转载:揪出MySQL磁盘消耗迅猛的真凶
揪出MySQL磁盘消耗迅猛的真凶
背景
Part1:写在最前
当一张单表10亿数据量的表放在你面前,你将面临着什么?
Part2:背景介绍
为了提升数据库资源利用率,一个实例中,在不互相影响,保证业务高效的前提下,我们会将同一个大业务下的不同小业务放在一个实例中,我们的磁盘空间是2T,告警阈值为当磁盘剩余空间10%时发出短信告警。笔者接到某业务主库磁盘剩余空间告警的短信后,经过一番查探,发现从几天前开始,有一张表的数据量增长非常快,而在之前,磁盘空间下降率还是较为平缓的,该表存在大字段text,其大批量写入更新,导致磁盘消耗迅猛。
我们首先来看下该表的表结构:
mysql> CREATE TABLE `tablename_v2` (
`id` bigint(20) unsigned NOT NULL AUTO_INCREMENT,
`No` varchar(64) NOT NULL DEFAULT '',
`Code` varchar(64) NOT NULL DEFAULT '' ,
`log` varchar(64) DEFAULT '' ,
`log1` varchar(64) DEFAULT '' ,
.....
`Phone` varchar(20) DEFAULT '',
`createTime` bigint(20) unsigned NOT NULL DEFAULT '0',
`updateTime` bigint(20) unsigned NOT NULL DEFAULT '0',
PRIMARY KEY (`id`),
UNIQUE KEY `uk_mailNo` (`No`,`Code`),
KEY `idx_Phone` (`Phone`)
) ENGINE=InnoDB AUTO_INCREMENT=9794134664 DEFAULT CHARSET=utf8;
与业务了解得知,该表几乎没有删除操作,由于数据量过大,我们模糊使用auto_increment来作为表数量预估值,避免count()操作对线上造成的影响。
Part3:案例分析
与业务沟通了解后得知,该表可以清理4个月以前的老旧数据,因此可以使用delete的方式清除,而我们通过表结构可以看出,该表在设计之初,并没有对updateTime列创建索引,因此以时间为范围去进行delete操作,这显然是不合理的。
经过与业务协商,我们确定了可以将id作为删除条件,删除id<2577754125之前的数据
也就是说,此时的delete语句变为了:
mysql> delete from tablename_v2 where id <2577754125;
且不说delete操作有多慢,直接执行这样的SQL也会有诸如长事务告警,从库大量延迟等并发症产生,因此绝不能在生产库上进行这种大批量的危险操作。
实战
Part1:监控
从监控图我们能看出磁盘下降的趋势:
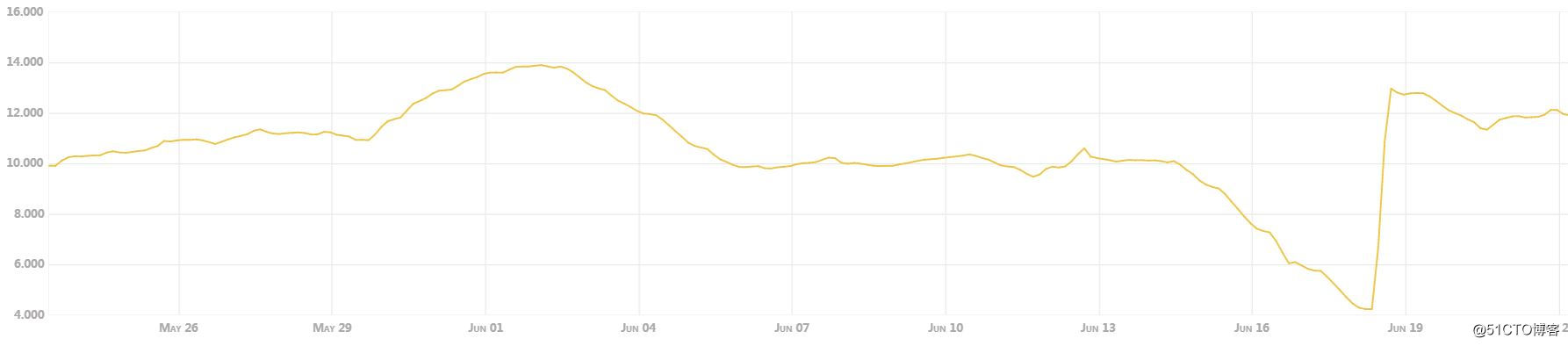
监控显示,从6月14日-6月18日期间,磁盘消耗最为严重,与业务沟通得知,618期间大促引发该表存储量激增导致。
Part2:实战操作
我们通过查看binlog发现,集群中binlog的刷新量虽不说像笔者上个案例那样多么迅猛,但也绝不是老实本分
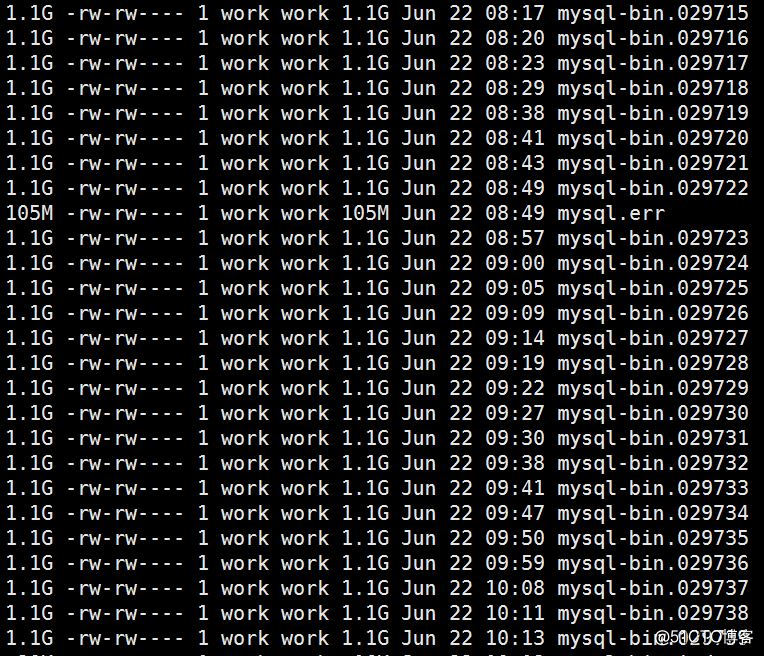
我们可以看出,在高峰期间,binlog的刷新间隔最短达到了2分钟写满1.1GB的binlog。因此笔者与业务沟通后,首先清理binlog日志,将 expire_logs_days从7天调整至3天。
同时,清理一些能够清理的无用日志、废旧文件等等。
我们也能在上面的监控图看到在做完这些清理操作后,磁盘空间剩余从4%提升至12%,但随后依旧保持原有速率下降。
Part3:pt-archiver
真凶找到了,我们怎么办,别急,使用pt-archiver。pt-archiver工具是percona工具集的一员,是归档MySQL大表数据的最佳轻量级工具之一。他可以实现分chunk分批次归档和删除数据,能避免一次性操作大量数据带来的各种问题。
闲话不多说,一向本着实战的原则,我们直接上命令:
pt-archiver --source
h=c3-helei-db01.bj,D=helei,t=tablename_v2,u=sys_admin,p=MANAGER
--where 'id<2577754125' --purge --progress 10000 --limit=10000
--no-check-charset --txn-size=10000 --bulk-delete --statistics --max-lag=20
--check-slave-lag c3-helei-db02.bj
简单说下常用的参数:
| source | 目标节点 |
| where | 条件 |
| purge | 删除source数据库的相关匹配记录 |
| progress | 每处理多少行显示一次信息 |
| limit | 每次取出多少行处理 |
| no-check-charset | 不检查字符集 |
| txn-size | 每多少行提交一次 |
| bulk-delete | 并行删除 |
| statistics | 结束后输出统计信息 |
| max-lag | 最大延迟 |
| check-slave-lag |
检查某个目标从库的延迟 |
Warning:警告这里就又有个小坑了,的确,我们使用bulk-delete参数能够增加删除速率,相比不使用bulk-delete速度能够提升10倍左右,但问题也就显现出来,在使用上述命令期间,发现binlog每秒写入量激增,这又回到了我们说的,哪些情况会导致binlog转为row格式。
首先我们需要了解到使用bulk-delete时,sql是如下执行的:
mysql> delete from tablename_v2 where id >xxx and id < xxx limit 10000.
如果您之前关注过笔者的文章,应该知道,当使用了delete from xxx where xxx limit 语法时,会将binlog_format从mixed转为row,这样的话,删除的同时,binlog由于转为了row格式也在激增,这与我们的预期是不符的。
因此最终的命令为:
pt-archiver --source
h=c3-helei-db01.bj,D=helei,t=tablename_v2,u=sys_admin,p=MANAGER
--where 'id<2577754125' --purge --progress 10000 --limit=10000
--no-check-charset --txn-size=10000 --statistics --max-lag=20
--check-slave-lag c3-helei-db02.bj
去掉了bulk-delete,这样的话就能够保证正常的delete,而不加limit,binlog不会转为row格式导致磁盘消耗继续激增。
对于Innodb引擎来说,delete操作并不会立即释放磁盘空间,新的数据会优先填满delete操作后的“空洞”,因此从监控来看就是磁盘不会进一步消耗了,说明我们的pt-archiver工具删除是有效的。
Part4:困惑
首先我们要知道,当你面对一张数据量庞大的表的时候,有些东西就会受限制,例如:
不能alter操作,因为这会阻塞dml操作。
对于本案例,空间本就不足,也不能使用pt-online工具来完成。
对于不能alter其实是比较要命的,比如开发要求在某个时间段尽快上线新业务,而新业务需要新增列,此时面对这么庞大的量级,alter操作会异常缓慢。
因此,笔者与研发沟通,尽快采用物理分表的方式解决这个问题,使用物理分表,清理表的操作就会很容易,无需delete,直接drop 老表就可以了。其次,物理分表让alter语句不会卡住太久,使用pt-online工具也不会一次性占据过多的磁盘空间诱发磁盘空间不足的告警。
再有就是迁移TiDB,TiDB相较MySQL更适合存储这类业务。
Part5:再谈binlog_format
我们选取其中高峰期的binlog发现其update操作转为了row格式,记录了所有列变更前后的所有信息,而binlog中并未出现update xxx limit这种操作,那又会是什么引发的row格式记录呢?
这里这篇文章又抛出一个新的案例,在官网那篇何时mixed转row格式中又一个没有记录的情况
官方文档:
When running in MIXED logging format, the server automatically switches from statement-based to row-based logging under the following conditions:
When a DML statement updates an NDBCLUSTER table.
When a function contains UUID().
When one or more tables with AUTO_INCREMENT columns are updated and a trigger or stored function is invoked. Like all other unsafe statements, this generates a warning if binlog_format = STATEMENT.
When any INSERT DELAYED is executed.
When a call to a UDF is involved.
If a statement is logged by row and the session that executed the statement has any temporary tables, logging by row is used for all subsequent statements (except for those accessing temporary tables) until all temporary tables in use by that session are dropped.
This is true whether or not any temporary tables are actually logged.
Temporary tables cannot be logged using row-based format; thus, once row-based logging is used, all subsequent statements using that table are unsafe. The server approximates this condition by treating all statements executed during the session as unsafe until the session no longer holds any temporary tables.
When FOUND_ROWS() or ROW_COUNT() is used. (Bug #12092, Bug #30244)
When USER(), CURRENT_USER(), or CURRENT_USER is used. (Bug #28086)
When a statement refers to one or more system variables. (Bug #31168)
我们这个案例中又出现了一个新的因素就是:
当表结构中存在多个唯一索引(包括主键id),本案例中存在主键和UNIQUE KEY `uk_mailNo`这个唯一索引,且使用了
INSERT ... ON DUPLICATE KEY UPDATE
这时,mysql binlog_format就会被转为row格式,这个内容也是记录在官网的其他章节:
https://dev.mysql.com/doc/refman/5.5/en/insert-on-duplicate.html
也就是说,只要业务解决了使用这种语法插入的话,磁盘空间下降迅猛的原因也能够缓解不少。我们统计发现,qps更高的其他业务中,binlog保留7天的磁盘消耗量在60GB
而该业务我们仅仅保留3天binlog,却依旧消耗了430GB的磁盘空间,这已经超过了我们整个2T磁盘空间的5分之一了。
——总结——
通过这个案例,我们能够了解到什么情况下binlog_format会由MIXED格式转为ROW格式,以及触发的一系列并发症和解决办法,还有pt工具pt-archiver的使用。由于笔者的水平有限,编写时间也很仓促,文中难免会出现一些错误或者不准确的地方,不妥之处恳请读者批评指正。喜欢笔者的文章,右上角点一波关注,谢谢!
转载:揪出MySQL磁盘消耗迅猛的真凶的更多相关文章
- 【转】Win8/8.1/Win7小技巧:揪出C盘空间占用的真凶
原文网址:http://www.ithome.com/html/win8/55496.htm 不少使用Win8.Win8.1的用户不难发现,原先只占用20G大小的系统盘,随着使用时间的增加,C盘的磁盘 ...
- 揪出“凶手”——实战WinDbg分析电脑蓝屏原因
http://www.appinn.com/blue-screen-search-code/ 蓝屏代码查询器 – 找出蓝屏的元凶 11 文章标签: windows / 系统 / 蓝屏. 蓝屏代码查询器 ...
- MySQL磁盘写入策略以及数据安全性的相关参数
转载自:http://blog.itpub.net/22664653/viewspace-1063134/ innodb_flush_log_at_trx_commit和sync_binlog ...
- 揪出Android流氓软件
揪出Android流氓软件 http://www.icpcw.com/Smartphone/Android/Android/1471/147142_all.htm http://www.william ...
- MariaDB日志审计 帮你揪出内个干坏事儿的小子
Part1:谁干的? 做DBA的经常会遇到,一些表被误操作了,被truncate.被delete.甚至被drop.引起这方面的原因大多数都是因为人为+权限问题导致的.一些公共账户,例如ceshi账户, ...
- 图解ARP协议(三)ARP防御篇-如何揪出“内鬼”并“优雅的还手”
一.ARP防御概述 通过之前的文章,我们已经了解了ARP攻击的危害,黑客采用ARP软件进行扫描并发送欺骗应答,同处一个局域网的普通用户就可能遭受断网攻击.流量被限.账号被窃的危险.由于攻击门槛非常低, ...
- 【经验分享】用adb揪出安卓APP弹窗广告的原形
背景 相信不少安卓用户中过影子弹窗广告的困扰,这种推广APP本体在后台运行,而且可以在其他APP上弹出覆盖广告,一不小心就会误操作,点击广告或者下载APP,着实令人恶心. 以前的广告软件只在通知栏会推 ...
- 转载用sql语句计算出mysql数据库的qps,tps,iops性能指标
本帖最后由 LUK 于 2014-9-21 22:39 编辑 思路: 1 关注MYSQL三个方面的性能指标,分别为query数,transaction数,io请求数 2 在某个时间范围内(例如20秒) ...
- 转载----开发者大杀器 —— 刨根问底,揪出 Android App 耗电的元凶代码
转载文章地址:http://www.jianshu.com/p/27ba2759b221
随机推荐
- shell截取指定字符串之间的内容
#!/bin/bash#截取字符串 #path=ss/usr/share/src/root/home/admin path=ss/usr/share/src/root/home/admin/src/a ...
- WEB学习笔记8-添加javascript禁用的提示
最常用的方式是使用<noscript>标签,此标签就是当javascript被禁用或者不被支持的时候提供一种代替方式,即<noscript>标签的内容会在此时被浏览器解析,作为 ...
- 用python写一个名片管理系统
info = [] #先定义一个空字典while True: #利用while循环 print(' 1.查看名片') #第一个选项 print(' 2.添加名片') #第二个选项 print(' 3. ...
- jQuery-4.动画篇---jQuery核心
jQuery中each方法的应用 jQuery中有个很重要的核心方法each,大部分jQuery方法在内部都会调用each,其主要的原因的就是jQuery的实例是一个元素合集 如下:找到所有的div, ...
- 使用C语言开发PHP扩展(转)
本篇文章给大家带来的内容是介绍如何使用C语言给PHP写扩展,,有一定的参考价值,有需要的朋友可以参考一下,希望对你有所帮助. 1.在php源码路径的ext文件夹下,新建一个extend_test.de ...
- vue集成环信IM
vue 集成环信im 简单demo 环信AppKey:1106190415055331#test 测试账号: test1 123456 test2 123456 test3 123456 默 ...
- SDL播放YUV——循环
#include "SDL.h" #include "as_lesson_log.h" #define PATH_YUV420 "/sdcard/ou ...
- Pagedown learning notes
Pagedown Links Google wiki page Download Markdown.Converter.js var converter = new Markdown.Converte ...
- 在安卓手机上安装完整kali linux系统
俗话说,没图说个JB.好我马上上图 提醒:我在这里只是提供一个思路过程,希望可以帮到你,同时我也做一个记录,有任何问题欢迎 0.0.:I87OI94664 威信 :Z2tsYmI1MjA= (b ...
- Linux第九节课学习笔记
fdisk可添加.删除.转换分区. 创建主分区:n-p-w:扩展分区:n-e:逻辑分区:n-l. SWAP分区专用格式化命令mkswap,专用挂载命令swapon. 磁盘容量配额中,硬限制必须,软限制 ...