python网络爬虫之使用scrapy下载文件
前面介绍了ImagesPipeline用于下载图片,Scrapy还提供了FilesPipeline用与文件下载。和之前的ImagesPipeline一样,FilesPipeline使用时只需要通过item的一个特殊字段将要下载的文件或图片的url传递给它们,它们便会自动将文件或图片下载到本地。将下载结果信息存入item的另一个特殊字段,便于用户在导出文件中查阅。工作流程如下:
1 在一个爬虫里,你抓取一个项目,把其中图片的URL放入 file_urls 组内。
2 项目从爬虫内返回,进入项目管道。
3 当项目进入 FilesPipeline,file_urls 组内的URLs将被Scrapy的调度器和下载器(这意味着调度器和下载器的中间件可以复用)安排下载,当优先级更高,会在其他页面被抓取前处理。项目会在这个特定的管道阶段保持“locker”的状态,直到完成文件的下载(或者由于某些原因未完成下载)。
4 当文件下载完后,另一个字段(files)将被更新到结构中。这个组将包含一个字典列表,其中包括下载文件的信息,比如下载路径、源抓取地址(从 file_urls 组获得)和图片的校验码(checksum)。 files 列表中的文件顺序将和源 file_urls 组保持一致。如果某个图片下载失败,将会记录下错误信息,图片也不会出现在 files 组中。
下面来看下如何使用:
第一步:在配置文件settings.py中启用FilesPipeline
ITEM_PIPELINES = {
'scrapy.pipelines.files.FilesPipeline':1,
}
第二步:在配置文件settings.py中设置文件下载路径
FILE_STORE='E:\scrapy_project\file_download\file' 第三步:在item.py中定义file_url和file两个字段
class FileDownloadItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
file_urls=scrapy.Field()
files=scrapy.Field()
这三步设置后以后,下面就来看下具体的下载了,我们从matplotlib网站上下载示例代码。网址是:http://matplotlib.org/examples/index.html
接下来来查看网页结构,如下

点击animate_decay后进入下载页面。Animate_decay的网页链接都在<div class=”toctree-wrapper compound”>元素下。
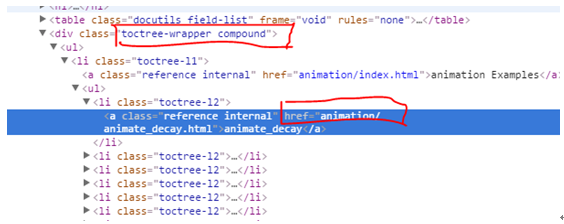
但是像animation Examples这种索引的链接我们是不需要的

通过这里我们可以首先写出我们的网页获取链接的方式:
def parse(self,response):
le=LinkExtractor(restrict_xpaths='//*[@id="matplotlib-examples"]/div',deny='/index.html$')
for link in le.extract_links(response):
yield Request(link.url,callback=self.parse_link)
restrict_xpaths设定网页链接的元素。Deny将上面的目录链接给屏蔽了。因此得到的都是具体的文件的下载链接
接下来进入下载页面,网页结构图如下:点击source_code就可以下载文件

网页结构如下

还有另外一种既包含代码链接,又包含图片链接的

从具体的文件下载链接来看有如下两种;
http://matplotlib.org/examples/pyplots/whats_new_99_mplot3d.py
http://matplotlib.org/mpl_examples/statistics/boxplot_demo.py
针对这两种方式获取对应的链接代码如下:
def parse_link(self,response):
pattern=re.compile('href=(.*\.py)')
div=response.xpath('/html/body/div[4]/div[1]/div/div')
p=div.xpath('//p')[0].extract()
link=re.findall(pattern,p)[0]
if ('/') in link: #针对包含文件,图片的下载链接方式生成:http://matplotlib.org/examples/pyplots/whats_new_99_mplot3d.py
href='http://matplotlib.org/'+link.split('/')[2]+'/'+link.split('/')[3]+'/'+link.split('/')[4]
else: #针对只包含文件的下载链接方式生成:http://matplotlib.org/mpl_examples/statistics/boxplot_demo.py
link=link.replace('"','')
scheme=urlparse(response.url).scheme
netloc=urlparse(response.url).netloc
temp=urlparse(response.url).path
path='/'+temp.split('/')[1]+'/'+temp.split('/')[2]+'/'+link
combine=(scheme,netloc,path,'','','')
href=urlunparse(combine)
# print href,os.path.splitext(href)[1]
file=FileDownloadItem()
file['file_urls']=[href]
return file
运行后出现如下的错误:提示ValueError: Missing scheme in request url: h。
2017-11-21 22:29:53 [scrapy] ERROR: Error processing {'file_urls': u'http://matplotlib.org/examples/api/agg_oo.htmlagg_oo.py'}
Traceback (most recent call last):
File "E:\python2.7.11\lib\site-packages\twisted\internet\defer.py", line 588, in _runCallbacks
current.result = callback(current.result, *args, **kw)
File "E:\python2.7.11\lib\site-packages\scrapy\pipelines\media.py", line 44, in process_item
requests = arg_to_iter(self.get_media_requests(item, info))
File "E:\python2.7.11\lib\site-packages\scrapy\pipelines\files.py", line 365, in get_media_requests
return [Request(x) for x in item.get(self.files_urls_field, [])]
File "E:\python2.7.11\lib\site-packages\scrapy\http\request\__init__.py", line 25, in __init__
self._set_url(url)
File "E:\python2.7.11\lib\site-packages\scrapy\http\request\__init__.py", line 57, in _set_url
raise ValueError('Missing scheme in request url: %s' % self._url)
ValueError: Missing scheme in request url: h
这个错误的意思是在url中丢失了scheme. 我们知道网址的一般结构是:scheme://host:port/path?。 这里的错误意思就是在scheme中没有找到http而只有一个h. 但是从log记录的来看,我们明明是生成了一个完整的网页呢。为什么会提示找不到呢。原因就在于下面的这个配置使用的是url列表形式
ITEM_PIPELINES = {
# 'file_download.pipelines.SomePipeline': 300,
'scrapy.pipelines.files.FilesPipeline':1,
}
而我们的代码对于item的赋值却是file['file_urls']=href 字符串的形式,因此如果用列表的方式来提取数据,只有h被提取出来了。因此代码需要成列表的赋值形式。修改为:file['file_urls']=[href]就可以了
程序运行成功。从保存路径来看,在download下面新建了一个full文件夹。然后下载的文件都保存在里面。但是文件名却是00f4d142b951f072.py这种形式的。这些文件名是由url的散列值的出来的。这种命名方式可以防止重名的文件相互冲突,但是这种文件名太不直观了,我们需要重新来定义下载的文件名名字

在FilesPipeline中,下载文件的函数是file_path。主体代码如下
Return的值就是文件路径。从下面看到是文件都是建立在full文件下面
media_guid = hashlib.sha1(to_bytes(url)).hexdigest()
media_ext = os.path.splitext(url)[1]
return 'full/%s%s' % (media_guid, media_ext)
media_guid得到的是url的散列值,作为文件名
media_ext得到的是文件的后缀名也就是.py
下面我们来重新写file_path函数用于生成我们自己的文件名
我们可以看到有很多网址是下面的形式,widgets是大类。后面的py文件是这个大类下的文件。我们需要将属于一个大类的文件归档到同一个文件夹下面。
http://matplotlib.org/examples/widgets/span_selector.py http://matplotlib.org/examples/widgets/rectangle_selector.py
http://matplotlib.org/examples/widgets/slider_demo.py
http://matplotlib.org/examples/widgets/radio_buttons.py
http://matplotlib.org/examples/widgets/menu.py
http://matplotlib.org/examples/widgets/multicursor.py
http://matplotlib.org/examples/widgets/lasso_selector_demo.py
比如网页为http://matplotlib.org/examples/widgets/span_selector.py
urlparse(request.url).path 得到的结果是examples/widgets/span_selector.py
dirname(path)得到的结果是examples/widgets
basename(dirname(path))得到的结果是widgets
join(basename(dirname(str)),basename(str))得到的结果是widgets\ span_selector.py
重写pipeline.py如下:
from scrapy.pipelines.files import FilesPipeline
from urlparse import urlparse
from os.path import basename,dirname,join
class FileDownloadPipeline(FilesPipeline):
def file_path(self, request, response=None, info=None):
path=urlparse(request.url).path
temp=join(basename(dirname(path)),basename(path))
return '%s/%s' % (basename(dirname(path)), basename(path))
运行程序发现生成的文件名还是散列值的。原因在于在之前的setting.py中,我们设置的是'scrapy.pipelines.files.FilesPipeline':1
这将会直接采用FilesPipeline。现在我们重写了FilesPipeline就需要更改这个设置,改为FileDownloadPipeline
ITEM_PIPELINES = {
# 'file_download.pipelines.SomePipeline': 300,
# 'scrapy.pipelines.files.FilesPipeline':1,
'file_download.pipelines.FileDownloadPipeline':1,
}
再次运行,得到如下的结果:同一类的文件都被归类到了同一个文件夹下面。

且文件名采用的是更直观的方式。这样比散列值的文件名看起来直观多了

matplotlib文件打包的下载链接如下,有需要的可以下载
https://files.cnblogs.com/files/zhanghongfeng/matplotlib.rar
scrapy工程代码如下:
https://files.cnblogs.com/files/zhanghongfeng/file_download.rar
python网络爬虫之使用scrapy下载文件的更多相关文章
- 【python 网络爬虫】之scrapy系列
网络爬虫之scripy系列 [scrapy网络爬虫]之0 爬虫与反扒 [scrapy网络爬虫]之一 scrapy框架简介和基础应用 [scrapy网络爬虫]之二 持久化操作 [scrapy网络爬虫]之 ...
- Python 网络爬虫 006 (编程) 解决下载(或叫:爬取)到的网页乱码问题
解决下载(或叫:爬取)到的网页乱码问题 使用的系统:Windows 10 64位 Python 语言版本:Python 2.7.10 V 使用的编程 Python 的集成开发环境:PyCharm 20 ...
- python网络编程-socket上传下载文件(包括md5验证,大数据发送,粘包处理)
ftp server 1) 读取文件名 2)检查文件是否存在 3)打开文件 4)检查文件大小 5)发送文件大小给客户端 6)等客户端确认 7)开始边读边(md5计算)发数据 8)给客户端发md5 ft ...
- python网络爬虫之使用scrapy爬取图片
在前面的章节中都介绍了scrapy如何爬取网页数据,今天介绍下如何爬取图片. 下载图片需要用到ImagesPipeline这个类,首先介绍下工作流程: 1 首先需要在一个爬虫中,获取到图片的url并存 ...
- python网络爬虫之使用scrapy自动爬取多个网页
前面介绍的scrapy爬虫只能爬取单个网页.如果我们想爬取多个网页.比如网上的小说该如何如何操作呢.比如下面的这样的结构.是小说的第一篇.可以点击返回目录还是下一页 对应的网页代码: 我们再看进入后面 ...
- python网络爬虫之使用scrapy自动登录网站
前面曾经介绍过requests实现自动登录的方法.这里介绍下使用scrapy如何实现自动登录.还是以csdn网站为例. Scrapy使用FormRequest来登录并递交数据给服务器.只是带有额外的f ...
- Python网络爬虫实战(五)批量下载B站收藏夹视频
我们除了爬取文本信息,有的时候还需要爬媒体信息,比如视频图片音乐等.就拿B站来说,我的收藏夹内的视频可能随时会失效,所以把它们下载到本地是非常保险的一件事. 对于这种大量列表型的数据,可以猜测B站收藏 ...
- PYTHON网络爬虫与信息提取[scrapy框架应用](单元十、十一)
scrapy 常用命令 startproject 创建一个新的工程 scrapy startproject <name>[dir] genspider 创建一个爬虫 ...
- 关于Python网络爬虫实战笔记③
Python网络爬虫实战笔记③如何下载韩寒博客文章 Python网络爬虫实战笔记③如何下载韩寒博客文章 target:下载全部的文章 1. 博客列表页面规则 也就是, http://blog.sina ...
随机推荐
- Install Qualcomm Development Environment
安裝 Android Development Environment http://www.cnblogs.com/youchihwang/p/6645880.html 除了上述還得安裝, sudo ...
- 对于Redux的理解
在移动端项目,经常会在不同view中进行传递数据,事件.当事件比较少时,我们可以通过常规的事件流方法,注册,发布事件 进行响应等等.但是项目中一个事件多处响应时候,就会使程序变得相当复杂.在现在的Vu ...
- hdu 4506(数学,循环节+快速幂)
小明系列故事——师兄帮帮忙 Time Limit: 3000/1000 MS (Java/Others) Memory Limit: 65535/32768 K (Java/Others)Tot ...
- LeetCode OJ——Two Sum
http://oj.leetcode.com/problems/two-sum/ 求是否存在两个数的和为target,暴力法,两层循环 #include <iostream> #inclu ...
- Hibernate游记——装备篇《二》(基础配置示例)
<?xml version='1.0' encoding='utf-8'?> <!DOCTYPE hibernate-configuration PUBLIC "-//Hi ...
- [转载][FPGA]有限状态机FSM学习笔记(二)
1. Mealy和Moore状态机的互换 对于给定的时序逻辑功能,可以用Mealy机实现,也可以用Moore机实现.根据Moore机比Mealy机输出落后一个周期的特性,可以实现两种状态机之间的转换. ...
- 用LCT解一类动态图的问题
很显然,学过了LCT,大家一定都会用LCT来维护动态树结构了 那么,遇到图问题的时候,是不是也能用lct来解决呢? 解决图问题的时候,我们必须要仍然维护一棵树的形态,否则,lct是做不动的 那么下面来 ...
- mysql 源码 jin-yang.github.io
https://jin-yang.github.io/post/mysql-group-commit.html
- 【IntelliJ IDEA】在idea上安装使用svn
1.在电脑上安装SVN 下载地址:64位SVN下载 然后一路next,安装完成即可. 如果忘记勾选第二个,可以重新点击安装包 重新安装,然后选择modify,然后勾选command line cli ...
- 拦截recyclerview 的item 的点击事件
recyclerview.addOnItemTouchListener(new RecyclerItemClickListener(getActivity(),recyclerview, new Re ...