针对初学者的A*算法入门详解(附带Java源码)
英文题目,汉语内容,有点挂羊头卖狗肉的嫌疑,不过请不要打击我这颗想学好英语的心。当了班主任我才发现大一18本书,11本是英语的,能多用两句英语就多用,个人认为这样也是积累的一种方法。
Thanks open source pioneers dedicated to computer science especially A*.
一、算法简介
为什么写这个,以前学长就用这个结合MFC做了个小游戏,分为三个等级“弱智,一般,大神”,分别采用不同算法来寻找迷宫出口,其中大神就是采用A*算法,当时感觉好神奇啊。前几天网上看到有人问A*算法,我就研究了下。下面的这部分内容估计奔走在各大高校的人工智能课上(国外的一片算法分析),很明显,笔者也不能免俗。
我知道下面不属于学术不端(没发表,结合自己的理解重新表达),现在就一起共享大神的作品吧(从图中可以看出并不是所有点都搜索一遍才找到了路径,给图片的目的是为了直观理解,以后忘记的话,看看图片也就记起来算法了,作为一名中共党员,笔者只信仰马克思主义,实践检验真理的唯一标准)。
我们假设某个人要从A点到达B点,而一堵墙把这两个点隔开了,如下图所示,绿色部分代表起点A,红色部分代表终点B,蓝色方块部分代表之间的墙。
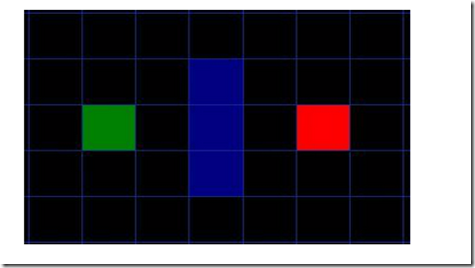

你首先会注意到我们把这一块搜索区域分成了一个一个的方格(如果地图特别大,类似稀疏矩阵的话就要结合数据结构的稀疏矩阵了,划分大块,不过没遇到过例子,不会),如此这般,使搜索区域简单化,正是寻找路径的第一步。这种方法将我们的搜索区域简化成了一个普通的二维数组。数组中的每一个元素表示对应的一个方格,该方格的状态被标记为可通过的和不可通过的。通过找出从A点到B点所经过的方格,就能得到AB之间的路径。当路径找出来以后,这个人就可以从一个格子中央移动到另一个格子中央,直到抵达目的地。 这些格子的中点叫做节点。当你在其他地方看到有关寻找路径的东西时,你会经常发现人们在讨论节点。为什么不直接把它们称作方格呢?因为你不一定要把你的搜索区域分隔成方块(感觉高大上),矩形、六边形或者其他任何形状都可以。况且节点还有可能位于这些形状内的任何一处呢(这句不懂,莫非是每个大块提前做一些预处理)?在中间、靠着边,或者什么的。我们就用这种设定,因为毕竟这是最简单的情况。
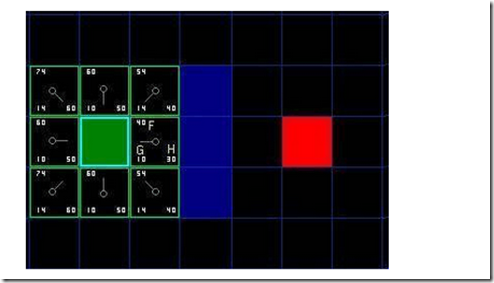
开始搜索,当我们把搜索区域简化成一些很容易操作的节点后,下一步就要构造一个搜索来寻找最短路径。在A*算法中,我们从A点开始,依次检查它的相邻节点,然后照此继续并向外扩展直到找到目的地。 从A点开始,将A点加入一个专门存放待检验的方格的“开放列表”中。这个开放列表有点像一张购物清单。当前这个列表中只有一个元素(个人感觉可以不加),但一会儿将会有更多。列表中包含的方格可能会是你要途经的方格,也可能不是。总之,这是一个包含待检验方格的列表。检查起点A相邻的所有可达的或者可通过的方格,不用管墙啊,水啊,或者其他什么无效地形,把它们也都加到开放列表中(这句话我很不认同,可能我理解错了,看我代码你会发现,我最外圈加了一圈1,表示墙壁,遇到墙壁就继续找其他相邻节点,并没有加入openTable)。对于每一个相邻方格,将点A保存为它们的“父方格”(类似最短路径算法打印路径,当然你可以选择严蔚敏老师的三维数组保存路径法,关于SP问题请参考笔者的(包括四大算法)http://www.cnblogs.com/hxsyl/p/3270401.html)。当我们要回溯路径的时候,父方格是一个很重要的元素。从开放列表中去掉方格A,并把A加入到一个“封闭列表”中。封闭列表存放的是你现在不用再去考虑的方格(说的很清楚,只是暂时不用考虑,如果不进行二次判断(指的是重新拿出来这个点来更新周边)的话,干嘛要closeTable,所以笔者认为不要光看理论,想一下实际情况,很多问题就会豁然开朗)。此时你将得到如图所示的样子。在这张图中,中间深绿色的方格是你的起始方格,所有相邻方格目前都在开放列表中,并且以亮绿色描边。每个相邻方格有一个灰色的指针指向它们的父方格,即起始方格。然后排序找到G最小的点作为下次起点。
下面还有很多,感觉不必赘述,随便百度一下都有的。
二、算法描述
1: //这段伪代码可以看出个大概,但是不完全,知道意思就行
2: while (Open表非空) {
3: 从Open中取得一个节点X,并从OPEN表中删除。
4: if (X是目标节点) {
5: 求得路径PATH;
6: 返回路径PATH;
7: }
8: for (每一个X的子节点Y) {
9: if (Y不在OPEN表和CLOSE表中) {
10: 求Y的估价值;
11: 并将Y插入OPEN表中;
12: }else if (Y在OPEN表中) {
13: if (Y的估价值小于OPEN表的估价值)
14: 更新OPEN表中的估价值;
15: }
16: else {//Y在CLOSE表中
17: if (Y的估价值小于CLOSE表的估价值) {
18: 更新CLOSE表中的估价值;
19: 从CLOSE表中移出节点,并放入OPEN表中;
20: }
21: }
22: }
23: 将X节点插入CLOSE表中;
24: 按照估价值将OPEN表中的节点排序;
25: }
三、算法Java实现
看了两天,感觉很简单,真正写的时候你会发现有多蛋疼,如果你是个爱思考的人,估计问题更多。
1: package util;
2:
3: import java.util.ArrayList;
4: import java.util.Collections;
5: import java.util.Stack;
6:
7: public class AstarPathFind {
8: // 前四个是上下左右,后四个是斜角
9: public final static int[] dx = { 0, -1, 0, 1, -1, -1, 1, 1 };
10: public final static int[] dy = { -1, 0, 1, 0, 1, -1, -1, 1 };
11:
12: // 最外圈都是1表示不可通过
13: final static public int[][] map = {
14: { 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1 },
15: { 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1 },
16: { 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1 },
17: { 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1 },
18: { 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1 },
19: { 1, 0, 0, 0, 0, 1, 1, 1, 1, 1, 0, 0, 0, 0, 1 },
20: { 1, 0, 0, 0, 0, 1, 0, 0, 0, 1, 0, 0, 0, 0, 1 },
21: { 1, 0, 0, 0, 0, 1, 0, 0, 0, 1, 0, 0, 0, 0, 1 },
22: { 1, 0, 0, 0, 0, 1, 0, 0, 0, 1, 0, 0, 0, 0, 1 },
23: { 1, 0, 0, 0, 0, 1, 1, 0, 1, 1, 0, 0, 0, 0, 1 },
24: { 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1 },
25: { 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1 },
26: { 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1 },
27: { 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1 },
28: { 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1 } };
29:
30: public static void main(String[] args) {
31: // TODO Auto-generated method stub
32: Point start = new Point(1, 1);
33: Point end = new Point(10, 13);
34: /*
35: * 第一个问题:起点FGH需要初始化吗?
36: * 看参考资料的图片发现不需要
37: */
38: Stack<Point> stack = printPath(start, end);
39: if(null==stack) {
40: System.out.println("不可达");
41: }else {
42: while(!stack.isEmpty()) {
43: //输出(1,2)这样的形势需要重写toString
44: System.out.print(stack.pop()+" -> ");
45: }
46: System.out.println();
47: }
48:
49: }
50:
51: public static Stack<Point> printPath(Point start, Point end) {
52:
53: /*
54: * 不用PriorityQueue是因为必须取出存在的元素
55: */
56: ArrayList<Point> openTable = new ArrayList<Point>();
57: ArrayList<Point> closeTable = new ArrayList<Point>();
58: openTable .clear();
59: closeTable.clear();
60: Stack<Point> pathStack = new Stack<Point>();
61: start.parent = null;
62: //该点起到转换作用,就是当前扩展点
63: Point currentPoint = new Point(start.x, start.y);
64: //closeTable.add(currentPoint);
65: boolean flag = true;
66:
67: while(flag) {
68: for (int i = 0; i < 8; i++) {
69: int fx = currentPoint.x + dx[i];
70: int fy = currentPoint.y + dy[i];
71: Point tempPoint = new Point(fx,fy);
72: if (map[fx][fy] == 1) {
73: // 由于边界都是1中间障碍物也是1,,这样不必考虑越界和障碍点扩展问题
74: //如果不设置边界那么fx >=map.length &&fy>=map[0].length判断越界问题
75: continue;
76: } else {
77: if(end.equals(tempPoint)) {
78: flag = false;
79: //不是tempPoint,他俩都一样了此时
80: end.parent = currentPoint;
81: break;
82: }
83: if(i<4) {
84: tempPoint.G = currentPoint.G + 10;
85: }else {
86: tempPoint.G = currentPoint.G + 14;
87: }
88: tempPoint.H = Point.getDis(tempPoint,end);
89: tempPoint.F = tempPoint.G + tempPoint.H;
90: //因为重写了equals方法,所以这里包含只是按equals相等包含
91: //这一点是使用java封装好类的关键
92: if(openTable.contains(tempPoint)) {
93: int pos = openTable.indexOf(tempPoint );
94: Point temp = openTable.get(pos);
95: if(temp.F > tempPoint.F) {
96: openTable.remove(pos);
97: openTable.add(tempPoint);
98: tempPoint.parent = currentPoint;
99: }
100: }else if(closeTable.contains(tempPoint)){
101: int pos = closeTable.indexOf(tempPoint );
102: Point temp = closeTable.get(pos);
103: if(temp.F > tempPoint.F) {
104: closeTable.remove(pos);
105: openTable.add(tempPoint);
106: tempPoint.parent = currentPoint;
107: }
108: }else {
109: openTable.add(tempPoint);
110: tempPoint.parent = currentPoint;
111: }
112:
113: }
114: }//end for
115:
116: if(openTable.isEmpty()) {
117: return null;
118: }//无路径
119: if(false==flag) {
120: break;
121: }//找到路径
122: openTable.remove(currentPoint);
123: closeTable.add(currentPoint);
124: Collections.sort(openTable);
125: currentPoint = openTable.get(0);
126:
127: }//end while
128: Point node = end;
129: while(node.parent!=null) {
130: pathStack.push(node);
131: node = node.parent;
132: }
133: return pathStack;
134: }
135: }
136:
137: class Point implements Comparable<Point>{
138: int x;
139: int y;
140: Point parent;
141: int F, G, H;
142:
143: public Point(int x, int y) {
144: super();
145: this.x = x;
146: this.y = y;
147: this.F = 0;
148: this.G = 0;
149: this.H = 0;
150: }
151:
152: @Override
153: public int compareTo(Point o) {
154: // TODO Auto-generated method stub
155: return this.F - o.F;
156: }
157:
158: @Override
159: public boolean equals(Object obj) {
160: Point point = (Point) obj;
161: if (point.x == this.x && point.y == this.y)
162: return true;
163: return false;
164: }
165:
166: public static int getDis(Point p1, Point p2) {
167: int dis = Math.abs(p1.x - p2.x) * 10 + Math.abs(p1.y - p2.y) * 10;
168: return dis;
169: }
170:
171: @Override
172: public String toString() {
173: return "(" + this.x + "," + this.y + ")";
174: }
175:
176: }
177: /*
178: 成功了,我在想找到的一定是最佳路线么,别告诉我因为每次取最佳点,我的意思是可能8次每循环完就break了,男刀这是不同路径的最佳路线
179: */
180:
四、结束语
大神提到,不管地图差异的话,主要是排序耽误时间,可考虑二叉堆(大神和我想法一样,哈哈),实际就是堆排序(不太清楚的请参考博主这篇博文http://www.cnblogs.com/hxsyl/p/3244756.html),不过这都不是咱么考虑的问题啦。。。。。好啦,洗洗该去上听力课了。
针对初学者的A*算法入门详解(附带Java源码)的更多相关文章
- SpringBoot Profile使用详解及配置源码解析
在实践的过程中我们经常会遇到不同的环境需要不同配置文件的情况,如果每换一个环境重新修改配置文件或重新打包一次会比较麻烦,Spring Boot为此提供了Profile配置来解决此问题. Profile ...
- 《Android NFC 开发实战详解 》简介+源码+样章+勘误ING
<Android NFC 开发实战详解>简介+源码+样章+勘误ING SkySeraph Mar. 14th 2014 Email:skyseraph00@163.com 更多精彩请直接 ...
- Android中Canvas绘图基础详解(附源码下载) (转)
Android中Canvas绘图基础详解(附源码下载) 原文链接 http://blog.csdn.net/iispring/article/details/49770651 AndroidCa ...
- Android事件传递机制详解及最新源码分析——ViewGroup篇
版权声明:本文出自汪磊的博客,转载请务必注明出处. 在上一篇<Android事件传递机制详解及最新源码分析--View篇>中,详细讲解了View事件的传递机制,没掌握或者掌握不扎实的小伙伴 ...
- 【详解】ThreadPoolExecutor源码阅读(三)
系列目录 [详解]ThreadPoolExecutor源码阅读(一) [详解]ThreadPoolExecutor源码阅读(二) [详解]ThreadPoolExecutor源码阅读(三) 线程数量的 ...
- 【详解】ThreadPoolExecutor源码阅读(二)
系列目录 [详解]ThreadPoolExecutor源码阅读(一) [详解]ThreadPoolExecutor源码阅读(二) [详解]ThreadPoolExecutor源码阅读(三) AQS在W ...
- 【详解】ThreadPoolExecutor源码阅读(一)
系列目录 [详解]ThreadPoolExecutor源码阅读(一) [详解]ThreadPoolExecutor源码阅读(二) [详解]ThreadPoolExecutor源码阅读(三) 工作原理简 ...
- JPA入门案例详解(附源码)
1.新建JavaEE Persistence项目
- 数据挖掘Aprior算法详解及c++源码
[算法大致描述] Aprior算法主要有两个操作,扫描数据库+统计.计算每一阶频繁项集都要扫描一次数据库并且统计出满足支持度的n阶项集. [算法主要步骤] 一.频繁一项集 算法开始第一步,通过扫描数据 ...
随机推荐
- java 集合(ArrayList)
ArrayList: ------------|Collection 单列集合的跟接口 ----------------------|List 有序,可重复. ------------------- ...
- 使用TCP/IP的套接字(Socket)进行通信
http://www.cnblogs.com/mengdd/archive/2013/03/10/2952616.html 使用TCP/IP的套接字(Socket)进行通信 套接字Socket的引入 ...
- 八大排序算法的 Python 实现
转载: 八大排序算法的 Python 实现 本文用Python实现了插入排序.希尔排序.冒泡排序.快速排序.直接选择排序.堆排序.归并排序.基数排序. 1.插入排序 描述 插入排序的基本操作就是将一个 ...
- #Javascript:this用法整理
常用Javascript的人都知道,[this這個關鍵字在一個函式內究竟指向誰]的這個問題很令人頭大,本人在這裡整理了一下Javascript中this的指向的五種不同情況,其中前三種屬於基本的情況, ...
- Django数据库设置
设置数据库,创建您的第一个模型,得到一个简单介绍 Django的自动生成管理网站. 数据库设置 现在,打开 mysite / settings.py . 这是一个普通的Python模块 模块级变量代表 ...
- robotframework笔记23
远程库接口 远程库接口提供了对在测试库 比机器人框架本身是在不同的机器上运行, 同时实现图书馆使用其他语言比 本机支持Python和Java. 为一个测试库用户远程 library看起来几乎一样的其他 ...
- JavaWeb基础: 会话技术简介
会话技术 用户使用Web应用的过程实际是调用了一系列的Servlet来组合处理请求,从而完成整个业务流.不同Servlet组合起来为用户服务的时候就会遇到一个数据共享和传输的问题,如何让多个Servl ...
- App开发
设置App图标 在Assets.xcassets的AppIcon中添加图片. 设置App名称 工程 -> Info -> 添加Key:“Bundle Display Name“ 和 Val ...
- Android res/目录下子目录详解
Directory Resource Type animator/ XML files that define property animations. anim/ XML files that de ...
- 使用 Fresco加载图片
概念: ImagePipeline ——负责从网络.本地图片.Content Provider(内容提供者)或者本地资源那里获取图片,压缩保存在本地存储中和在内存中保存为压缩的图片 Drawee——处 ...