机器学习中的特征缩放(feature scaling)
参考:https://blog.csdn.net/iterate7/article/details/78881562
在运用一些机器学习算法的时候不可避免地要对数据进行特征缩放(feature scaling),比如:在随机梯度下降(stochastic gradient descent)算法中,特征缩放有时能提高算法的收敛速度。
什么是特征缩放
特征缩放的目标就是数据规范化,使得特征的范围具有可比性。它是数据处理的预处理处理,对后面的使用数据具有关键作用。
机器算法为什么要特征缩放
特征缩放还可以使机器学习算法工作的更好。比如在K近邻算法中,分类器主要是计算两点之间的欧几里得距离,如果一个特征比其它的特征有更大的范围值,那么距离将会被这个特征值所主导。因此每个特征应该被归一化,比如将取值范围处理为0到1之间。
第二个原因则是,特征缩放也可以加快梯度收敛的速度。
特征缩放的一些方法
调节比例(Rescaling)
这种方法是将数据的特征缩放到[0,1]或[-1,1]之间。缩放到什么范围取决于数据的性质。对于这种方法的公式如下:
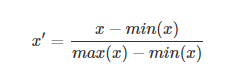
xx是最初的特征值,x'x′是缩放后的值。
平均值规范化(Mean normalisation)
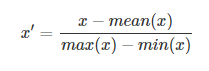
标准化(Standardization)
特征标准化使每个特征的值有零均值(zero-mean)和单位方差(unit-variance)。这个方法在机器学习地算法中被广泛地使用。例如:SVM,逻辑回归和神经网络。这个方法的公式如下:
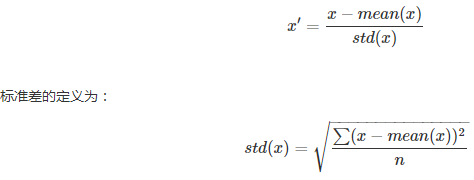
缩放到单位长度(Scaling to unit length)
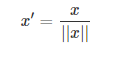
就是除以向量的欧拉长度( the Euclidean length of the vector),二维范数。
总结
数据的归一化和缩放非常重要,会影响到特征选择和对真实业务问题的判定。
参考
https://en.wikipedia.org/wiki/Feature_scaling
机器学习中的特征缩放(feature scaling)的更多相关文章
- (一)线性回归与特征归一化(feature scaling)
线性回归是一种回归分析技术,回归分析本质上就是一个函数估计的问题(函数估计包括参数估计和非参数估计),就是找出因变量和自变量之间的因果关系.回归分析的因变量是应该是连续变量,若因变量为离散变量,则问题 ...
- CS229 1 .线性回归与特征归一化(feature scaling)
线性回归是一种回归分析技术,回归分析本质上就是一个函数估计的问题(函数估计包括参数估计和非参数估计),就是找出因变量和自变量之间的因果关系.回归分析的因变量是应该是连续变量,若因变量为离散变量,则问题 ...
- 机器学习入门09 - 特征组合 (Feature Crosses)
原文链接:https://developers.google.com/machine-learning/crash-course/feature-crosses/ 特征组合是指两个或多个特征相乘形成的 ...
- 深度学习中的特征(feature)指的是什么?
一般在machine learning意义上,我们常说的feature,是一种对数据的表达.当然,要衡量一种feature是否是合适的表达,要根据数据,应用,ML的模型,方法....很多方面来看.一般 ...
- Spark机器学习API之特征处理(二)
Spark机器学习库中包含了两种实现方式,一种是spark.mllib,这种是基础的API,基于RDDs之上构建,另一种是spark.ml,这种是higher-level API,基于DataFram ...
- Spark机器学习API之特征处理(一)
Spark机器学习库中包含了两种实现方式,一种是spark.mllib,这种是基础的API,基于RDDs之上构建,另一种是spark.ml,这种是higher-level API,基于DataFram ...
- 斯坦福大学公开课机器学习:梯度下降运算的特征缩放(gradient descent in practice 1:feature scaling)
以房屋价格为例,假设有两个特征向量:X1:房子大小(1-2000 feets), X2:卧室数量(1-5) 关于这两个特征向量的代价函数如下图所示: 从上图可以看出,代价函数是一个又瘦又高的椭圆形轮廓 ...
- 特征缩放(Feature Scaling)
特征缩放的几种方法: (1)最大最小值归一化(min-max normalization):将数值范围缩放到 [0, 1] 区间里 (2)均值归一化(mean normalization):将数值范围 ...
- 131.006 Unsupervised Learning - Feature Scaling | 非监督学习 - 特征缩放
@(131 - Machine Learning | 机器学习) 1 Feature Scaling transforms features to have range [0,1] according ...
随机推荐
- HTML5 number类型文本框step属性的验证机制——张鑫旭
我在下一盘很大的棋,本文只是其中的一个棋子. 需要提前知道的: 目前而言,对step雄起的浏览器为IE10+, Chrome以及Opera浏览器. 需要预先知道number类型input的一些基本知识 ...
- Codeforces Global Round1 简要题解
Codeforces Global Round 1 A 模拟即可 # include <bits/stdc++.h> using namespace std; typedef long l ...
- react 使用map 的时候提示 没有返回值
因为map 的函数体里 用了if判断,在if块之外return 一个值就可以了 <div className="service-entry"> {!!services ...
- CSDN博客大事日记1
一. 2016-10-18,申请了博客专家,但是因为PV不够,所以很荣幸的成为了一名CSDN准博客专家,接下,得更加努力了争取早日成为博客专家,在此立帖为证哦. ...
- VSCode环境
PythonPython for VSCode Language Support for Java(TM) by Red HatJava Language SupportJava DebuggerJa ...
- Vue项目中引用vue-resource步骤
直接上步骤: 1.通过命令,进入到当前项目所在目录 2.输入以下命令npm install vue-resource --save 3.安装完毕后,在main.js中导入,如下: import Vue ...
- linux 获取shell内置命令帮助信息 help xx
shell,命令解释器 shell内置命令有cd/umask/pwd等 help shell内置命令适用于所有用户获取shell内置命令的帮助信息help umaskhelp if
- redis介绍(6)集群(ruby)
redis集群: redis集群是高可用的一种体现,让整个redis圈更加稳定,不易出现宕机的情况, redis原理: redis3.0之前是不支持集群的,实现集群要自己去配置实现,很麻烦,在3.0之 ...
- scp远程传输文件和ssh远程连接
ssh使用方法 如果从一台linux服务器通过ssh远程登录到另一台Linux机器, 这种情况通常会在多台服务器的时候用到. 如用root帐号连接一个IP为192.168.1.102的机器,输入:“ ...
- CSS 小结笔记之选择器
Css选择器主要分为以下几类 类选择器 ID选择器 通配符选择器 标签选择器 伪类选择器 复合选择器 1.类选择器:通过.classname 来选择 例如 .color2 { color: rebec ...