信息摘要算法之三:SHA256算法分析与实现
前面一篇中我们分析了SHA的原理,并且以SHA1为例实现了相关的算法,在这一片中我们将进一步分析SHA2并实现之。
1、SHA简述
前面的篇章中我们已经说明过,SHA实际包括有一系列算法,分别是SHA-1、SHA-224、SHA-256、SHA-384以及SHA-512。而我们所说的SHA2实际是对后面4中的统称。各种SHA算法的数据比较如下表,其中的长度单位均为位:
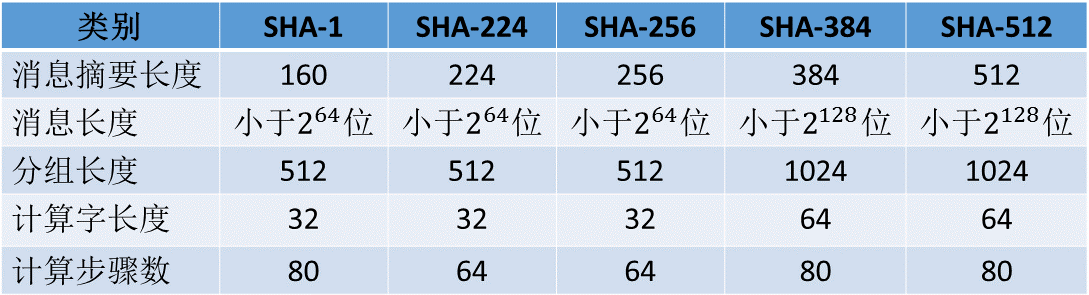
从上表中我们不难发现,SHA-224和SHA-256、SHA-384和SHA-512在消息长度、分组长度、计算字长以及计算步骤各方面分别都是一致的。事实上通常认为SHA-224是SHA-256的缩减版,而SHA-384是SHA-512的缩减版。所以在接下来的讨论中,我们把SHA-224和SHA-256作为一组,而把SHA-384和SHA-512作为另一组来讨论。在这一篇我们先来分析和实现SHA-224和SHA-256算法。
2、消息的填充与解析
在这里我们讨论的散列函数用于在计算机中将根据作为输入消息或者数据文件生成其对应的信息摘要。消息或数据文件通常被作为是位字符串。消息的长度是消息中的比特数(空消息的长度为0)。如果消息中的比特数是8的倍数,那么我们就可以用十六进制来表示消息的紧凑性。消息填充的目的是为了在消息填充后,在SHA-224和SHA-256中消息的长度正好是512位的整数倍。
接下来我们说明消息或者数据文件将如何实现填充。总的来说就是,先添加一个“1”,再后跟多个“0”,然后再追加一个64位的消息长度信息,使得填充完成后的消息长度正好是512位的整数倍。追加的64位的消息长度信息是原始消息的位长,填充完成的消息会被分成512位的消息分组。
对于SHA-224和SHA-256来说消息的最大长度L<264,在对消息进行散列运算之前需要对消息做相应的填充处理。
首先,在原始信息之后填充一个“1”,例如:如果原始信息是"01010000",完成这一填充之后就是 "010100001"。
接下来,在完成上一步填充后,在其后面需天充一定数量的“0”,数量记为K,则K的取值必须是满足下述表达式的最小非负整数值。
( L + 1 + K ) mod 512 = 448
最后,在填充完必的消息后,追加64位的原始消息长度,因为消息的长度不会超过264位,所以其长度数据的值不会超过64位。填充完毕后,所有的消息分组都将是一个512位。
3、迭代函数与常数
SHA算法这类散列算法的计算过程都需要用到逻辑函数和计算常量。但由于具体算法的不同所使用的具体的函数和常数略有差别。我们在前面的篇章中说过MD5和SHA1,它们都有4个逻辑函数,而在SHA2的一系列算法中都采用了6个逻辑函数。接下来将说明SHA-224和SHA-256的逻辑函数和常量。
SHA-224和SHA-256采用6个逻辑函数,每个函数均基于32位字运算,这些输入的32位字我们记为x、y、z,同样的这些函数的计算结果也是一个32位字。这些逻辑函数表示如下:
CH( x, y, z) = (x AND y) XOR ( (NOT x) AND z)
MAJ( x, y, z) = (x AND y) XOR (x AND z) XOR (y AND z)
BSIG0(x) = ROTR^2(x) XOR ROTR^13(x) XOR ROTR^22(x)
BSIG1(x) = ROTR^6(x) XOR ROTR^11(x) XOR ROTR^25(x)
SSIG0(x) = ROTR^7(x) XOR ROTR^18(x) XOR SHR^3(x)
SSIG1(x) = ROTR^17(x) XOR ROTR^19(x) XOR SHR^10(x)
SHA-224和SHA-256采用相同的,64个32位的常数序列。通常记为:K0、K1、……、K63,这些常数的取值是前64个质数的立方根的小数部分的前32位。这些数以16进制表示如下:
428a2f98 71374491 b5c0fbcf e9b5dba5 3956c25b 59f111f1 923f82a4 ab1c5ed5
d807aa98 12835b01 243185be 550c7dc3 72be5d74 80deb1fe 9bdc06a7 c19bf174
e49b69c1 efbe4786 0fc19dc6 240ca1cc 2de92c6f 4a7484aa 5cb0a9dc 76f988da
983e5152 a831c66d b00327c8 bf597fc7 c6e00bf3 d5a79147 06ca6351 14292967
27b70a85 2e1b2138 4d2c6dfc 53380d13 650a7354 766a0abb 81c2c92e 92722c85
a2bfe8a1 a81a664b c24b8b70 c76c51a3 d192e819 d6990624 f40e3585 106aa070
19a4c116 1e376c08 2748774c 34b0bcb5 391c0cb3 4ed8aa4a 5b9cca4f 682e6ff3
748f82ee 78a5636f 84c87814 8cc70208 90befffa a4506ceb bef9a3f7 c67178f2
4、计算过程
前面,我们已经介绍了消息的预处理及散列逻辑函数,接下来我们将说明摘要的计算过程。
每个安全散列函数的输出,在应用到一个分为N个分组的消息后,结果记为散列量H(N)。对于SHA-224和SHA-256,H(i)可以被认为是8个32位的字,记为:H(i)0、H(i)1、…、H(i)7。
散列字被初始化为一个特定的值,并在处理完每一个消息分组后对它进行更新,并在处理最后一个块后将其连接起来以产生输出。对于SHA-256,所有的H(N)变量都是串联的,而SHA-224散列值是通过最后连接时,省略一些而产生的。
接下来我们说明一下SHA-224和SHA-256的计算过程。首先初始化链接变量。对于SHA-224来说,初始散列值H(0)由以下8个32位的十六进制数组成:
H(0)0 = c1059ed8
H(0)1 = 367cd507
H(0)2 = 3070dd17
H(0)3 = f70e5939
H(0)4 = ffc00b31
H(0)5 = 68581511
H(0)6 = 64f98fa7
H(0)7 = befa4fa4
而对于SHA-256来说,初始散列值H(0)由以下8个32位的十六进制数组成。这些字由前8个质数的平方根的小数部分的钱32位组成。
H(0)0 = 6a09e667
H(0)1 = bb67ae85
H(0)2 = 3c6ef372
H(0)3 = a54ff53a
H(0)4 = 510e527f
H(0)5 = 9b05688c
H(0)6 = 1f83d9ab
H(0)7 = 5be0cd19
接下来我们描述一下摘要计算,SHA-224和SHA-256在消息分组执行相同的处理,只在初始化H(0)和如何生成最终输出的过程中有所不同。SHA-224和SHA-256可以用来散列处理长度为L位的消息,其中0 < L< = 264。算法使用一个64个32位字的消息列表, 8个工作变量32位以及8个32位字的散列值。
消息列表每32位分为一个子分组,被标记为W0、W1、…、W63。8个工作变量分别为a、b、c、d、e、f、g和h,8个散列值被标记为h(i)0、h(i)1、…、H(i)7,并保留初始散列值H(0),替换为每一个连续的中间散列值(在处理完每个消息分组后) H(i),并以最终的散列值H(N)结束,在处理完所有N块后。它们还使用两个临时变量T1和T2。
从前面我们知道,填充完了之后消息被分为了512位的消息分组。每个分组被分为16个32位的子分组,记为:M(i)0、M(i)1、...、M(i)15。将对N个消息分组进行如下操作。
a、64个消息列表的生成
For t = 0 to 15
Wt = M(i)t
For t = 16 to 63
Wt = SSIG1(W(t-2)) + W(t-7) + SSIG0(w(t-15)) + W(t-16)
b、初始化工作变量
a = H(i-1)0
b = H(i-1)1
c = H(i-1)2
d = H(i-1)3
e = H(i-1)4
f = H(i-1)5
g = H(i-1)6
h = H(i-1)7
c、执行散列计算
For t = 0 to 63
T1 = h + BSIG1(e) + CH(e,f,g) + Kt + Wt
T2 = BSIG0(a) + MAJ(a,b,c)
h = g
g = f
f = e
e = d + T1
d = c
c = b
b = a
a = T1 + T2
d、计算中间散列值
H(i)0 = a + H(i-1)0
H(i)1 = b + H(i-1)1
H(i)2 = c + H(i-1)2
H(i)3 = d + H(i-1)3
H(i)4 = e + H(i-1)4
H(i)5 = f + H(i-1)5
H(i)6 = g + H(i-1)6
H(i)7 = h + H(i-1)7
在对所有消息分组完成上述计算之后,计算最终输出。对于SHA-256,是所有H(N)0、H(N)1到H(N)7的串联。对于SHA-224,则是H(N)0、H(N)1直到H(N)6的串联。
5、代码实现
前面我们已经说明了SHA-256(SHA-224)的计算过程,接下来我们将这一过程代码化。同样的首先定义一个上下文的结构。
/** 定义SHA-256哈希操作的内容信息结构体 */
typedef struct SHA256Context {
uint32_t Intermediate_Hash[SHA256HashSize/]; /* 信息摘要 */
uint32_t Length_High; /* 按位计算的信息长度高字 */
uint32_t Length_Low; /* 按位计算的信息长度低字 */
int_least16_t Message_Block_Index; /* 信息分组数组的索引 */
uint8_t Message_Block[SHA256_Message_Block_Size];/* 512位信息分组 */
int Computed; /* 摘要计算标识 */
int Corrupted; /* 信息摘要损坏标识 */
} SHA256Context;
接下来实现SHA256Context结构的初始化,为后续的计算过程做准备。
static SHAStatusCode SHA224_256Reset(SHA256Context *context, uint32_t *H0)
{
if (!context) return shaNull;
context->Length_High = context->Length_Low = ;
context->Message_Block_Index = ;
context->Intermediate_Hash[] = H0[];
context->Intermediate_Hash[] = H0[];
context->Intermediate_Hash[] = H0[];
context->Intermediate_Hash[] = H0[];
context->Intermediate_Hash[] = H0[];
context->Intermediate_Hash[] = H0[];
context->Intermediate_Hash[] = H0[];
context->Intermediate_Hash[] = H0[];
context->Computed = ;
context->Corrupted = shaSuccess;
return shaSuccess;
}
接下来实现信息分组的输入,这个函数接受一个字节数组作为下一个消息分组以便进行处理。
SHAStatusCode SHA256Input(SHA256Context *context, const uint8_t *message_array,unsigned int length)
{
if (!context) return shaNull;
if (!length) return shaSuccess;
if (!message_array) return shaNull;
if (context->Computed) return context->Corrupted = shaStateError;
if (context->Corrupted) return context->Corrupted;
while (length--)
{
context->Message_Block[context->Message_Block_Index++] =*message_array;
if ((SHA224_256AddLength(context, ) == shaSuccess) &&(context->Message_Block_Index == SHA256_Message_Block_Size))
SHA224_256ProcessMessageBlock(context);
message_array++;
}
return context->Corrupted;
}
当然还需要一个消息处理及最终摘要输出的函数,这个函数将返回一个224位或者256位的信息摘要到调用者给定的Message_Digest数组。返回的信息摘要,第一个元素索引为0,最后一个元素索引为27(SHA-2244)或者31(SHA-256)。
static SHAStatusCode SHA224_256ResultN(SHA256Context *context,uint8_t Message_Digest[ ], int HashSize)
{
int i;
if (!context) return shaNull;
if (!Message_Digest) return shaNull;
if (context->Corrupted) return context->Corrupted;
if (!context->Computed)
SHA224_256Finalize(context, 0x80);
for (i = ; i < HashSize; ++i)
Message_Digest[i] = (uint8_t)(context->Intermediate_Hash[i>>] >> * ( - ( i & 0x03 ) ));
return shaSuccess;
}
至此我们就完成了SHA-256(SHA-224)的编码,在后续我们将对这一编码进行验证。
6、结论
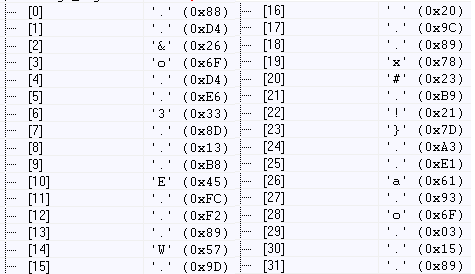
上一节我们实现了SHA-256(SHA-224)的编码,接下来我们来对这一实现进行验证。我们输入明文“abcd”并输出结果:
同时我们对比一下其他工具生成的“abcd”的SHA-256的信息摘要结果如下:
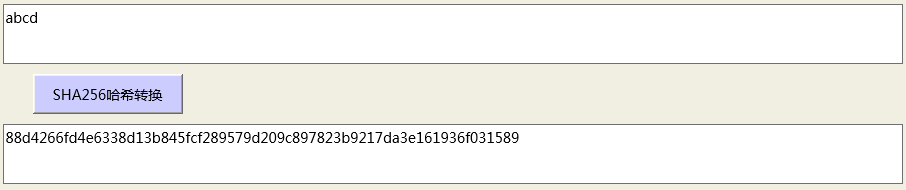
对比上述两个结果,我们发现是完全一致的,说明我们的编码是没有问题的。
欢迎关注:

信息摘要算法之三:SHA256算法分析与实现的更多相关文章
- 信息摘要算法之五:HMAC算法分析与实现
MAC(Message Authentication Code,消息认证码算法)是含有密钥散列函数算法,兼容了MD和SHA算法的特性,并在此基础上加上了密钥.因此MAC算法也经常被称作HMAC算法. ...
- 信息摘要算法之一:MD5算法解析及实现
MD5即Message-Digest Algorithm 5(信息-摘要算法5),用于确保信息传输完整一致.是计算机广泛使用的杂凑算法之一(又译摘要算法.哈希算法),主流编程语言普遍已有MD5实现. ...
- 信息摘要算法 MessageDigestUtil
package com.xgh.message.digest.test; import java.math.BigInteger; import java.security.MessageDigest ...
- MD5加密算法(信息摘要算法)、Base64算法
1 什么是MD5 信息摘要算法,可以将字符进行加密,每个加密对象在进行加密后都是等长的 应用场景:将用户密码经过MD5加密后再存储到数据库中,这样即使是超级管理员也没有能力知道用户的具体密码是多少:因 ...
- MD5( 信息摘要算法)的概念原理及python代码的实现
简述: message-digest algorithm 5(信息-摘要算法).经常说的“MD5加密”,就是它→信息-摘要算法. md5,其实就是一种算法.可以将一个字符串,或文件,或压缩包,执行md ...
- 一步一步实现web程序信息管理系统之三----登陆业务逻辑实现(验证码功能+参数获取)
本篇紧接着上一篇文章[一步一步实现web程序信息管理系统之二----后台框架实现跳转登陆页面] 验证码功能 一般验证码功能实现方式为,前端界面访问一个url请求,后端服务代码生成一个图片流返回至浏览器 ...
- OpenSSL实现了5种信息摘要算法有哪些?
OpenSSL实现了5种信息摘要算法,分别是MD2.MD5.MDC2.SHA(SHA1)和RIPEMD.SHA算法事实上包括了SHA和SHA1两种信息摘要算法.此外,OpenSSL还实现了DSS标准中 ...
- 信息摘要算法之六:HKDF算法分析与实现
HKDF是一种特定的键衍生函数(KDF),即初始键控材料的功能,KDF从其中派生出一个或多个密码强大的密钥.在此我们想要描述的是基于HMAC的HKDF. 1.HKDF概述 密钥派生函数(KDF)是密码 ...
- 信息摘要算法之四:SHA512算法分析与实现
前面一篇中我们分析了SHA256的原理,并且实现了该算法,在这一篇中我们将进一步分析SHA512并实现之. 1.SHA简述 尽管在前面的篇章中我们介绍过SHA算法,但出于阐述的完整性我依然要简单的说明 ...
随机推荐
- 接口管理工具——阿里RAP
1.阿里官网RAP a.进入官网 http://rapapi.org/org/index.do b.项目创建:创建 团队 —— 创建 产品线 —— 创建 分组 —— 创建 项目 c.然后就可以创建 页 ...
- json转化技巧
如果用户是一级下拉菜单,二级联动,动态加载内容到二级菜单,并在下方内容处,随着用户选择的内容动态加载相应内容. 实现的方法其实很简单 select部分:一级菜单选择内容,ajax动态加载,因为内容固定 ...
- windows下编译SDL1.2
首先,官网下载开发库,我这里用的是tdm-gcc,因此下载mingw版的. 解压,写代码,编译…… 成功!...地出错了 这里提一下,编译命令是 g++ test.cpp -I include目录 ...
- linux的软件安装方式总结
Linux系统中软件的“四”种安装原理详解:源码包安装.RPM二进制安装.YUM在线安装.脚本安装包 一.Linux软件包分类 1.1 源码包 优点: 开源,如果有足够的能力,可以修改源代码: 可 ...
- TypeScript 函数-函数类型
//指定参数类型 function add(x:number,y:number){ console.log("x:"+x); // reutrn(x+y); } //指定函数类型 ...
- async与defer
<script>元素的几种常见属性: async 异步加载,立即下载,不应妨碍页面其他操作,标记为 async 的异步脚本并不保证按照指定的先后顺序执行,因此异步脚本不应该在加载期间修改 ...
- ES6-个人学习大纲
1,let const学习补充 1.1,let的知识点: 01-作用域只限制在当前代码块内,代码块形式如下: { var str = '张三'; console.log(str); let str ...
- 封装一个 员工类 使用preparedStatement 查询数据 (2) 使用 arrayList 集合
创建 员工=类生成 有参构造 get set 方法 toString 方法 package cn.hph; public class emp1 { //创建员工类的属性 private int id; ...
- 有关promise的技巧
其实promise的作用是将异步的代码转化为同步,这里的异步指的是request1,request2.
- Revisiting Network Support for RDMA
重新审视RDMA的网络支持 本文为SIGCOMM 2018会议论文. 笔者翻译了该论文.由于时间仓促,且笔者英文能力有限,错误之处在所难免:欢迎读者批评指正. 本文及翻译版本仅用于学习使用.如果有任何 ...