Weight")
par(opar) #还原par
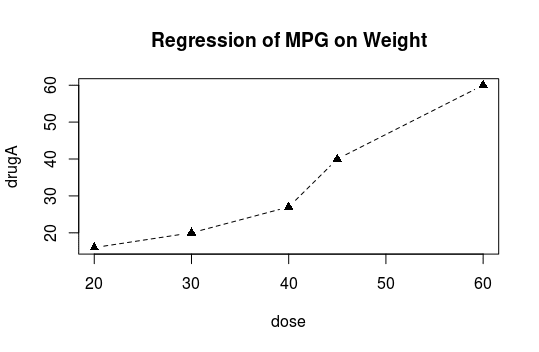
用par画出来的图。
那么par到底是个啥东东呢?简而言之,par只不过储存着plot的众多参数而已,plot在做图前,会去读par里面的变量,如果自己没有设置,就按照par里面的设置操作。我们把par打开看看是个什么东西:
> summary(par())
Length Class Mode
xlog 1 -none- logical
ylog 1 -none- logical
adj 1 -none- numeric
ann 1 -none- logical
ask 1 -none- logical
bg 1 -none- character
bty 1 -none- character
cex 1 -none- numeric
cex.axis 1 -none- numeric
cex.lab 1 -none- numeric
cex.main 1 -none- numeric
cex.sub 1 -none- numeric
cin 2 -none- numeric
col 1 -none- character
col.axis 1 -none- character
col.lab 1 -none- character
col.main 1 -none- character
col.sub 1 -none- character
cra 2 -none- numeric
crt 1 -none- numeric
csi 1 -none- numeric
cxy 2 -none- numeric
din 2 -none- numeric
err 1 -none- numeric
family 1 -none- character
fg 1 -none- character
fig 4 -none- numeric
fin 2 -none- numeric
font 1 -none- numeric
font.axis 1 -none- numeric
font.lab 1 -none- numeric
font.main 1 -none- numeric
font.sub 1 -none- numeric
lab 3 -none- numeric
las 1 -none- numeric
lend 1 -none- character
lheight 1 -none- numeric
ljoin 1 -none- character
lmitre 1 -none- numeric
lty 1 -none- character
lwd 1 -none- numeric
mai 4 -none- numeric
mar 4 -none- numeric
mex 1 -none- numeric
mfcol 2 -none- numeric
mfg 4 -none- numeric
mfrow 2 -none- numeric
mgp 3 -none- numeric
mkh 1 -none- numeric
new 1 -none- logical
oma 4 -none- numeric
omd 4 -none- numeric
omi 4 -none- numeric
page 1 -none- logical
pch 1 -none- numeric
pin 2 -none- numeric
plt 4 -none- numeric
ps 1 -none- numeric
pty 1 -none- character
smo 1 -none- numeric
srt 1 -none- numeric
tck 1 -none- numeric
tcl 1 -none- numeric
usr 4 -none- numeric
xaxp 3 -none- numeric
xaxs 1 -none- character
xaxt 1 -none- character
xpd 1 -none- logical
yaxp 3 -none- numeric
yaxs 1 -none- character
yaxt 1 -none- character
ylbias 1 -none- numeric
我们已然发现,里面有我们刚刚用过的比如bg,fg,col等。par 是一个函数,它的返回值是一个链表(List) .改变par的参数,就改变了plot的参数。
par的权限机制
par中那么多参数,并不是每一个都可以被设定,也不是每一个都可以被任何函数所调用的。这正如一个人的家里,不是每个人可以随便进入或做出改变。权限机制有什么好处呢?可以想象一下,如果没有权限机制,那么每一个做图的函数都要自己定义一套参数,或者大家所有的都要用公共的参数,这带来的不是浪费就是滥用,因此,par意识到有必要设定权限机制。
一些readonly的参数,用R.O.标识:
"cin",
"cra",
"csi",
"cxy",
"din"
"page"
仅仅可以通过par设置的参数:
"ask",
"fig", "fin",
"lheight",
"mai", "mar", "mex", "mfcol", "mfrow", "mfg",
"new",
"oma", "omd", "omi",
"pin", "plt", "ps", "pty",
"usr",
"xlog", "ylog",
"ylbias"
可以被其他函数调用的参数:剩余其他。
总结
鉴于篇幅长度,par的使用下一节再介绍。
R语言天生就有可视化的优越条件,简单而且可配置性强。让人专注于数据处理而非代码本身,这又是R语言在数据处理上的禀赋。
[2]R语言在数据处理上的禀赋之——可视化技术的更多相关文章
- [3]R语言在数据处理上的禀赋——par参数详解(一)
本文目录 公共参数列表 par 颜色相关 字体相关 字体大小相关 线条相关 符号相关 线条和符号大小相关 结束 本文首发:program-dog.blogspot.com 注1:本文也曾在csdn发布 ...
- R语言之数据处理
R语言之数据处理 一.向量处理 1.选择和显示向量 data[1] data[3] data[1:3] data[-1]:除第一项以外的所有项 data[c(1,3,4,6)] data[data&g ...
- 利用R语言制作出漂亮的交互数据可视化
利用R语言制作出漂亮的交互数据可视化 利用R语言也可以制作出漂亮的交互数据可视化,下面和大家分享一些常用的交互可视化的R包. rCharts包 说起R语言的交互包,第一个想到的应该就是rCharts包 ...
- R语言之数据处理常用包
dplyr包是Hadley Wickham的新作,主要用于数据清洗和整理,该包专注dataframe数据格式,从而大幅提高了数据处理速度,并且提供了与其它数据库的接口:tidyr包的作者是Hadley ...
- R语言︱噪声数据处理、数据分组——分箱法(离散化、等级化)
每每以为攀得众山小,可.每每又切实来到起点,大牛们,缓缓脚步来俺笔记葩分享一下吧,please~ --------------------------- 分箱法在实际案例操作过程中较为常见,能够将一些 ...
- R语言操作mysql上亿数据量(ff包ffbase包和ETLUtils包)
平时都是几百万的数据量,这段时间公司中了个大标,有上亿的数据量. 现在情况是数据已经在数据库里面了,需要用R分析,但是完全加载不进来内存. 面对现在这种情况,R提供了ff, ffbase , ETLU ...
- R语言在柱状图上添加文字
代码示例: data <- data.frame(A = 1:2, B = 1:2, C = 1:2) data <- data.matrix(data) par(font = 2, lw ...
- R语言:用简单的文本处理方法优化我们的读书体验
博客总目录:http://www.cnblogs.com/weibaar/p/4507801.html 前言 延续之前的用R语言读琅琊榜小说,继续讲一下利用R语言做一些简单的文本处理.分词的事情.其实 ...
- 数据攻略●R语言自述
(注明:以下文章均在Linux操作系统下执行) 一.R语言简介 R语言是用于统计分析,图形表示和报告的编程语言和软件环境.R语言由Ross Ihaka和Robert Gentleman在新西兰奥克兰大 ...
随机推荐
- Rnadom Teams
Rnadom Teams 题目链接:http://acm.hust.edu.cn/vjudge/contest/view.actioncid=88890#problem/B 题目: Descript ...
- Eclipse中添加PyDev插件
思路 1.启动Eclipse, 2.点击Help->Install New Software... 3.在弹出的对话框中,点Add 按钮. 4.Name中填:Pydev, Location中填h ...
- Listener监听器使用小案例
这里介绍的就是一个客户流失监听器案例 新建一个监听器实现ServletContextListener接口 覆写contextDestroyed和contextInitialized 方法 packag ...
- 全选,不选,反选js
<!doctype html> <html> <head> <meta charset="utf-8"> <meta name ...
- ArcEngine:空间索引格网大小无效
参考如下帖子:http://www.cnblogs.com/linhugh/archive/2012/07/24/2606439.html\ C# 代码如下 IFeatureClass pNewFtC ...
- JSP中乱码问题
一.JSP页面显示乱码 二.表单提交中文时出现乱码 三.数据库连接 大家在JSP的开发过程中,经常出现中文乱码的问题,可能一至困扰着您,我现在把我在JSP开发中遇到的中文乱码的问题及解决办法写出来供大 ...
- 满足要求的最长上升子序列(nlogn)
题意:数列A1,A2,...,AN,修改最少的数字,使得数列严格单调递增.(1<=N<=10^5; 1<=Ai<=10^9 ) 思路:首先要明白的一点是数列是严格单调递增,那么 ...
- iframe父子页面之间相互调用元素和函数
<!doctype html> <html> <head> <meta http-equiv="Content-Type" content ...
- js console 一些拓展技巧
console.time 方法 / console.timeEnd() 方法 统计一段代码的执行时间, 形参必须一致 console.time("string"); for(var ...
- Centos7 安装codeblock( 转载)
1.安装gcc,需要c和c++两部分,默认安装下,CentOS不安装编译器的,在终端输入以下命令即可 yum install gcc yum install gcc-c++ 2.安装gtk2-deve ...