rule-based optimizer cost-based optimizer
SQL processing uses the following main components to execute a SQL query:
- The Parser checks both syntax and semantic analysis.
- The Optimizer uses costing methods, cost-based optimizer (CBO), or internal rules, rule-based optimizer (RBO), to determine the most efficient way of producing the result of the query.
- The Row Source Generator receives the optimal plan from the optimizer and outputs the execution plan for the SQL statement.
- The SQL Execution Engine operates on the execution plan associated with a SQL statement and then produces the results of the query.
Overview of the Optimizer
The optimizer determines the most efficient way to execute a SQL statement after considering many factors related to the objects referenced and the conditions specified in the query. This determination is an important step in the processing of any SQL statement and can greatly affect execution time.
A SQL statement can be executed in many different ways, including the following:
- Full table scans
- Index scans
- Nested loops
- Hash joins
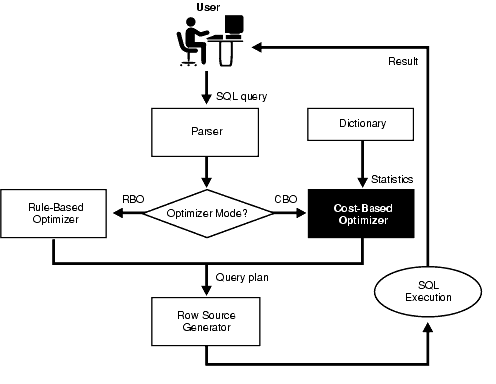
This figure shows a user entering a SQL query, which goes to the parser. The parser passes the statement to the optimizer, which can either use a rule-based approach (RBO) or a cost-based approach (CBO).
If the CBO is used, it retrieves statistics from the data dictionary. The query plan generated by the optimizer is sent to the row source generator, then the SQL execution is performed, and the query result is returned to the user.
https://docs.oracle.com/cd/B10501_01/server.920/a96533/img_text/pfgrf185.htm
https://docs.oracle.com/cd/B10501_01/server.920/a96533/optimops.htm#721
Overview of the Rule-Based Optimizer (RBO)
【推荐使用基于代价的优化器】
Although Oracle supports the rule-based optimizer, you should design new applications to use the cost-based optimizer (CBO). You should also use the CBO for data warehousing applications, because the CBO supports enhanced features for DSS. Many new performance features, such as partitioned tables, improved star query processing, and materialized views, are only available with the CBO.
Using the RBO, the optimizer chooses an execution plan based on the access paths available and the ranks of these access paths. Oracle's ranking of the access paths is heuristic. If there is more than one way to execute a SQL statement, then the RBO always uses the operation with the lower rank. Usually, operations of lower rank execute faster than those associated with constructs of higher rank.
The list shows access paths and their ranking:
RBO Path 1: Single Row by Rowid
RBO Path 2: Single Row by Cluster Join
RBO Path 3: Single Row by Hash Cluster Key with Unique or Primary Key
RBO Path 4: Single Row by Unique or Primary Key
RBO Path 7: Indexed Cluster Key
RBO Path 9: Single-Column Indexes
RBO Path 10: Bounded Range Search on Indexed Columns
RBO Path 11: Unbounded Range Search on Indexed Columns
RBO Path 13: MAX or MIN of Indexed Column
RBO Path 14: ORDER BY on Indexed Column
http://www.cnblogs.com/kerrycode/p/3842215.html
Oracle数据库中的优化器又叫查询优化器(Query Optimizer)。它是SQL分析和执行的优化工具,它负责生成、制定SQL的执行计划。Oracle的优化器有两种,基于规则的优化器(RBO)与基于代价的优化器(CBO)
RBO: Rule-Based Optimization 基于规则的优化器
CBO: Cost-Based Optimization 基于代价的优化器
RBO自ORACLE 6以来被采用,一直沿用至ORACLE 9i. ORACLE 10g开始,ORACLE已经彻底丢弃了RBO,它有着一套严格的使用规则,只要你按照它去写SQL语句,无论数据表中的内容怎样,也不会影响到你的“执行计划”,也就是说RBO对数据不“敏感”;它根据ORACLE指定的优先顺序规则,对指定的表进行执行计划的选择。比如在规则中,索引的优先级大于全表扫描;RBO是根据可用的访问路径以及访问路径等级来选择执行计划,在RBO中,SQL的写法往往会影响执行计划,它要求开发人员非常了解RBO的各项细则,菜鸟写出来的SQL脚本性能可能非常差。随着RBO的被遗弃,渐渐不为人所知。也许只有老一辈的DBA对其了解得比较深入。
【看重大数据而非经验】
CBO是一种比RBO更加合理、可靠的优化器,它是从ORACLE 8中开始引入,但到ORACLE 9i 中才逐渐成熟,在ORACLE 10g中完全取代RBO, CBO是计算各种可能“执行计划”的“代价”,即COST,从中选用COST最低的执行方案,作为实际运行方案。它依赖数据库对象的统计信息,统计信息的准确与否会影响CBO做出最优的选择。如果对一次执行SQL时发现涉及对象(表、索引等)没有被分析、统计过,那么ORACLE会采用一种叫做动态采样的技术,动态的收集表和索引上的一些数据信息。
关于RBO与CBO,我有个形象的比喻:大数据时代到来以前,做生意或许凭借多年累计下来的经验(RBO)就能够很好的做出决策,跟随市场变化。但是大数据时代,如果做生意还是靠以前凭经验做决策,而不是靠大数据、数据分析、数据挖掘做决策,那么就有可能做出错误的决策。这也就是越来越多的公司对BI、数据挖掘越来越重视的缘故,像电商、游戏、电信等行业都已经大规模的应用,以前在一家游戏公司数据库部门做BI分析,挖掘潜在消费用户简直无所不及。至今映像颇深。
http://tencentdba.com
【join优化】
The following considerations apply to both the cost-based and rule-based approaches:
- The optimizer first determines whether joining two or more of the tables definitely results in a row source containing at most one row. The optimizer recognizes such situations based on
UNIQUEandPRIMARYKEYconstraints on the tables. If such a situation exists, then the optimizer places these tables first in the join order. The optimizer then optimizes the join of the remaining set of tables. - For join statements with outer join conditions, the table with the outer join operator must come after the other table in the condition in the join order. The optimizer does not consider join orders that violate this rule.
Understanding the Cost-Based Optimizer
【使用最小代价的】
The CBO determines which execution plan is most efficient by considering available access paths and by factoring in information based on statistics for the schema objects (tables or indexes) accessed by the SQL statement. The CBO also considers hints, which are optimization suggestions placed in a comment in the statement.
| See Also:
Chapter 5, "Optimizer Hints" for detailed information on hints |
The CBO performs the following steps:
- The optimizer generates a set of potential plans for the SQL statement based on available access paths and hints.
- The optimizer estimates the cost of each plan based on statistics in the data dictionary for the data distribution and storage characteristics of the tables, indexes, and partitions accessed by the statement.
The cost is an estimated value proportional to the expected resource use needed to execute the statement with a particular plan. The optimizer calculates the cost of access paths and join orders based on the estimated computer resources, which includes I/O, CPU, and memory.
Serial plans with higher costs take more time to execute than those with smaller costs. When using a parallel plan, however, resource use is not directly related to elapsed time.
- The optimizer compares the costs of the plans and chooses the one with the lowest cost.
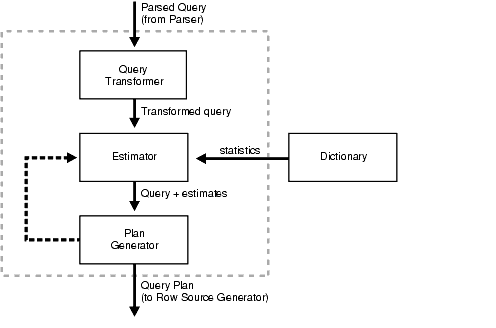
This figure depicts a parsed query (from the parser) entering the query transformer.
The transformed query is then sent to the estimator. Statistics are retrieved from the dictionary, then the query and estimates are sent to the plan generator.
The plan generator either returns the plan to the estimator or sends the query plan to the row source generator.
Query Transformer
The input to the query transformer is a parsed query, which is represented by a set of query blocks. The query blocks are nested or interrelated to each other. The form of the query determines how the query blocks are interrelated to each other. The main objective of the query transformer is to determine if it is advantageous to change the form of the query so that it enables generation of a better query plan. Four different query transformation techniques are employed by the query transformer:
Any combination of these transformations can be applied to a given query.
Estimator
The estimator generates three different types of measures:
These measures are related to each other, and one is derived from another. The end goal of the estimator is to estimate the overall cost of a given plan. If statistics are available, then the estimator uses them to compute the measures. The statistics improve the degree of accuracy of the measures.
Plan Generator
The main function of the plan generator is to try out different possible plans for a given query and pick the one that has the lowest cost. Many different plans are possible because of the various combinations of different access paths, join methods, and join orders that can be used to access and process data in different ways and produce the same result.
A join order is the order in which different join items, such as tables, are accessed and joined together. For example, in a join order of t1, t2, and t3, table t1 is accessed first. Next, t2 is accessed, and its data is joined to t1 data to produce a join of t1 and t2. Finally, t3 is accessed, and its data is joined to the result of the join between t1 and t2.
The plan for a query is established by first generating subplans for each of the nested subqueries and nonmerged views. Each nested subquery or nonmerged view is represented by a separate query block. The query blocks are optimized separately in a bottom-up order. That is, the innermost query block is optimized first, and a subplan is generated for it. The outermost query block, which represents the entire query, is optimized last.
The plan generator explores various plans for a query block by trying out different access paths, join methods, and join orders. The number of possible plans for a query block is proportional to the number of join items in the FROM clause. This number rises exponentially with the number of join items.
【启发式寻找最小代价】
The plan generator uses an internal cutoff to reduce the number of plans it tries when finding the one with the lowest cost. The cutoff is based on the cost of the current best plan. If the current best cost is large, then the plan generator tries harder (in other words, explores more alternate plans) to find a better plan with lower cost. If the current best cost is small, then the plan generator ends the search swiftly, because further cost improvement will not be significant.
The cutoff works well if the plan generator starts with an initial join order that produces a plan with cost close to optimal. Finding a good initial join order is a difficult problem. The plan generator uses a simple heuristic for the initial join order. It orders the join items by their effective cardinalities. The join item with the smallest effective cardinality goes first, and the join item with the largest effective cardinality goes last.
rule-based optimizer cost-based optimizer的更多相关文章
- register based 和 stack based虚拟机的区别
其实其核心的差异,就是Dalvik 虚拟机架构是 register-based,与 Sun JDK 的 stack-based 不同,也就是架构上的差异.我先摘录几段网上可以找到的资料,重新整理和排版 ...
- 【原创】大数据基础之Hive(5)性能调优Performance Tuning
1 compress & mr hive默认的execution engine是mr hive> set hive.execution.engine;hive.execution.eng ...
- MYSQL COST optimizer
http://blog.chinaunix.net/uid-26896862-id-3326400.html https://www.slideshare.net/olavsa/mysql-optim ...
- 47、Spark SQL核心源码深度剖析(DataFrame lazy特性、Optimizer优化策略等)
一.源码分析 1. ###入口org.apache.spark.sql/SQLContext.scala sql()方法: /** * 使用Spark执行一条SQL查询语句,将结果作为DataFram ...
- CMU Advanced DB System - Query Optimizer
Overview Optimizer模块所处在的位置如图, 那么做optimize的目的是, 找出所有‘correct’执行计划中‘cost’最低的 那么这里首先要明确的概念,‘correct’,关系 ...
- Using the FutureRequestExecutionService Based on classic (blocking) I/O handle a great number of concurrent connections is more important than performance in terms of a raw data throughput
Chapter 7. Advanced topics http://hc.apache.org/httpcomponents-client-ga/tutorial/html/advanced.html ...
- Eclipse优化工具Optimizer for Eclipse
第一次看到是Optimizer for Eclipse是在InfoQ 然后使用了一下,发现不错啊,我的好几年的破本都能比较快的启动Eclipse了 好了,废话不说了,来介绍一下Optimizer fo ...
- Physically Based Shader Development for Unity 2017 Develop Custom Lighting Systems (Claudia Doppioslash 著)
http://www.doppioslash.com/ https://github.com/Apress/physically-based-shader-dev-for-unity-2017 Par ...
- Oracle数据库基础知识
oracle数据库plsql developer 目录(?)[-] 一 SQL基础知识 创建删除数据库 创建删除修改表 添加修改删除列 oracle cascade用法 添加删除约束主键外 ...
- oracle sql 优化
2. 选择最有效率的表名顺序(只在基于规则的优化器中有效) ORACLE的解析器按照从右到左的顺序处理FROM子句中的表名,因此FROM子句中写在最后的表(基础表 driving table)将被最先 ...
随机推荐
- Promise简单实现--摘抄
Promise 看了些promise的介绍,还是感觉不够深入,这个在解决异步问题上是一个很好的解决方案,所以详细看一下,顺便按照自己的思路实现一个简单的Promise. Promise/A+规范: 首 ...
- Linux--内核Uevent事件机制 与 Input子系统【转】
转自:http://blog.csdn.net/lxl584685501/article/details/46379453 [-] 一Uevent机制 Uevent在kernel中的位置 Uevent ...
- 获取当前网络中的电脑数目及MAC-通过MAC查找IP-通过IP查询机器名
Microsoft Windows [版本 ] 版权所有 (c) Microsoft Corporation.保留所有权利. C:\Users\Administrator>netsh netsh ...
- hdu 2462(欧拉定理+高精度快速幂模)
The Luckiest number Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Othe ...
- POJ - 2135最小费用流
题目链接:http://poj.org/problem?id=2135 今天学习最小费用流.模板手敲了一遍. 产生了一个新的问题:对于一条无向边,这样修改了正向边容量后,反向边不用管吗? 后来想了想, ...
- 移动端自动化测试(一)appium环境搭建
自动化测试有主要有两个分类,接口自动化和ui自动化,ui自动化呢又分移动端的和web端的,当然还有c/s架构的,这种桌面程序应用的自动化,使用QTP,只不过现在没人做了. web自动化呢,现在基本上都 ...
- latex beamer 插入代码
有网友在beamer中使用mcode也就是 listings 输出源代码时遇到如下错误: Runaway argument?! Paragraph ended before \lst@next was ...
- 标题:如何使用ShareSDK实现Cocos2d-x的Android/iOS分享与授权
Cocos2DX 简介 Cocos2d-x是一套成熟的开源跨平台游戏开发框架.其引擎提供了图形渲染.GUI.音频.网络.物理.用户输入等丰富的功能,被广泛应用于游戏开发及交互式应用的构建.引擎的核心采 ...
- Maven设置代理
很多时候电信的网络对于出国不太稳定,针对一些库下载速度比较慢,所以在使用SSR出国时配置maven使用是一种不错的选择.当然,还有另一种选择,就是使用国内的镜像库. 操作步骤: 1.打开{M2_HOM ...
- intellij idea 提示找不到default activivty
更换环境之后 ,intellij idea 提示找不到默认的activity. 而查看源代码. 在代码中明显已经设置了默认activity了. 后来发现.程序中有个库工程中的AndroidMe ...