Java数据结构-------List
三种List:ArrayList,Vector,LinkedList
类继承关系图
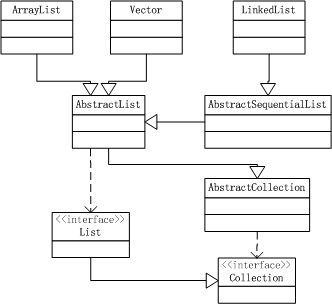
ArrayList和Vector通过数组实现,几乎使用了相同的算法;区别是ArrayList不是线程安全的,Vector绝大多数方法做了线程同步。
LinkedList通过双向链表实现。
源代码分析
1、添加元素到列表尾端(Appends the specified element to the end of this list.)
ArrayList:当所需容量超过当前ArrayList的大小时,需要进行扩容,对性能有一定的影响。
优化策略:在能有效评估ArrayList数组初始值大小的情况下,指定其容量大小有助于性能提升,避免频繁的扩容。
public boolean add(E e) {
ensureCapacityInternal(size + 1); // Increments modCount!! 确保内部数组有足够的空间
elementData[size++] = e; //将元素放在数组尾部
return true;
}
private void ensureCapacityInternal(int minCapacity) {
if (elementData == EMPTY_ELEMENTDATA) {
minCapacity = Math.max(DEFAULT_CAPACITY, minCapacity); //如果数组为空数组,取初始容量和minCapacity中的最大值,初始容量DEFAULT_CAPACITY = 10
}
ensureExplicitCapacity(minCapacity);
}
private void ensureExplicitCapacity(int minCapacity) {
modCount++; //被修改次数,iterator成员变量expectedModCount为创建时的modCount的值,用来判断list是否在迭代过程中被修改
// overflow-conscious code
if (minCapacity - elementData.length > 0)
grow(minCapacity); //如果所需容量大小大于数组的大小就进行扩展
}
private void grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length;
int newCapacity = oldCapacity + (oldCapacity >> 1); //旧容量的1.5倍。二进制右移一位差不多相当于十进制除以2,对CPU来说,右移比除运算速度更快。如果oldCapacity为偶数,newCapacity为1.5*oldCapacity,否则为1.5*oldCapacity-1。
if (newCapacity - minCapacity < 0) //如果计算出的容量不够用,就使用minCapacity
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0) //如果计算出的容量大于MAX_ARRAY_SIZE=Integer.MAX_VALUE-8,
newCapacity = hugeCapacity(minCapacity);
// minCapacity is usually close to size, so this is a win:
elementData = Arrays.copyOf(elementData, newCapacity);//调用System.arraycopy方法复制数组
}
//判断是否大于数组最大值Integer.MAX_VALUE,疑问:设置MAX_ARRAY_SIZE=Integer.MAX_VALUE-8的意义是什么?
private static int hugeCapacity(int minCapacity) {
if (minCapacity < 0) // overflow
throw new OutOfMemoryError();
return (minCapacity > MAX_ARRAY_SIZE) ?
Integer.MAX_VALUE :
MAX_ARRAY_SIZE;
//
}
LinkedList:每次新增元素都需要new一个Node对象,并进行更多的赋值操作。在频繁的调用中,对性能会产生一定的影响。
public boolean add(E e) {
linkLast(e);
return true;
}
void linkLast(E e) {
final Node<E> l = last;
final Node<E> newNode = new Node<>(l, e, null); //每增加一个节点,都需要new一个Node
last = newNode;
if (l == null)
first = newNode;
else
l.next = newNode;
size++;
modCount++;
}
2、在列表任意位置添加元素
ArrayList:基于数组实现,数组需要一组连续的内存空间,如果在任意位置插入元素,那么该位置之后的元素需要重新排列,效率低。
public void add(int index, E element) {
rangeCheckForAdd(index);//检查索引是否越界
ensureCapacityInternal(size + 1); // Increments modCount!!
System.arraycopy(elementData, index, elementData, index + 1,
size - index);//每次操作都会进行数组复制,System.arraycopy可以实现数组自身的复制
elementData[index] = element;
size++;
}
private void rangeCheckForAdd(int index) {
if (index > size || index < 0)
throw new IndexOutOfBoundsException(outOfBoundsMsg(index));
}
LinkedList:先找到指定位置的元素,然后在该元素之前插入元素。在首尾插入元素,性能较高;在中间位置插入,性能较低。
//在列表指定位置添加元素
public void add(int index, E element) {
checkPositionIndex(index);//检查索引是否越界 if (index == size) //index为列表大小,相当于在列表尾部添加元素
linkLast(element);
else
linkBefore(element, node(index));
} //返回指定索引的元素,在首尾查找速度快,在中间位置查找速度较慢,需要遍历列表的一半元素。
Node<E> node(int index) {
// assert isElementIndex(index); if (index < (size >> 1)) { //如果index在列表的前半部分,从头结点开始向后遍历
Node<E> x = first;
for (int i = 0; i < index; i++)
x = x.next;
return x;
} else { //如果index在列表的后半部分,从尾结点开始向前遍历
Node<E> x = last;
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
} //在指定节点succ之前添加元素
void linkBefore(E e, Node<E> succ) {
// assert succ != null;
final Node<E> pred = succ.prev;
final Node<E> newNode = new Node<>(pred, e, succ);
succ.prev = newNode;
if (pred == null) //只有succ一个节点
first = newNode;
else
pred.next = newNode;
size++;
modCount++;
}
3、删除任意位置元素
ArrayList:每次删除都会复制数组。删除的位置越靠前,开销越大;删除的位置越靠后,开销越小。
public E remove(int index) {
rangeCheck(index);//检查索引是否越界
modCount++;
E oldValue = elementData(index);
int numMoved = size - index - 1;
if (numMoved > 0)
System.arraycopy(elementData, index+1, elementData, index,
numMoved);//将删除位置后面的元素往前移动一位
elementData[--size] = null; // clear to let GC do its work 最后一个位置设置为null
return oldValue;
}
LinkedList:先通过循环找到要删除的元素,然后删除该元素。删除首尾的元素,效率较高;删除中间元素,效率较差。
public E remove(int index) {
checkElementIndex(index);
return unlink(node(index));
}
E unlink(Node<E> x) {
// assert x != null;
final E element = x.item;
final Node<E> next = x.next;
final Node<E> prev = x.prev;
if (prev == null) { //x为第一个元素
first = next;
} else {
prev.next = next;
x.prev = null;
}
if (next == null) { //x为最后一个元素
last = prev;
} else {
next.prev = prev;
x.next = null;
}
x.item = null;
size--;
modCount++;
return element;
}
4、遍历列表
三种遍历方式:foreach,迭代器,for遍历随机访问。
foreach的内部实现也是使用迭代器进行遍历,但由于foreach存在多余的赋值操作,比直接使用迭代器稍慢,影响不大。for遍历随机访问对ArrayList性能较好,对LinkedList是灾难性的。
并发List
Vector和CopyOnWriteArrayList是线程安全的实现;
ArrayList不是线程安全的,可通过Collections.synchronizedList(list)进行包装。
CopyOnWriteArrayList,读操作不需要加锁,
1、读操作
CopyOnWriteArrayList:读操作没有锁操作
public E get(int index) {
return get(getArray(), index);
}
final Object[] getArray() {
return array;
}
private E get(Object[] a, int index) {
return (E) a[index];
}
Vector:读操作需要加对象锁,高并发情况下,锁竞争影响性能。
public synchronized E get(int index) {
if (index >= elementCount)
throw new ArrayIndexOutOfBoundsException(index);
return elementData(index);
}
2、写操作
CopyOnWriteArrayList:需要加锁且每次写操作都需要进行一次数组复制,性能较差。
public boolean add(E e) {
final ReentrantLock lock = this.lock;
lock.lock();
try {
Object[] elements = getArray();
int len = elements.length;
Object[] newElements = Arrays.copyOf(elements, len + 1); //通过复制生成数组副本
newElements[len] = e; //修改副本
setArray(newElements); //将副本写会
return true;
} finally {
lock.unlock();
}
}
Vector:和读一样需要加对象锁,相对CopyOnWriteArrayList来说不需要复制,写性能比CopyOnWriteArrayList要高。
public synchronized boolean add(E e) {
modCount++;
ensureCapacityHelper(elementCount + 1); //确认是否需要扩容
elementData[elementCount++] = e;
return true;
}
private void ensureCapacityHelper(int minCapacity) {
// overflow-conscious code
if (minCapacity - elementData.length > 0)
grow(minCapacity);
}
总结:在读多写少的高并发应用中,适合使用CopyOnWriteArrayList;在读少写多的高并发应用中,Vector更适合。
Java数据结构-------List的更多相关文章
- Java数据结构之队列的实现以及队列的应用之----简单生产者消费者应用
Java数据结构之---Queue队列 队列(简称作队,Queue)也是一种特殊的线性表,队列的数据元素以及数据元素间的逻辑关系和线性表完全相同,其差别是线性表允许在任意位置插入和删除,而队列只允许在 ...
- JAVA数据结构系列 栈
java数据结构系列之栈 手写栈 1.利用链表做出栈,因为栈的特殊,插入删除操作都是在栈顶进行,链表不用担心栈的长度,所以链表再合适不过了,非常好用,不过它在插入和删除元素的时候,速度比数组栈慢,因为 ...
- Java数据结构之树和二叉树(2)
从这里始将要继续进行Java数据结构的相关讲解,Are you ready?Let's go~~ Java中的数据结构模型可以分为一下几部分: 1.线性结构 2.树形结构 3.图形或者网状结构 接下来 ...
- Java数据结构之树和二叉树
从这里开始将要进行Java数据结构的相关讲解,Are you ready?Let's go~~ Java中的数据结构模型可以分为一下几部分: 1.线性结构 2.树形结构 3.图形或者网状结构 接下来的 ...
- Java数据结构之线性表(2)
从这里开始将要进行Java数据结构的相关讲解,Are you ready?Let's go~~ java中的数据结构模型可以分为一下几部分: 1.线性结构 2.树形结构 3.图形或者网状结构 接下来的 ...
- Java数据结构之线性表
从这里开始将要进行Java数据结构的相关讲解,Are you ready?Let's go~~ java中的数据结构模型可以分为一下几部分: 1.线性结构 2.树形结构 3.图形或者网状结构 接下来的 ...
- java 数据结构 图
以下内容主要来自大话数据结构之中,部分内容参考互联网中其他前辈的博客,主要是在自己理解的基础上进行记录. 图的定义 图是由顶点的有穷非空集合和顶点之间边的集合组成,通过表示为G(V,E),其中,G标示 ...
- java 数据结构 队列的实现
java 数据结构队列的代码实现,可以简单的进行入队列和出队列的操作 /** * java数据结构之队列的实现 * 2016/4/27 **/ package cn.Link; import java ...
- java 数据结构 栈的实现
java数据结构之栈的实现,可是入栈,出栈操作: /** * java数据结构之栈的实现 * 2016/4/26 **/ package cn.Link; public class Stack{ No ...
- Java数据结构和算法
首先,本人自学java,但是只学习了java的基础知识,所以想接下来学习一下数据结构和算法,但是找了很多教材,大部分写的好的都是用c语言实现的,虽然知道数据结构和算法,跟什么语言实现的没有关系,但是我 ...
随机推荐
- ajax 的 promise
$.when().done().fail() $.when($.ajax("test1.html"),$.ajax("test2.html")).done(fu ...
- 第六篇:python中numpy.zeros(np.zeros)的使用方法
用法:zeros(shape, dtype=float, order='C') 返回:返回来一个给定形状和类型的用0填充的数组: 参数:shape:形状 dtype:数据类型,可选参数,默认numpy ...
- jsp--提交表单→插入数据库→成功后返回提示信息
<%@ page language="java" import="java.util.*,java.sql.*" pageEncoding="u ...
- 如何修改iframe内的页面的元素的样式。。。。
方法一: 直接通过设置backgroundColor的颜色即可:<!DOCTYPE html><html><head><script>function ...
- tp3.2框架中使用volist输出混乱的一点发现
在tp框架中,volist真的是一样很好用的东西,但是要是不注意,用起来也会有问题的 在Controller层中,将数据assign到页面 $this->assign('vo',$news); ...
- Vue钩子函数生命周期实例详解
vue生命周期简介 Vue实例有一个完整的生命周期,也就是从开始创建.初始化数据.编译模板.挂载Dom.渲染→更新→渲染.卸载等一系列过程,我们称这是Vue的生命周期.通俗说就是Vue实例从创建到销毁 ...
- mysql中的FROM_UNIXTIME()函数和UNIX_TIMESTAMP()函数
unix_timestamp 是时间戳,可以用数据库里的存储时间数据的字段 from_unixtime 是将时间戳格式化为你想要时间
- 关于在namanode上编写脚本控制DataNode的...
脚本如下:(我的虚拟机名字分别为:wang201 wang 202 wang 203 wang 204) params=$@ i= ; i <= ; i++)) ; do echo ====== ...
- Android 获取当前应用的版本号+版本号比较
前言:因为项目更新的时候需要一些版本号的信息,后台返回两个string,一个是最低兼容版,一个是最新版.所以拿到数据后要比较一下,所以封装了一个Common包来处理. Step 1 废话不多说, ...
- Hadoop第三课
1.3Hadoop基础知识 1.3.1术语解释 1.Hadoop1.0 • 第一代Hadoop,由分布式文件系统HDFS 和分布式计算框架MapReduce组成 • HDFS由一个NameNode和多 ...