Scrapy案例02-腾讯招聘信息爬取
1. 目标
目标:https://hr.tencent.com/position.php?&start=0#a
爬取所有的职位信息信息
- 职位名
- 职位url
- 职位类型
- 职位人数
- 工作地点
- 发布时间
2. 网站结构分析
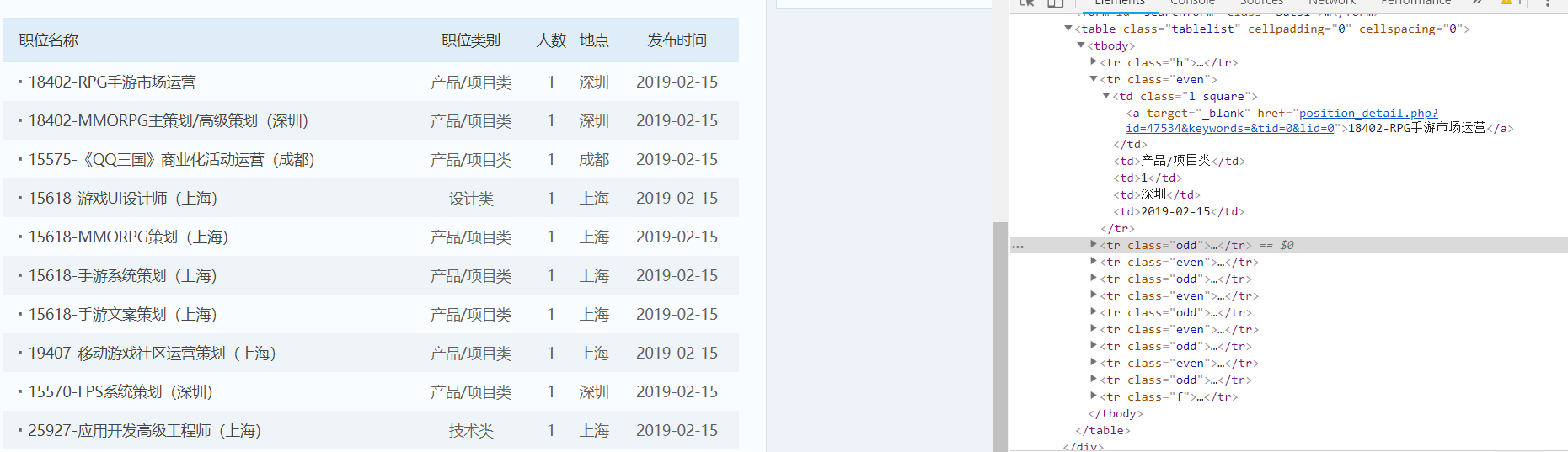
3. 编写爬虫程序
3.1. 配置需要爬取的目标变量
class TecentjobItem(scrapy.Item):
# define the fields for your item here like:
positionname = scrapy.Field()
positionlink = scrapy.Field()
positionType = scrapy.Field()
peopleNum = scrapy.Field()
workLocation = scrapy.Field()
publishTime = scrapy.Field()
3.2. 写爬虫文件scrapy
# -*- coding: utf-8 -*-
import scrapy
from tecentJob.items import TecentjobItem
class TencentSpider(scrapy.Spider):
name = 'tencent'
allowed_domains = ['tencent.com']
url = 'https://hr.tencent.com/position.php?&start='
offset = 0
start_urls = [url + str(offset)]
def parse(self, response):
for each in response.xpath("//tr[@class = 'even'] | //tr[@class = 'odd']"):
# 初始化模型对象
item = TecentjobItem()
item['positionname'] = each.xpath("./td[1]/a/text()").extract()[0]
item['positionlink'] = each.xpath("./td[1]/a/@href").extract()[0]
item['positionType'] = each.xpath("./td[2]/text()").extract()[0]
item['peopleNum'] = each.xpath("./td[3]/text()").extract()[0]
item['workLocation'] = each.xpath("./td[4]/text()").extract()[0]
item['publishTime'] = each.xpath("./td[5]/text()").extract()[0]
yield item
if self.offset < 100:
self.offset += 10
# 将请求重写发送给调度器入队列、出队列、交给下载器下载
# 拼接新的rurl,并回调parse函数处理response
# yield scrapy.Request(url, callback = self.parse)
yield scrapy.Request(self.url + str(self.offset), callback=self.parse)
3.3. 编写yield需要的管道文件
import json
class TecentjobPipeline(object):
def __init__(self):
self.filename = open("tencent.json", 'wb')
def process_item(self, item, spider):
text = json.dumps(dict(item),ensure_ascii=False) + "\n"
self.filename.write(text.encode('utf-8'))
return item
def close_spider(self, spider):
self.filename.close()
3.4. setting中配置请求抱头信息
DEFAULT_REQUEST_HEADERS = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'en',
}
4. 最后结果

Scrapy案例02-腾讯招聘信息爬取的更多相关文章
- Scrapy项目 - 实现腾讯网站社会招聘信息爬取的爬虫设计
通过使Scrapy框架,进行数据挖掘和对web站点页面提取结构化数据,掌握如何使用Twisted异步网络框架来处理网络通讯的问题,可以加快我们的下载速度,也可深入接触各种中间件接口,灵活的完成各种需求 ...
- Scrapy项目 - 数据简析 - 实现腾讯网站社会招聘信息爬取的爬虫设计
一.数据分析截图 本例实验,使用Weka 3.7对腾讯招聘官网中网页上所罗列的招聘信息,如:其中的职位名称.链接.职位类别.人数.地点和发布时间等信息进行数据分析,详见如下图: 图1-1 Weka ...
- Python 招聘信息爬取及可视化
自学python的大四狗发现校招招python的屈指可数,全是C++.Java.PHP,但看了下社招岗位还是有的.于是为了更加确定有多少可能找到工作,就用python写了个爬虫爬取招聘信息,数据处理, ...
- Scrapy项目 - 实现豆瓣 Top250 电影信息爬取的爬虫设计
通过使Scrapy框架,掌握如何使用Twisted异步网络框架来处理网络通讯的问题,进行数据挖掘和对web站点页面提取结构化数据,可以加快我们的下载速度,也可深入接触各种中间件接口,灵活的完成各种需求 ...
- Scrapy项目 - 实现斗鱼直播网站信息爬取的爬虫设计
要求编写的程序可爬取斗鱼直播网站上的直播信息,如:房间数,直播类别和人气等.熟悉掌握基本的网页和url分析,同时能灵活使用Xmind工具对Python爬虫程序(网络爬虫)流程图进行分析. 一.项目 ...
- Scrapy项目 - 项目源码 - 实现腾讯网站社会招聘信息爬取的爬虫设计
1.tencentSpider.py # -*- coding: utf-8 -*- import scrapy from Tencent.items import TencentItem #创建爬虫 ...
- Python爬虫框架Scrapy获得定向打击批量招聘信息
爬虫,就是一个在网上到处或定向抓取数据的程序,当然,这样的说法不够专业,更专业的描写叙述就是.抓取特定站点网页的HTML数据.只是因为一个站点的网页非常多,而我们又不可能事先知道全部网页的URL地址, ...
- 安居客scrapy房产信息爬取到数据可视化(下)-可视化代码
接上篇:安居客scrapy房产信息爬取到数据可视化(下)-可视化代码,可视化的实现~ 先看看保存的数据吧~ 本人之前都是习惯把爬到的数据保存到本地json文件, 这次保存到数据库后发现使用mongod ...
- scrapy爬虫框架教程(二)-- 爬取豆瓣电影TOP250
scrapy爬虫框架教程(二)-- 爬取豆瓣电影TOP250 前言 经过上一篇教程我们已经大致了解了Scrapy的基本情况,并写了一个简单的小demo.这次我会以爬取豆瓣电影TOP250为例进一步为大 ...
随机推荐
- CDN边缘节点容器调度实践(下)
5月27日,OSC 源创会在上海成功举办.又拍云系统开发高级工程师黄励博在大会分享了<CDN 边缘节点容器调度的实践>.主要介绍又拍云自主开发的边缘节点容器调度方案,从 0 到 1 ,实现 ...
- 模板模式之clone()方法
clone()方法的使用,体现了模板模式的思想,常见用法可以参考:http://blog.csdn.net/zhangjg_blog/article/details/18369201
- Shiro中的授权问题
在初识Shiro一文中,我们对Shiro的基本使用已经做了简单的介绍,不懂的小伙伴们可以先阅读上文,今天我们就来看看Shiro中的授权问题. Shiro中的授权,大体上可以分为两大类,一类是隐式角色, ...
- Django项目开发
1.django中Form验证.CSRF.Cookie.Session.Model操作数据库 2.django介绍&快速实现简单留言系统 3.django开发在线教育网站
- 《HelloGitHub月刊》第 10 期
前言 这一年感谢大家的支持,小弟这里给大家拜年了! <HelloGitHub月刊>会一直做下去,欢迎大家加入进来提供更多的好的项目. 最后,祝愿大家:鸡年大吉- <HelloGitH ...
- docker-swarm相关命令和注意事项
在k8s出现之后,docker-swarm使用的人越来越少,但在本地集成开发环境的搭建上,使用它还是比较轻量级的,它比docker-compose最大的好处就是容器之间的共享和服务的治理,你不需要li ...
- 如何定制Linux外围文件系统?
本文由云+社区发表 作者:我是乖宝宝哦 一般来说,我们所说的Linux系统指的是各种基于Linux Kernel和GNU Project的操作系统发行版.为了掌握Linux操作系统的使用,了解 Lin ...
- Docker系列03—Docker 基础入门
本文收录在容器技术学习系列文章总目录 1.概念介绍 1.1 容器 1.1.1 介绍 容纳其它物品的工具,可以部分或完全封闭,被用于容纳.储存.运输物品.物体可以被放置在容器中,而容器则可以保护内容物. ...
- Spring AOP中的JDK和CGLib动态代理哪个效率更高?
一.背景 今天有小伙伴面试的时候被问到:Spring AOP中JDK 和 CGLib动态代理哪个效率更高? 二.基本概念 首先,我们知道Spring AOP的底层实现有两种方式:一种是JDK动态代理, ...
- 使用LR编写HTTP协议Json报文格式接口脚本实战
最近在做HTTP协议接口压测时,遇到一些编写脚本方面的问题,在这里总结记录下,以便以后温习,也希望能帮助到和我有同样困惑的朋友吧. //实战代码如下所示:Action() { lr_start_tra ...