Storm集成Kafka应用的开发
我们知道storm的作用主要是进行流式计算,对于源源不断的均匀数据流流入处理是非常有效的,而现实生活中大部分场景并不是均匀的数据流,而是时而多时而少的数据流入,这种情况下显然用批量处理是不合适的,如果使用storm做实时计算的话可能因为数据拥堵而导致服务器挂掉,应对这种情况,使用kafka作为消息队列是非常合适的选择,kafka可以将不均匀的数据转换成均匀的消息流,从而和storm比较完善的结合,这样才可以实现稳定的流式计算,那么我们接下来开发一个简单的案例来实现storm和kafka的结合
storm和kafka结合,实质上无非是之前我们说过的计算模式结合起来,就是数据先进入kafka生产者,然后storm作为消费者进行消费,最后将消费后的数据输出或者保存到文件、数据库、分布式存储等等,具体框图如下:
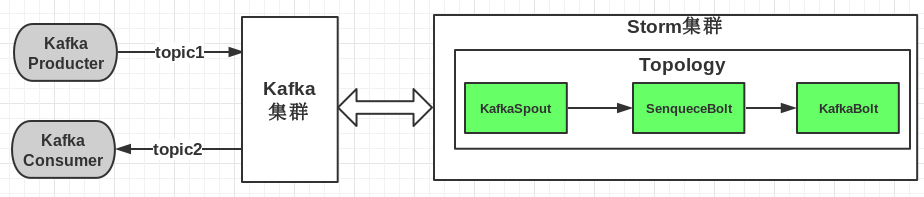
这张图片摘自博客地址:http://www.cnblogs.com/tovin/p/3974417.html 在此感谢作者的奉献
首先我们保证在服务器上zookeeper、kafka、storm正常运行,然后我们开始写程序,这里使用eclipse for javaee IDE
和之前一样,建立一个maven项目,在pom.xml写入如下代码:
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion> <groupId>kafkastorm</groupId>
<artifactId>kafkastorm</artifactId>
<version>0.0.1-SNAPSHOT</version>
<packaging>jar</packaging> <name>kafkastorm</name>
<url>http://maven.apache.org</url> <properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties> <dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>3.8.1</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.apache.storm</groupId>
<artifactId>storm-core</artifactId>
<version>0.9.6</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka_2.9.2</artifactId>
<version>0.8.2.2</version>
<exclusions>
<exclusion>
<groupId>org.apache.zookeeper</groupId>
<artifactId>zookeeper</artifactId>
</exclusion>
<exclusion>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.apache.storm</groupId>
<artifactId>storm-kafka</artifactId>
<version>0.9.6</version>
</dependency>
</dependencies> <build>
<plugins>
<plugin>
<artifactId>maven-assembly-plugin</artifactId>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>
主要是导入的zookeeper、storm、kafka外部依赖这些叠加起来,还有<plugin>插件便于我们后续对程序进程maven的打包
和之前一样首先编写storm消费kafka的逻辑,MessageScheme类,代码如下:
package net.zengzhiying; import java.io.UnsupportedEncodingException;
import java.util.List; import backtype.storm.spout.Scheme;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Values; public class MessageScheme implements Scheme { public List<Object> deserialize(byte[] arg0) {
try {
String msg = new String(arg0, "UTF-8");
return new Values(msg);
} catch (UnsupportedEncodingException e) {
e.printStackTrace();
}
return null;
} public Fields getOutputFields() {
return new Fields("msg");
} }
逻辑很简单,就是对kafka出来的数据转换成字符串,接下来我们想办法来处理strom清洗之后的数据,我们为了简单就把输出保存到一个文件中,Bolt逻辑SenqueceBolt类的代码如下:
package net.zengzhiying; import java.io.DataOutputStream;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException; import backtype.storm.topology.BasicOutputCollector;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.topology.base.BaseBasicBolt;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Tuple;
import backtype.storm.tuple.Values; public class SenqueceBolt extends BaseBasicBolt { public void execute(Tuple arg0, BasicOutputCollector arg1) {
String word = (String) arg0.getValue(0);
String out = "output:" + word;
System.out.println(out); //写文件
try {
DataOutputStream out_file = new DataOutputStream(new FileOutputStream("kafkastorm.out"));
out_file.writeUTF(out);
out_file.close();
} catch (FileNotFoundException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} arg1.emit(new Values(out));
} public void declareOutputFields(OutputFieldsDeclarer arg0) {
arg0.declare(new Fields("message"));
} }
就是把输出的消息放到文件kafkastorm.out中
然后我们编写主类,也就是配置kafka提交topology到storm的代码,类名为StormKafkaTopo,代码如下:
package net.zengzhiying; import java.util.HashMap;
import java.util.Map; import backtype.storm.Config;
import backtype.storm.LocalCluster;
import backtype.storm.StormSubmitter;
import backtype.storm.generated.AlreadyAliveException;
import backtype.storm.generated.InvalidTopologyException;
import backtype.storm.spout.SchemeAsMultiScheme;
import backtype.storm.topology.TopologyBuilder;
import backtype.storm.utils.Utils;
import storm.kafka.BrokerHosts;
import storm.kafka.KafkaSpout;
import storm.kafka.SpoutConfig;
import storm.kafka.ZkHosts;
import storm.kafka.bolt.KafkaBolt; public class StormKafkaTopo {
public static void main(String[] args) {
BrokerHosts brokerHosts = new ZkHosts("192.168.1.216:2181/kafka"); SpoutConfig spoutConfig = new SpoutConfig(brokerHosts, "topic1", "/kafka", "kafkaspout"); Config conf = new Config();
Map<String, String> map = new HashMap<String, String>(); map.put("metadata.broker.list", "192.168.1.216:9092");
map.put("serializer.class", "kafka.serializer.StringEncoder");
conf.put("kafka.broker.properties", map);
conf.put("topic", "topic2"); spoutConfig.scheme = new SchemeAsMultiScheme(new MessageScheme()); TopologyBuilder builder = new TopologyBuilder();
builder.setSpout("spout", new KafkaSpout(spoutConfig));
builder.setBolt("bolt", new SenqueceBolt()).shuffleGrouping("spout");
builder.setBolt("kafkabolt", new KafkaBolt<String, Integer>()).shuffleGrouping("bolt"); if(args != null && args.length > 0) {
//提交到集群运行
try {
StormSubmitter.submitTopology(args[0], conf, builder.createTopology());
} catch (AlreadyAliveException e) {
e.printStackTrace();
} catch (InvalidTopologyException e) {
e.printStackTrace();
}
} else {
//本地模式运行
LocalCluster cluster = new LocalCluster();
cluster.submitTopology("Topotest1121", conf, builder.createTopology());
Utils.sleep(1000000);
cluster.killTopology("Topotest1121");
cluster.shutdown();
} }
}
注意上面代码的配置,和之前单独运行storm和kafka代码不太一样,配置也很简单,注意区别即可,如果细心的话会注意到这里建了两个topic一个是topic1,一个是topic2,topic1的含义kafka接收生产者过来的数据所需要的topic,topic2是KafkaBolt也就是storm中的bolt生成的topic,当然这里topic2这行配置可以省略,是没有任何问题的,类似于一个中转的东西,另外我们这次测试是上传到服务器执行,本地模式的代码没有执行到,当然原理是一样的
之前一般网上的教程到这里就完毕了,这样我们会引起一种没有生产者的误区,注意:上面3个类实现的功能是kafka消费者输出的数据被storm消费!生产者的代码可以看成独立的其他来源,可以写在其他项目中,根据数据源的情况来,下面我们为了示例,编写一个类来进行生产,代码和之前kafka单独的一样:
package net.zengzhiying; import java.util.ArrayList;
import java.util.List;
import java.util.Properties; import kafka.javaapi.producer.Producer;
import kafka.producer.KeyedMessage;
import kafka.producer.ProducerConfig; public class DataProducerInsert {
private static Producer<Integer,String> producer;
private final Properties props=new Properties();
public DataProducerInsert(){
//定义连接的broker list
props.put("metadata.broker.list", "192.168.1.216:9092");
//定义序列化类 Java中对象传输之前要序列化
props.put("serializer.class", "kafka.serializer.StringEncoder");
//props.put("advertised.host.name", "192.168.1.216");
producer = new Producer<Integer, String>(new ProducerConfig(props));
}
public static void main(String[] args) {
DataProducerInsert sp=new DataProducerInsert();
//定义topic
String topic="topic1";
//开始时间统计
long startTime = System.currentTimeMillis();
//定义要发送给topic的消息
String messageStr = "This is a message";
List<KeyedMessage<Integer, String>> datalist = new ArrayList<KeyedMessage<Integer, String>>(); //构建消息对象
KeyedMessage<Integer, String> data = new KeyedMessage<Integer, String>(topic, messageStr);
datalist.add(data); //结束时间统计
long endTime = System.currentTimeMillis();
KeyedMessage<Integer, String> data1 = new KeyedMessage<Integer, String>(topic, "用时" + (endTime-startTime)/1000.0);
datalist.add(data1); //推送消息到broker
producer.send(data);
producer.close();
}
}
注意,这里我们定义的topic是topic1,正好和前面的topic1数据源对应,是整个kafka保持一致的topic,也就是说kafka生产者topic和消费者topic是必须名称相同才可以响应,下面简单添加了一点时间统计的代码,也很简单
另外还要注意kafka配置文件host.name尽量改成ip,和之前说过的一样
到现在项目就编写完成了,然后我们使用maven命令对项目打包,首先得保证我们windows上安装好了maven,我们运行cmd,进入到当前项目目录下,执行命令: mvn assembly:assembly 进行打包,打包的前提就是之前pom.xml的所有配置,执行后maven会自动下载相应的依赖并完成打包,需要耐心等待一会:
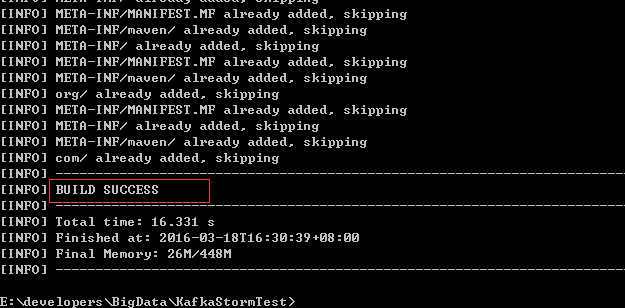
看到如图所示的BUILD SUCCESS返回之后,那么打包就成功了,现在进入项目目录下的target目录中,会看到2个jar包
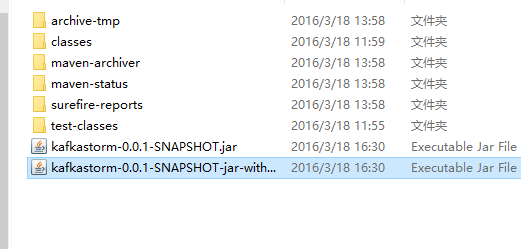
其中后面那个文件名较长的大小也比较大,是包含相关依赖的包,接下来我们将这个包上传到服务器,然后使用storm执行jar包将我们的topology上传到集群中运行,注意是使用storm执行jar包,而不是java
/usr/storm/apache-storm-0.9./bin/storm jar kafkastorm-0.0.-SNAPSHOT-jar-with-dependencies.jar net.zengzhiying.StormKafkaTopo kafkagostorm
前面是storm的绝对路径,参数jar执行jar包,后面跟的是上传topology的主类,最后kafkagostorm是我们上传拓扑的名称
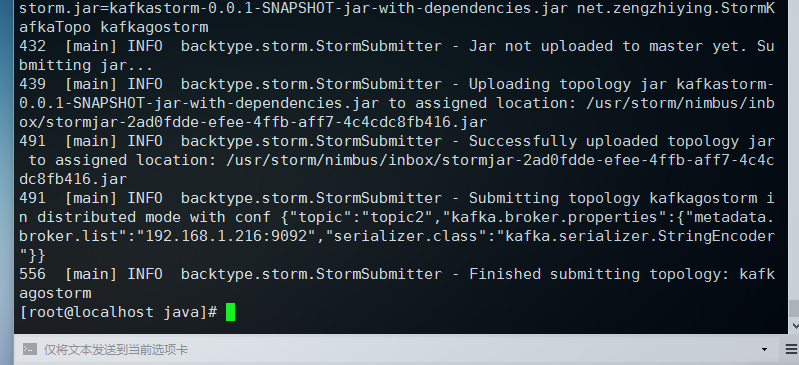
这里执行完之后会回到命令行,现在就在后台集群中开始分发运行了,这就是集群模式,之前我们讲的storm案例会不断滚动大量数据,那个属于本地模式,如果我们现在开启ui界面的话,那么访问我们的地址http://192.168.1.216:8080/可以看到正在运行的Topology
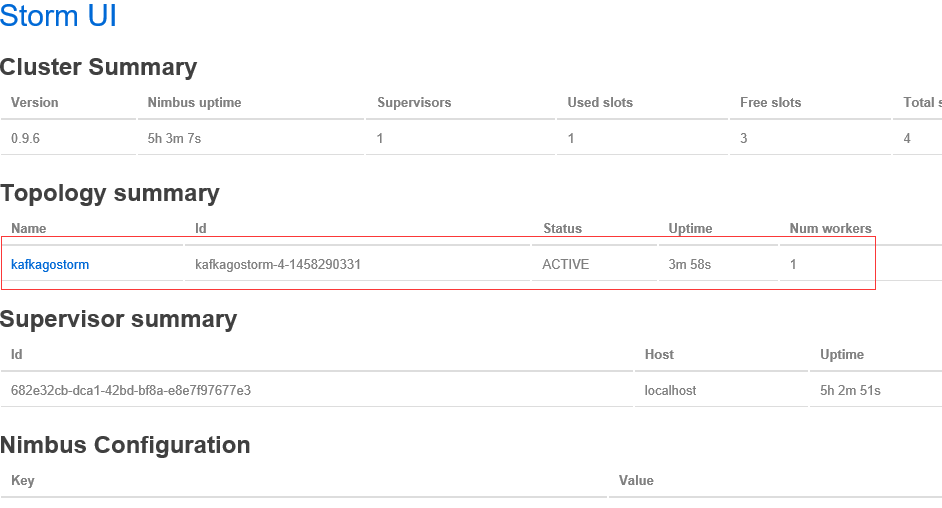
可以看到状态是active正在运行了,我们上面代码中kafkabolt创建了一个topic2的消息,我们现在可以测试一下,消费者这里只是简单地原样输出,我们进入kafka目录,执行下面命令:
bin/kafka-console-consumer.sh --zookeeper localhost:/kafka --topic topic2 --from-beginning
后面参数--from-beginning不添加也是可以的,添加包括旧信息,不添加就是新的输出
现在界面卡住,待会我们来观察输出,现在我们新开一个窗口,还是使用storm执行刚才的生产者类DataProducerInsert来生产一条消息,命令如下:
/usr/storm/apache-storm-0.9./bin/storm jar kafkastorm-0.0.-SNAPSHOT-jar-with-dependencies.jar net.zengzhiying.DataProducerInsert
回车之后,等待界面滚动2s程序跑完之后,我们看到另一个窗口输出了消息:
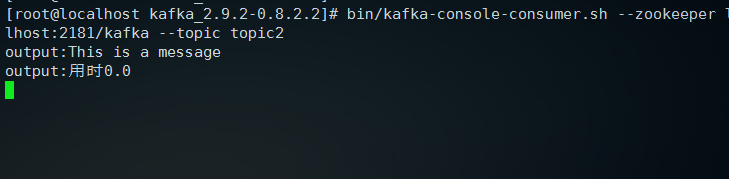
然后,我们的输出文件在哪呢,刚才我们使用storm执行的生产者代码,所以输出的kafkastorm.out就在storm的安装目录下,我们使用cat或者vim都可以看到文件内容,如果有时间统计的话两行内容显示可能会有点问题,因为后续要进行简单的转换,去掉时间统计代码只输出消息的内容如下,这里使用vim打开的:
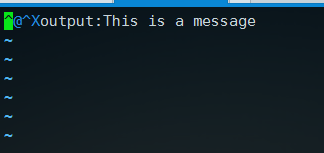
另外注意,上传拓扑时所有的代码都加载到集群了,所以修改代码版本时,一定要先在storm目录下执行 bin/storm kill topo_name 结束拓扑,修改代码后重新上传即可再次运行,否则可能会出现错误,在集群上的时候kafka配置文件的host.name注释即可,默认为localhost,最后代码中用到的参数比较多,很容易出错,所以写代码时还是要仔细点
这样storm集成kafka的测试案例就完成了,并且实现了一定的功能,只要我们灵活掌握了怎么写kafka和storm结合的整体拓扑结构,那么主要的代码就集中在数据源也就是kafka生产者的发送和storm消费后的存储问题,这所有的代码都是在storm和kafka给好的方法内写逻辑,而不用关心底层,这样使开发更加简单快捷,比如我们消费后的数据既可以写到文件、数据库还可以索引到solr,存到Hbase等,这样就可以灵活运用了;其实最关键的还是要了解这些框架底层的实现原理,这样遇到问题才可以知其然知其所以然
Storm集成Kafka应用的开发的更多相关文章
- storm集成kafka的应用,从kafka读取,写入kafka
storm集成kafka的应用,从kafka读取,写入kafka by 小闪电 0前言 storm的主要作用是进行流式的实时计算,对于一直产生的数据流处理是非常迅速的,然而大部分数据并不是均匀的数据流 ...
- storm集成kafka
kafkautil: import java.util.Properties; import kafka.javaapi.producer.Producer; import kafka.produce ...
- Storm集成Kafka的Trident实现
原本打算将storm直接与flume直连,发现相应组件支持比较弱,topology任务对应的supervisor也不一定在哪个节点上,只能采用统一的分布式消息服务Kafka. 原本打算将结构设 ...
- Storm 学习之路(九)—— Storm集成Kafka
一.整合说明 Storm官方对Kafka的整合分为两个版本,官方说明文档分别如下: Storm Kafka Integration : 主要是针对0.8.x版本的Kafka提供整合支持: Storm ...
- Storm 系列(九)—— Storm 集成 Kafka
一.整合说明 Storm 官方对 Kafka 的整合分为两个版本,官方说明文档分别如下: Storm Kafka Integration : 主要是针对 0.8.x 版本的 Kafka 提供整合支持: ...
- 5、Storm集成Kafka
1.pom文件依赖 <!--storm相关jar --> <dependency> <groupId>org.apache.storm</groupId> ...
- Storm集成Kafka编程模型
原创文章,转载请注明: 转载自http://www.cnblogs.com/tovin/p/3974417.html 本文主要介绍如何在Storm编程实现与Kafka的集成 一.实现模型 数据流程: ...
- Storm应用系列之——集成Kafka
本文系原创系列,转载请注明. 原帖地址:http://blog.csdn.net/xeseo 前言 在前面Storm系列之——基本概念一文中,提到过Storm的Spout应该是源源不断的取数据,不能间 ...
- spark streaming集成kafka
Kakfa起初是由LinkedIn公司开发的一个分布式的消息系统,后成为Apache的一部分,它使用Scala编写,以可水平扩展和高吞吐率而被广泛使用.目前越来越多的开源分布式处理系统如Clouder ...
随机推荐
- unslider的用法详解
unslider本身下载后只需要dist文件夹就好了, 其中只包含dist/js/unslider-min.js, jquery的js要自己提供; dist/css/unslider.css是主要的c ...
- 安装使用ubuntu和opensuse
liquid: n.液体, adj. 液体的, 流动的 liquidate: v. 清洗; 清算; 变现; 杀戮; weird: [wi2d] e:i, ir:2 离奇的,古怪的... 英文名称, 直 ...
- hdu4941 Magical Forest (stl map)
2014多校7最水的题 Magical Forest Magical Forest Time Limit: 24000/12000 MS (Java/Others) Memory Limit ...
- oracle 中的trunc()函数及加一个月,一天,一小时,一分钟,一秒钟方法
返回处理后的数据,不同于round()(对数值进行四舍五入处理),该函数不对指定小数前或后的数值部分进行舍入处理. 语法:trunc(number[,decimals]) 其中,number为待做处理 ...
- [译]angularjs directive design made easy
原文: http://seanhess.github.io/2013/10/14/angularjs-directive-design.html AngularJS directives很酷 Angu ...
- JDBC、JDBCTemplate、MyBatis、Hiberante 比较与分析
JDBC (Java Data Base Connection,java数据库连接) JDBC(Java Data Base Connection,java数据库连接)是一种用于执行SQL语句的Jav ...
- Excel 使用CHIINV函数和GAMMA.DIST函数绘制卡方分布
1.使用CHIINV(概率,自由度),在Excel中绘制卡方分布. 若n个独立的随机变量均服从标准正态分布,则这n个随机变量的平方和构成一新的随机变量,其分布规律称为服从自由度为ν 的χ2分布. 2. ...
- Logistic 回归(sigmoid函数,手机的评价,梯度上升,批处理梯度,随机梯度,从疝气病症预测病马的死亡率
(手机的颜色,大小,用户体验来加权统计总体的值)极大似然估计MLE 1.Logistic回归 Logistic regression (逻辑回归),是一种分类方法,用于二分类问题(即输出只有两种).如 ...
- Android 实现简单音乐播放器(一)
今天掐指一算,学习Android长达近两个月了,今天开始,对过去一段时间的学习收获以及遇到的疑难杂症做一些总结. 简单音乐播放器是我自己完成的第一个功能较为完整的APP,可以说是我的Android学习 ...
- JAVA 如何使JScrollPane中的JTextArea自动滚动到最后一行?
1.要使JTextArea带有滚动条,需将JTextArea对象添加到JScrollPane中. JTextArea logArea = new JTextArea(15, 35); //创建JTex ...