深度学习中GPU和显存分析
刚入门深度学习时,没有显存的概念,后来在实验中才渐渐建立了这个意识。
下面这篇文章很好的对GPU和显存总结了一番,于是我转载了过来。
作者:陈云
链接:https://zhuanlan.zhihu.com/p/31558973
来源:知乎
深度学习最吃机器,耗资源,在本文,我将来科普一下在深度学习中:
- 何为“资源”
- 不同操作都耗费什么资源
- 如何充分的利用有限的资源
- 如何合理选择显卡
并纠正几个误区:
- 显存和GPU等价,使用GPU主要看显存的使用?
- Batch Size 越大,程序越快,而且近似成正比?
- 显存占用越多,程序越快?
- 显存占用大小和batch size大小成正比?
0 预备知识
nvidia-smi是Nvidia显卡命令行管理套件,基于NVML库,旨在管理和监控Nvidia GPU设备。
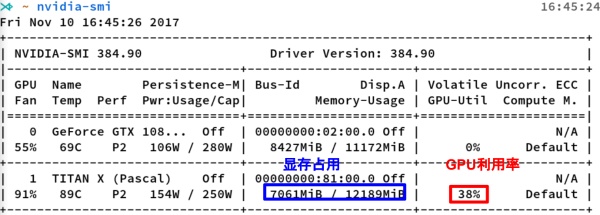
这是nvidia-smi命令的输出,其中最重要的两个指标:
- 显存占用
- GPU利用率
显存占用和GPU利用率是两个不一样的东西,显卡是由GPU计算单元和显存等组成的,显存和GPU的关系有点类似于内存和CPU的关系。
这里推荐一个好用的小工具:gpustat,直接pip install gpustat即可安装,gpustat基于nvidia-smi,可以提供更美观简洁的展示,结合watch命令,可以动态实时监控GPU的使用情况。
watch --color -n1 gpustat -cpu

显存可以看成是空间,类似于内存。
- 显存用于存放模型,数据
- 显存越大,所能运行的网络也就越大
GPU计算单元类似于CPU中的核,用来进行数值计算。衡量计算量的单位是flop: the number of floating-point multiplication-adds,浮点数先乘后加算一个flop。计算能力越强大,速度越快。衡量计算能力的单位是flops: 每秒能执行的flop数量
1*2+3 1 flop
1*2 + 3*4 + 4*5 3 flop
1. 显存分析
1.1 存储指标
1Byte = 8 bit
1K = 1024 Byte
1M = 1024 K
1G = 1024 M
1T = 1024 G
10 K = 10*1024 Byte
除了K、M,G,T等之外,我们常用的还有KB 、MB,GB,TB 。二者有细微的差别。
1Byte = 8 bit
1KB = 1000 Byte
1MB = 1000 KB
1GB = 1000 MB
1TB = 1000 GB
10 KB = 10000 Byte
K、M,G,T是以1024为底,而KB 、MB,GB,TB以1000为底。不过一般来说,在估算显存大小的时候,我们不需要严格的区分这二者。
在深度学习中会用到各种各样的数值类型,数值类型命名规范一般为TypeNum,比如Int64、Float32、Double64。
- Type:有Int,Float,Double等
- Num: 一般是 8,16,32,64,128,表示该类型所占据的比特数目
常用的数值类型如下图所示(int64 准确的说应该是对应c中的long long类型, long类型在32位机器上等效于int32):
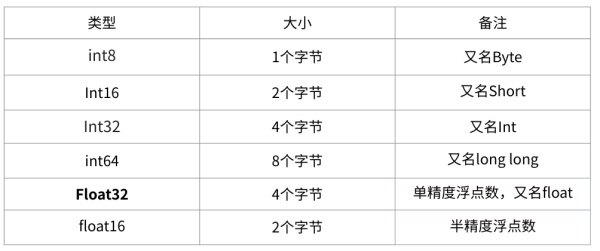
其中Float32 是在深度学习中最常用的数值类型,称为单精度浮点数,每一个单精度浮点数占用4Byte的显存。
举例来说:有一个1000x1000的 矩阵,float32,那么占用的显存差不多就是
1000x1000x4 Byte = 4MB
32x3x256x256的四维数组(BxCxHxW)占用显存为:24M
1.2 神经网络显存占用
神经网络模型占用的显存包括:
- 模型自身的参数
- 模型的输出
举例来说,对于如下图所示的一个全连接网络(不考虑偏置项b)
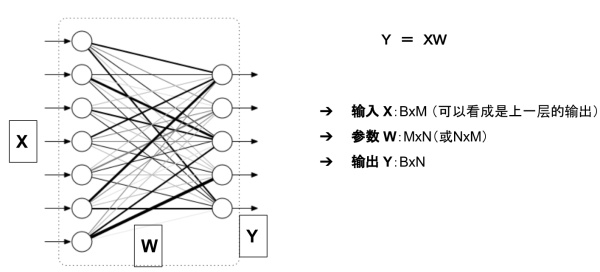
模型的显存占用包括:
- 参数:二维数组 W
- 模型的输出: 二维数组 Y
输入X可以看成是上一层的输出,因此把它的显存占用归于上一层。
这么看来显存占用就是W和Y两个数组?
并非如此!!!
下面细细分析。
1.2.1 参数的显存占用
只有有参数的层,才会有显存占用。这部份的显存占用和输入无关,模型加载完成之后就会占用。
有参数的层主要包括:
- 卷积
- 全连接
- BatchNorm
- Embedding层
- ... ...
无参数的层:
- 多数的激活层(Sigmoid/ReLU)
- 池化层
- Dropout
- ... ...
更具体的来说,模型的参数数目(这里均不考虑偏置项b)为:
- Linear(M->N): 参数数目:M×N
- Conv2d(Cin, Cout, K): 参数数目:Cin × Cout × K × K
- BatchNorm(N): 参数数目: 2N
- Embedding(N,W): 参数数目: N × W
参数占用显存 = 参数数目×n
n = 4 :float32
n = 2 : float16
n = 8 : double64
在PyTorch中,当你执行完model=MyGreatModel().cuda()之后就会占用相应的显存,占用的显存大小基本与上述分析的显存差不多(会稍大一些,因为其它开销)。
1.2.2 梯度与动量的显存占用
举例来说, 优化器如果是SGD:
可以看出来,除了保存W之外还要保存对应的梯度 ,因此显存占用等于参数占用的显存x2,
如果是带Momentum-SGD
这时候还需要保存动量, 因此显存x3
如果是Adam优化器,动量占用的显存更多,显存x4
总结一下,模型中与输入无关的显存占用包括:
- 参数 W
- 梯度 dW(一般与参数一样)
- 优化器的动量(普通SGD没有动量,momentum-SGD动量与梯度一样,Adam优化器动量的数量是梯度的两倍)
1.2.3 输入输出的显存占用
这部份的显存主要看输出的feature map 的形状。
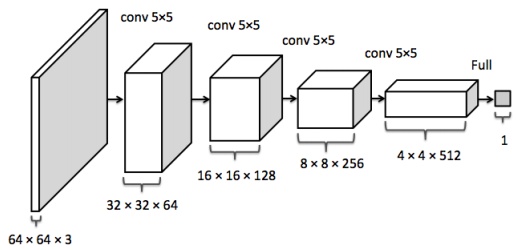
比如卷积的输入输出满足以下关系:
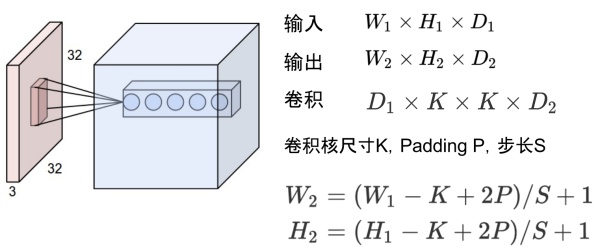
据此可以计算出每一层输出的Tensor的形状,然后就能计算出相应的显存占用。
模型输出的显存占用,总结如下:
- 需要计算每一层的feature map的形状(多维数组的形状)
- 需要保存输出对应的梯度用以反向传播(链式法则)
- 显存占用与 batch size 成正比
- 模型输出不需要存储相应的动量信息。
深度学习中神经网络的显存占用,我们可以得到如下公式:
显存占用 = 模型显存占用 + batch_size × 每个样本的显存占用
可以看出显存不是和batch-size简单的成正比,尤其是模型自身比较复杂的情况下:比如全连接很大,Embedding层很大
另外需要注意:
- 输入(数据,图片)一般不需要计算梯度
- 神经网络的每一层输入输出都需要保存下来,用来反向传播,但是在某些特殊的情况下,我们可以不要保存输入。比如ReLU,在PyTorch中,使用
nn.ReLU(inplace = True)能将激活函数ReLU的输出直接覆盖保存于模型的输入之中,节省不少显存。感兴趣的读者可以思考一下,这时候是如何反向传播的(提示:y=relu(x) -> dx = dy.copy();dx[y<=0]=0)
1.3 节省显存的方法
在深度学习中,一般占用显存最多的是卷积等层的输出,模型参数占用的显存相对较少,而且不太好优化。
节省显存一般有如下方法:
- 降低batch-size
- 下采样(NCHW -> (1/4)*NCHW)
- 减少全连接层(一般只留最后一层分类用的全连接层)
2 计算量分析
计算量的定义,之前已经讲过了,计算量越大,操作越费时,运行神经网络花费的时间越多。
2.1 常用操作的计算量
常用的操作计算量如下:
- 全连接层:BxMxN , B是batch size,M是输入形状,N是输出形状。
- 卷积的计算量: \(BHWC_{out}C_{in}K^2\)

- BatchNorm 计算量我个人估算大概是 \(BHWC\times \{4,5,6\}\), 欢迎指正
- 池化的计算量: \(BHWCK^2\)
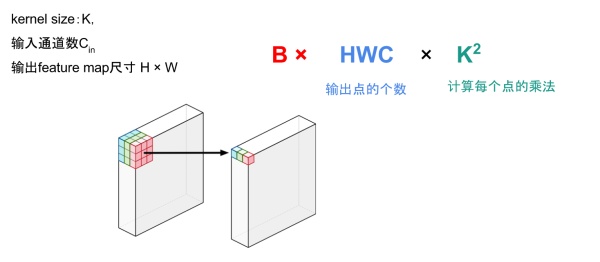
- ReLU的计算量: BHWC
2.2 AlexNet 分析
AlexNet的分析如下图,左边是每一层的参数数目(不是显存占用),右边是消耗的计算资源. 这里某些地方的计算结果可能和上面的公式对不上, 这是因为原始的AlexNet实现有点特殊(在多块GPU上实现的).

可以看出:
- 全连接层占据了绝大多数的参数
- 卷积层的计算量最大
2.3 减少卷积层的计算量
今年谷歌提出的MobileNet,利用了一种被称为DepthWise Convolution的技术,将神经网络运行速度提升许多,它的核心思想就是把一个卷积操作拆分成两个相对简单的操作的组合。如图所示, 左边是原始卷积操作,右边是两个特殊而又简单的卷积操作的组合(上面类似于池化的操作,但是有权重,下面类似于全连接操作)。
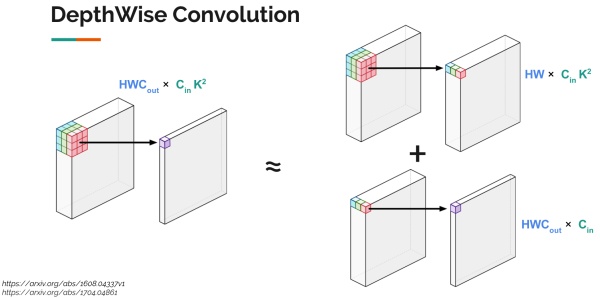 Depthwise Convolution
Depthwise Convolution
这种操作使得:
- 显存占用变多(每一步的输出都要保存)
- 计算量变少了许多,变成原来的( \({1\over C_{out} } + \frac 1 {k^2}\))(一般为原来的10-15%)
2.4 常用模型 显存/计算复杂度/准确率
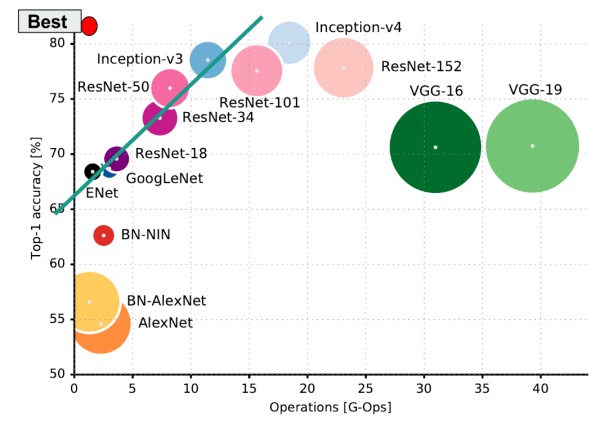
去年一篇论文(https://arxiv.org/abs/1605.07678)总结了当时常用模型的各项指标,横座标是计算复杂度(越往右越慢,越耗时),纵座标是准确率(越高越好),圆的面积是参数数量(不是显存占用),参数量越多,保存的模型文件越大。左上角我画了一个红色小圆,那是最理想的模型:快,准确率高,显存占用小。
3 总结
3.1 建议
- 时间更宝贵,尽可能使模型变快(减少flop)
- 显存占用不是和batch size简单成正比,模型自身的参数及其延伸出来的数据也要占据显存
- batch size越大,速度未必越快。在你充分利用计算资源的时候,加大batch size在速度上的提升很有限
尤其是batch-size,假定GPU处理单元已经充分利用的情况下:
- 增大batch size能增大速度,但是很有限(主要是并行计算的优化)
- 增大batch size能减缓梯度震荡,需要更少的迭代优化次数,收敛的更快,但是每次迭代耗时更长。
- 增大batch size使得一个epoch所能进行的优化次数变少,收敛可能变慢,从而需要更多时间才能收敛(比如batch_size 变成全部样本数目)。
3.2 关于显卡选购
当前市面上常用的显卡指标如下:
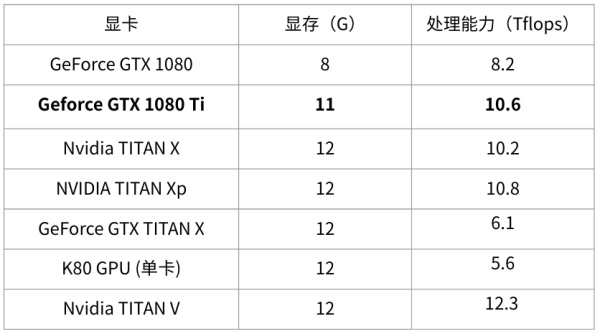
更多显卡的更多指标请参阅https://en.wikipedia.org/wiki/List_of_Nvidia_graphics_processing_units
显然GTX 1080TI性价比最高,速度超越新Titan X,价格却便宜很多,显存也只少了1个G(据说故意阉割掉一个G,不然全面超越了Titan X怕激起买Titan X人的民愤~)。
- K80性价比很低(速度慢,而且贼贵)
- 注意GTX TITAN X和Nvidia TITAN X的区别
- tensorcore的性能目前来看还无法全面发挥出来, 这里不考虑. 其它的tesla系列像P100这些企业级的显卡这里不列了,普通消费者不会买, 而且性价比较低(一台DGX 1上百万.....)
另外,针对本文,我做了一个Google 幻灯片:神经网络性能分析,国内用户可以点此下载ppt。Google幻灯片格式更好,后者格式可能不太正常。
限于本人水平,文中有疏漏之处,还请指正。
深度学习中GPU和显存分析的更多相关文章
- 科普帖:深度学习中GPU和显存分析
知乎的一篇文章: https://zhuanlan.zhihu.com/p/31558973 关于如何使用nvidia-smi查看显存与GPU使用情况,参考如下链接: https://blog.csd ...
- 自制操作系统Antz(3)——进入保护模式 (中) 直接操作显存
Antz系统更新地址: https://www.cnblogs.com/LexMoon/category/1262287.html Linux内核源码分析地址:https://www.cnblogs. ...
- 用深度学习LSTM炒股:对冲基金案例分析
英伟达昨天一边发布“全球最大的GPU”,一边经历股价跳水20多美元,到今天发稿时间也没恢复过来.无数同学在后台问文摘菌,要不要抄一波底嘞? 今天用深度学习的序列模型预测股价已经取得了不错的效果,尤其是 ...
- 深度学习中的序列模型演变及学习笔记(含RNN/LSTM/GRU/Seq2Seq/Attention机制)
[说在前面]本人博客新手一枚,象牙塔的老白,职业场的小白.以下内容仅为个人见解,欢迎批评指正,不喜勿喷![认真看图][认真看图] [补充说明]深度学习中的序列模型已经广泛应用于自然语言处理(例如机器翻 ...
- 关于深度学习中的batch_size
5.4.1 关于深度学习中的batch_size 举个例子: 例如,假设您有1050个训练样本,并且您希望设置batch_size等于100.该算法从训练数据集中获取前100个样本(从第1到第100个 ...
- 深度学习中Dropout原理解析
1. Dropout简介 1.1 Dropout出现的原因 在机器学习的模型中,如果模型的参数太多,而训练样本又太少,训练出来的模型很容易产生过拟合的现象. 在训练神经网络的时候经常会遇到过拟合的问题 ...
- 卷积在深度学习中的作用(转自http://timdettmers.com/2015/03/26/convolution-deep-learning/)
卷积可能是现在深入学习中最重要的概念.卷积网络和卷积网络将深度学习推向了几乎所有机器学习任务的最前沿.但是,卷积如此强大呢?它是如何工作的?在这篇博客文章中,我将解释卷积并将其与其他概念联系起来,以帮 ...
- 深度学习中的Normalization模型
Batch Normalization(简称 BN)自从提出之后,因为效果特别好,很快被作为深度学习的标准工具应用在了各种场合.BN 大法虽然好,但是也存在一些局限和问题,诸如当 BatchSize ...
- [优化]深度学习中的 Normalization 模型
来源:https://www.chainnews.com/articles/504060702149.htm 机器之心专栏 作者:张俊林 Batch Normalization (简称 BN)自从提出 ...
随机推荐
- Local storage htm5
使用本地存储,web应用可以在用户浏览器中本地存储数据. 在HTML5之前,应用数据存储必须使用cookie,包括每个服务端的请求,本地存储更加安全,并且可以存储大量的数据到本地,不影响网站的性能. ...
- js 分享代码--完整示例代码
<div class="bdsharebuttonbox" data-tag="share_1"> <a class="bds_ms ...
- codeforces 450B B. Jzzhu and Sequences(矩阵快速幂)
题目链接: B. Jzzhu and Sequences time limit per test 1 second memory limit per test 256 megabytes input ...
- vim的tab缩进及用空格设置
编辑~/.vimrc文件,分别设置用空格而不是用tab,一个tab多少个空格,自动缩进多少宽度,显示行号. set expandtabset tabstop=4 set shiftwidth=4 se ...
- sipp 对asterisk 进行压力测试
测试环境 asterisk 192.168.106.170 版本astrisk1.8 sipp 192.168.106.141 sipp版本3.3 安装依赖包yum install make g ...
- YouTube视频签名加密算法的破解
密码学方法 多年以前,YouTube的视频源地址是直接encode在页面中的,你甚至可以用一行Perl来下载它们. 直到2012年8月,这个简单的脚本(用在0.0.1版本的You-Get中)仍然可以解 ...
- Code-NFine:.NET快速开发平台 NFine.Framework Web框架
ylbtech-Code-NFine:.NET快速开发平台 NFine.Framework Web框架 1.NFine.Framework 详细介绍返回顶部 1. NFine 是基于 C# 语言的极速 ...
- jQuery.validator.addMethod方法的使用
该方法有三个api接口参数,name,method,messages addMethod(name,method,message)方法 参数 name 是添加的方法的名字. 参数 method 是一个 ...
- java 随机颜色
用HSV模型来实现颜色的随机,然后转为RGB模型 色相(H)是色彩的基本属性,就是平常所说的颜色名称,如红色.黄色等. 饱和度(S)是指色彩的纯度,越高色彩越纯,低则逐渐变灰,取0-100%的数值. ...
- APP开发过程中需求变更流程
在APP开发过程中,不可避免的会有需求变更,从以往项目开发过程总结发现,需求变更太频繁,产品一句话需求,没有形成良好的版本迭代概念,频繁的变动影响开发交付日期,但是交付日期又是定死的,严重拖累了开发及 ...