【scrapy】使用方法概要(一)(转)
【请初学者作为参考,不建议高手看这个浪费时间】
工作中经常会有这种需求,需要抓取互联网上的数据。笔者就经常遇到这种需求,一般情况下会临时写个抓取程序,但是每次遇到这种需求的时候,都几乎要重头写,特别是面临需要抓取大数量网页,并且被抓取网站有放抓取机制的时候,处理起来就会很麻烦。
无意中接触到了一个开源的抓取框架scrapy,按照introduction做了第一个dirbot爬虫,觉得很方便,就小小研究了一下,并在工作中用到过几次。
scrapy的文档是英文的,网上相关的说明很少,使用的过程中也遇到过很多问题,大部分都是在 stack overflow 上找到的解答,看来这个工具国外的同行们用的会更多些。鉴于国内关于scrapy的文章甚少,笔者希望能用自己的一些浅显的经验希望帮助大家更快对scrapy入门,作为笔者的第一篇分享文章,很难一气呵成完成,本文将分为几个部分,按照我自己的学习曲线作为组织,如果有错误,希望大家指正。
首先简要终结一下我认为scrapy最便利的几个地方:
1. 代码分工明确,一个抓取任务只需要在几个位置固定的地方增加代码,很容易就能写出基本的抓取功能。
2. 框架隐藏了很多抓取细节,如任务调度,重试机制,但并不是说框架不够灵活,例如框架支持以添加中间件的方式更改隐藏的细节,满足特殊需要,如使用代理ip池进行抓取,防止服务器封掉ip。
好啦,下面正式开始,从安装开始
笔者的运行环境是:linux python2.5
包管理使用的是:apt-get
安装流程:
1. 首先去官方网站下载源码
https://github.com/scrapy/scrapy/tarball/0.14
2. 安装scrapy以来的python库
sudo apt-get install python-twisted python-libxml2 python-pyopenssl python-simplejson
3. 安装
tar zxf Scrapy-X.X.X.tar.gz
cd Scrapy-X.X.X
sudo python setup.py install
4. 执行
scrapy
如果出现
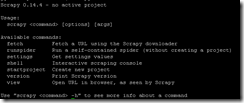
恭喜你,安装成功。
【未完待续~~~~~】
【scrapy】使用方法概要(一)(转)的更多相关文章
- Python3 Scrapy 安装方法
Python3 Scrapy 安装方法 (一脸辛酸泪) 写在前面 最近在学习爬虫,在熟悉了Python语言和BeautifulSoup4后打算下个爬虫框架试试. 没想到啊,这坑太深了... 看了看相关 ...
- 【scrapy】使用方法概要(三)(转)
请初学者作为参考,不建议高手看这个浪费时间] 前两篇大概讲述了scrapy的安装及工作流程.这篇文章主要以一个实例来介绍scrapy的开发流程,本想以教程自带的dirbot作为例子,但感觉大家应该最先 ...
- 【scrapy】使用方法概要(二)(转)
[请初学者作为参考,不建议高手看这个浪费时间] 上一篇文章里介绍了scrapy的主要优点及linux下的安装方式,此篇文章将简要介绍scrapy的爬取过程,本文大部分内容源于scrapy文档,翻译并加 ...
- 【scrapy】使用方法概要(四)(转)
[请初学者作为参考,不建议高手看这个浪费时间] 上一篇文章,我们抓取到了一大批代理ip,本篇文章介绍如何实现downloaderMiddleware,达到随即使用代理ip对目标网站进行抓取的. 抓取的 ...
- 简单总结scrapy使用方法
应课程需要写了几天爬虫,一开始使用requests+bs4的技术路线,但是速度不是很理想而且不能暂停,通过查阅资料,发现scrapy正是我需要的 做一下简短的记录: 首先应该毫不犹豫的scrapy s ...
- Scrapy安装方法
Scrapy安装在Python2.7环境下 1.配置环境变量: 2.安装基础软件 4个(64位系统) 安装twisted: C:\Users\Administrator>pip install ...
- virtualenv简介以及一个比较折腾的scrapy安装方法
本文来自网易云社区 作者:沈高峰 virtualenv + pip 安装python软件包是一种非常好的选择,在大部分情况下安装python软件包是不需要求助于sa的. 使用自己的一个工作副本也是写p ...
- python-1.Centos7安装Python3.6和Scrapy的方法
由于centos7原本就安装了Python2,而且这个Python2不能被删除,因为有很多系统命令,比如yum都要用到 [root@iZm5efjrz9szlsq1a0ai3gZ ~]# python ...
- python scrapy解码方法和时间格式转换
import scrapy from datetime import datetime class BianSpider(scrapy.Spider): name = 'bian' # allowed ...
随机推荐
- python基础--re模块
常用正则表达式符号 '.' 默认匹配除\n之外的任意一个字符,若指定flag DOTALL,则匹配任意字符,包括换行 '^' 匹配字符开头,若指定flags MULTILINE,这种也可以匹配上(r& ...
- Shell脚本系列教程二: 开始Shell编程
Shell脚本系列教程二: 开始Shell编程 2.1 如何写shell script? (1) 最常用的是使用vi或者mcedit来编写shell脚本, 但是你也可以使用任何你喜欢的编辑器; (2) ...
- No.19 selenium学习之路之os模块
os模块没有什么好说的,直接看实例就可以了 读取文件内容: open只能读文件的内容,不能读文件夹的内容 常用方法: 1. os.name——判断现在正在实用的平台,Windows 返回 ‘nt'; ...
- 练习题 --- 写出5种css定位语法
写出至少5种css语法(每种语法不一样)
- Python线程和进程
一.进程 程序并不能单独和运行只有将程序装载到内存中,系统为他分配资源才能运行,而这种执行的程序就称之为进程.程序和进程的区别在于:程序是指令的集合,它是进程的静态描述文本:进程是程序的一次执行活动, ...
- return to dl_resolve无需leak内存实现利用
之前在drop看过一篇文章,是西电的Bigtang师傅写的,这里来学习一下姿势做一些笔记. 0x01 基础知识 Linux ELF文件存在两个很重要的表,一个是got表(.got.plt)一个是plt ...
- 【LOJ】 #2033. 「SDOI2016」生成魔咒
题解 就是字符集较大需要离散化和建边表的后缀自动机水题 每次会加入i个新的串,其中重复的就是i的父亲节点所在节点的长度,减掉即可 代码 #include <iostream> #inclu ...
- JavaScript中正则的使用(1)
通过例子学习正则中的常见语法(1) $num javascript var a = 'javascript'; var b = a.replace(/(java)(script)/gi, '$2-$1 ...
- Ionic实战二:购物车
用户名密码都为空 此app功能主要有如下 1.首页轮播和商品列表展示 2.左侧侧滑页面分类展示 3.商品详情页面展示 以及购买 4.购物车 订单填写 支付等页面          
- IP、TCP和DNS与HTTP的密切关系
看了上一篇博文的发表时间,是7月22日,现在是10月22日,已经有三个月没写博客了.这三个月里各种忙各种瞎折腾,发生了很多事情,也思考了很多问题.现在这段时间开始闲下来了,同时该思考的事情也思考清楚了 ...