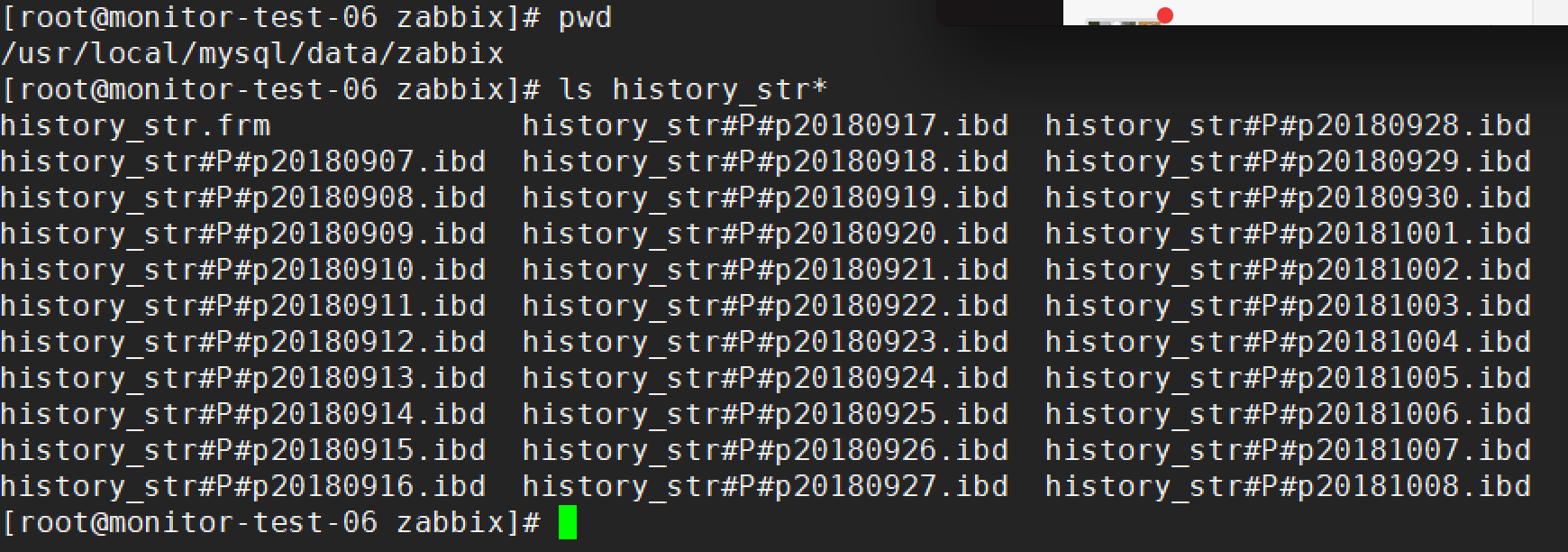
前提条件是主从同步操作完成(主从同步的前提是两个数据库表结构必须一样)
先看一下mysql配置文件
vi /usr/local/mysql/my.cnf
配置内容:------------------------------------------------------------------------------------
[client]
port=3306
socket=/tmp/mysql.sock
default-character-set=utf8
[mysql]
no-auto-rehash
#default-storage-engine=INNODB
default-character-set=utf8
[mysqld]
user = mysql
port = 3306
basedir = /usr/local/mysql
datadir = /usr/local/mysql/data
socket = /tmp/mysql.sock
pid-file = /usr/local/mysql/data/mysql3306.pid
log-error= /usr/local/mysql/logs/error.log
skip_name_resolve = 1
open_files_limit = 65535
back_log = 1024
max_connections = 1500
max_connect_errors = 1000000
table_open_cache = 1024
table_definition_cache = 1024
table_open_cache_instances = 64
thread_stack = 512K
external-locking = FALSE
max_allowed_packet = 32M
sort_buffer_size = 16M
join_buffer_size = 16M
thread_cache_size = 2250
query_cache_size = 0
query_cache_type = 0
interactive_timeout = 600
wait_timeout = 600
tmp_table_size = 96M
max_heap_table_size = 96M
sql_mode=STRICT_TRANS_TABLES,NO_ZERO_IN_DATE,NO_ZERO_DATE,ERROR_FOR_DIVISION_BY_ZERO,NO_AUTO_CREATE_USER,NO_ENGINE_SUBSTITUTION
event_scheduler=ON
###***slowqueryparameters
long_query_time = 0.1
slow_query_log = 1
slow_query_log_file = /usr/local/mysql/logs/slow.log
###***binlogparameters
log-bin=mysql-bin
binlog_cache_size=4M
max_binlog_cache_size=8M
max_binlog_size=1024M
binlog_format=MIXED
expire_logs_days=7
###***master-slavereplicationparameters
server-id=1
binlog-do-db=zabbix #只同步zabbix数据库
innodb_buffer_pool_size = 128M
innodb_flush_method = O_DIRECT
innodb_file_per_table = 1
#slave-skip-errors=all
[mysqldump]
quick
max_allowed_packet=32M
配置文件下载:https://pan.baidu.com/s/1Qd5oWsAQYESzn3pne8yBkg 密码:wanb
首先删除表
use zabbix
drop table history;
drop table history_text;
drop table history_log;
drop table history_str;
drop table history_uint;
drop table trends;
drop table trends_uint;
新建数据表
范例:(1471910400)==(UNIX_TIMESTAMP("2017-04-01 00:00:00"))
注意:时间设置为自修改日期到月底。
执行以下操作新建表:
CREATE TABLE `history` (
`itemid` bigint(20) unsigned NOT NULL,
`clock` int(11) NOT NULL DEFAULT '0',
`value` double(16,4) NOT NULL DEFAULT '0.0000',
`ns` int(11) NOT NULL DEFAULT '0',
KEY `history_1` (`itemid`,`clock`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8
PARTITION BY RANGE (`clock`)
(PARTITION p20171101 VALUES LESS THAN (UNIX_TIMESTAMP("2017-11-1 23:59:00")) ENGINE = InnoDB,
PARTITION p20171102 VALUES LESS THAN (UNIX_TIMESTAMP("2017-11-2 23:59:00")) ENGINE = InnoDB,
PARTITION p20171103 VALUES LESS THAN (UNIX_TIMESTAMP("2017-11-3 23:59:00")) ENGINE = InnoDB,
PARTITION p20171104 VALUES LESS THAN (UNIX_TIMESTAMP("2017-11-4 23:59:00")) ENGINE = InnoDB,
PARTITION p20171105 VALUES LESS THAN (UNIX_TIMESTAMP("2017-11-5 23:59:00")) ENGINE = InnoDB,
PARTITION p20171106 VALUES LESS THAN (UNIX_TIMESTAMP("2017-11-6 23:59:00")) ENGINE = InnoDB,
PARTITION p20171107 VALUES LESS THAN (UNIX_TIMESTAMP("2017-11-7 23:59:00")) ENGINE = InnoDB,
PARTITION p20171108 VALUES LESS THAN (UNIX_TIMESTAMP("2017-11-8 23:59:00")) ENGINE = InnoDB,
PARTITION p20171109 VALUES LESS THAN (UNIX_TIMESTAMP("2017-11-9 23:59:00")) ENGINE = InnoDB,
PARTITION p20171110 VALUES LESS THAN (UNIX_TIMESTAMP("2017-11-10 23:59:00")) ENGINE = InnoDB,
PARTITION p20171111 VALUES LESS THAN (UNIX_TIMESTAMP("2017-11-11 23:59:00")) ENGINE = InnoDB,
PARTITION p20171112 VALUES LESS THAN (UNIX_TIMESTAMP("2017-11-12 23:59:00")) ENGINE = InnoDB,
PARTITION p20171113 VALUES LESS THAN (UNIX_TIMESTAMP("2017-11-13 23:59:00")) ENGINE = InnoDB,
PARTITION p20171114 VALUES LESS THAN (UNIX_TIMESTAMP("2017-11-14 23:59:00")) ENGINE = InnoDB,
PARTITION p20171115 VALUES LESS THAN (UNIX_TIMESTAMP("2017-11-15 23:59:00")) ENGINE = InnoDB,
PARTITION p20171116 VALUES LESS THAN (UNIX_TIMESTAMP("2017-11-16 23:59:00")) ENGINE = InnoDB,
PARTITION p20171117 VALUES LESS THAN (UNIX_TIMESTAMP("2017-11-17 23:59:00")) ENGINE = InnoDB,
PARTITION p20171118 VALUES LESS THAN (UNIX_TIMESTAMP("2017-11-18 23:59:00")) ENGINE = InnoDB,
PARTITION p20171119 VALUES LESS THAN (UNIX_TIMESTAMP("2017-11-19 23:59:00")) ENGINE = InnoDB,
PARTITION p20171120 VALUES LESS THAN (UNIX_TIMESTAMP("2017-11-20 23:59:00")) ENGINE = InnoDB,
PARTITION p20171121 VALUES LESS THAN (UNIX_TIMESTAMP("2017-11-21 23:59:00")) ENGINE = InnoDB,
PARTITION p20171122 VALUES LESS THAN (UNIX_TIMESTAMP("2017-11-22 23:59:00")) ENGINE = InnoDB,
PARTITION p20171123 VALUES LESS THAN (UNIX_TIMESTAMP("2017-11-23 23:59:00")) ENGINE = InnoDB,
PARTITION p20171124 VALUES LESS THAN (UNIX_TIMESTAMP("2017-11-24 23:59:00")) ENGINE = InnoDB,
PARTITION p20171125 VALUES LESS THAN (UNIX_TIMESTAMP("2017-11-25 23:59:00")) ENGINE = InnoDB,
PARTITION p20171126 VALUES LESS THAN (UNIX_TIMESTAMP("2017-11-26 23:59:00")) ENGINE = InnoDB,
PARTITION p20171127 VALUES LESS THAN (UNIX_TIMESTAMP("2017-11-27 23:59:00")) ENGINE = InnoDB,
PARTITION p20171128 VALUES LESS THAN (UNIX_TIMESTAMP("2017-11-28 23:59:00")) ENGINE = InnoDB,
PARTITION p20171129 VALUES LESS THAN (UNIX_TIMESTAMP("2017-11-29 23:59:00")) ENGINE = InnoDB,
PARTITION p20171130 VALUES LESS THAN (UNIX_TIMESTAMP("2017-11-30 23:59:00")) ENGINE = InnoDB
);
。。。。。。
sql文件根据实际情况修改
链接:https://pan.baidu.com/s/1vUPTQOIAWTHRN1Y1LWnkbQ 密码:cgxx
依次创建新的表结构
修改自动分区脚本中用户名和密码,拷贝自动分区脚本到指定目录下
主从都需要添加
chmod 755 autopartitions.sh
chown mysql.mysql autopartitions.sh
3.设置后台计划任务自动分区
执行crontab -e
01 01 * * * /data/mysqldb/autopartitions.sh
脚本下载
链接:https://pan.baidu.com/s/18N8rkh2vDhltq9DVjq9EhQ 密码:7o0l
是否成功可以参考mysql配置文件中对应库文件下是否有基于日期的文件
主库
从库

- zabbix 数据库分表操作
近期zabbix数据库占用的io高,在页面查看图形很慢,而且数据表已经很大,将采用把数据库的数据目录移到新的磁盘,将几个大表进行分表操作 一.数据迁移: 1.数据同步到新的磁盘上,先停止mysql(不 ...
- MySQL数据库分表的3种方法
原文地址:MySQL数据库分表的3种方法作者:dreamboycx 一,先说一下为什么要分表 当一张的数据达到几百万时,你查询一次所花的时间会变多,如果有联合查询的话,我想有可能会死在那儿了.分表的目 ...
- Hibernate与数据库分表
数据库分片(shard)是一种在数据库的某些表变得特别大的时候采用的一种技术. 通过按照一定的维度将表切分,可以使该表在常用的检索中保持较高的效率,而那些不常用的记录则保存在低访问表中.比如:销售记录 ...
- 数据库分表之Mybatis+Mysql实践(含部分关键代码)
2018年01月31日 随着我们系统用户数量的日增,业务数据处于一个爆发前,增长的数据量已经给我们的系统造成了很大的不确定.在上个周末用户量较多,并发较大的情况下,读写频繁的验证码表,数据量 ...
- 一致性Hash算法在数据库分表中的实践
最近有一个项目,其中某个功能单表数据在可预估的未来达到了亿级,初步估算在90亿左右.与同事详细讨论后,决定采用一致性Hash算法来完成数据库的自动扩容和数据迁移.整个程序细节由我同事完成,我只是将其理 ...
- Oracle亿级数据查询处理(数据库分表、分区实战)
大数据量的查询,不仅查询速度非常慢,而且还会导致数据库经常宕机(刚接到这个项目时候,数据库经常宕机o(╯□╰)o). 那么,如何处理上亿级的数据量呢?如何从数据库经常宕机到上亿数据秒查?仅以此篇文章作 ...
- Mycat(4):消息表mysql数据库分表实践
本文的原文连接是: http://blog.csdn.net/freewebsys/article/details/46882777 未经博主同意不得转载. 1,业务需求 比方一个社交软件,比方像腾讯 ...
- MySQL数据库分表分区(一)(转)
面对当今大数据存储,设想当mysql中一个表的总记录超过1000W,会出现性能的大幅度下降吗? 答案是肯定的,一个表的总记录超过1000W,在操作系统层面检索也是效率非常低的 解决方案: 目前针对 ...
- 数据库分表和分库的原理及基于thinkPHP的实现方法
为什么要分表,分库: 当我们的数据表数据量,訪问量非常大.或者是使用频繁的时候,一个数据表已经不能承受如此大的数据訪问和存储,所以,为了减轻数据库的负担,加快数据的存储,就须要将一张表分成多张,及将一 ...
随机推荐
- java.lang.NullPointerException一个低级的解决方法
java.lang.NullPointerException 这次因为调用了类的方法的时候忘记了new对象了 导致该对象为空
- Page Cache与Page回写
综述 Page cache是通过将磁盘中的数据缓存到内存中,从而减少磁盘I/O操作,从而提高性能.此外,还要确保在page cache中的数据更改时能够被同步到磁盘上,后者被称为page回写(page ...
- MFC自绘菜单
自绘控件问题多多.本文以菜单为例. ①当要使用顶层菜单资源.对话框资源.状态栏资源等这3种资源的任何一种.那么CWinApp::InitInstance函数内部必须使用LoadFrame函数来加载资源 ...
- MySql 学习之路-聚合函数
下面是mysql 数据库中经常用到的聚合函数的简单实例 -- 创建学生表 create table student ( id int primary key auto_increment commen ...
- CentOS 6.9安装Python2.7.13
查看当前系统中的 Python 版本 python --version 返回 Python 2.6.6 为正常. 检查 CentOS 版本 cat /etc/redhat-release 返回 Cen ...
- jq轮播图插件—手写
<!DOCTYPE html><html lang="en"> <head> <meta charset="UTF-8" ...
- hbase 迁库移库步骤
1 将数据导出 hbase org.apache.hadoop.hbase.mapreduce.Export t_zyzx_grzyfwtjxxb /hbase/data_backup/2018103 ...
- Chrome Inspect调试微信出现404,需要FQ
要么FQ,要么买个程序 见连接 http://www.cnblogs.com/slmk/p/7591126.html
- 如何使用 IDEA 创建项目并且上传到 GitHub
在 GitHub中 注册创建账号 :https://github.com 下载安装 Git : https://git-scm.com 安装成功后打开 Git Bash,输入下列命令,设置 Git 全 ...
- 哈希长度扩展攻击(Hash Length Extension Attack)利用工具hexpand安装使用方法
去年我写了一篇哈希长度扩展攻击的简介以及HashPump安装使用方法,本来已经足够了,但HashPump还不是很完善的哈希长度扩展攻击,HashPump在使用的时候必须提供original_data, ...