论文选读二:Multi-Passage Machine Reading Comprehension with Cross-Passage Answer Verification
论文选读二:Multi-Passage Machine Reading Comprehension with Cross-Passage Answer Verification
目前,阅读理解通常会给出一段背景资料,据此提出问题,而问题的答案也往往在背景资料里。不过背景资料一般是一篇文章,或者是文章的一个段落。而对于多篇文章,特别是多篇相近文章时,当前的模型效果就不那么明显了。本文即针对此问题提出的解决方案。此文提出的模型包含三个部分:答案提取模块,答案评价模块,与答案交叉验证模块。
本文提出一个假设:问题的正确答案往往会出现在多篇文章中,且有通性,而不正确的答案则通常会与众不同。
(这个场景正对应我们平常在搜索引擎中的搜索。当键入我们想要找的内容,会命中很多内容,而通常其中只有一项是我们真正需要的,因此我们会多个答案对比,从而找到最终想要的。)
本文提出的模型即基于这个假设。当提出一个问题后,有多篇文章命中,或者说针对多篇文章提出一个问题,首先分别在每篇文章中提取回答,即确定候选回答在文章中的位置;其次, 用打分函数对每个答案进行打分,即对每个候选回答的内容进行评价,最后,再对比每个回答,让每个回答相互验证。这三步会共同决定最终的答案。
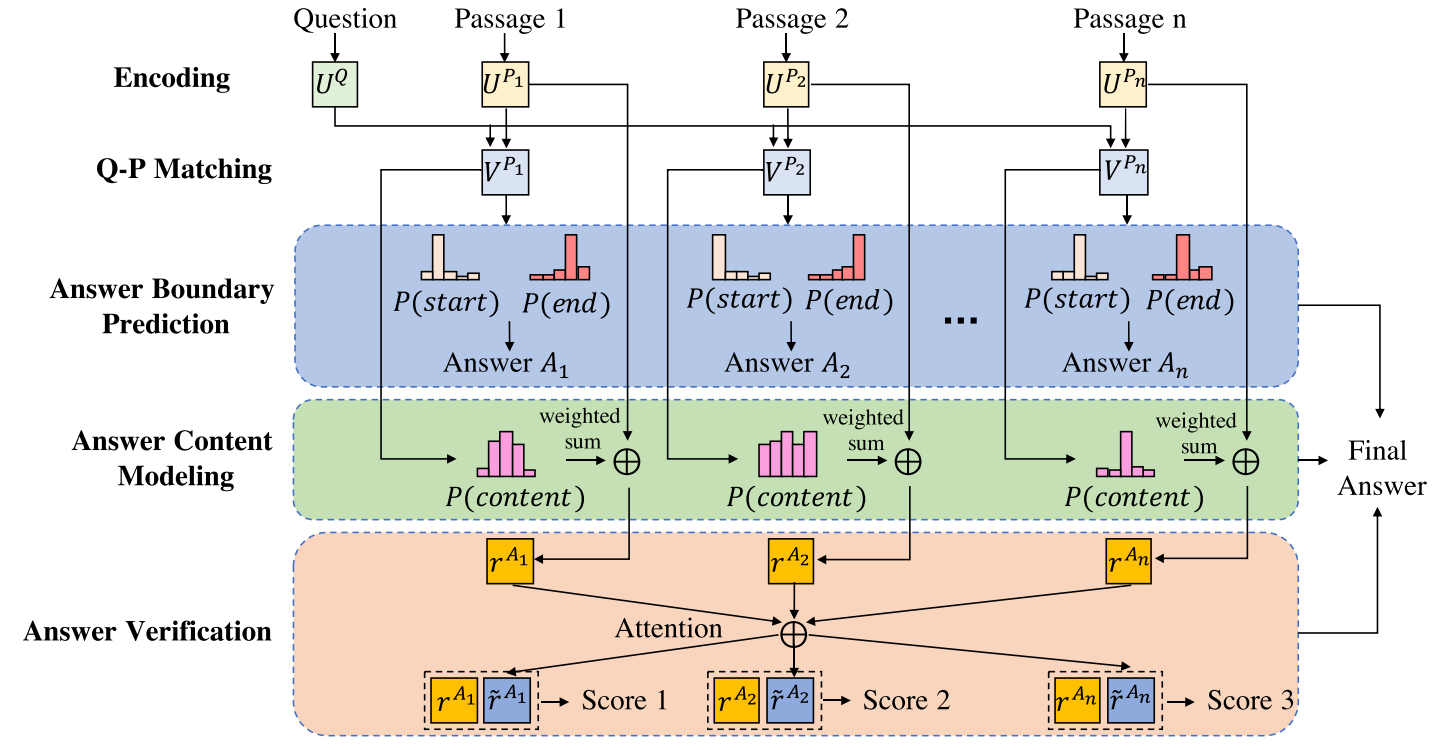
对于给定的问题Q与对应的文章集\(\{P_i\}\),我们希望找到Q最恰当的答案。
第一个模块:
编码:将所有单词向量化(主要是字符向量和与词向量拼接),然后,用biLSTM处理问题与文章集:
\[
u_t^Q = BiLSTM_Q(u_{t-1}^Q, [e_t^Q, c_t^Q])\\
u_t^{P_i} = BiLSTM_P(u_{t-1}^{P_i},[e_t^{P_i},c_t^{P_i}])
\]
其中\(e_t, c_t\)分别是第t个词的词向量与字符向量,可以看出,每篇文章是单独训练的。
Q-P Matching: 接下来将Q 与Ps联系起来,目前来说,就一定是context-to-question attention layer了。 这里使用的是attention flow layer产生一个混淆矩阵:
\[
S_{t,k} = u_t^{Q^T}\cdot u_k^{P_i}
\]
接下来按 Seo et al的方法得到 c2q attention:
\[
a_t = softmax(S_{t:})\\
\tilde{U}_{:t}^{P_i} = \sum_j a_{tj}\cdot U_{:j}^{P_i}
\]
然后,再经过一biLSTM得到新的内部表示:
\[
v^{P_i}_t = BiLSTM_M(v_{t-1}^{P_i}, \tilde{u}_t^{P_i})
\]
Answer Boundary Prediction: 有了上述的内部表示,第一个模块终于可以给出答案在文章中位置的预测了:
\[
g_k^t = w_1^{aT}\tanh (W_2^a [v_k^P, h_{t-1}^a])\\
\alpha_k^t = \exp(g_k^t)/\sum_{j =1 }^{|P|}\exp(g_j^t)\\
c_t = \sum_{k = 1}^{|P|} a_k^t\cdot v_k^P\\
h_t^a = LSTM(h_{t-1}^a,c_t)
\]
则第一部分的loss:
\[
L_{boundary} =- \frac{1}{N}\sum_{i = 1}^N (\log\alpha_{y_i^1}^1 +\log\alpha_{y_i^2}^2)
\]
其中$y_i^1,y_i^2为第i篇文章的起点与终点。
第二模块:
此模块对上一模块得到的候选答案进行评分,对每个候选答案的每个词判断其是否在应该出现在答案中:
\[
p_k^c = sigmoid(w_1^c ReLU(W_2^2v_k^{P_i}))
\]
此为第k个词出现在答案中的概率。
那损失为:
\[
L_{content} = - \frac{1}{N}\frac{1}{|P|}\sum_{i=1}^N\sum_{j = 1}^{|P|}[y_k^c \log p_k^c + (1 - y_k^c)\log(1 - p_k^c)]
\]
第三模块:
这一模块对所有候选答案进行attention,从而找到最佳答案. 每篇文章的候选答案可以这样表示:
\[
r^{A_i} = \frac{1}{|P_i|} \sum_{k = 1}^{|P_i|}p_k^c[e_k^{P_i},c_k^{P_i}]
\]
应用attention:
\[
\begin{equation}
s_{i,j} = \left\{
\begin{array}{lr}
0, \ \ \ \ if\ \ i = j, & \\
r^{A_i^T}\cdot r^{A_j}, \ \ \ \ otherwise, &
\end{array}
\right.
\end{equation}
\\
\alpha_{i,j} = \exp(s_{i,j})/\sum_{k = 1}^n \exp(s_{i,k})\\
\tilde{r}^{A_i} = \sum_{j = 1}^n \alpha_{i,j}^{A_j}\\
p_i^v = \exp(g_i^v)/ \sum_{j = 1}^n \exp(g_j^v)\\
L_{verify} = -\frac{1}{N}\sum_{i = 1}^N\log p_{y_i^v}^v
\]
最后,整个模型的损失:
\[
L = L_{boundary} + \beta_1 L_{content} + \beta_2 L_{verify}
\]
其中\(\beta_1, \beta_2\)为超参。
评:
本文对多篇文章的阅读理解,使用attention的方式选择是最优答案,是一个不错的思路。
论文选读二:Multi-Passage Machine Reading Comprehension with Cross-Passage Answer Verification的更多相关文章
- 机器阅读理解综述Neural Machine Reading Comprehension Methods and Trends(略读笔记)
标题:Neural Machine Reading Comprehension: Methods and Trends 作者:Shanshan Liu, Xin Zhang, Sheng Zhang, ...
- Attention-over-Attention Neural Networks for Reading Comprehension论文总结
Attention-over-Attention Neural Networks for Reading Comprehension 论文地址:https://arxiv.org/pdf/1607.0 ...
- Cognitive Graph for Multi-Hop Reading Comprehension at Scale(ACL2019) 阅读笔记与源码解析
论文地址为:Cognitive Graph for Multi-Hop Reading Comprehension at Scale github地址:CogQA 背景 假设你手边有一个维基百科的搜索 ...
- HDU4990 Reading comprehension —— 递推、矩阵快速幂
题目链接:https://vjudge.net/problem/HDU-4990 Reading comprehension Time Limit: 2000/1000 MS (Java/Others ...
- hdu-4990 Reading comprehension(快速幂+乘法逆元)
题目链接: Reading comprehension Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 32768/32768 K ( ...
- 【LaTeX排版】LaTeX论文排版<二>
1.目录的生成 直接使用命令\tableofcontents即可.其默认格式如下: 我们会发现,这样的格式不一定是我们所期望的.比如说,我们也希望章标题与页码之间也有点连线,并且也希望将致谢. ...
- 机器学习---逻辑回归(二)(Machine Learning Logistic Regression II)
在<机器学习---逻辑回归(一)(Machine Learning Logistic Regression I)>一文中,我们讨论了如何用逻辑回归解决二分类问题以及逻辑回归算法的本质.现在 ...
- hdu 4990 Reading comprehension 二分 + 快速幂
Description Read the program below carefully then answer the question. #pragma comment(linker, " ...
- 转:Google论文之二----Google文件系统(GFS)翻译学习
文章来自于:http://www.cnblogs.com/geekma/archive/2013/06/09/3128372.html 摘要 我们设计并实现了Google文件系统,它是一个可扩展的分布 ...
随机推荐
- OO第二次博客作业—17373247
OO第二次博客作业 零.写在前面 OO第二单元宣告结束,在这个单元里自己算是真正对面向对象编程产生了比较深刻的理解,也认识到了一个合理的架构为编程带来的极大的便利. (挂三次评测分数 看出得分接近等差 ...
- vue-cli配置
转载--https://www.cnblogs.com/caideyipi/p/8187656.html 手撕vue-cli配置文件——config篇 最近一直在研究webpack,突然想看看vu ...
- golang从文件按行读取并输出
package main import ( "fmt" "os" "bufio" "io" "time&quo ...
- replace用法替换实例
实例一: 待处理字符串:str="display=test name=mu display=temp" 要求:把display=后的值都改成localhost JS处理方法: st ...
- ThreadLocal的意义和实现
可以想像,如果一个对象的可变的变量被多个线程访问时,必然是不安全的. 在单线程应用可能会维持一个全局的数据库连接,并在程序启动时初始化这个连接对象,从而避免在调用每个方法时都传递一个Connectio ...
- CSDN去广告插件
因为避免不了与代码打交道,所以经常要上网搜代码,一般搜索到的资源都指向了CSDN,然而,好好的一篇博文,上面有很多广告,看着很不舒服,冲vip是不可能的,穷的的要死,怎么办呢?写个插件把! 去广告原理 ...
- ng/cli uses yarn as the package manager
Switch to working directory Excuting the following command ng config cli.packageManager yarn
- SQL Server監控与診斷
僅為記錄工作中遇到的問題. 1. 字符串截斷: SQL server里很多job用於運行DTS,經常會收到系統出錯警報,如: ...String ) The statement has been te ...
- 连接MySQL报错The server time zone value 'Öйú±ê׼ʱ¼ä' is unrecognized or represents more than one time zone.
MySQL time zone 时区错误 使用root用户登陆执行命令: ---> show variables like '%time_zone%'; 默认值system为美国时间:如下图: ...
- Vue-admin工作整理(十): Vuex-Actions(模拟接口请求实现组件字段更新)
思路:通过提交一个 mutation,而不是直接变更状态,它可以包括异步操作,通过请求接口,定义一个方法,第一个参数为对象,在里面能够提取到一些东西,比如:commit,这是一个方法,调用这个comm ...