MySQL实战45讲学习笔记:日志系统(第二讲)
一、重要的日志模块:redo log
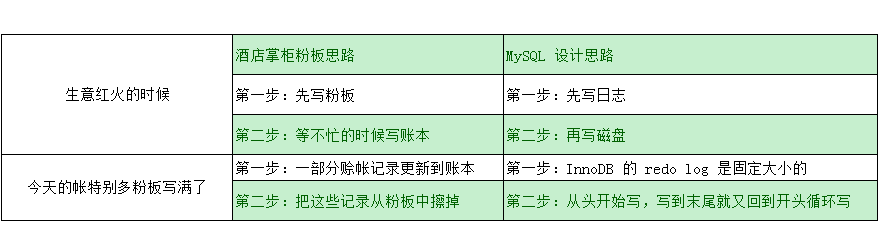
1、通过酒店掌柜记账思路刨析redo log工作原理
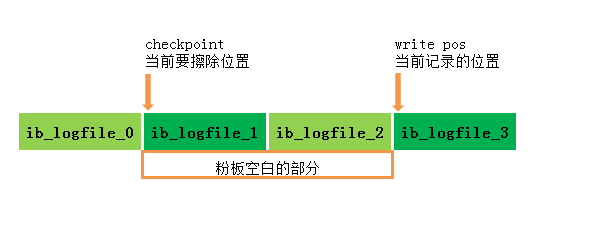
2、InnoDB 的 redo log 是固定大小的
只要赊账记录在了粉板上或写了账本上,之后即使掌柜忘记了,
比如停业几天,回复生意后依然可以通过账本和粉板上的数据明确赊账账目
有了redo log,InnoDB就可以保证即使数据库发生异常重启,之前提交的记录都不会丢失,这个能力成为crash-safe二、重要的日志模块:binlog
二、重要的日志模块binlog
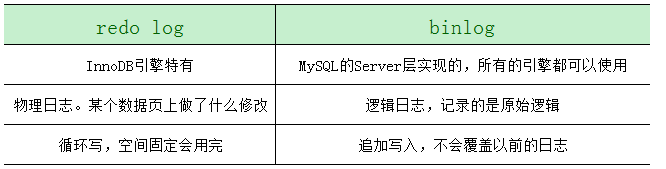
1、redo和三点区别binlog
redo是物理的,binlog是逻辑的;现在由于redo是属于InnoDB引擎,所以必须要有binlog,因为你可以使用别的引擎
2、binlog几大模式

一般采用row,因为遇到时间,从库可能会出现不一致的情况,但是row更新前后都有,会导致日志变大
最后2个参数,保证事务成功,日志必须落盘,这样,数据库crash后,就不会丢失某个事务的数据了
3、企业场景如何选择binglog:
1、互联网公司,使用MySQL的功能相对少(存储过程、触发器、函数)
选择默认的语句模式,Statement Level(默认)
2、公司如果用到使用MySQL的特殊功能(存储过程、触发器、函数)
则选择Mixed模式
3、公司如果用到使用MySQL的特殊功能(存储过程、触发器、函数)又希望数据最大化一直,此时最好选择Row level模式
4、行模式和语句模式的区别

5、 ROW模式下binlog日志记录效果
[root@db01]# mysqlbinlog --base64-output="decode-rows" --verbose mysql-bin.000248 /*!50530 SET @@SESSION.PSEUDO_SLAVE_MODE=1*/; /*!40019 SET @@session.max_insert_delayed_threads=0*/; /*!50003 SET @OLD_COMPLETION_TYPE=@@COMPLETION_TYPE,COMPLETION_TYPE=0*/; DELIMITER /*!*/; # at 4 #160628 11:06:52 server id 1 end_log_pos 107 Start: binlog v 4, server v 5.5.49-log created 160628 11:06:52 at startup # Warning: this binlog is either in use or was not closed properly. ROLLBACK/*!*/; # at 107 #160628 11:07:09 server id 1 end_log_pos 177 Query thread_id=1 exec_time=0 error_code=0 SET TIMESTAMP=1467083229/*!*/; SET @@session.pseudo_thread_id=1/*!*/; SET @@session.foreign_key_checks=1, @@session.sql_auto_is_null=0, @@session.unique_checks=1, @@session.autocommit=1/*!*/; SET @@session.sql_mode=0/*!*/; SET @@session.auto_increment_increment=1, @@session.auto_increment_offset=1/*!*/;/*!\C utf8 *//*!*/; SET @@session.character_set_client=33,@@session.collation_connection=33,@@session.collation_server=33/*!*/; SET @@session.lc_time_names=0/*!*/; SET @@session.collation_database=DEFAULT/*!*/; BEGIN /*!*/; # at 177 # at 223 #160628 11:07:09 server id 1 end_log_pos 223 Table_map: `oldboy`.`sc` mapped to number 33 #160628 11:07:09 server id 1 end_log_pos 785 Update_rows: table id 33 flags: STMT_END_F ### UPDATE `oldboy`.`sc` ### WHERE ### @1=1 ### @2=1001
三、update 语句的执行流程图
1、update语句的执行流程图
图中绿色框表示是在内粗执行,红色框表示是在执行器中执行

2、 流程说明
1.首先客户端通过tcp/ip发送一条sql语句到server层的SQL interface
2.SQL interface接到该请求后,先对该条语句进行解析,验证权限是否匹配
3.验证通过以后,分析器会对该语句分析,是否语法有错误等
4.接下来是优化器器生成相应的执行计划,选择最优的执行计划
5.之后会是执行器根据执行计划执行这条语句。在这一步会去open table,如果该table上有MDL,则等待。如果没有,则加在该表上加短暂的MDL(S),
(如果opend_table太大,表明open_table_cache太小。需要不停的去打开frm文件)
6.进入到引擎层,首先会去innodb_buffer_pool里的data dictionary(元数据信息)得到表信息
7.通过元数据信息,去lock info里查出是否会有相关的锁信息,并把这条update语句需要的锁信息写入到lock info里(锁这里还有待补充)
8.然后涉及到的老数据通过快照的方式存储到innodb_buffer_pool里的undo page里,并且记录undo log修改的redo
(如果data page里有就直接载入到undo page里,如果没有,则需要去磁盘里取出相应page的数据,载入到undo page里)
9.在innodb_buffer_pool的data page做update操作。并把操作的物理数据页修改记录到redo log buffer里
由于update这个事务会涉及到多个页面的修改,所以redo log buffer里会记录多条页面的修改信息。
因为group commit的原因,这次事务所产生的redo log buffer可能会跟随其它事务一同flush并且sync到磁盘上
10.同时修改的信息,会按照event的格式,记录到binlog_cache中。(这里注意binlog_cache_size是transaction级别的,不是session级别的参数,
一旦commit之后,dump线程会从binlog_cache里把event主动发送给slave的I/O线程)
11.之后把这条sql,需要在二级索引上做的修改,写入到change buffer page,等到下次有其他sql需要读取该二级索引时,再去与二级索引做merge
(随机I/O变为顺序I/O,但是由于现在的磁盘都是SSD,所以对于寻址来说,随机I/O和顺序I/O差距不大)
12.此时update语句已经完成,需要commit或者rollback。这里讨论commit的情况,并且双1
13.commit操作,由于存储引擎层与server层之间采用的是内部XA(保证两个事务的一致性,这里主要保证redo log和binlog的原子性),
所以提交分为prepare阶段与commit阶段
14.prepare阶段,将事务的xid写入,将binlog_cache里的进行flush以及sync操作(大事务的话这步非常耗时)
15.commit阶段,由于之前该事务产生的redo log已经sync到磁盘了。所以这步只是在redo log里标记commit
16.当binlog和redo log都已经落盘以后,如果触发了刷新脏页的操作,先把该脏页复制到doublewrite buffer里,把doublewrite buffer里的刷新到共享表空间,然后才是通过page cleaner线程把脏页写入到磁盘中
其实在实现上5是调用了6的过程了的,所以是一回事。MySQL server 层和InnoDB层都保存了表结构,所以有书上描述时会拆开说。
四、两阶段提交
1、保证数据库的一致性:
必须要保证2份日志一致,使用的2阶段式提交;其实感觉像事务,不是成功就是失败,不能让中间环节出现,也就是一个成功,一个失败
如果有一天mysql只有InnoDB引擎了,有redo来实现复制,那么感觉oracle的DG就诞生了,物理的速度也将远超逻辑的,毕竟只记录了改动向量
2、binlog能不能去掉?
老师,今天MYSQL第二讲中提到binlog和redo log, 我感觉binlog很多余,按理是不是只要redo log就够了?[费解]
一个原因是,redolog只有InnoDB有,别的引擎没有。
另一个原因是,redolog是循环写的,不持久保存,binlog的“归档”这个功能,redolog是不具备的。
3、运维同学的实战疑惑
老师您好,我之前是做运维的,通过binlog恢复误操作的数据,但是实际上,我们会后知后觉,误删除一段时间了,才发现误删除,此时,我把之前误删除的binlog导入,再把误删除之后binlog导入,会出现问题,比如主键冲突,而且binlog导数据,不同模式下时间也有不同,但是一般都是row模式,时间还是很久,有没什么方式,时间短且数据一致性强的方式
其实恢复数据只能恢复到误删之前到一刻,
误删之后的,不能只靠binlog来做,因为业务逻辑可能因为误删操作的行为,插入了逻辑错误的语句,
所以之后的,跟业务一起,从业务快速补数据的。只靠binlog补出来的往往不完整
4、怎样让数据库恢复到半个月内任意一秒的状态?
1 prepare阶段
2 写binlog
3 commit
当在2之前崩溃时
重启恢复:后发现没有commit,回滚。备份恢复:没有binlog 。一致
当在3之前崩溃
重启恢复:虽没有commit,但满足prepare和binlog完整,所以重启后会自动commit。备份:有binlog. 一致
五、思考题(同学们的经典留言)
1、Jason同学
备份时间周期的长短,感觉有2个方便
首先,是恢复数据丢失的时间,既然需要恢复,肯定是数据丢失了。如果一天一备份的话,只要找到这天的全备,加入这天某段时间的binlog来恢复,如果一周一备份,假设是周一,而你要恢复的数据是周日某个时间点,那就,需要全备+周一到周日某个时间点的全部binlog用来恢复,时间相比前者需要增加很多;看业务能忍受的程度
其次,是数据库丢失,如果一周一备份的话,需要确保整个一周的binlog都完好无损,否则将无法恢复;而一天一备,只要保证这天的binlog都完好无损;当然这个可以通过校验,或者冗余等技术来实现,相比之下,上面那点更重要
2、justd同学的形象比喻
1、一个完整的交易过程:
1、账本记上 卖一瓶可乐(redo log为 prepare状态),
2、然后收钱放入钱箱(bin log记录)
3、然后回过头在账本上打个勾(redo log置为commit)表示一笔交易结束。
2、如果收钱时交易被打断
1、回过头来整理此次交易,发现只有记账没有收钱,则交易失败,删掉账本上的记录(回滚);
2、如果收了钱后被终止,然后回过头发现账本有记录(prepare)而且钱箱有本次收入(bin log),则继续完善账本(commit),本次交易有效。
MySQL实战45讲学习笔记:日志系统(第二讲)的更多相关文章
- MySQL实战45讲学习笔记:第八讲
一.今日内容概要 我在第 3 篇文章和你讲事务隔离级别的时候提到过,如果是可重复读隔离级别,事务 T 启动的时候会创建一个视图 read-view,之后事务 T 执行期间,即使有其他事务修改了数据,事 ...
- MySQL实战45讲学习笔记:第十讲
一 .本节内容概要 前面我们介绍过索引,你已经知道了在 MySQL 中一张表其实是可以支持多个索引的.但是,你写 SQL 语句的时候,并没有主动指定使用哪个索引.也就是说,使用哪个索引是由MySQL ...
- MySQL实战45讲学习笔记:第六讲
一.今日内容概要 今天我要跟你聊聊 MySQL 的锁.数据库锁设计的初衷是处理并发问题.作为多用户共享的资源,当出现并发访问的时候,数据库需要合理地控制资源的访问规则.而锁就是用来实现这些访问规则的重 ...
- MySQL实战45讲学习笔记:第七讲
一.上节回顾今日计划 在上一篇文章中,我跟你介绍了 MySQL 的全局锁和表级锁,今天我们就来讲讲 MySQL的行锁. MySQL 的行锁是在引擎层由各个引擎自己实现的.但并不是所有的引擎都支持行锁, ...
- MySQL实战45讲学习笔记:第十七讲
一 .引子 我在上一篇文章,为你讲解完 order by 语句的几种执行模式后,就想到了之前一个做英语学习 App 的朋友碰到过的一个性能问题.今天这篇文章,我就从这个性能问题说起,和你说说 MySQ ...
- MySQL实战45讲学习笔记:第十一讲
一.如何在邮箱这样的字段上建立合理的索引 现在,几乎所有的系统都支持邮箱登录,如何在邮箱这样的字段上建立合理的索引,是我们今天要讨论的问题. 假设,你现在维护一个支持邮箱登录的系统,用户表是这么定义的 ...
- 深挖计算机基础:MySQL实战45讲学习笔记
参考极客时间专栏<MySQL实战45讲>学习笔记 一.基础篇(8讲) MySQL实战45讲学习笔记:第一讲 MySQL实战45讲学习笔记:第二讲 MySQL实战45讲学习笔记:第三讲 My ...
- MySQL实战45讲学习笔记:第三十九讲
一.本节概况 MySQL实战45讲学习笔记:自增主键为什么不是连续的?(第39讲) 在第 4 篇文章中,我们提到过自增主键,由于自增主键可以让主键索引尽量地保持递增顺序插入,避免了页分裂,因此索引更紧 ...
- 《MySQL实战45讲》学习笔记1——MySQL的基础架构
在<极客时间>订阅了<MySQL实战45讲>专栏,总觉得看完和没看一样
- 极客时间 Mysql实战45讲 07讲行锁功过:怎么减少行锁对性能的影响笔记 极客时间
极客时间 Mysql实战45讲 07讲行锁功过:怎么减少行锁对性能的影响笔记 极客时间极客时间 Mysql实战45讲 07讲行锁功过:怎么减少行锁对性能的影响笔记 极客时间 笔记体会: 方案一,事务相 ...
随机推荐
- 高端内存映射之kmap持久内核映射--Linux内存管理(二十)
1 高端内存与内核映射 尽管vmalloc函数族可用于从高端内存域向内核映射页帧(这些在内核空间中通常是无法直接看到的), 但这并不是这些函数的实际用途. 重要的是强调以下事实 : 内核提供了其他函数 ...
- RX 和 TX
我们在ifconfig 查看网卡配置时或者嵌入式开发的时候,经常会看到rx/tx缩写,其含义如下: RX==receive,接收,从开启到现在接收封包的情况,是下行流量. TX==Transmit,发 ...
- Linix基本命令
基本命令关机:shutdown -h halt init 0 poweroff重启:shutdown -r reboot init 6pwd:查看工作目录ls:查看指定目录的内容-l:列表显示-a:显 ...
- Saltstack_使用指南02_远程执行-验证
1. 主机规划 2. Master与哪些minion通信 2.1. Master与哪些minion正常通信 [root@salt100 ~]# salt '*' test.ping salt100: ...
- webstorm 的 .后缀名-tab快捷键
if (key) {}//key.if tab if (!key) {}//key.else tab if (key != null) {}//key.notnull tab if (typeof k ...
- 关于Docker开通远程访问端口2375
一.使用版本:docker for windows 18.06,安装过程略,具体如下: 二.开通远程访问端口2375,只需要设置一下即可,如下图:
- JSP七大动作
- Linux-基础学习(六)-Redis的进阶学习
1. redis的进阶操作 1.1 redis的订阅操作 发布订阅的命令 PUBLISH channel msg 将信息 message 发送到指定的频道 channel SUBSCRIBE chan ...
- 《通过C#学Proto.Actor模型》之PID
PID对象是代表Actor对象的进程,是能过Actor.Spawn(props)获取的:它有什么成员呢?既然代理Actor,首先有一个ID,标识自己是谁,Actor在Spawn时可以命名这个ID,否则 ...
- Java面试准备之多线程
什么叫线程安全?举例说明 多个线程访问某个类时,不管运行时环境采用何种调度方式或者这些线程将如何交替执行,并且在主调代码中不需要任何额外的同步或者协同,这个类都能表现出正确的行为,那么就称这个类是线程 ...