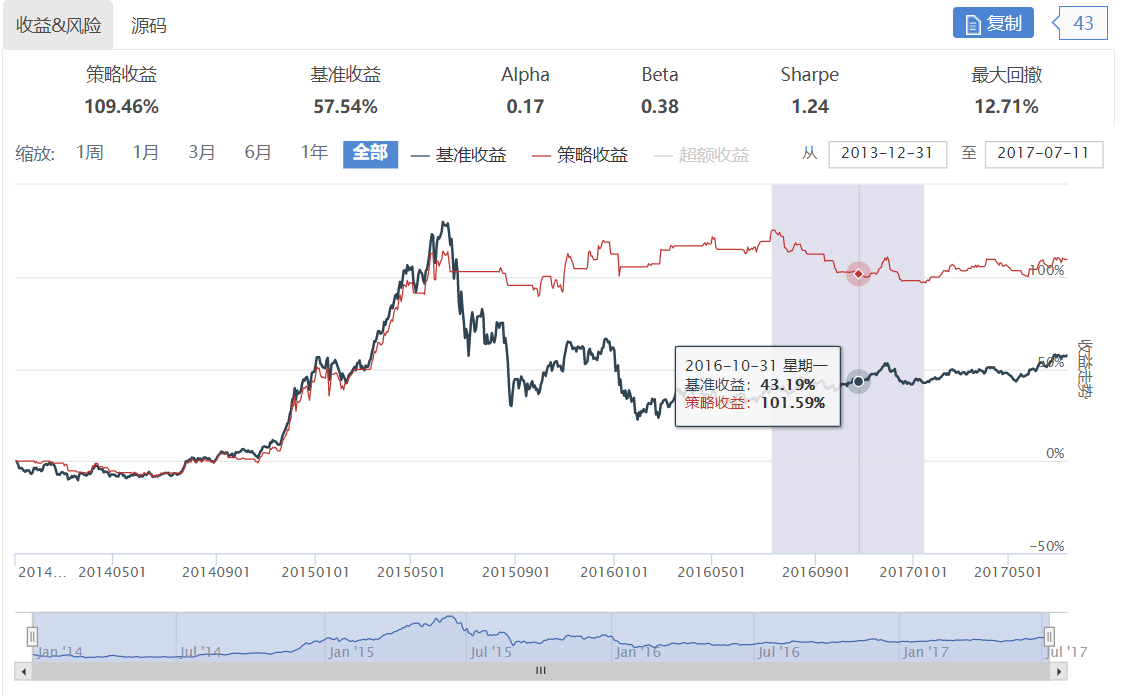
基于KMeans的指数择时策略
【导语】:聚类分析是指将物理或者抽象对象的结合分组为由类似对象组成的多个类的分析过程。简单来讲,聚类就是通过一些特征去自动识别一个大群体中的多个子群体,这些子群体中的对象彼此之间相似度高,而子群体之间差异较大。聚类的概念其实是Machine Learning中的一个子分支,在很多情况下,我们无法直接获得足够的带标签(分类)的数据样本来训练我们的模型,在这种情况下,聚类分析就显得尤为重要。它能够在给定的无标签样本中根据其特征给每个样本分类。
【策略思想】
这里有必要简单介绍一下KMeans。KMeans是聚类分析中的一种算法。它的算法过程大致是这样的:
有一天,你想要给5只西瓜分类,你已经测量好了这些西瓜的质量、半径、颜色深度等一系列特征,你是一个挑西瓜的小白,并不懂得好瓜应该长成什么样。这个时候,你想通过Kmeans聚类算法来对这些瓜分类。
1.你的目标是区分好瓜和坏瓜,所以你给定了想要聚类的数量为2。
2.你随机挑选了2只瓜作为好瓜和坏瓜的起点,当然了,其实你并不知道它们是不是真的是好瓜和坏瓜,有可能给的定义完全是相反的。(那么我们暂定1号瓜作为好瓜,2号瓜作为坏瓜)
3.这个时候你顺理成章的想,既然现在假设好了好瓜和坏瓜,那么现在第3只瓜的各个特征跟哪只瓜更加相似就应该划分都哪只瓜里去。所以你分别计算了每只瓜和1号瓜以及2号瓜的“距离”大小,发现3、4号瓜与1号更加相似,5号瓜与2号更加相似。于是得到了下面的结果。

4.一只瓜的分类未必是准确的,而前面你直接指定了1号和2号瓜的命运。。所以,你现在需要更新好瓜和坏瓜的标准,说专业点就叫做更新聚类中心。怎么做呢?对于第1类来说,你计算了1、3、4这几只瓜各个特征的平均值,重新生成了一个聚类中心;类似的,对于第2类来说,计算了2、5号瓜各个特征的平均值。
5.经过第4步,已经完成了一次聚类中心的更新。那么由于好瓜和坏瓜的定义被改变了(不再是1号或者2号瓜中的任何一个),所以需要重新更新每只瓜的归属,于是你重复上面第3步,重新将每只瓜根据与更新后的聚类中心的距离分类到两个类中。
6.这个时候为了保证一定的科学性,你需要多重复几次上面的过程,直到最后两个类别的聚类中心都基本不改变或者达到了指定的迭代次数。算法就停止了。
这也是K-Means算法名称的来源,K代表了给定的聚类数量,也就是上面的2,Means则代表了对于这个算法而言,它的聚类中心是通过计算样本点的均值而来的。
进入正题。。
那么思路就来了,我们可以给定一些特征来描述指数的任意一天,比如过去14天的平均波动率,过去30天的平均成交量,等等等等。然后在给定的历史数据区间上(训练集,如2005-01-01至2013-12-31)对训练样本进行训练,比如目标是为了预测某一天是涨是跌,我们可以像刚才吃瓜的例子一样,给K-Means算法参数K=2。
刚才西瓜的例子中的特征向量:
[质量, 半径, 颜色深度, ...] ………………一只瓜
现在的特征向量:
[14日ATR, MACD, 30日avg_volume, ...] ………………一个交易日
换句话说,现在的任何一个交易日就对应了一只瓜。
得到了特征向量以后,按照上面的KMeans算法步骤,就可以得到每个交易日被分到哪个类中的结果了。比如我们以5个交易日举例。

要注意,到现在为止,我们还不知道类1和类2的具体含义是什么。所以我们需要在数据集上进行验证。这里我们也给出这5个交易日的涨跌情况。于是,我们可以计算出这两个类别在训练集上的累积收益情况:
类1:0.9994×0.9967 = 0.9961 (-0.39%)
类2:1.0047×1.0077×1.0044 = 1.0169 ( 1.69%)
我们发现,在这里,我们的模型表现非常棒,明确的将所有上涨和下跌的交易日分到了两类里,类1和类2的意义也相当明确,1代表弱势,2代表涨势。
所以,我们可以使用这个模型进行择时判断,如果预测后一天是涨势,那么就在第二天开盘开仓,如果预测后一天为弱势,那么就在第二天开盘卖出清仓。
【注意点】
1.标准化。KMeans是基于欧式距离计算样本点之间的距离,所以务必在训练模型之前进行特征的标准化,否则会在计算距离时严重偏向值较大的属性特征,相当于自带了不同的权重。使用Min-Max或者Z-score标准化都可。
2.特征的挑选和个数。由于KMeans的迭代过程都利用了样本点之间的距离,距离的计算又都是由特征而来的,所以选取好的特征以及合适数量的特征数是重要的。
3.给定的参数K。当K的数值很小,比如取2时,很容易得到每个类的收益情况都不佳的结果,因此,适当的增加聚类数可以提高拟合效果,但是当K值过大,也容易造成过拟合,相当于每个类的交易日个数会变得相当少,丧失了模型的通用性。
4.特别要注意在对所得到的聚类进行解释的时候,要根据后一天的收益率去评判,也就是这里必须有一个滞后期,否则得到的评判结果对于后续的择时是毫无意义的。

'''
机器学习系列策略
K-Means聚类择时
根据K-Means在历史一段时间的聚类结果,对当天的属性进行分类
并根据分类结果所属的类别判断买入/卖出
'''
from sklearn.externals import joblib
from features import gen_attrs #初始化账户
def initialize(account):
account.security = '000300.SH' def handle_data(account,data):
time = get_last_datetime().strftime("%Y%m%d")
log.info(time)
#获取证券过去20日的收盘价数据
history = get_price(account.security,'',time,'1d',\
['open','close','low','high','avg_price','prev_close','volume'],False,'pre')
# history = data.attribute_history(account.security, ['open','close','low','high','avg_price','prev_close','volume'], 34, '1d')
log.info(history)
# 计算当天属性值
attrs, logreturn = gen_attrs(history, 33)
# state = 1
model = joblib.load('kmeans/kmeans.m')
min_max_scaler = joblib.load('kmeans/std.m')
attrs = min_max_scaler.transform(attrs)
state = model.predict(attrs)[-1]
if state in [0,1,7]:
# if state in [1, 5, 10] and g.is_pos == 0:
# order_value('510300.OF',account.cash)
order_value('159919.OF',account.cash)
# order_value('510050.OF',account.cash)
log.info("买入 %s" % (account.security))
# g.is_pos = 1
elif state not in [0,1,7]:
# elif state not in [1, 5, 10] and g.is_pos == 1:
# order_target('510300.OF',0)
order_target('159919.OF',0)
# order_target('510050.OF',0)
log.info("卖出 %s" % (account.security))
# g.is_pos = 0
from sklearn.externals import joblib
from sklearn.cluster import KMeans
from sklearn.preprocessing import MinMaxScaler
import numpy as np
import talib
from scipy.stats import boxcox
import features # history_price = get_price('000300.SH', 'None', '2013-12-31', '1d',['open','close','low','high','avg_price','prev_close','volume'], False, None, 2500,is_panel=1)
history_price = get_price('000300.SH', '2005-01-04', '2013-12-31', '1d',['open','close','low','high','avg_price','prev_close','volume'], False, None)
close = history_price.loc[:, 'close']
prev_close = history_price.loc[:, 'prev_close']
high = history_price.loc[:, 'high']
low = history_price.loc[:, 'low']
train_X, train_logreturn = features.gen_attrs(history_price, 33)
min_max_scaler = MinMaxScaler()
train_X = min_max_scaler.fit_transform(train_X)
joblib.dump(min_max_scaler, 'std.m')
kmeans = KMeans(n_clusters=8, random_state=0, n_init=50, max_iter=1000).fit(train_X)
joblib.dump(kmeans, 'kmeans.m')
['kmeans.m']
基于KMeans的指数择时策略的更多相关文章
- 【转】在Spring中基于JDBC进行数据访问时怎么控制超时
http://www.myexception.cn/database/1651797.html 在Spring中基于JDBC进行数据访问时如何控制超时 超时分类 超时根据作用域可做如下层级划分: Tr ...
- 基于ElementUI,设置流体高度时,固定列与底部有间隙
基于ElementUI,设置流体高度时,固定列与底部有间隙问题,如下图: 解决办法: 1.fixed流体的高度设置为100% 2.将fixed的滚动内容的最大高度设置为none,bottom为 ...
- 基于K-means Clustering聚类算法对电商商户进行级别划分(含Octave仿真)
在从事电商做频道运营时,每到关键时间节点,大促前,季度末等等,我们要做的一件事情就是品牌池打分,更新所有店铺的等级.例如,所以的商户分入SKA,KA,普通店铺,新店铺这4个级别,对于不同级别的商户,会 ...
- 基于 普通及Lambda方式实现策略模式
什么是策略模式 策略模式代表了解决一类算法的通用解决方案,你可以在运行时选择使用哪种方案.比如如何使用不同的条件(比如苹果的重量,或者颜色 )来筛选库存中的苹果.你可以将这一模式应用到更广泛的领域 , ...
- 【OpenCV】基于kmeans的细胞检测方法
问题是这样的,有一幅经过二值化处理之后的图像,我们希望统计其中细胞的个数,和不同粘连情况的细胞个数,比如,下图中有1个细胞组成连通区域的,也有2个细胞组成连通区域的,也有更多个细胞组成连通区域的,我们 ...
- 基于Flink秒级计算时CPU监控图表数据中断问题
基于Flink进行秒级计算时,发现监控图表中CPU有数据中断现象,通过一段时间的跟踪定位,该问题目前已得到有效解决,以下是解决思路: 一.问题现象 以SQL02为例,发现本来10秒一 ...
- 【winform】基于UserControl实现webBrower组件时html页面元素加载及onclick事件监听实现
[背景]基于System.Windows.Forms.UserControl实现的webBrower组件在html内使用window.external调用winform事件失败. [解决思路]借助wi ...
- 基于jQuery的鼠标悬停时放大图片的效果制作
这是一个基于jQuery的效果,当鼠标在小图片上悬停时,会弹出一个大图,该大图会跟随鼠标的移动而移动.这个效果最初源于小敏同志的一个想法,刚开始做的时候只能实现弹出的图片是固定的,不能随鼠标移动,最后 ...
- 【原/转】ios指令集以及基于指令集的app包压缩策略
iPhone指令集 本文所讲的内容都是围绕iPhone的CPU指令集(想了解ARM指令集的同学请点击这里),现在先说说不同型号的iPhone都使用的是什么指令集: ARMv8/ARM64 = iP ...
随机推荐
- SQL Server之null
数据库中,一个列如果没有指定值,那么值就为null,数据库中的null表示unknown“不知道”,而不是表示没有.因此select null+1结果是null,因为“不知道”加1的结果还是“不知道” ...
- Fitnesse中TemplateLibrary的使用方法
1.新建一个SuitePage,命名为TemplateLibrary 2.然后如下图,添加作为template的TestPage,如下面的Get 3.在Get page中添加template内容,如下 ...
- 3 手写Java HashMap核心源码
手写Java HashMap核心源码 上一章手写LinkedList核心源码,本章我们来手写Java HashMap的核心源码. 我们来先了解一下HashMap的原理.HashMap 字面意思 has ...
- 怎样让自定义Cell的图片和文本自适应高度
Let's do it! 首先创建一个Model类 包括一个图片名称属性 还有文字内容属性 #import <Foundation/Foundation.h> @interface Mod ...
- layui常用功能
包含的主要样式: 验证不通过时的弹窗 弹窗修改信息 询问框(是否删除之类的) 操作成功提示.操作失败提示 加载样式(显示加载层) 文件下载请前往github over!over!over!
- lightoj 1125【背包·从n个选m个】
题意: 给你 n 个背包,然后给你两个数,D,M,问你从n个里面挑M个出来,有多少种方法能够整除D: 思路: 试想我先不挑M个出来的话,仅仅是构造一个D的倍数,其实就是构造一个数的话, 其实就是个递推 ...
- [HNOI2010] 物品调度 fsk
标签:链表+数论知识. 题解: 对于这道题,其实就是两个问题的拼凑,我们分开来看. 首先要求xi与yi.这个可以发现,x每增加1,则pos增加d:y每增加1,则pos增加1.然后,我们把x与y分别写在 ...
- 返回零长度的数组或集合,而不是null
返回零长度的数组或集合,而不是null 像下面的方法并不少见: private final List<Cheese> cheesesInStock = ...; /** * @retu ...
- idea svn 问题
https://blog.csdn.net/liyantianmin/article/details/52837506
- 搭建Keepalived + Nginx + Tomcat的高可用负载均衡架构
1 概述 初期的互联网企业由于业务量较小,所以一般单机部署,实现单点访问即可满足业务的需求,这也是最简单的部署方式,但是随着业务的不断扩大,系统的访问量逐渐的上升,单机部署的模式已无法承载现有的业务量 ...