漫谈使用Kafka作为MQ中间件
哪些场景适合使用Kafka
线上系统会实时产生数以万计的日志信息,服务器运行状态,用户行为记录,业务消息 等信息,这些信息需要用于多个不同的目的,比如审计、安全、数据挖掘等,因此需要以分类的方式将这些信息发送到某个地方,以方便后台处理service实时的去获取数据。MQ用于解决数据生成速率与数据消费速率不一致的场景,业务接口解耦,数据缓存冗余,海量数据处理弹性,异步通信。
Kafka是LinkedIn开源出来的分布式消息发布-订阅系统,主要特点是基于Pull模式来处理消息,O(1)常数时间级别的消息持久化和读取时间复杂度,基于at least once的处理原则,追求高吞吐量(单台机器吞吐量可达10w/s),主要用于非敏感信息如日志的收集和传输,不支持事务,对消息的重复、丢失和错误没有严格要求 。
简单的Kafka消息生产/消费模型
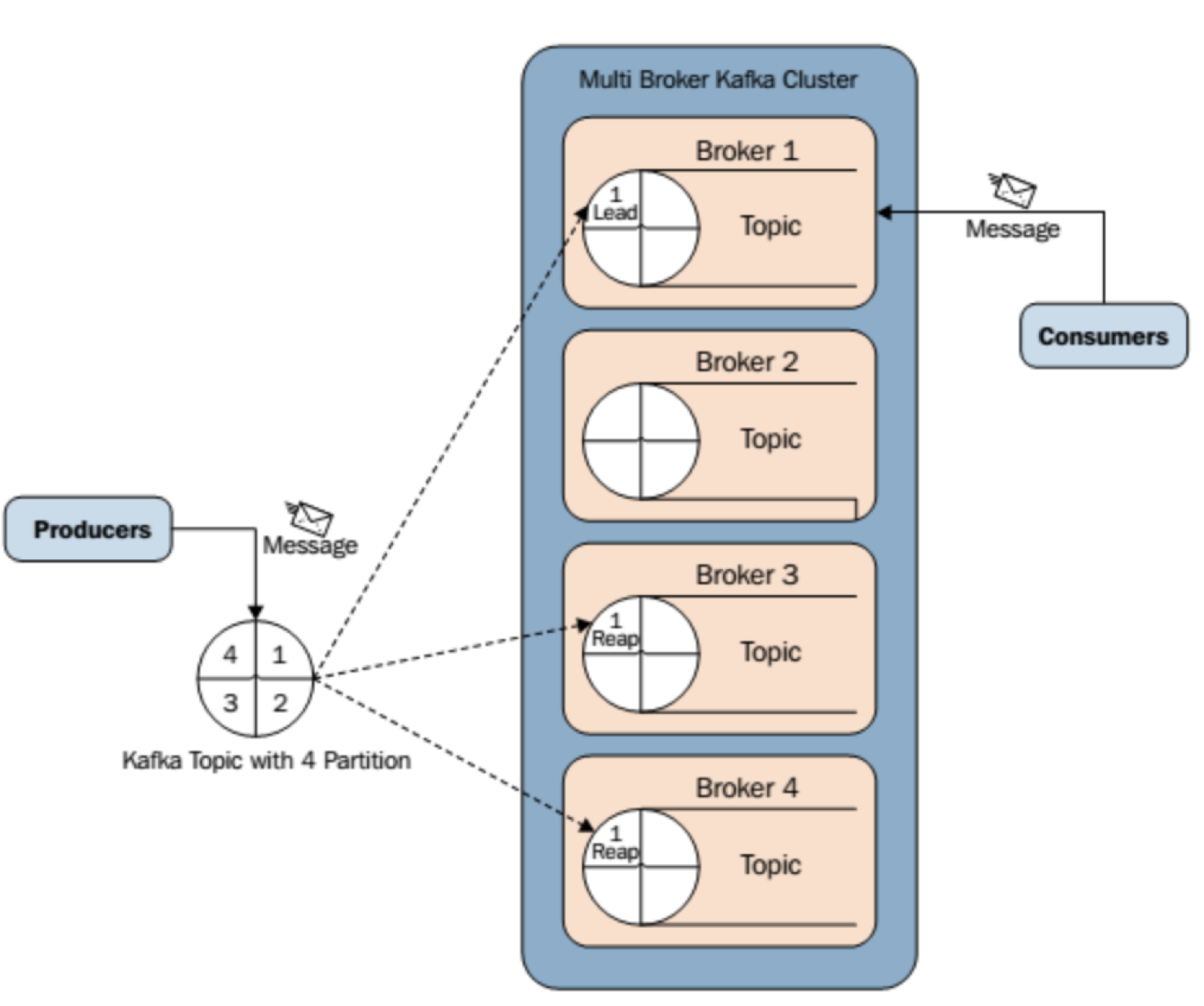
最简单的Kafka拓扑网络里只有一个broker,producer创建不同的topics,并将msg通过push的方式发送到broker,broker使用append log的方式顺序性持久化msg,然后不同的consumers根据自己的消费速率按需从broker处pull自己需要的topics对应的msg;对于一个broker上的一个topic的msg而言,kafka总会保证其被consumer消费的先后顺序;采用pull的消息处理模式可以让consumer按需处理。
Broker从本地文件系统里添加消息和获取消息都是按照队列的入列和出列模式操作,因此时间复杂度都是O(1);Kafka不会主动删除被消费过的消息,而是通过server.properties中的配置按照过期时间或者文件总大小来进行文件删除。
构建Kafka Cluster,并使用zookeeper cluster作为协调服务
为了提供更高的msg吞吐量以及HA,Kafka支持以cluster的方式创建多个broker对外提供服务,由于集群环境引入的不确定性,kafka使用Zookeeper作为协调性服务(0.7.+引入),功能如下:
#1监听broker的活跃状态及其存储的topic和partition状态,协调broker leader和partition leader的选举;
#2 为producer提供broker的访问地址,并记录每个topic下对应的partition leader分布地址,以帮助实现负载均衡;
#3 为consumer提供broker的访问地址,并记录每个partition正在被哪些CG内的哪一个consumer消费,CG中成员的变化,以帮助实现负载均衡,同时记录每个CG的offset。
Zookeeper上典型的存储kafka信息的格式如下,Kafka Cluster中每个broker都可以获取关于cluster的metadata,包含active broker list,topic’s partition leaders等,因此对于producer而言每个broker都是对等的;
leo-chen-zookeeper
-> broker
-> ids
-> [broker_id] ## temp znode, value is host:port
-> topics
-> [topic_id]
-> [partition_id] ## temp znode, value is partition refer
-> consumers
-> [group_id]
-> ids
-> [consumer_id] ## temp znode, value is partition_id list
-> offsets
-> [topic_id]
-> [broker_id-partition_id] ## persist znode, value is offset
-> owners
-> [topic_id]
-> [broker_id-partition_id] ## temp znode, value is consumer_id
Zookeeper实现的功能如下:
#1 broker node注册:新上线的broker会在zookeeper上创建一个temp znode以维护自己的活跃状态,znode value为broker的访问地址;broker下线或者session失效都会导致temp znode被删除。
#2 broker topic注册:新上线的broker还会根据自身存储的topic-partition创建对应的temp znode,znode value为partition的索引,用于失效转移的时候进行状态对比。
#3 consumer node注册:新上线的consumer会在zookeeper上创建一个temp znode以维护自己的活跃状态,znode value为该consumer正在访问的topic-partition列表;consumer的上线下线都会触发kafka的rebalance动作。
#4 consumer-partition offset注册:一个CG中新上线的consumer会根据自己正在访问的partition对应的offset在zookeeper上创建一个persist znode,znode value为offset的值;当consumer下线之后,同一个CG内的其他consumer会继续消费这个offset对应的partition msg;
#5 partition owner注册:新上线的consumer会根据自己正在消费的topic-partition在zookeeper上创建一个temp znode,表示当前CG内所有正在被消费的partition都有哪些consumer在消费。
一个新的consumer上线之后会触发如下操作:
#1 进行consumer node注册;
#2 在consumers/[group_id]/ids路径下注册一个watcher用于监听当前group中其他consumer临时节点的变动,如果有变动则触发负载均衡,通知当前consumer node重新计算可消费的topic-partition;
#3 在broker/ids路径下注册一个watcher用于监听所有broker临时节点的变动,如果有变动则触发负载均衡,通知当前consumer node重新计算可消费的topic-partition;
维护topic下partition的数量,同步和过期策略
kafka将每一个topics拆分成多个partition(0.8.+引入)以便于负载均衡到多个broker上,由于一个topics的msg被分拆到了多个partition,则 kafka只能保证按一个partition中的msg按顺序让consumer进行消费(除partition所在的broker下线的情况),并不保证一个topic内多个partition间的msg的消费顺序。一个topics的msg划分到哪个partition的策略有两种,一是采用Key Hash算法,一是采用Round Robin算法。
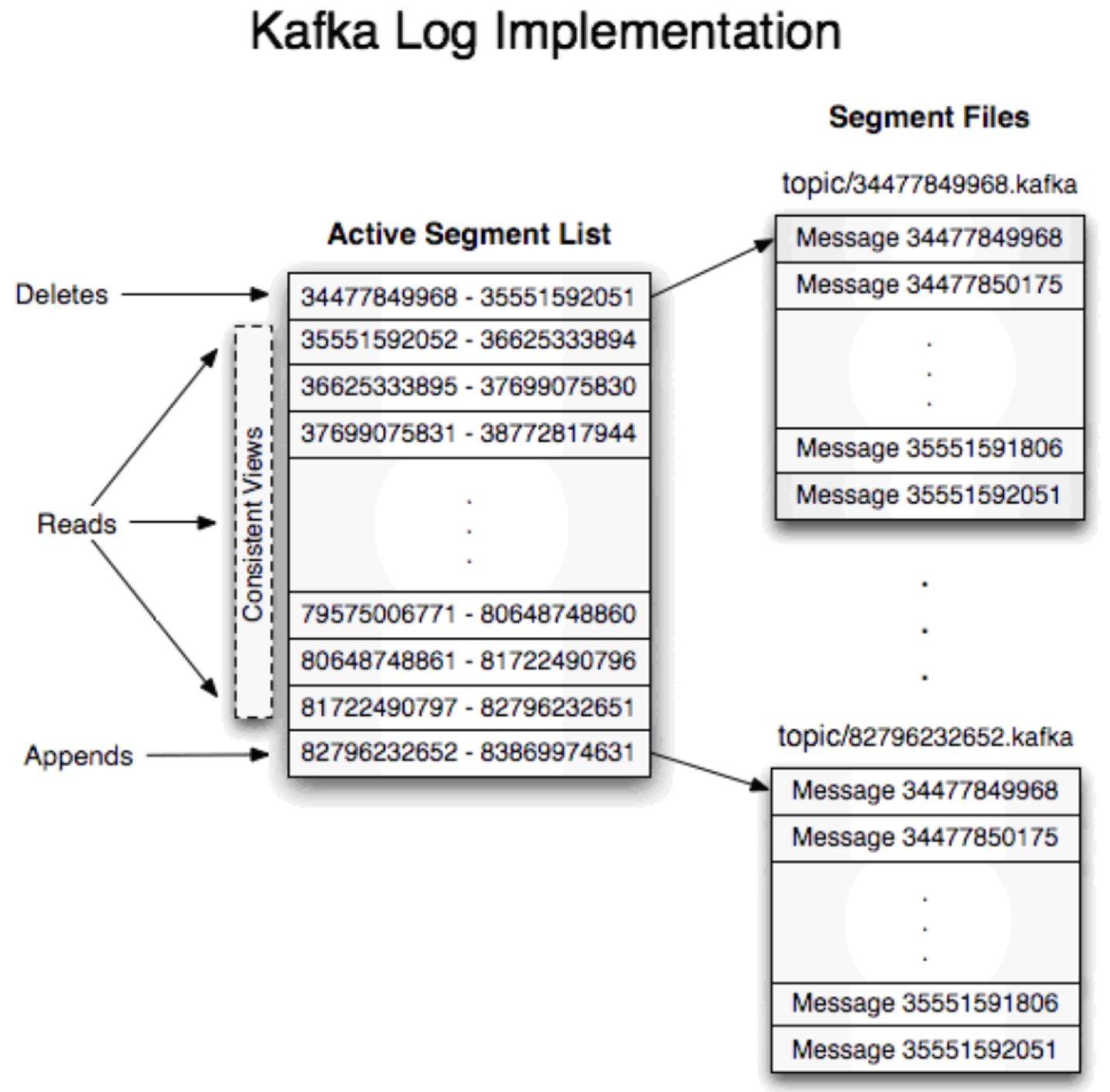
Kafka通过partition log文件在文件系统上存储msg,msg的写入和读取都可以是批量线性的,同时基于read-ahead,write-behind,线性读写,系统页缓存的操作方式使得kafka对partition log文件的操作非常快,并且优于JVM的内存操作效率;传统的RPC文件读取流程会经历四个步骤:磁盘到内核页缓存,内核页缓存到用户空间缓存,用户空间缓存到内核socket缓存,内核socket缓存到网卡缓存,最终发送给用户;而利用sendfile和zero-copy技术可以将内核页缓存的数据直接复制到网卡缓存,从而可以让kafka实现近似缓存级别的数据操作速度。
Broker上典型的存储msg的文件格式如下,~/leo-chen/kafka-msg表示log.dirs指向的根目录,然后是按照topic以及partition划分的子目录,[topic-name] - [partition-num],数字表示partition的编号,同一个topic下的partition尽量不要分布在一个broker下;
leo-chen-broker
-> kafka-msg
-> topic_report-0
-> 34477849968.index
-> 34477849968.log
-> 35551592052.index
-> 35551592052.log
-> topic_report-3
-> topic_launch_info-0
-> topic_api_call-0
-> topic_api_call-1
producer向指定的topic发送msg也就是寻找对应的topic目录,并将一条msg entry添加到文件末尾的过程,一个日志文件由*.index和*.log组成,前者为msg的位置索引,后者是msg本身,这样的存储设计有如下优势:
#1 segment file的分段存储方式方便独立加载,检索和删除数据;
#2 独立存储索引信息*.index的方式可以避免冗余IO操作,快速定位数据;

下图是一个topic下一个partition log的逻辑抽象图,所有的partition log files都以topic name作为根目录,该broker上存储的关于该topic的日志文件都位于此目录下;每一条日志由三个部分组成,8个字节的offset用于唯一标记该msg,4个字节的num表示该msg的总长度,n个字节的content表示消费内容,其他就是一些版本和校验字段;每一个segment file由一个offset区间段的msg组成,文件名是该区间最小的offset,因此获取消息时指定一个起始offset和maximum chunk size就可以定位目标msg;将msg分文件存储的一个好处就是如果指定了过期时间,则删除过期的msg就只需要简单删除独立的文件。
另外kafka允许给每个partition设置一个或多个replication,但只有一个partition会作为leader对外同时提供读写服务,其他的replication仅作为备份,他们之间的关系由zookeeper进行维护;当当前的partition leader下线后,zookeeper维护的临时节点会因为session失效而自动删除,因此其他的follower可以竞争成为新的leader,实现故障转移;kafka会为每个partition维护一个a set of in-sync replicas的列表(ISR,总数为n的集群里只要有1个节点存活就能正常工作,不同于zookeeper的majority vote策略,需要总数为2n+1的集群里至少有n+1个节点存活才能正常工作,优势在于系统的latency取决于吞吐量最快的node),存储所有replication中与之前的partition leader同步状态保持一致的节点,而新的leader也将从这个列表里诞生,而不需要经过投票过程产生新的leader。
Replication与partition leader同步的过程类似于consumer消费msg的过程,也是顺序批量的将partition leader上的消息pull到本地;而kafka会通过两个状态值判定一个replication的健康状态,一个是replication与zookeeper的heartbeat,另一个是partition与replication上最大offset的差值,只有满足两个条件的replication才会被加入ISR;一个msg只有在所有的replication上都进行同步之后,msg的状态才设置为committed,表示这条msg可被consumer消费。
producer使用batch或者async的方式向broker发送消息
producer需要将msg发送到broker之前,会先为msg指定一个partitionKey,并通过可自定义的hash算法获取一个partition refer,然后向zookeeper获取对应partition的host:port;通过这样的方式保证在一个topic下,所有标记为partitionKey的msg都会被发送到同一个partition上;为了提升性能,producer可以当msg累积到一定量之后统一将一批消息发送到broker,可以是累积消息数量,时间间隔,或者累积msg数据大小;Kafka支持gzip,snappy等多种数据压缩方式。
另外由于kafka会为每个leader partition提供一个或者多个replication以保证容错性,因此leader partition在收到msg之后会将数据同步到其他的replication上, producer可以通过设置acks参数(0|1|-1)要求同步\异步等待成功被同步了msg的replication的数量。一个msg只有在对应的所有replication上都sync之后才会在partition leader上被标注为committed状态,表示可以被producer消费。
consumer基于consumer group和offset从broker取出msg
kafka定义一个 topic可以被多个CG(Consumer Group)监听消费,CG内的consumer可以消费多个不同的partitions,但对于一个topic内的partitions,一个CG下的consumers只能消费不同的partitions,也就是对于一个partition而言禁止同一个CG内的consumer进行并发访问,这样可以最小的代价保证一个CG内的msg消费顺序。
因此如果想实现topic内的消息广播(一个msg被所有consumer消费)则为每一个consumer都创建一个CG,如果想实现topic内的消息单播(一个msg只被一个consumer消费)则所有的consumer都放到一个CG里。一般情况下一定是一个CG处理一个topic下所有的partition的所有msg,为了达到最优效率,一个topic下所有partition的数量需要大于等于一个CG内所有consumer的数量(尽量让所有consumer都处理工作状态),同时也要大于所有broker的数量以便于均衡分配到不同的broker上。
一个msg是否被消费是通过partition上msg队列中的位置(offset)决定,因此consumer可以通过修改offset的值从而读取partition上任意位置的msg,由于这个offset是交由consumers进行维护,如果是多个CG消费同一个partition的msg的话,需要各自维护自己的offset,因此不存在锁的竞争,并且通过简单增加broker的数量就可以提升访问并发量,通过配置producer.property可以将offset存储于zookeeper,或者producer自己维护 。
kafka提供三种级别的msg消费一致性语义
#1 at most once:fetch msg, update offset, consume msg,由于更新offset是在处理msg之前,所以可能出现msg丢失的场景。
#2 at least once:fetch msg, consume msg, update offset,由于更新offset是在处理msg之后,所以可能出现msg被重复消费的场景,kafka推荐配置。
#3 exactly once:在at least once的基础上,在处理msg之前添加一个接口幂等性判定,或者基于2阶段提交。
Kafka如何保证消息机制的可靠性
消息系统中由于参与方较多以及网络延迟等问题,需要保证几个点,
#1 保证msg发送成功:producer会同步等待broker的返回,并确认replication同步的结果,以保证消息成功被多个broker保存;但如果设置为等待所有replication都同步才返回的话会极大降低producer的吞吐量。
#2 保证msg的消费顺序与发送顺序一致:kafka可以保证一个broker下一个partition接受到的msg可以依次发送到consumer,但需要处理几个常见的问题:
一个问题是由于网络原因导致先发送的msg晚于后发送的msg到达broker/consumer,这样的问题可以通过producer在msg上添加version,并在consumer方按照version的先后顺序进行消费。
另外一个问题就是当一个broker下线之后,即使对应的partition在其他broker上有replication可以支持故障转移,但由于partition leader被新的replication替代,CG针对原来partition锁记录的offset不再可用,也就是不再能保证当前msg的消费顺序。
#3 保证msg被成功消费后不再重复消费:在at most once/at least once/exactly once中,kafka使用的是at least once,因此msg有可能被重复消费,而exactly once可以保证一条消息有且只有一次消费过程,可以在at least once的基础上在producer端添加幂等性判定,由于不同msgId可能表示同一个业务消息,因此还需要从业务层面定制一个全局唯一性的标识 。
漫谈使用Kafka作为MQ中间件的更多相关文章
- Kafka与MQ的区别
作为消息队列来说,企业中选择mq的还是多数,因为像Rabbit,Rocket等mq中间件都属于很成熟的产品,性能一般但可靠性较强, 而kafka原本设计的初衷是日志统计分析,现在基于大数据的背景下也可 ...
- 消息队列 ---常用的 MQ 中间件
目前市面上比较常用的 MQ(Message Queue,消息队列)中间件有 RabbitMQ.Kafka.RocketMQ,如果是轻量级的消息队列可以使用 Redis 提供的消息队列,其中 Redis ...
- MQ中间件死信队列深度不断增加问题解决案例
感谢作者: http://www.wo81.com/tec/mid/mq/2014-04-14/94.html MQ中间件死信队列深度不断增加问题解决案例 ❞ ☜ ☞ 作者:彭新 日期:2014-0 ...
- 初试kafka消息队列中间件一 (只适合初学者哈)
初试kafka消息队列中间件一 今天闲来有点无聊,然后就看了一下关于消息中间件的资料, 简单一点的理解哈,网上都说的太高大上档次了,字面意思都想半天: 也就是用作消息通知,比如你想告诉某某你喜欢他,或 ...
- 初试kafka消息队列中间件二(采用java代码收发消息)
初试kafka消息队列中间件二(采用java代码收发消息) 上一篇 初试kafka消息队列中间件一 今天的案例主要是将采用命令行收发信息改成使用java代码实现,根据上一篇的接着写: 先启动Zooke ...
- 物联网架构成长之路(28)-Docker练习之MQ中间件(Kafka)
0. 前言 消息队列MQ,这个在一般的系统上都是会用到的一个中间件,我选择Kafka作为练手的一个中间件,Kafka依赖Zookeeper.Zookeeper安装上一篇博客已经介绍过了. 1. Kaf ...
- Kafka,Mq,Redis作为消息队列使用时的差异?
redis 消息推送(基于分布式 pub/sub)多用于实时性较高的消息推送,并不保证可靠.其他的mq和kafka保证可靠但有一些延迟(非实时系统没有保证延迟).redis-pub/sub断电就清空, ...
- 用IBM MQ中间件开发碰到的MQRC_NOT_AUTHORIZED(2035)问题
我在一台工作站上面部署了MQ服务器,在MQ服务器中我建立了队列管理器MQ_TEST,在该队列管理器中我建立了一个本地队列MQ_Q以及一个服务器连接通道MQ_C,MQ_C中的MCA用户标识默认为空.同时 ...
- MQ中间件选型
如果Java项目,数据量不大,用ActiveMQ,相对简单.支持JMS. 如果对性能.可靠性有一定要求,用RabbitMQ. 如果对性能有很高要求,甚至可牺牲一些可靠性,选kakfa. 在当前大数据时 ...
随机推荐
- lombok常用注解
简介: Lombok能以简单的注解形式来简化java代码,提高开发人员的开发效率.例如开发中经常需要写的javabean,都需要花时间去添加相应的getter/setter,也许还要去写构造器.equ ...
- hdu 1695 GCD(容斥)
题目链接 #include <bits/stdc++.h> using namespace std; typedef long long ll; inline int read() { , ...
- socket模拟服务器,客户端下载东西(ftp)
服务端(ftp_server.py) import hashlib,socket,os server = socket.socket() server.bind(("localhost&qu ...
- centos 7 安装pip和pip3
首先安装epel扩展源: yum -y install epel-release 更新完成之后,就可安装pip: yum -y install python-pip 安装完成之后清除cache: yu ...
- 排序算法(C语言+Python版)宝宝再也不怕面试官写排序算法了
直接插入排序 过程: 1. 数据可分看成两个部分,前面的数据是有序的 2. 从后面的数据取出一个元素,插到前面有序数据的合适位置 从右端开始查找,到找到比此元素大的时候,则此元素向后移动,以空出多余的 ...
- 解决“程序包管理器控制台”输入命令找不到Nuget包问题
问题: 问题原因: Nuget源的地址上不去 解决办法: 1.将Nuget源更新为可以国内使用的官方Nuget源. 1)打开VS2013:工具-->Nuget程序包管理器-->程序包管理器 ...
- MySQL57修改root密碼
之前在電腦里安裝了MySQL57之后,一直沒用,卻忘記了root密碼, 在網上找了一些資料修改root密碼,卻一直出錯.直到試到這個: 用管理員權限打開CMD CD C:\Program Files\ ...
- kafka基础四
消费者消费过程(二) 消费组状态机:消息的产生存储消费看似是杂乱无章的,但万物都会遵循一定的规则成长,任何事物的发展都是有迹可循的. 开始消费组初始状态为Stable,经过第一次Rebalance之后 ...
- hdoj薛猫猫杯程序设计网络赛1003 球球大作战
思路: 二分,check函数不是很好写. 实现: 1. #include <bits/stdc++.h> using namespace std; typedef long long ll ...
- Sass基本特性
Sass扩展/继承@extend 代码的继承,声明方式:.class;调用方式:@extend 如: .btn { border: 1px solid #ccc; padding: 6px 10px; ...