从URL到看到网页的过程
从我们输入URL并按下回车键到看到网页结果之间发生了什么?换句话说,一张网页,要经历怎样的过程,才能抵达用户面前?下面来从一些细节上面尝试一下探寻里面的秘密。
前言:键盘与硬件中断
说到输入URL,当然是从手敲键盘开始。对于键盘,生活中用到的最常见的键盘有两种:薄膜键盘、机械键盘。
薄膜键盘:由面板、上电路、隔离层、下电路构成。有外观优美、寿命较长、成本低廉的特点,是最为流行的键盘种类。键盘中有一整张双层胶膜,通过胶膜提供按键的回弹力,利用薄膜被按下时按键处碳心于线路的接触来控制按键触发。
机械键盘:由键帽、机械轴组成。键盘打击感较强,常见于游戏发烧友与打字爱好者。每一个按键都有一个独立的机械触点开关,利用柱型弹簧提供按键的回弹力,用金属接触触点来控制按键的触发。
键盘传输信号到操作系统后便会触发硬件中断处理程序。硬件中断是操作系统中提高系统效率、满足实时需求的非常重要的信号处理机制,它是一个异步信号,并提供相关中断的注册表(IDT)与请求线(IRQ)。键盘被按压时,将通过请求线将信号输入给操作系统,CPU在当前指令结束之后,根据注册表与信号响应该中断并利用段寄存器装入中断程序入口地址。具体可参看操作系统与汇编相关书籍。
当然本文主要不是介绍硬件与操作系统中的细节,前言只是想说明,从输入URL到浏览器展现结果页面之间有太多底层相关的知识,怀着一颗敬畏的心并且在有限的篇幅中是无法详细阐述的,所以本文会将关注点放在在一个稍高的角度上来看,从浏览器替我们发送请求之后到看到页面显示完成这中间中发生了什么事情,比如DNS解析、浏览器渲染。
浏览器解析URL
按下回车键之前
比如我按下一个‘b’键,会出现很多待选URL给我,第一个便是百度。那么其实是在浏览器接收到这个消息之后,会触发浏览器的自动完成机制,会在你之前访问过的搜索最匹配的相关URL,会根据特定的算法显示出来供用户选择。

按下回车键之后
依据上述键盘触发原理,一个专用于回车键的电流回路通过不同的方式闭合了。然后触发硬件中断,随之操作系统内核去处理对应中断。省略其中的过程,最后交给了浏览器这样一个“回车”信号。那么浏览器(本文涉及到的浏览器版本都为Chrome 61)会进行以下但不仅限于以下炫酷(乱七八糟)的步骤:
解析URL:您输入的是http还是https开头的网络资源 / file开头的文件资源 / 待搜索的关键字?然后浏览器进行对应的资源加载进程
URL转码:RFC标准中规定部分字符可以不经过转码直接用于URL,但是汉字不在范围内。所以如果在网址路径中包含汉字将会被转码
HSTS:鉴于HTTPS遗留的安全隐患,大部分现代浏览器已经支持HSTS。对于浏览器来说,浏览器会检测是否该网络资源存在于预设定的只使用HTTPS的网站列表,或者是否保存过以前访问过的只能使用HTTPS的网站记录,如果是,浏览器将强行使用HTTPS方式访问该网站。
DNS解析
不查DNS,读取缓存
浏览器中的缓存:对于Chrome,缓存查看地址为:chrome://net-internals/#dns
本地hosts文件:以Mac与Linux为例,hosts文件所在路径为:/etc/hosts。所以有一种翻墙的方式就是修改hosts文件避免GFW对DNS解析的干扰,直接访问真正IP地址,但已经不能完全生效因为GFW还有根据IP过滤的机制。
发送DNS查找请求
DNS的查询方式是:按根域名->顶级域名->次级域名->主机名这样的方式来查找的,对于某个URL,如下所示
123 |
|
查询步骤为:
查询本地DNS服务器。本地DNS服务器地址为连接网络时路由器指定的DNS地址,一般为DHCP自动分配的路由器地址,保存在/etc/resolv.conf,而路由器的DNS转发器将请求转发到上层ISP的DNS,所以此处本地DNS服务器是局域网或者运营商的。
从"根域名服务器"查到"顶级域名服务器"的NS记录和A记录(IP地址)。世界上一共有十三组根域名服务器,从A.ROOT-SERVERS.NET一直到M.ROOT-SERVERS.NET,由于已经将这些根域名服务器的IP地址存放在本地DNS服务器中。
从"顶级域名服务器"查到"次级域名服务器"的NS记录和A记录(IP地址)
从"次级域名服务器"查出"主机名"的IP地址
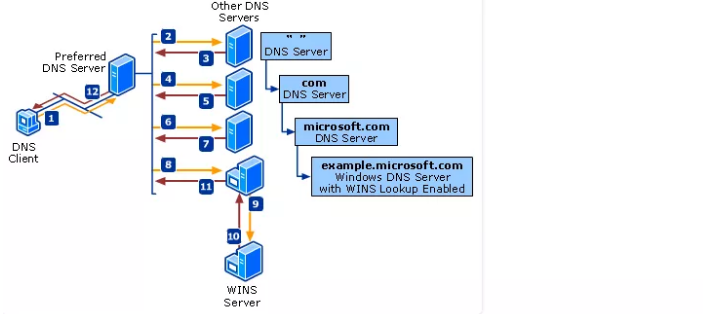
以www.google.com为例,下面是一整个DNS查询过程:
由于本次测试是在阿里云上的实例进行测试,所以首先从100.100.2.138这个阿里内网DNS服务器查找到所有根域名服务器的映射关系。
访问根域名服务器(f.root-servers.net),拿到com顶级域名服务器的NS记录与IP地址。
访问顶级域名服务器(e.gtld-servers.net),拿到google.com次级域名服务器的NS记录与IP地址。
访问次级域名服务器(ns2.google.com),拿到www.google.com的IP地址
12345678910111213141516171819202122232425262728293031323334353637383940 |
|
所以总的来说,DNS的解析是一个逐步缩小范围的查找过程。
建立HTTPS、TCP连接
确定发送目标
拿到IP之后,还需要拿到那台服务器的MAC地址才行,在以太网协议中规定,同一局域网中的一台主机要和另一台主机进行直接通信,必须要知道目标主机的MAC地址。所以根据ARP(根据IP地址获取物理地址的一个TCP/IP协议)获取到MAC地址之后保存到本地ARP缓存之后与目标主机准备开始通信。具体细节参见维基百科DHCH/ARP。
建立TCP连接
为什么握手一定要是三次?

第一次与第二次握手完成意味着:A能发送请求到B,并且B能解析A的请求
第二次与第三次握手完成意味着:A能解析B的请求,并且B能发送请求到A
这样就保证了A与B之间既能相互发送请求也能相互接收解析请求。同时避免了因为网络延迟产生的重复连接问题,比如A发送一次连接请求但网络延迟导致这次请求是在A重发连接请求并完成与B通信之后的,有三次握手的话,B返回的建立请求A就不会理睬了。
短连接与长连接?
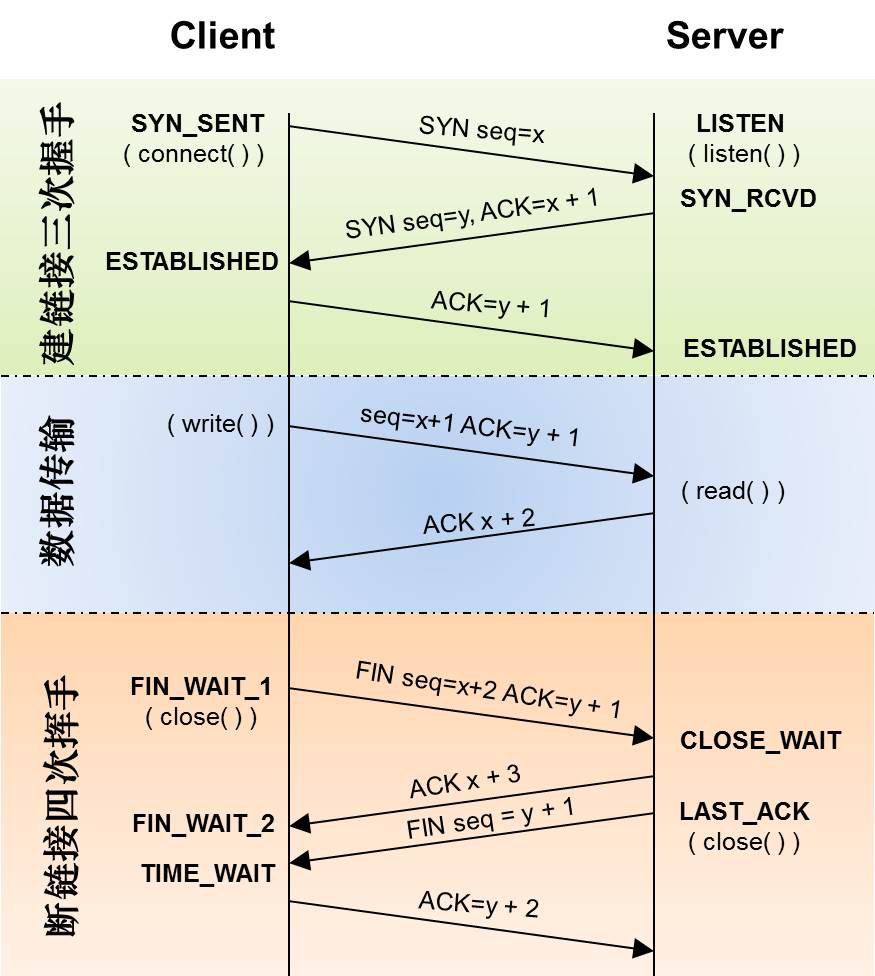
上图是一个短连接的过程演示,对于长连接,A与B完成一次读写之后,它们之间的连接并不会主动关闭,后续的读写操作会继续使用这个连接。另外,由于长连接的实现比较困难,需要要求长连接在没有数据通信时,定时发送数据包(心跳),以维持连接状态,并且长连接对于服务器的压力也会很大,所以推送服务对于一般的开发者是非常难以实现的,这样的话就出现了很多不同的大型厂商提供的消息推送服务。
进行TLS加密过程
Hello - 握手开始于客户端发送Hello消息。包含服务端为了通过SSL连接到客户端的所有信息,包括客户端支持的各种密码套件和最大SSL版本。服务器也返回一个Hello消息,包含客户端需要的类似信息,包括到底使用哪一个加密算法和SSL版本。
证书交换 - 现在连接建立起来了,服务器必须证明他的身份。这个由SSL证书实现,像护照一样。SSL证书包含各种数据,包含所有者名称,相关属性(域名),证书上的公钥,数字签名和关于证书有效期的信息。客户端检查它是不是被CA验证过的。注意服务器被允许需求一个证书去证明客户端的身份,但是这个只发生在敏感应用。
密钥交换 - 先使用RSA非对称公钥加密算法(客户端生成一个对称密钥,然后用SSL证书里带的服务器公钥将改对称密钥加密。随后发送到服务端,服务端用服务器私钥解密,到此,握手阶段完成。)或者DH交换算法在客户端与服务端双方确定一将要使用的密钥,这个密钥是双方都同意的一个简单,对称的密钥,这个过程是基于非对称加密方式和服务器的公钥/私钥的。
加密通信 - 在服务器和客户端加密实际信息是用到对称加密算法,用哪个算法在Hello阶段已经确定。对称加密算法用对于加密和解密都很简单的密钥,这个密钥是基于第三步在客户端与服务端已经商议好的。与需要公钥/私钥的非对称加密算法相反。
服务端的处理
静态缓存、CDN
为了优化网站访问速度并减少服务器压力,通常将html、js、css、文件这样的静态文件放在独立的缓存服务器或者部署在类似Amazon CloudFront的CDN云服务上,然后根据缓存过期配置确定本次访问是否会请求源服务器来更新缓存。
负载均衡
负载均衡具体实现有多种,有直接基于硬件的F5,有操作系统传输层(TCP)上的 LVS,也有在应用层(HTTP)实现的反向代理(也叫七层代理),下面简单介绍一下最后者。
在请求发送到真正处理请求的服务器之前,还需要将请求路由到适合的服务器上,一个请求被负载均衡器拿到之后,需要做一些处理,比如压缩请求(在nginx中gzip压缩格式是默认配置在nginx.conf内的,所以默认开启,如果不对数据量要求特别精细的话,默认配置完全可以满足基本需求)、接收请求(接收完毕后才发给Server,提高Server处理效率),然后根据预定的路由算法,将此次请求发送到某个后台服务器上。
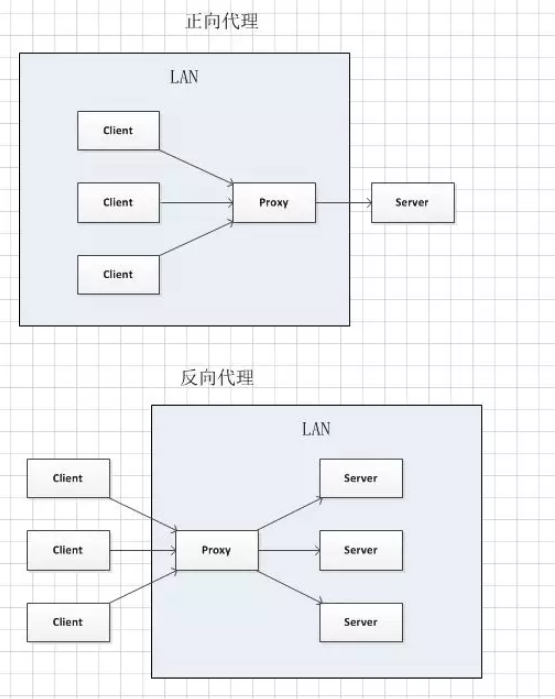
其中需要提到的一点是反向代理,先回顾一下反向代理的原理:正向代理是将自己要访问的资源告诉Proxy,让Proxy帮你拿到数据返回给你,Proxy服务于Client,常用于翻墙和跨权限操作;反向代理也是将自己要访问的资源告诉Proxy,让Proxy帮你拿到数据返回给你,但是Proxy服务于Server,它会将请求接受完毕之后发送给某一合适的Server,这个时候Client是不知道是根据什么规则并且也不知道最后是哪一个Server服务于它的,所以叫反向代理,常用于负载均衡、安全控制.
服务器的处理
对于HTTPD(HTTP Daemon)在服务器上部署,最常见的 HTTPD 有 Linux 上常用的 Apache 和 Nginx。对于Java平台来说,Tomcat是Spring Boot也会默认选用的Servlet容器实现,Tomcat对于请求的处理如下:
请求到达Tomcat启动时监听的TCP端口。
解析请求中的各种信息之后创建一个Request对象并填充那些有可能被所引用的Servlet使用的信息,如参数,头部、cookies、查询字符串等。
创建一个Response对象,所引用的Servlet使用它来给客户端发送响应。
调用Servlet的service方法,并传入Request和Response对象。这里Servlet会从Request对象取值,给Response写值。
根据我们自己写的Servlet程序或者框架携带的Servlet类做进一步的处理(业务处理、请求的进一步处理)
最后根据Servlet返回的Response生成相应的HTTP响应报文。
浏览器的渲染
浏览器的功能是从服务器上取回你想要的资源,然后展示在浏览器窗口当中。资源通常是 HTML 文件,也可能是 PDF,图片,或者其他类型的内容。也可以显示其他类型的插件(浏览器扩展)。例如显示PDF使用PDF浏览器插件。资源的位置通过用户提供的 URI(Uniform Resource Identifier) 来确定。
浏览器解释和展示 HTML 文件的方法,在 HTML 和 CSS 的标准中有详细介绍。这些标准由 Web 标准组织 W3C(World Wide Web Consortium) 维护。

下面会以Chrome中使用的浏览器引擎Webkit为例,根据上图来简单介绍浏览器的渲染。具体解析、渲染会涉及到非常多的细节,请参考HTML5渲染规范和对应的页面GPU渲染实现。
HTML解析
浏览器拿到具体的HTML文档之后,需要调用浏览器中使用的浏览器引擎中处理HTML的工具(HTML Parser)来将HTML文档解析成为DOM树,将以便外部接口(JS)调用。
文档内容解析:将一大串字符串解析为DOM之前需要从中分析出结构化的信息让HTML解析器可以很方便地提取数据进行其他操作,所以对于文档内容的解析是第一步。解析器有两个处理过程——词法分析(将字符串切分成符合特定语法规范的符号)与语法分析(根据符合语法规范的符号构建对应该文档的语法树)。
HTML解析:根据HTML语法,将HTML标记到语法树上构建成DOM(Document Object Model)。
CSS解析
根据CSS词法和句法分析CSS文件和<style>标签包含的内容以及style属性的值
每个CSS文件都被解析成一个样式表对象(StyleSheet object),这个对象里包含了带有选择器的CSS规则,和对应CSS语法的对象
页面渲染
解析完成后,浏览器引擎会通过DOM树和CSS Rule树来构造渲染树。渲染树的构建会产生Layout,Layout是定位坐标和大小,是否换行,各种position, overflow, z-index属性的集合,也就是对各个元素进行位置计算、样式计算之后的结果。
接下来,根据渲染树对页面进行渲染(可以理解为“画”元素)。
当然,将这个渲染的过程完成并显示到屏幕上会涉及到显卡的绘制,显存的修改,有兴趣的读者可以深入了解。
从URL到看到网页的过程的更多相关文章
- 转:从输入url到显示网页发生了什么
在浏览器中输入url到显示网页主要包含两个部分: 网络通信和页面渲染 互联网内各网络设备间的通信都遵循TCP/IP协议,利用TCP/IP协议族进行网络通信时,会通过分层顺序与对方进行通信.分层由高到低 ...
- spring-mvc实现模拟数据到网页展示过程代码
spring-mvc实现模拟数据到网页展示过程代码 先看看我们的3种模拟数据到网页展示的思路图: 1.当mybatis的环境配置完成.一个动态Web项目建立好.开始导入jar包. -spring的ao ...
- 从输入url到显示网页发生了什么
原文链接:https://juejin.im/post/5bf23afa6fb9a049be5d1494 在浏览器中输入url到显示网页主要包含两个部分: 网络通信和页面渲染 互联网内各网络设备间的通 ...
- 一文摸透从输入URL到页面渲染的过程
一文摸透从输入URL到页面渲染的过程 从输入URL到页面渲染需要Chrome浏览器的多个进程配合,所以我们先来谈谈现阶段Chrome浏览器的多进程架构. 一.Chrome架构 目前Chrome采用的是 ...
- 从输入 URL 到浏览器接收的过程中发生了什么事情
从输入 URL 到浏览器接收的过程中发生了什么事情? 原文:http://www.codeceo.com/article/url-cpu-broswer.html 从触屏到 CPU 首先是「输入 U ...
- 从输入 URL 到浏览器接收的过程中发生了什么事情?
从输入 URL 到浏览器接收的过程中发生了什么事情? What really happens when you navigate to a URL 上面两篇文章都解读的很好,值得阅读. 接下来在总结一 ...
- C# HttpWebRequest 绝技 根据URL地址获取网页信息
如果要使用中间的方法的话,可以访问我的帮助类完全免费开源:C# HttpHelper,帮助类,真正的Httprequest请求时无视编码,无视证书,无视Cookie,网页抓取 1.第一招,根据URL地 ...
- 【转载】ASP.NET MVC重写URL制作伪静态网页,URL地址以.html结尾
在搜索引擎优化领域,静态网页对于SEO的优化有着很大的好处,因此很多人就想把自己的网站的一些网页做成伪静态.我们现在在网络上发现很多博客网站.论坛网站.CMS内容管理系统等都有使用伪静态这一种情况,伪 ...
- 用户对动态PHP网页访问过程,以及nginx解析php步骤
www.example.com | Nginx | 路由到www.example.com/index.php | 加载nginx的fast-cgi模块 | fast-cgi监听127.0.0.1:90 ...
随机推荐
- Hadoop 集群安装(从节点安装配置)
1.Java环境配置 view plain copy sudo mv /tmp/java /opt/ jdk安装完配置环境变量,编辑/etc/profile: view plain copy sudo ...
- CentOS 7 安装配置 OpenVPN 客户端
安装 epel yum 源: $ rpm -ivh http://mirrors.sohu.com/fedora-epel/6/x86_64/epel-release-6-8.noarch.rpm $ ...
- 混合物App开发中,在移动设备上调试查看日志,重写window.console
(function(){ var print={ lock:true, log:function(param){ if(this.lock){ var element=document.createE ...
- laytpl模板——怎么使用ajax与数据交互
第一次在项目中用laytpl模板,下面是一些使用过程中的探索,希望对小伙伴们有所帮助. 注:第一次使用这个模板的小伙伴建议先去看看官网 laytpl <script type="tex ...
- [Swift]LeetCode891. 子序列宽度之和 | Sum of Subsequence Widths
Given an array of integers A, consider all non-empty subsequences of A. For any sequence S, let the ...
- python之高阶函数和匿名函数
map() map()函数接收两个参数,一个是函数,一个是Iterable,map将传入的函数依次作用到序列的每个元素,并把结果作为新的Iterator返回. def func(x): return ...
- 【实战分享】又拍云 OpenResty / Nginx 服务优化实践
2018 年 11 月 17 日,由 OpenResty 主办的 OpenResty Con 2018 在杭州举行.本次 OpenResty Con 的主题涉及 OpenResty 的新开源特性.业界 ...
- 运行PHP后台项目:xampp下载,安装,配置,运行PHP的web项目
本来没有想着弄PHP,但是有同学叫我帮忙启动一下一个PHP写的后台.着实需要去学习一下. 想着安装xampp软件,一个集合了多个服务器,多个数据库,多个后台语言的管理软件. 一.xampp下载 二.安 ...
- 单机部署redis5.0集群环境
#安装rediscd redis-5.0.0makemake install #部署集群mkdir redis_clustermkdir -p redis_cluster/{7000,7001,700 ...
- 使用npm安装配置vue
npm安装很慢(国外服务器),所以一般推荐使用npm淘宝镜像cnpm,先安装下cnpm: npm install -g cnpm --registry=https://registry.npm.tao ...