Linux之数据库操作
一、mysql基本操作
,连接数据库
mysql -u root -p -h 127.0.0.1
mysql -u root -p -h 192.168.12.56
,授予远程连接的权限
grant all privileges on *.* to root@"%" identified by "nihao123"
,修改root用户的密码
先进入mysql的交互式模式
set password = PASSWORD('redhat123');
,创建mysql用户
create user zijin@"%" identified by "zijin"
,给予zijin用户查询所有库和所有表的权限
grant select on *.* to zijin@"%" identified by "zijin"
,查询mysql库中的用户信息
use mysql;
select host,user,password from user;
,给予zijin用户创建所有库和表的权限,再给修改权限,再给删除权限
grant create on *.* to zijin@"%" identified by "zijin"
grant update on *.* to zijin@"%" identified by "zijin"
grant delete on *.* to zijin@"%" identified by "zijin"
,授予mysql权限的语法
mysql使用grant命令对账户进行授权,grant命令常见格式如下
grant 权限 on 数据库.表名 to 账户@主机名 对特定数据库中的特定表授权
grant 权限 on 数据库.* to 账户@主机名 对特定数据库中的所有表给与授权
grant 权限1,权限2,权限3 on *.* to 账户@主机名 对所有库中的所有表给与多个授权
grant all privileges on *.* to 账户@主机名 对所有库和所有表授权所有权限
,移出zijin的创建权限
revoke create on *.* from zijin@"%" identified by 'zijin';
revoke delete on *.* from zijin@"%" identified by 'zijin;
,数据库备份与恢复
mysqldump -u root -p --all-databases > /tmp/db.sql #这不是在数据库环境下
可以备份单个数据库
mysqldump -u root -p luffycity > /tmp/luffycity.sql
,导入数据
第一种:
进入mysql交互模式
source /tmp/luffycity.sql;
第二种:
mysql -u root -p < /tmp/luffycity.sql
第三种:
navicat
二,mariadb主从复制部署
1, 准备两台机器
192.168.12.56 #主服务器master(可读可写)
mariadb数据库用户名:root
密码:root1
192.168.12.81 #从服务器slave(可读)
mariadb数据库用户名:root
密码:root2
2, 配置主数据库
2.1 修改主数据库配置文件
,进入配置文件
vim /etc/my.cnf
,添加配置信息
[mysqld] # 如果配置文件里面有这一行,就只需要加以下两行配置就可以了
server-id=
log-bin=qishi2-logbin
2.2 进入数据库
systemctl start mariadb
2.3 创建主从复制用户
1,进入数据库
mysql -uroot -p
2,创建用户
create user zijin@'%' identified by 'zijin';
2.4 给从库账号授权
grant replication slave on *.* to 'zijin'@'%';
2.5 把主库数据导入从库
,实现对主数据库锁表只读,防止数据写入,数据复制失败
flush table with read lock;
,查看并记录主数据库的状态
show master status;
,导出主数据库的数据为alldb.sql
mysqldump -u root -p --all-databases > /opt/alldb.sql #这个是在数据库环境外
,scp /opt/alldb.sql 192.168.12.81:/opt/

3,配置从数据库
3.1 修改从数据库的配置文件
,进入配置文件
vim /etc/my.cnf
,添加信息
[mysqld]
server-id=
read-only=true
3.2 启动数据库
systemctl start mariadb
3.3 导入主库的数据
,连接数据库
mysql -u root -p
,导入数据
source /opt/alldb.sql
3.4 配置复制的参数,slave从库连接master主库的配置(最重要的)
在数据库的环境下输入:
change master to master_host='192.168.12.64',
master_user='zijin',
master_password='zijin',
master_log_file='qishi2-logbin.000004',
master_log_pos=;
3.5 启动从库的同步开关
start slave #开启
stop slave #停止
3.6 查看从库的状态
show slave status;
还可以输show slave status /G;
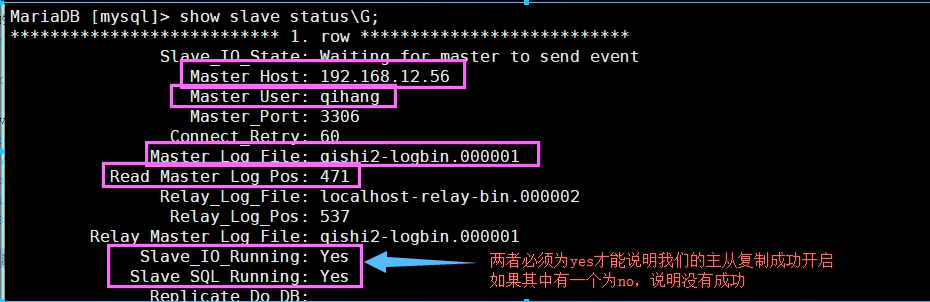
3,主库再设置
3.1 从库数据导入完毕和开启主从同步后,解锁主库
unlock tables; #在主库下
3.2验证主从复制情况
在主库上创建数据,查看从库数据同步状态
3.3 在主库上给zijin用户select权限,并刷新权限表
grant select on *.* to zijin@"%" identified by "zijin";
flush privileges;
3.4 在从库上登录zijin用户,并试图创建一个库
create database aaaa; ERROR (HY000): The MariaDB server is running with the --read-only option so
it cannot execute this statement #说明从库没有新建的权限
三、redis发布订阅和持久化
1,redis发布订阅
1.1基本命令
PUBLISH channel msg
将信息 message 发送到指定的频道 channel SUBSCRIBE channel [channel ...]
订阅频道,可以同时订阅多个频道 UNSUBSCRIBE [channel ...]
取消订阅指定的频道, 如果不指定频道,则会取消订阅所有频道
PSUBSCRIBE pattern [pattern ...]
订阅一个或多个符合给定模式的频道,每个模式以 * 作为匹配符,比如 it* 匹配所 有以 it 开头的频道
( it.news 、 it.blog 、 it.tweets 等等), news.* 匹配所有 以 news. 开头的频道
( news.it 、 news.global.today 等等),诸如此类
PUNSUBSCRIBE [pattern [pattern ...]]
退订指定的规则, 如果没有参数则会退订所有规则
PUBSUB subcommand [argument [argument ...]]
查看订阅与发布系统状态
注意:使用发布订阅模式实现的消息队列,当有客户端订阅channel后只能收到后续发布到该频道的消息,之前发送的不会缓存,
必须Provider和Consumer同时在线。
1.2发布订阅案例
发布者
[root@web02 ~]# redis-cli
127.0.0.1:> PUBLISH diantai 'jinyewugenglaiwojia'
(integer) 订阅者1
[root@web02 ~]# redis-cli
127.0.0.1:> SUBSCRIBE diantai
Reading messages... (press Ctrl-C to quit)
) 'jinyewugenglaiwojia'
) (integer) 订阅者2
[root@web02 ~]# redis-cli
127.0.0.1:> SUBSCRIBE diantai
Reading messages... (press Ctrl-C to quit)
) 'jinyewugenglaiwojia'
) (integer)
1.3 订阅模糊匹配的频道案例
发布者
[root@web02 ~]# redis-cli
127.0.0.1:> PUBLISH wangbaoqiang "jintian zhennanshou "
(integer) 订阅者1
127.0.0.1:> PSUBSCRIBE wang*
Reading messages... (press Ctrl-C to quit)
) "jintian zhennanshou "
) (integer) 订阅者2
127.0.0.1:> PSUBSCRIBE wa*
Reading messages... (press Ctrl-C to quit)
) "jintian zhennanshou "
) (integer)
2,redis持久化之RDB
2.1 创建redis配置文件
vim /opt/redis_conf/reids-.conf
2.2 写入信息
port
daemonize yes
dir /data/
pidfile /data//redis.pid
loglevel notice
logfile "/data/6379/redis.log"
protected-mode yes
dbfilename dbmp.rdb
save
save
save
2.3 进入redis数据库,写入数据,并使用save命令开启rdb持久化
redis-cli set name liujie
set age
set sex nam save # 开启rdb持久化, 也可以不用
3,redis之AOF持久化
3.1 修改redis配置文件
,进入配置文件
vim /opt/redis_conf/redis-.con
,写入配置信息
appendonly yes
appendfsync everysec
3.2 重启redis服务
pkill reids
redis-server /opt/redis_conf/redis-.conf
3.3 不用重启redis,直接从RDB切换到AOF(因为生产环境中是不允许停止redis)
,修改redis配置文件
daemonize yes
port
logfile /data//redis.log
dir /data/
dbfilename dbmp.rdb
save #rdb机制 每900秒 有1个修改记录
save #每300秒 10个修改记录
save #每60秒内 10000修改记录 ,启动redis服务端
redis-server redis.conf ,写入数据
127.0.0.1:> set name tiger
OK
127.0.0.1:> set age
OK
127.0.0.1:> set addr daxuecheng
OK
127.0.0.1:> save
OK ,检查rdb文件是否存在,然后备份rdb文件(这是生成环境中需要做的,以免切换不成功导致数据丢失) ,开启AOF持久化
CONFIG set appendonly yes # 开启AOF功能
CONFIG SET save "" # 关闭RDB功能
四、redis主从同步
1,准备三个redis配置文件
cd /opt/redis_conf redis-.conf # 主数据库master
redis-.conf # 从库slave
redis-.conf # 从库slave
2,在配置文件写入配置信息,是哪个内容一样,只是端口不一样而已
port
daemonize yes
pidfile /data//redis.pid
loglevel notice
logfile "/data/6380/redis.log"
dbfilename dump.rdb
dir /data/
protected-mode no 可以使用这一条命令通过redis-.conf生成6381和6382的配置文件
sed "s/6380/6381/g" redis-.conf > redis-.conf
sed "s/6380/6382/g" redis-.conf > redis-.conf
3,在6381和6382文件中加入以下配置,使其成为从数据库
slaveof 127.0.0.1
4,开启这三个redis服务,确保启动正常,并查看状态
1,首先开启是三个redis服务
redis-server /opt/redis_conf/redis-6380.conf
redis-server /opt/redis_conf/redis-6381.conf
redis-server /opt/redis_conf/redis-6382.conf
2,用三个客户端连接
redis-cli -p info replication
redis-cli -p info replication
redis-cli -p info replication
5,验证redis主从复制功能
,6380写入数据,在6381和6382中查看数据是否同步
,看是否能在6381和6382中写入数据(正常情况下是不能的)
6,手动切换主从复制
也就是当6380进程死掉后,相当于主库没了,此时就需要从6381和6382中选择一个作为主库,完成主从复制切换
6.1 把最开始的主库6380进程给杀死
kill - 进程id
6.2 在6382的redis下执行这条命令(此时我们选择6382为主库)
slaveof no one
6.2 此时6381为从库,把原来的主库指向改为6382
slaveof no one
slaveof 127.0.0.1
6.3 可以验证此时的主从复制功能
1,在6382上写入数据,在6381上查看数据(正常情况下是数据同步的)
2,在6381上写数据(正常情况下为报错)
7,哨兵sentinel
对于第6步来说,必须要我们手动切换主从配置,其实是不科学的,所以,大佬开发了哨兵sentinel,用哨兵去监控主库,当主库挂掉的时候,哨兵从从库中决策出一个新的主库,剩余的从库就作为新的主库的从库。
7.1准备三个哨兵配置文件
touch /opt/redis_conf/redis-26380.conf
touch /opt/redis_conf/redis-26381.conf
touch /opt/redis_conf/redis-26382.conf
7.2修改redis-26380.conf配置文件
port 26380
dir /var/redis/data/
logfile "26380.log"
sentinel monitor qishi2master 127.0.0.1 6380 2
sentinel down-after-milliseconds qishi2master 30000
sentinel parallel-syncs qishi2master 1
sentinel failover-timeout qishi2master 180000
daemonize yes
7.3再配置另外两个哨兵
sed "s/26380/26381/g" redis-26380.conf > redis-26381.conf
sed "s/26380/26382/g" redis-26380.conf > redis-26382.conf
7.4启动是三个哨兵
redis-sentinel /opt/redis_conf/redis-26380.conf
redis-sentinel /opt/redis_conf/redis-26381.conf
redis-sentinel /opt/redis_conf/redis-26382.conf
7.5查看进程
ps -ef | grep redis-sentinel
7.6可以查看三个哨兵的状态
redis-cli -p 26380 info sentinel
redis-cli -p 26381 info sentinel
redis-cli -p 26382 info sentinel
7.7测试,把主库干掉
1,查看主库进程id
ps -ef | grep redis
2,杀死主库进程
kill -9 主库进程ID
3,查看6381和6382的状态
redis-cli -p 6381 info replication
redis-cli -p 6381 info replication
五、redis集群
1,准备6个配置文件
,我们把集群的配置文件放在/opt/redis_conf/redis_cluster目录
mkdir /opt/redis_conf/redis_cluster
,创建配置文件
cd redis_cluster
touch redis-.conf redis-.conf redis-.conf redis-.conf redis-.conf redis-.conf
2,往配置文件中添加配置信息
,进入redis-.conf
vim redis-.conf
,写入如下配置信息
port
daemonize yes
dir "/opt/redis/data"
logfile "/opt/redis/logs/6000.log"
dbfilename "dump-6000.rdb"
cluster-enabled yes # 开启集群模式
cluster-config-file nodes-.conf # 集群内部的配置文件
cluster-require-full-coverage no # redis cluster需要16384个slot都正常的时候才能对外提供服务,
换句话说,只要任何一个slot异常那么整个cluster不对外提供服务。 因此生产环境一般为no
,配置其他5个配置文件
sed "s/6000/6001/g" redis-.conf > redis-.conf
sed "s/6000/6002/g" redis-.conf > redis-.conf
sed "s/6000/6003/g" redis-.conf > redis-.conf
sed "s/6000/6004/g" redis-.conf > redis-.conf
sed "s/6000/6005/g" redis-.conf > redis-.conf
3,启动这6个redis集群节点
redis-server redis-.conf
redis-server redis-.conf
redis-server redis-.conf
redis-server redis-.conf
redis-server redis-.conf
redis-server redis-.conf 2,查看进程
ps -ef | grep redis
现在是无法往节点上添加数据的,因为哈希槽还没分配
我们需要使用redis-trib.rb去分配集群的哈希槽,但这个脚本需要使用ruby环境去执行,所以我们需要安装ruby解释器
4,安装ruby解释器
下载ruby
wget https://cache.ruby-lang.org/pub/ruby/2.3/ruby-2.3.1.tar.gz 安装ruby
tar -xvf ruby-2.3..tar.gz
cd ruby-2.3./
./configure --prefix=/opt/ruby/
make && make install 配置ruby的环境变量
vim /etc/profile
写入如下配置
PATH=$PATH:/opt/ruby/bin
,读取
source /etc/profile
5,安装ruby gem包管理工具
下载gem包管理工具
wget http://rubygems.org/downloads/redis-3.3.0.gem 安装
gem install -l redis-3.3..gem
6,开启集群
/opt/redis-4.0./src/redis-trib.rb create --replicas 127.0.0.1: 127.0.0.1: 127.0.0.1:
127.0.0.1: 127.0.0.1: 127.0.0.1: 命令说明:
--replicas # 表示进行身份授权
# 表示每个主节点,只有一个从节点 # 集群会自动分配主从关系 、、6002为主服务器master 、、6005为从服务器slave
7,可以查看集群状态与槽位
redis-cli -p cluster info
redis-cli -p cluster info
redis-cli -p cluster info
redis-cli -p cluster info
redis-cli -p cluster info
redis-cli -p cluster info
8,使用命令连接redis集群
redis-cli -p -c
-c 参数表示连接集群
Linux之数据库操作的更多相关文章
- linux mysql 数据库操作导入导出 数据表导出导入
linux mysql 数据库操作导入导出 数据表导出导入 1,数据库导入 mysql -uroot -p show databases; create database newdb; use 数据库 ...
- Oracle Linux下数据库操作的相关问题
1.su - oracle 切换到oracle用户 lsnrctl status 查看数据库监听状态 lsnrctl start 打开数据库监听 2.Connected to an idle inst ...
- linux中mysql,mongodb,redis,hbase数据库操作
.实验内容与完成情况:(实验具体步骤和实验截图说明) (一) MySQL 数据库操作 学生表 Student Name English Math Computer zhangsan lisi 根据上面 ...
- python之数据库操作
数据库操作 Python 操作 Mysql 模块的安装 1 2 3 4 5 linux: yum install MySQL-python window: http://files ...
- Python Paramiko模块与MySQL数据库操作
Paramiko模块批量管理:通过调用ssh协议进行远程机器的批量命令执行. 要使用paramiko模块那就必须先安装这个第三方模块,仅需要在本地上安装相应的软件(python以及PyCrypto), ...
- Python之路【第九篇】堡垒机基础&数据库操作
复习paramiko模块 Python的paramiko模块,是基于SSH用于连接远程服务器并执行相关操作. SSHClient #!/usr/bin/env python #-*- coding:u ...
- Linux下数据库的安装和使用
数据库有多重要就不用说了,每一个计算机相关行业的人都必须要学会基本的数据库操作,因为你总会用到的. 之前转过一些学习资源: 与MySQL的零距离接触 - 慕课网 Python操作MySQL数据库 生物 ...
- android中的数据库操作
如何在android中调用数据库资源 在android中主要有两种方法来实现对数据库的访问,一种是adb shell方式,另一种是通过相关的android 的java类来间接的对数据库来进行操作.其中 ...
- Python之路【第八篇】:堡垒机实例以及数据库操作
Python之路[第八篇]:堡垒机实例以及数据库操作 堡垒机前戏 开发堡垒机之前,先来学习Python的paramiko模块,该模块机遇SSH用于连接远程服务器并执行相关操作 SSHClient ...
随机推荐
- Java拦截器的实现原理
对于某个类的A方法进行拦截,在A执行前插入一段代码,A执行后也插入一段代码 原理: 写个拦截器,拦截器中包含要插入前后执行的两段代码 interceptor { C();//C方法 D();//D方法 ...
- SQL Server查询重复数据
1.查询单列重复: select * from test where name in (select name from test group by name having count (name) ...
- 关于A2C算法
https://github.com/sweetice/Deep-reinforcement-learning-with-pytorch/blob/master/Char4%20A2C/A2C.py ...
- Matlab调用遗传工具箱复现论文模型求解部分
原文转载自:https://blog.csdn.net/robert_chen1988/article/details/52431594 论文来源: https://www.sciencedirect ...
- async与defer
<script>元素的几种常见属性: async 异步加载,立即下载,不应妨碍页面其他操作,标记为 async 的异步脚本并不保证按照指定的先后顺序执行,因此异步脚本不应该在加载期间修改 ...
- 单点登录实现原理(SSO)
简介 单点登录是在多个应用系统中,用户只需要登录一次就可以访问所有相互信任的应用系统的保护资源,若用户在某个应用系统中进行注销登录,所有的应用系统都不能再直接访问保护资源,像一些知名的大型网站,如:淘 ...
- mysql的必知技巧
1.使用联合索引可以大大减少查询数据,联合索引的顺序尽量为查询的顺序
- linux 使用sh@d0ws0cks server
[root@linux-node1 ~]# cat /etc/shadowsocks.json { "server":"x.x.x.x", , "lo ...
- FBOSS: Building Switch Software at Scale
BOSS: 大规模环境下交换机软件构建 本文为SIGCOMM 2018 论文,由Facebook提供. 本文翻译了论文的关键内容. 摘要: 在网络设备(例如交换机和路由器)上运行的传统软件,通常是由供 ...
- postman run之前需要手动调整顺序
最近刚入坑postman,记录下遇到的坑: 1.先用postman interceptor录制好脚本,在postman中,将History的脚本导入Collections,由于项目接口之间需要toke ...