Logstash 6.4.3 导入 csv 数据到 ElasticSearch 6.4.3
本文实践最新版的Logstash从csv文件导入数据到ElasticSearch。
注:本文所有文件路径相关的配置,需要根据你当前的环境配置修改
1、初始化ES、Kibana、Logstash
ElasticSearch、Kibana、Logstash的安装、初始化等操作这里就不赘述了,可以参考以下文章:
实现logstash6.4.3 同步mysql数据到Elasticsearch6.4.3
2、安装logstash文件导入、过滤器等插件
为了能导入文件,需要先给logstash安装几个文件导入所需的插件、过滤器等
在logstash的bin目录打开CMD窗口(win7系统可以在当前目录通过shift+右键,选择在此处打开命令窗口),然后输入:
logstash-plugin install logstash-input-file
logstash-plugin install logstash-filter-csv
logstash-plugin install logstash-filter-date
3、配置logstash.conf
logstash.conf配置文件的内容如下;
input {
file {
path => ["H:/ElasticSearch/6.4.3/logstash-6.4.3/test/student.csv"]
# 设置多长时间检测文件是否修改(单位:秒)
stat_interval => 1
# 监听文件的起始位置,默认是end
start_position => beginning
# 监听文件读取信息记录的位置
sincedb_path => "H:/ElasticSearch/6.4.3/logstash-6.4.3/test/since_db.txt"
# 设置多长时间会写入读取的位置信息(单位:秒)
sincedb_write_interval => 5
codec => plain{
charset=>"GBK"
}
}
}
filter {
#去除每行记录中需要过滤的\N,替换为空字符串
mutate{
gsub => [ "message", "\\N", "" ]
}
# 日期格式化
date{
match => ["create_time", "yyyy-MM-dd HH:mm:ss"]
locale => "cn"
}
csv {
# 每行记录的字段之间以|分隔
separator => "|"
columns => ["id","name","department","nickname","create_time","story"]
# 过滤掉默认加上的字段
remove_field => ["host", "tags", "path", "message"]
}
}
output {
elasticsearch {
hosts => ["192.168.1.212:9210","192.168.1.212:9211","192.168.1.212:9212"]
index => "student"
manage_template => true
template => "H:/ElasticSearch/6.4.3/logstash-6.4.3/config/logstash-template.json"
template_overwrite => true
template_name => "student"
}
stdout{
codec => json_lines
}
}
上面的
conf文件中有引用自定义的mapping模板,为啥要这么做呢?我们这里需要定制自己的字段映射模板,否则会直接用默认的logstash的模板,不一定适合我们的需求,比如不是所有字段都需要全文检索,比如日期create_time需要是date类型等,我们可以自己定义个json格式的模板在导入csv的时候指定这个模板文件路径即可。例如我们定义自己的mapping模板logstash-template.json内容如下:
这里有个坑,开始没有设置
order值,默认是0,不起作用,改为大于0就可以了,这里配置成了100
{
"order": 100,
"version": 6100,
"index_patterns": ["student*"],
"settings": {
"index.number_of_shards": 5,
"number_of_replicas": 1,
"index.refresh_interval": "10s"
},
"mappings": {
"doc": {
"properties": {
"@timestamp": {
"type": "date"
},
"@version": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"create_time": {
"type": "date",
"format": "yyyy-MM-dd HH:mm:ss"
},
"department": {
"type": "text"
},
"id": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"name": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"nickname": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
}
}
}
}
}
4、导入csv数据
然后我们在logstash的bin目录启动cmd窗口,输入以下命令执行导入数据(-f 表示需要使用自定义的配置文件,后面带自定义配置文件路径):
logstash.bat -f ../config/logstash.conf
注意:如果前面指定的记录上次读取文件位置信息的文件存在,请删掉(不删除的话不会重新开始导入,只会增量导入),比如删掉我们前面的logstash.conf配置文件指定了这个记录的文件:sincedb_path => "H:/ElasticSearch/6.4.3/logstash-6.4.3/test/since_db.txt"
结果如下:
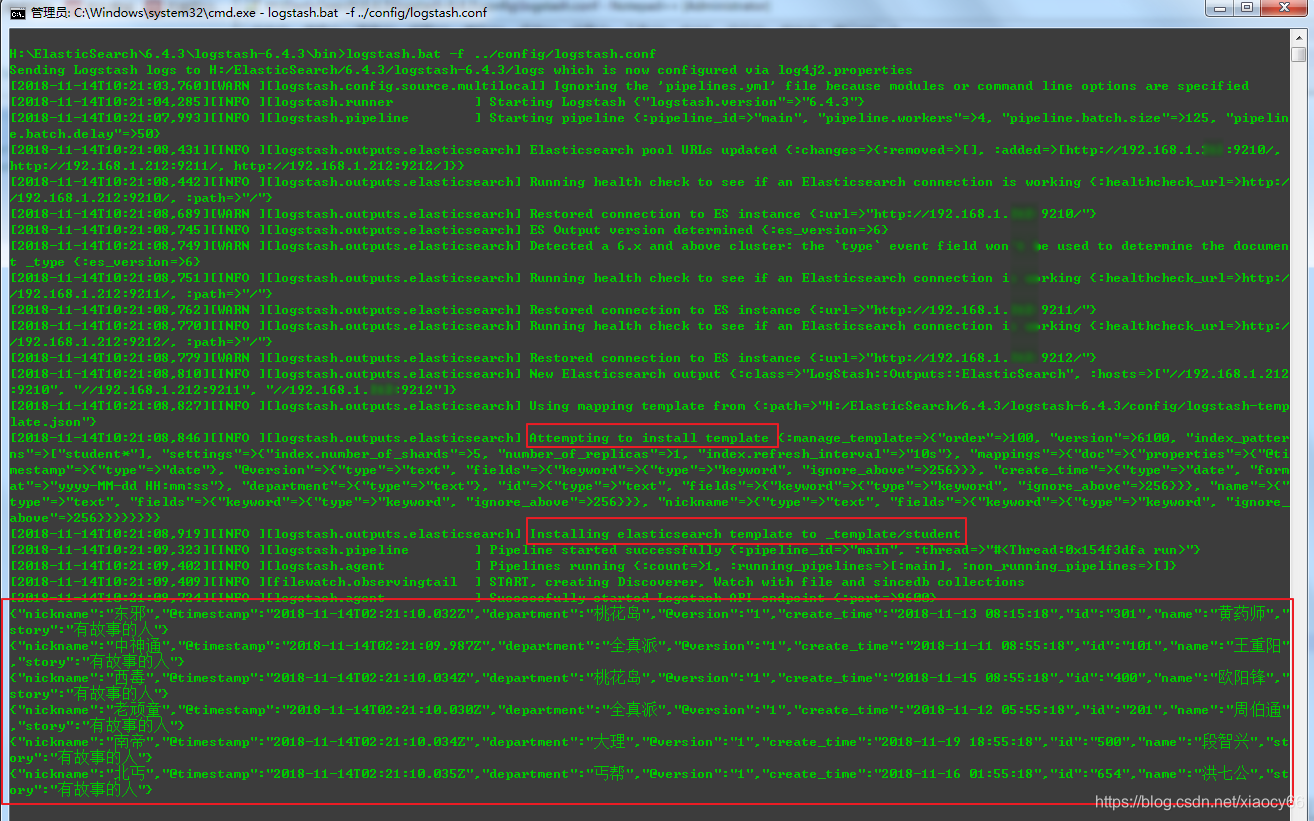
然后我们通过kibana查看下导入的数据:
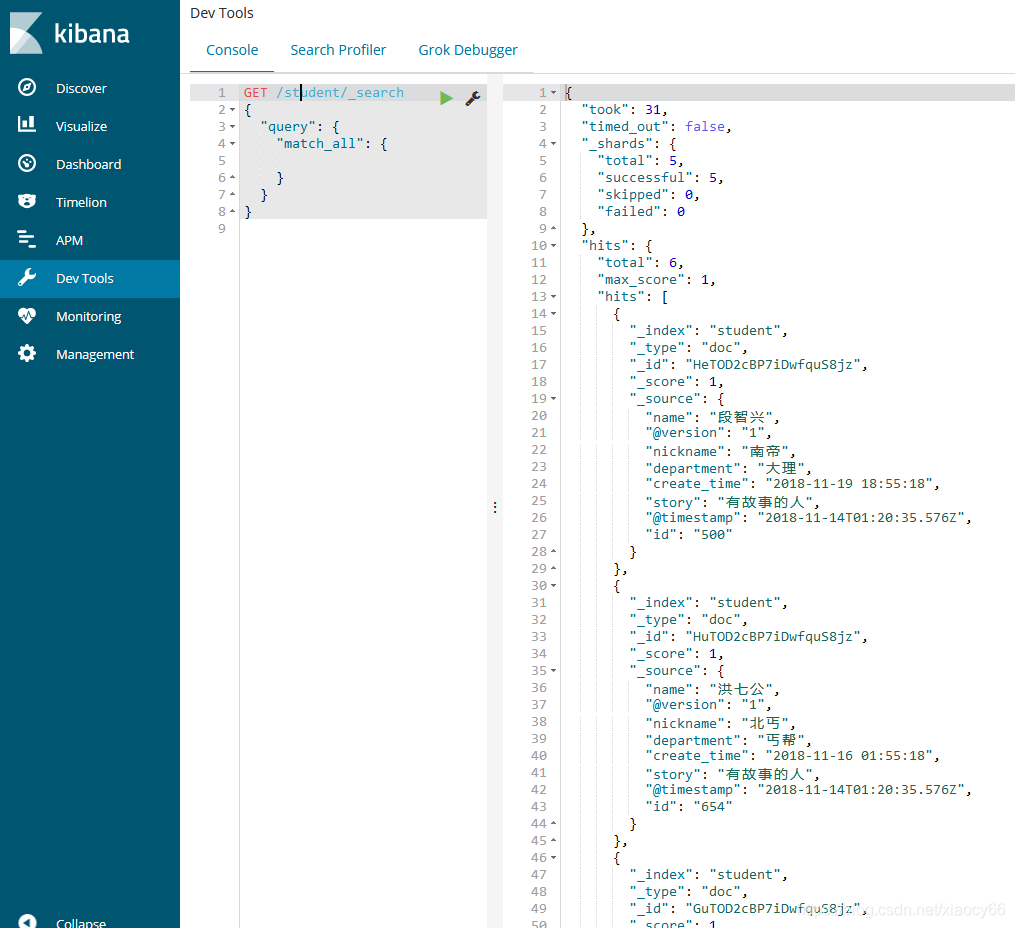
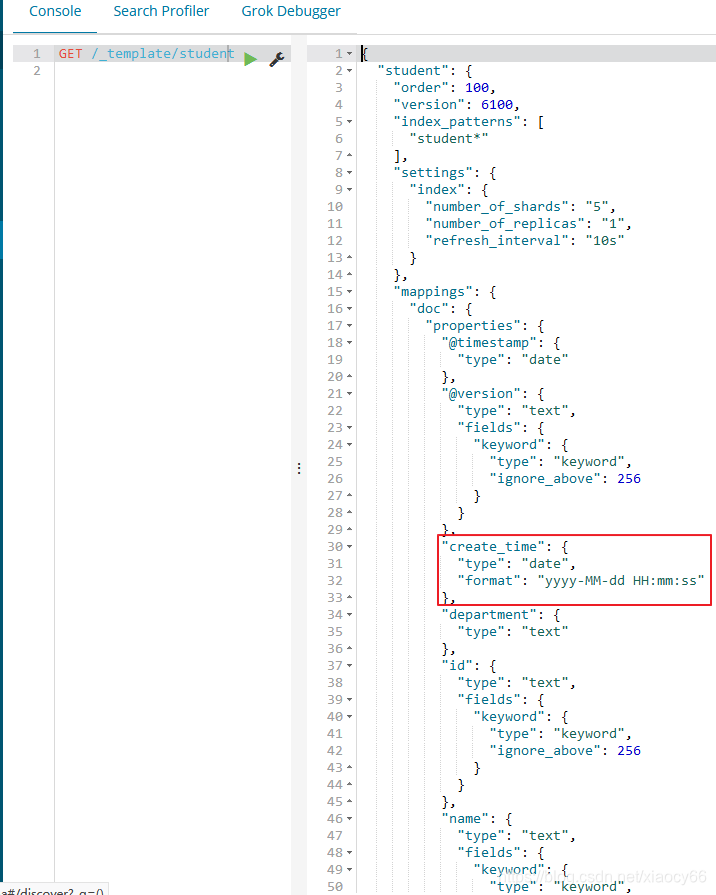
再查看下我们自定义的studen这个mapping模板是否安装到elasticsearch的模板库了,以及它的具体内容是啥:
从上图可以看到确实把我们自定义的mapping模板保存到ES了,并且其中的内容就是我们自定义的,比如create_date 这个字段的格式format就是我们在模板json文件中定义的。
5、本文相关文件下载
本文相关的配置文件、csv数据源
点我去下载
Logstash 6.4.3 导入 csv 数据到 ElasticSearch 6.4.3的更多相关文章
- mysql导出csv/excel文件的几种方法,mysql的load导入csv数据
方法一 php教程用mysql的命令和shell select * into outfile './bestlovesky.xls' from bestlovesky where 1 order by ...
- mysql SQLyog导入csv数据失败怎么办?
分享下mysql使用SQLyog导入csv数据失败的解决方法 给mysql导入数据,选中某个表选择导入--导入使用本地csv数据即可,单有的时候不知道什么问题导入不成功!!! 给mysql导入数据,使 ...
- jmeter 导入csv数据中json格式数据取值不完整
1.jmeter中添加csv数据文件时,数据是json格式 2.jmeter中执行取值发现只取了一部分 分析原因,json格式数据,中间有逗号,而csv是根据逗号来分割的,这回导致我们取值错位. 解决 ...
- MySQL 导入CSV数据
第一步 创建表结构 create table t1( key1 ), v1 ) ); 第二步 导入数据 load data local infile 'D:/t1.csv' into table t1 ...
- mysql 导入CSV数据 [转]
转自: http://blog.chinaunix.net/uid-23284114-id-3196638.html MYSQL LOAD DATA INFILE命令可以把csv平面文件中的数据导 ...
- Mysql 导入CSV数据 语句 导入时出现乱码的解决方案
1. 登陆mysql 2. use testdb 3. 执行导入语句 LOAD DATA LOCAL INFILE 'd://exportedtest2.csv' INTO TABLE usertab ...
- sql server 小技巧(1) 导入csv数据到sql server
1. 右击 DataBaseName,选择 Tasks->Import Data 2. 选择数据源: Flat File Source , 选择一个csv文件 Advance: 选择所有的列,改 ...
- 如何导入CSV数据 (python3.6.6区别于python2 环境)
1.python2环境下 2.python3.6.6环境下 如果用python2环境下的代码,在python3.6.6环境下编译会出现以下问题: 错误(1): SyntaxError:Missing ...
- plsql导入csv数据,未响应,invalid identifier
问题分析: 1.确保cvs字段名与表字段名一致,不要有空格 2.cvs字段对应表字段的大写,确保表字段都是大写 3.如果字段能对应上,plsql会自动识别出来
随机推荐
- jmeter使用csv传参进行并发测试验证
1.获取到注册接口,添加HTTP信息头管理器.HTTP请求,设置好入参,且检查使用csv文件传参的入参 2.创建csv文件,写入需要传的入参 3.添加CSV Data Set Config 设置配置 ...
- 【尚学堂·Hadoop学习】MapReduce案例2--好友推荐
案例描述 根据好友列表,推荐好友的好友 数据集 tom hello hadoop cat world hadoop hello hive cat tom hive mr hive hello hive ...
- 2018-2019 20165221 网络对抗 Exp5 MSF基础
2018-2019 20165221 网络对抗 Exp5 MSF基础 实践内容: 重点掌握metassploit的基本应用方式,重点常用的三种攻击方式的思路.具体需要完成: 一个主动攻击实践,如ms0 ...
- 20175315 实验二《Java面向对象程序设计》实验报告
20175315 实验二<Java面向对象程序设计>实验报告 一.实验内容及步骤 1.初步掌握单元测试和TDD 单元测试 任务一:三种代码 用程序解决问题时,要学会写以下三种代码: 伪代码 ...
- input子系统 KeyPad-Touch上报数据格式与机制【转】
转自:https://www.cnblogs.com/0822vaj/p/4185634.html -------------------------------------------------- ...
- Grunt 实战
专题截图:(注:这个截图没啥意义) 项目截图: 目录讲解: app/ //开发目录; c/ //开发编译完成css文件夹; i/ //开发img文件夹; j/ / ...
- Mysql 反向解析 导致远程访问慢
在云端部署了mysql后,发现远程连接的响应速度非常慢(3-10s) 但是在本地访问数据库却没有问题 经过一番google这才知道原来mysql默认会进行反向解析,即通过ip地址反向向ISP申请获取域 ...
- Oracle数据安全解决方案(1)——透明数据加密TDE
Oracle数据安全解决方案(1)——透明数据加密TDE2009年09月23日 22:49:00 华仔爱技术 阅读数:7991原文地址: http://www.oracle.com/technolog ...
- SpringJUnit4ClassRunner (单元测试)
1.在Maven的pom.xml中加入 <dependency> <groupId>junit</groupId> <artifactId>junit& ...
- uni-app 引入本地iconfont的正确姿势以及阿里图标引入
1.引入本地iconfont iconfont文件里面包含 iconfont.ttf.iconfont.css, 将 iconfont.tt64文件转位 base64.推荐转换工具地址:https:/ ...