Python的scrapy之爬取6毛小说网的圣墟
闲来无事想看个小说,打算下载到电脑上看,找了半天,没找到可以下载的网站,于是就想自己爬取一下小说内容并保存到本地
圣墟 第一章 沙漠中的彼岸花 - 辰东 - 6毛小说网 http://www.6mao.com/html/40/40184/12601161.html
这是要爬取的网页
观察结构
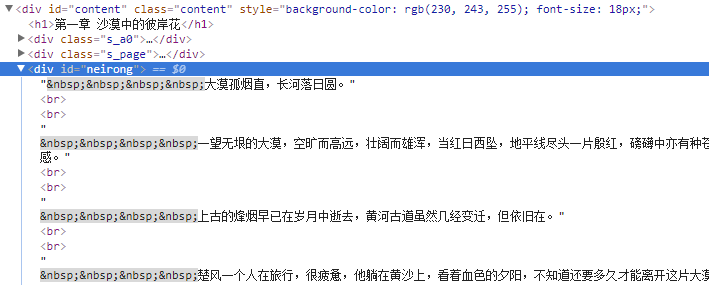
下一章

然后开始创建scrapy项目:
其中sixmaospider.py:
# -*- coding: utf-8 -*-
import scrapy
from ..items import SixmaoItem class SixmaospiderSpider(scrapy.Spider):
name = 'sixmaospider'
#allowed_domains = ['http://www.6mao.com']
start_urls = ['http://www.6mao.com/html/40/40184/12601161.html'] #圣墟 def parse(self, response):
novel_biaoti = response.xpath('//div[@id="content"]/h1/text()').extract()
#print(novel_biaoti)
novel_neirong=response.xpath('//div[@id="neirong"]/text()').extract()
print(novel_neirong)
#print(len(novel_neirong))
novelitem = SixmaoItem()
novelitem['novel_biaoti'] = novel_biaoti[0]
print(novelitem['novel_biaoti']) for i in range(0,len(novel_neirong),2):
#print(novel_neirong[i]) novelitem['novel_neirong'] = novel_neirong[i] yield novelitem #下一章
nextPageURL = response.xpath('//div[@class="s_page"]/a/@href').extract() # 取下一页的地址
nexturl='http://www.6mao.com'+nextPageURL[2]
print('下一章',nexturl)
if nexturl:
url = response.urljoin(nexturl)
# 发送下一页请求并调用parse()函数继续解析
yield scrapy.Request(url, self.parse, dont_filter=False)
pass
else:
print("退出")
pass
pipelinesio.py 将内容保存到本地文件
import os
print(os.getcwd()) class SixmaoPipeline(object):
def process_item(self, item, spider):
#print(item['novel']) with open('./data/圣墟.txt', 'a', encoding='utf-8') as fp:
fp.write(item['novel_neirong'])
fp.flush()
fp.close()
return item
print('写入文件成功')
items.py
import scrapy class SixmaoItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
novel_biaoti=scrapy.Field()
novel_neirong=scrapy.Field()
pass
startsixmao.py,直接右键这个运行,项目就开始运行了
from scrapy.cmdline import execute execute(['scrapy', 'crawl', 'sixmaospider'])
settings.py
LOG_LEVEL='INFO' #这是加日志
LOG_FILE='novel.log' DOWNLOADER_MIDDLEWARES = {
'sixmao.middlewares.SixmaoDownloaderMiddleware': 543,
'scrapy.contrib.downloadermiddleware.useragent.UserAgentMiddleware' : None,
'sixmao.rotate_useragent.RotateUserAgentMiddleware' :400 #这行是使用代理
} ITEM_PIPELINES = {
#'sixmao.pipelines.SixmaoPipeline': 300,
'sixmao.pipelinesio.SixmaoPipeline': 300, } #在pipelines输出管道加入这个 SPIDER_MIDDLEWARES = {
'sixmao.middlewares.SixmaoSpiderMiddleware': 543,
} #打开中间件 其余地方应该不需要改变
rotate_useragent.py 给项目加代理,防止被服务器禁止
# 导入random模块
import random
# 导入useragent用户代理模块中的UserAgentMiddleware类
from scrapy.downloadermiddlewares.useragent import UserAgentMiddleware # RotateUserAgentMiddleware类,继承 UserAgentMiddleware 父类
# 作用:创建动态代理列表,随机选取列表中的用户代理头部信息,伪装请求。
# 绑定爬虫程序的每一次请求,一并发送到访问网址。 # 发爬虫技术:由于很多网站设置反爬虫技术,禁止爬虫程序直接访问网页,
# 因此需要创建动态代理,将爬虫程序模拟伪装成浏览器进行网页访问。
class RotateUserAgentMiddleware(UserAgentMiddleware):
def __init__(self, user_agent=''):
self.user_agent = user_agent def process_request(self, request, spider):
#这句话用于随机轮换user-agent
ua = random.choice(self.user_agent_list)
if ua:
# 输出自动轮换的user-agent
print(ua)
request.headers.setdefault('User-Agent', ua) # the default user_agent_list composes chrome,I E,firefox,Mozilla,opera,netscape
# for more user agent strings,you can find it in http://www.useragentstring.com/pages/useragentstring.php
# 编写头部请求代理列表
user_agent_list = [\
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1"\
"Mozilla/5.0 (X11; CrOS i686 2268.111.0) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.57 Safari/536.11",\
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1092.0 Safari/536.6",\
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1090.0 Safari/536.6",\
"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/19.77.34.5 Safari/537.1",\
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.9 Safari/536.5",\
"Mozilla/5.0 (Windows NT 6.0) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.36 Safari/536.5",\
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",\
"Mozilla/5.0 (Windows NT 5.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",\
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_8_0) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",\
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3",\
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3",\
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",\
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",\
"Mozilla/5.0 (Windows NT 6.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",\
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.0 Safari/536.3",\
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24",\
"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24"
]
最终运行结果:
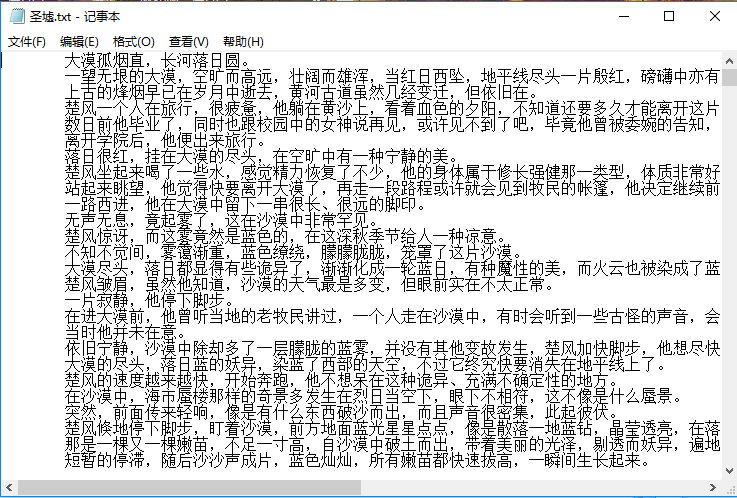
呐呐呐,这就是一个小的scrapy项目了
Python的scrapy之爬取6毛小说网的圣墟的更多相关文章
- python利用scrapy框架爬取起点
先上自己做完之后回顾细节和思路的东西,之后代码一起上. 1.Mongodb 建立一个叫QiDian的库,然后建立了一个叫Novelclass(小说类别表)Novelclass(可以把一级类别二级类别都 ...
- Python使用Scrapy框架爬取数据存入CSV文件(Python爬虫实战4)
1. Scrapy框架 Scrapy是python下实现爬虫功能的框架,能够将数据解析.数据处理.数据存储合为一体功能的爬虫框架. 2. Scrapy安装 1. 安装依赖包 yum install g ...
- 基于python的scrapy框架爬取豆瓣电影及其可视化
1.Scrapy框架介绍 主要介绍,spiders,engine,scheduler,downloader,Item pipeline scrapy常见命令如下: 对应在scrapy文件中有,自己增加 ...
- Python的scrapy之爬取顶点小说网的所有小说
闲来无事用Python的scrapy框架练练手,爬取顶点小说网的所有小说的详细信息. 看一下网页的构造: tr标签里面的 td 使我们所要爬取的信息 下面是我们要爬取的二级页面 小说的简介信息: 下面 ...
- python爬虫scrapy框架——爬取伯乐在线网站文章
一.前言 1. scrapy依赖包: 二.创建工程 1. 创建scrapy工程: scrapy staratproject ArticleSpider 2. 开始(创建)新的爬虫: cd Artic ...
- Python的scrapy之爬取boss直聘网站
在我们的项目中,单单分析一个51job网站的工作职位可能爬取结果不太理想,所以我又爬取了boss直聘网的工作,不过boss直聘的网站一次只能展示300个职位,所以我们一次也只能爬取300个职位. jo ...
- Python的scrapy之爬取51job网站的职位
今天老师讲解了Python中的爬虫框架--scrapy,然后带领我们做了一个小爬虫--爬取51job网的职位信息,并且保存到数据库中 用的是Python3.6 pycharm编辑器 爬虫主体: im ...
- Python的scrapy之爬取链家网房价信息并保存到本地
因为有在北京租房的打算,于是上网浏览了一下链家网站的房价,想将他们爬取下来,并保存到本地. 先看链家网的源码..房价信息 都保存在 ul 下的li 里面 爬虫结构: 其中封装了一个数据库处理模 ...
- Python的scrapy之爬取妹子图片
闲来无事,做的一个小爬虫项目 爬虫主程序: import scrapy from ..items import MeiziItem class MztSpider(scrapy.Spider): na ...
随机推荐
- frame shiro 授权及原理简述
shiro 授权模式 shiro采用的是rbac授权模式rbac,基于角色的权限管理,谁扮演什么角色,被允许做什么事情. shiro 授权流程 shiro 授权方式 1.编程式 通过写if/else授 ...
- mysql navicat 及命令行 创建、删除数据库
1.命令行创建数据库 create database mybatis default character set utf8 collate utf8_general_ci; drop database ...
- 附加到SQL2012的数据库就不能再附加到低于SQL2012的数据库版本
附加到SQL2012的数据库就不能再附加到低于SQL2012的数据库版本 昨天我只是将数据库附加到SQL2012,然后各个数据库都做了收缩事务日志的操作 兼容级别这些都没有改 再附加回SQL2005的 ...
- GreenPlum 5.0的安装
基本环境: server IP MDW 172.16.16.31 SDW1 172.16.16.34 SDW2 172.16.16.35 1:检查操作系统是否符合要求,以及系统设置. 我这里使用的系统 ...
- 使用AKLocationManager定位
使用AKLocationManager定位 https://github.com/ideaismobile/AKLocationManager 以下是使用情况: 是不是很简单呢,我们可以将它的步骤进一 ...
- screen 命令基本操作教程
sreen 命令提供的基本功能与 tmux 较为相似( 关于 tmux 基本操作可参见笔者的博文 终端复用工具 tmux 基本操作教程 ).screen 命令以会话( session )为基础为用户提 ...
- codeforces 933D A Creative Cutout
题目链接 正解:组合数学. 充满套路与细节的一道题.. 首先我们显然要考虑每个点的贡献(我就不信你能把$f$给筛出来 那么对于一个点$(x,y)$,我们设$L=x^{2}+y^{2}$,那么它的贡献就 ...
- 1305. [CQOI2009]跳舞【最大流+二分】
Description 一次舞会有n个男孩和n个女孩.每首曲子开始时,所有男孩和女孩恰好配成n对跳交谊舞.每个男孩都不会和同一个女孩跳两首(或更多)舞曲.有一些男孩女孩相互喜欢,而其他相互不喜欢(不会 ...
- [USACO08DEC]Patting Heads
嘟嘟嘟 这题还是比较水的.首先O(n2)模拟显然过不了,那就换一种思路,考虑每一个数对答案的贡献,显然一个数a[i]会对后面的a[i] * 2, a[i] * 3,a[i] * 4……都贡献1,.那么 ...
- kubernetes API Server 权限管理实践
API Server权限控制方式介绍 API Server权限控制分为三种:Authentication(身份认证).Authorization(授权).AdmissionControl(准入控制). ...