hive的join
第一:在map端产生join
- set hive.auto.convert.join=true;
这样设置,hive就会自动的识别比较小的表,继而用mapJoin来实现两个表的联合。看看下面的两个表格的连接。这里的dept相对来讲是比较小的。我们看看会发生什么,如图所示:

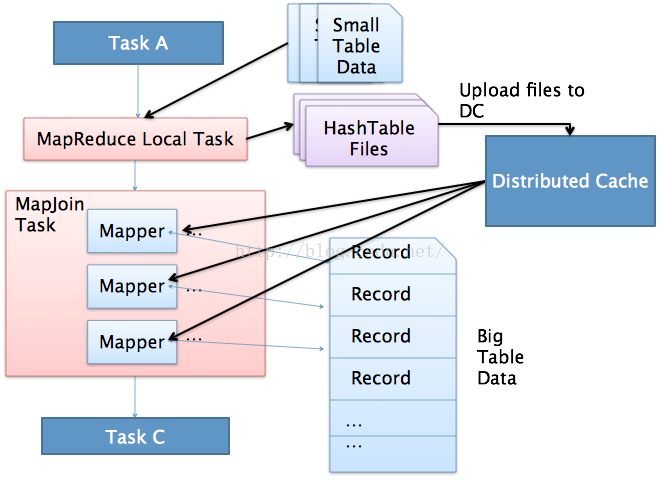
第二:common join

- set hive.auto.convert.sortmerge.join=true;
- set hive.optimize.bucketmapjoin = true;
- set hive.optimize.bucketmapjoin.sortedmerge = true;
- set hive.auto.convert.sortmerge.join.noconditionaltask=true;
- create table emp_info_bucket(ename string,deptno int)
- partitioned by (empno string)
- clustered by(deptno) into 4 buckets;
- insert overwrite table emp_info_bucket
- partition (empno=7369)
- select ename ,deptno from emp
- create table dept_info_bucket(deptno string,dname string,loc string)
- clustered by (deptno) into 4 buckets;
- insert overwrite table dept_info_bucket
- select * from dept;
- select * from emp_info_bucket emp join dept_info_bucket dept
- on(emp.deptno==dept.deptno);//正常的情况下,应该是启动smbjoin的但是这里的数据量太小啦,还是启动了mapjoin
hive的join的更多相关文章
- HIVE: Map Join Vs Common Join, and SMB
HIVE Map Join is nothing but the extended version of Hash Join of SQL Server - just extending Hash ...
- hive:join操作
hive的多表连接,都会转换成多个MR job,每一个MR job在hive中均称为Join阶段.按照join程序最后一个表应该尽量是大表,因为join前一阶段生成的数据会存在于Reducer 的bu ...
- Hive中Join的原理和机制
转自:http://lxw1234.com/archives/2015/06/313.htm 笼统的说,Hive中的Join可分为Common Join(Reduce阶段完成join)和Map Joi ...
- Hive的join表连接查询的一些注意事项
Hive支持的表连接查询的语法: join_table: table_reference JOIN table_factor [join_condition] | table_reference {L ...
- hive的join查询
hive的join查询 语法 join_table: table_reference [INNER] JOIN table_factor [join_condition] | table_refere ...
- Hive 中Join的专题---Join详解
1.什么是等值连接? 2.hive转换多表join时,如果每个表在join字句中,使用的都是同一个列,该如何处理? 3.LEFT,RIGHT,FULL OUTER连接的作用是什么? 4.LEFT或RI ...
- Hive中Join的类型和用法
关键字:Hive Join.Hive LEFT|RIGTH|FULL OUTER JOIN.Hive LEFT SEMI JOIN.Hive Cross Join Hive中除了支持和传统数据库中一样 ...
- Hive 基本语法操练(五):Hive 的 JOIN 用法
Hive 的 JOIN 用法 hive只支持等连接,外连接,左半连接.hive不支持非相等的join条件(通过其他方式实现,如left outer join),因为它很难在map/reduce中实现这 ...
- hive的join优化
“国际大学生节”又称“世界大学生节”.“世界学生日”.“国际学生日”.1946年,世界各国学生代表于布拉格召开全世界学生大会,宣布把每年的11月17日定为“世界大学生节”,以加强全世界大学生的团结和友 ...
- [Hadoop大数据]——Hive连接JOIN用例详解
SQL里面通常都会用Join来连接两个表,做复杂的关联查询.比如用户表和订单表,能通过join得到某个用户购买的产品:或者某个产品被购买的人群.... Hive也支持这样的操作,而且由于Hive底层运 ...
随机推荐
- SqlServer存储过程及函数
存储过程和函数类似于Java中的方法. ⒈存储过程 一组预先编译好的sql语句的集合,理解成批处理语句. 好处: ①提高代码的重用性 ②简化操作 ③减少了编译次数并且减少了和数据库服务器的连接次数,提 ...
- Spring Cloud 2-Bus 消息总线(九)
Spring Cloud Bus 1.服务端配置 pom.xml application.yml 2.客户端配置 pom.xml application.yml Controller.java 3 ...
- Spring Cloud 2-RabbitMQ 集成(八)
Spring Cloud RabbitMQ pom.xml application.yml 提供者 消费者 队列配置 单元测试 通过消息队列MQ做为通信中心,这里采用RabbitMQ.安装方参考: ...
- python3.5 默认安装路径 | 安装 | 删除
win7 环境下: Python3.5默认安装路径是当前用户的 AppData\.. 下 这么做的一个可能原因是 现在安装过程中默认是install just for me,这个会把python默认 ...
- DEV控件GridControl常用属性设置(转)
1. 如何解决单击记录整行选中的问题 View->OptionsBehavior->EditorShowMode 设置为:Click 2. 如何新增一条记录 (1).gridView. ...
- Linux下定时备份文件
一. 编写脚本 编写一个脚本文件,使脚本可以执行备份命令. 例如,将文件目录 /home/backups/balalala 备份到/home目录下,并压缩. 1. 创建脚本 命令格式: touch 路 ...
- C# 操作Session、Cookie,Url 编码解码工具类WebHelper
using System; using System.Collections.Generic; using System.IO; using System.Net; using System.Text ...
- js-图片预加载
//图片预加载 //闭包模拟局部作用于 (function($){ function Preload(imgs,options){ this.imgs = (typeof imgs === 'st ...
- MySQL存储过程中的事务执行失败之后获取错误信息
1.表结构: 2. 存储过程中: 代码如下: BEGINDECLARE CONTINUE HANDLER FOR SQLEXCEPTIONBEGINROLLBACK;GET DIAGNOSTICS C ...
- P2255 [USACO14JAN]记录奥林比克
P2255 [USACO14JAN]记录奥林比克 题目描述 农民约翰热衷于所有寒冷天气的运动(尤其是涉及到牛的运动), 农民约翰想录下尽可能多的电视节目. 为moolympics电视时间表由N个不同的 ...