day10-内置模块学习(一)
今日份目录
1.模块之间的相互调用
2.代码结构的标准化
3.os模块
4.sys模块
5.collection模块
开始今日份总结
开始今日份总结
1.模块之间的相互调用
由于一些原因,总是会调用别人的模块以及接口包括其他乱七八糟的东西,这个时候就需要了模块之间的相互调用。
引用模块相当于执行这个模块,不过重新导入会直接引用内存中已经加载好的结果。
模块被执行时发生了三件事:
- 创建一个以被导入模块的名字命名的名称空间
- 自动执行模块中的代码(将模块中的所有内容加载到内存)
- 要想执行模块中的代码必须通过模块名.的方式执行获取
1.1 模块的改名
# 1,模块名过长,引用不方便,给模块改名,简化引用。
import abcdpythonuser as ab
print(ab.age)
ab.func()
import time
print(time.time())
import time as t
print(t.time())
# 2, 优化代码。
import mysql
import orcle
db_sql = input('>>> ')
if db_sql == 'mysql':
mysql.sqlparse()
elif db_sql == 'orcle':
orcle.sqlparse() 改版
db_sql = input('>>> ')
if db_sql == 'mysql':
import mysql as db
elif db_sql == 'orcle':
import orcle as db
db.sqlparse()
1.2多个模块的引用
标准的:
import mysql
import time
import sys
不建议:
import mysql,time,os,sys
1.3其他引用
# from ..... import .....
# 执行过程:
'''
1,执行一遍tbjx的所有代码,加载到内存。
2,将name,read1这些实际引用过来的变量函数在本文件复制一份。
globals()查看
'''
from tbjx import name,read1
print(name)
read1()
# 好处:使用简单。
# 坏处:容易与本文件的变量,函数名等发生冲突。
多个导入的时候
#导入多个:
# 方式一
from tbjx import name
from tbjx import raed1
# 方式2
from tbjx import name,read1,read2 # 导入所有:
from tbjx import *
print(globals())
# 一般不用,
# 如果使用只有两点:
# 1,将导入的模块中的所有的代码全部清楚的前提下,可以使用 *。
from time import time
# 2,只是用一部分。
文件有个两个作用:
- 作为脚本,直接运行
- 作为模块供别人使用。
- __name__ == '__main__' 可以作为一个项目的启动文件用。
2.代码结构的标准化
2.1为什么设计项目目录结构
"设计项目目录结构",就和"代码编码风格"一样,属于个人风格问题。对于这种风格上的规范,一直都存在两种态度:
- 一类同学认为,这种个人风格问题"无关紧要"。理由是能让程序work就好,风格问题根本不是问题。
- 另一类同学认为,规范化能更好的控制程序结构,让程序具有更高的可读性。
我是比较偏向于后者的,因为我是前一类同学思想行为下的直接受害者。我曾经维护过一个非常不好读的项目,其实现的逻辑并不复杂,但是却耗费了我非常长的时间去理解它想表达的意思。从此我个人对于提高项目可读性、可维护性的要求就很高了。"项目目录结构"其实也是属于"可读性和可维护性"的范畴,我们设计一个层次清晰的目录结构,就是为了达到以下两点:
- 可读性高: 不熟悉这个项目的代码的人,一眼就能看懂目录结构,知道程序启动脚本是哪个,测试目录在哪儿,配置文件在哪儿等等。从而非常快速的了解这个项目。
- 可维护性高: 定义好组织规则后,维护者就能很明确地知道,新增的哪个文件和代码应该放在什么目录之下。这个好处是,随着时间的推移,代码/配置的规模增加,项目结构不会混乱,仍然能够组织良好。
所以,我认为,保持一个层次清晰的目录结构是有必要的。更何况组织一个良好的工程目录,其实是一件很简单的事儿。
2.2推荐的目录结构
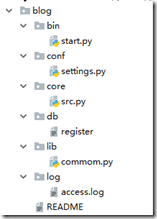
2.3 关于read me
这个我觉得是每个项目都应该有的一个文件,目的是能简要描述该项目的信息,让读者快速了解这个项目。
它需要说明以下几个事项:
- 软件定位,软件的基本功能。
- 运行代码的方法: 安装环境、启动命令等。
- 简要的使用说明。
- 代码目录结构说明,更详细点可以说明软件的基本原理。
- 常见问题说明。
我觉得有以上几点是比较好的一个README。在软件开发初期,由于开发过程中以上内容可能不明确或者发生变化,并不是一定要在一开始就将所有信息都补全。但是在项目完结的时候,是需要撰写这样的一个文档的。
可以参考Redis源码中Readme的写法,这里面简洁但是清晰的描述了Redis功能和源码结构。
3.os模块
od模块是整个代码过程中经常要使用的一个模块
#当前执行这个python文件的工作目录相关的工作路径
os.getcwd() 获取当前工作目录,即当前python脚本工作的目录路径
os.chdir("dirname") 改变当前脚本工作目录;相当于shell下cd
os.curdir 返回当前目录: ('.')
os.pardir 获取当前目录的父目录字符串名:('..') #和文件夹相关
os.makedirs('dirname1/dirname2') 可生成多层递归目录
os.removedirs('dirname1') 若目录为空,则删除,并递归到上一级目录,如若也为空,则删除,依此类推
os.mkdir('dirname') 生成单级目录;相当于shell中mkdir dirname
os.rmdir('dirname') 删除单级空目录,若目录不为空则无法删除,报错;相当于shell中rmdir dirname
os.listdir('dirname') 列出指定目录下的所有文件和子目录,包括隐藏文件,并以列表方式打印 # 和文件相关
os.remove() 删除一个文件
os.rename("oldname","newname") 重命名文件/目录
os.stat('path/filename') 获取文件/目录信息 # 和操作系统差异相关
os.sep 输出操作系统特定的路径分隔符,win下为"\\",Linux下为"/"
os.linesep 输出当前平台使用的行终止符,win下为"\t\n",Linux下为"\n"
os.pathsep 输出用于分割文件路径的字符串 win下为;,Linux下为:
os.name 输出字符串指示当前使用平台。win->'nt'; Linux->'posix' # 和执行系统命令相关
os.system("bash command") 运行shell命令,直接显示
os.popen("bash command).read() 运行shell命令,获取执行结果
os.environ 获取系统环境变量 #path系列,和路径相关
os.path.abspath(path) 返回path规范化的绝对路径
os.path.split(path) 将path分割成目录和文件名二元组返回
os.path.dirname(path) 返回path的目录。其实就是os.path.split(path)的第一个元素
os.path.basename(path) 返回path最后的文件名。如何path以/或\结尾,那么就会返回空值,即os.path.split(path)的第二个元素。
os.path.exists(path) 如果path存在,返回True;如果path不存在,返回False
os.path.isabs(path) 如果path是绝对路径,返回True
os.path.isfile(path) 如果path是一个存在的文件,返回True。否则返回False
os.path.isdir(path) 如果path是一个存在的目录,则返回True。否则返回False
os.path.join(path1[, path2[, ...]]) 将多个路径组合后返回,第一个绝对路径之前的参数将被忽略
os.path.getatime(path) 返回path所指向的文件或者目录的最后访问时间
os.path.getmtime(path) 返回path所指向的文件或者目录的最后修改时间
os.path.getsize(path) 返回path的大小
注意:os.stat('path/filename') 获取文件/目录信息 的结构说明
stat 结构: st_mode: inode 保护模式
st_ino: inode 节点号。
st_dev: inode 驻留的设备。
st_nlink: inode 的链接数。
st_uid: 所有者的用户ID。
st_gid: 所有者的组ID。
st_size: 普通文件以字节为单位的大小;包含等待某些特殊文件的数据。
st_atime: 上次访问的时间。
st_mtime: 最后一次修改的时间。
st_ctime: 由操作系统报告的"ctime"。在某些系统上(如Unix)是最新的元数据更改的时间,在其它系统上(如Windows)是创建时间(详细信息参见平台的文档)。 stat结构
4.sys模块
sys.argv 命令行参数List,第一个元素是程序本身路径
sys.exit(n) 退出程序,正常退出时exit(0),错误退出sys.exit(1)
sys.version 获取Python解释程序的版本信息
sys.path 返回模块的搜索路径,初始化时使用PYTHONPATH环境变量的值
sys.platform 返回操作系统平台名称
5.collection模块
在内置数据类型(dict、list、set、tuple)的基础上,collections模块还提供了几个额外的数据类型:Counter、deque、defaultdict、namedtuple和OrderedDict等。
1.namedtuple: 生成可以使用名字来访问元素内容的tuple
2.deque: 双端队列,可以快速的从另外一侧追加和推出对象
3.Counter: 计数器,主要用来计数
4.OrderedDict: 有序字典
5.defaultdict: 带有默认值的字典
namedtuple
我们知道tuple可以表示不变集合,例如,一个点的二维坐标就可以表示成:
>>> p = (1, 2)
但是,看到(1, 2),很难看出这个tuple是用来表示一个坐标的。
这时,namedtuple就派上了用场:
>>> from collections import namedtuple
>>> Point = namedtuple('Point', ['x', 'y'])
>>> p = Point(1, 2)
>>> p.x
>>> p.y
类似的,如果要用坐标和半径表示一个圆,也可以用namedtuple定义:
#namedtuple('名称', [属性list]):
Circle = namedtuple('Circle', ['x', 'y', 'r'])
deque
使用list存储数据时,按索引访问元素很快,但是插入和删除元素就很慢了,因为list是线性存储,数据量大的时候,插入和删除效率很低。
deque是为了高效实现插入和删除操作的双向列表,适合用于队列和栈:
>>> from collections import deque
>>> q = deque(['a', 'b', 'c'])
>>> q.append('x')
>>> q.appendleft('y')
>>> q
deque(['y', 'a', 'b', 'c', 'x'])
deque除了实现list的append()和pop()外,还支持appendleft()和popleft(),这样就可以非常高效地往头部添加或删除元素。
ordereddict
使用dict时,Key是无序的。在对dict做迭代时,我们无法确定Key的顺序。
如果要保持Key的顺序,可以用OrderedDict:
>>> from collections import OrderedDict
>>> d = dict([('a', 1), ('b', 2), ('c', 3)])
>>> d # dict的Key是无序的
{'a': 1, 'c': 3, 'b': 2}
>>> od = OrderedDict([('a', 1), ('b', 2), ('c', 3)])
>>> od # OrderedDict的Key是有序的
OrderedDict([('a', 1), ('b', 2), ('c', 3)])
注意,OrderedDict的Key会按照插入的顺序排列,不是Key本身排序:
>>> od = OrderedDict()
>>> od['z'] = 1
>>> od['y'] = 2
>>> od['x'] = 3
>>> od.keys() # 按照插入的Key的顺序返回
['z', 'y', 'x']
defaultdict
有如下值集合 [11,22,33,44,55,66,77,88,99,90...],将所有大于 66 的值保存至字典的第一个key中,将小于 66 的值保存至第二个key的值中。
即: {'k1': 大于66 , 'k2': 小于66}
li = [11,22,33,44,55,77,88,99,90]
result = {}
for row in li:
if row > 66:
if 'key1' not in result:
result['key1'] = []
result['key1'].append(row)
else:
if 'key2' not in result:
result['key2'] = []
result['key2'].append(row)
print(result) 原生字典的解决方法 from collections import defaultdict values = [11, 22, 33,44,55,66,77,88,99,90] my_dict = defaultdict(list) for value in values:
if value>66:
my_dict['k1'].append(value)
else:
my_dict['k2'].append(value) defaultdict字典解决方法
使用dict时,如果引用的Key不存在,就会抛出KeyError。如果希望key不存在时,返回一个默认值,就可以用defaultdict:
>>> from collections import defaultdict
>>> dd = defaultdict(lambda: 'N/A')
>>> dd['key1'] = 'abc'
>>> dd['key1'] # key1存在
'abc'
>>> dd['key2'] # key2不存在,返回默认值
'N/A'
counter
Counter类的目的是用来跟踪值出现的次数。它是一个无序的容器类型,以字典的键值对形式存储,其中元素作为key,其计数作为value。计数值可以是任意的Interger(包括0和负数)。Counter类和其他语言的bags或multisets很相似。
c = Counter('abcdeabcdabcaba')
print c
输出:Counter({'a': 5, 'b': 4, 'c': 3, 'd': 2, 'e': 1})
day10-内置模块学习(一)的更多相关文章
- day10 python学习 函数的嵌套命名空间作用域 三元运算 位置参数 默认参数 动态参数
1.三元运算 #1.三元运算 利用已下方法就可以实现一步运算返回a b中大的值 def my_max(a,b): c=0 a=int(input('请输入')) b=int(input('请输入')) ...
- day10 Pyhton学习
一.昨日内容回顾 函数: 定义:对功能或者动作的封装 def 函数名(形参): 函数体 函数名(实参) return: 返回,当程序运行到return的时候,终止函数的执行 一个函数一定拥有返回值 ...
- python入门灵魂5问--python学习路线,python教程,python学哪些,python怎么学,python学到什么程度
一.python入门简介 对于刚接触python编程或者想学习python自动化的人来说,基本都会有以下python入门灵魂5问--python学习路线,python教程,python学哪些,pyth ...
- python开发学习-day10(select/poll/epoll回顾、redis、rabbitmq-pika)
s12-20160319-day10 *:first-child { margin-top: 0 !important; } body>*:last-child { margin-bottom: ...
- python学习笔记之heapq内置模块
heapq内置模块位于./Anaconda3/Lib/heapq.py,提供基于堆的优先排序算法 堆的逻辑结构就是完全二叉树,并且二叉树中父节点的值小于等于该节点的所有子节点的值.这种实现可以使用 h ...
- 学习日常笔记<day10>servlet编程
1 如何开发一个Servlet 1.1 步骤: 1)编写java类,继承HttpServlet类 2)重新doGet和doPost方法 3)Servlet程序交给tomcat服务器运行!! 3.1 s ...
- python学习Day10 函数的介绍(定义、组成、使用)
今日学习内容: 1.什么是函数 :函数就是一个含有特定功能的变量,一个解决某问题的工具 函数的定义:通过关键字def + 功能名字():代码体(根据需求撰写代码逻辑) 2.为什么要用函数:可以复用:函 ...
- Python学习笔记【第八篇】:Python内置模块
什么时模块 Python中的模块其实就是XXX.py 文件 模块分类 Python内置模块(标准库) 自定义模块 第三方模块 使用方法 import 模块名 form 模块名 import 方法名 说 ...
- Python学习笔记(四十一)— 内置模块(10)urllib
摘抄自:https://www.liaoxuefeng.com/wiki/0014316089557264a6b348958f449949df42a6d3a2e542c000/001432688314 ...
- Python学习 day10
一.默认参数的陷阱 先看如下例子: def func(li=[]): li.append(1) print(li) func() func() func(li=['abc']) func() 结果: ...
随机推荐
- 优雅的启动、停止、重启你的SpringBoot项目
前言 你是如何启动.关闭你的SpringBoot项目的?还是使用java -jar xxxx.jar启动? 还在用ps -ef找到你的pid去kill你的应用吗? 让我们来看看还有什么更加优雅的一键启 ...
- Chapter 5 Blood Type——13
"Kryptonite doesn't bother me, either," he chuckled. “氪星石也不会影响我,” 他笑着说道. "You're not ...
- Session执行机制与原理
Session执行机制与原理 作者:Stanley 罗昊 [转载请注明出处和署名,谢谢!] 什么是Session 首先了解一下Session的中文意思:一次会话,什么是一次会话呢?我举个例子:就我们现 ...
- ES6躬行记(13)——类型化数组
类型化数组(Typed Array)是一种处理二进制数据的特殊数组,它可像C语言那样直接操纵字节,不过得先用ArrayBuffer对象创建数组缓冲区(Array Buffer),再映射到指定格式的视图 ...
- 我们知道CDN护航了双11十年,却不知道背后有那么多故事……
情不知如何而起,竟一往情深.恰如我们.十年前,因为相信,所以看见.十年后,就在眼前,看见一切. 当2018天猫双11成交额2135亿元的大屏上,打出这么一段字的时候,参与双11护航的阿里云CDN技术掌 ...
- IO通信模型(三)多路复用IO
多路复用IO 从非阻塞同步IO的介绍中可以发现,为每一个接入创建一个线程在请求很多的情况下不那么适用了,因为这会渐渐耗尽服务器的资源,人们也都意识到了这个 问题,因此终于有人发明了IO多路复用.最大的 ...
- 全网Star最多(近20k)的Spring Boot开源教程 2019 年要继续更新了!
从2016年1月开始写博客,默默地更新<Spring Boot系列教程>,从无人问津到千万访问,作为一个独立站点(http://blog.didispace.com),相信只有那些跟我一样 ...
- 在Windows 下如何使用 AspNetCore Api 和 consul
一.概念:什么是consul: Consul 是有多个组件组成的一个整体,作用和Eureka,Zookeeper相当,都是用来做服务的发现与治理. Consul的特性: 1. 服务的发现:consul ...
- Oracle day01 select where关键字
select关键字 作用:检索“列” 注意:1.select后面的列可以起别名(查询的显示结果) 1) 列名后面一个空格后添加别名(别名中不许有“空格”) 2) 列名后面一个空格后使用双引号添加别名 ...
- Java开发笔记(十三)利用关系运算符比较大小
前面在<Java开发笔记(九)赋值运算符及其演化>中提到,Java编程中的等号“=”表示赋值操作,并非数学上的等式涵义.Java通过等式符号“==”表示左右两边相等,对应数学的等号“=”: ...