PostgreSQL timeline
磨砺技术珠矶,践行数据之道,追求卓越价值
回到上一级页面: PostgreSQL基础知识与基本操作索引页 回到顶级页面:PostgreSQL索引页
关于timeline,有如下的说法
http://www.postgresql.org/docs/current/static/continuous-archiving.html
24.3.. Timelines The ability to restore the database to a previous point in time creates some complexities that are akin to science-fiction stories about time travel and parallel universes. For example, in the original history of the database, suppose you dropped a critical table at :15PM on Tuesday evening, but didn't realize your mistake until Wednesday noon. Unfazed, you get out your backup, restore to the point-in-time 5:14PM Tuesday evening, and are up and running. In this history of the database universe, you never dropped the table. But suppose you later realize this wasn't such a great idea, and would like to return to sometime Wednesday morning in the original history. You won't be able to if, while your database was up-and-running, it overwrote some of the WAL segment files that led up to the time you now wish you could get back to. Thus, to avoid this, you need to distinguish the series of WAL records generated after you've done a point-in-time recovery from those that were generated in the original database history. To deal with this problem, PostgreSQL has a notion of timelines. Whenever an archive recovery completes, a new timeline is created to identify the series of WAL records generated after that recovery. The timeline ID number is part of WAL segment file names so a new timeline does not overwrite the WAL data generated by previous timelines. It is in fact possible to archive many different timelines. While that might seem like a useless feature, it's often a lifesaver. Consider the situation where you aren't quite sure what point-in-time to recover to, and so have to do several point-in-time recoveries by trial and error until you find the best place to branch off from the old history. Without timelines this process would soon generate an unmanageable mess. With timelines, you can recover to any prior state, including states in timeline branches that you abandoned earlier. Every time a new timeline is created, PostgreSQL creates a "timeline history" file that shows which timeline it branched off from and when. These history files are necessary to allow the system to pick the right WAL segment files when recovering from an archive that contains multiple timelines. Therefore, they are archived into the WAL archive area just like WAL segment files. The history files are just small text files, so it's cheap and appropriate to keep them around indefinitely (unlike the segment files which are large). You can, if you like, add comments to a history file to record your own notes about how and why this particular timeline was created. Such comments will be especially valuable when you have a thicket of different timelines as a result of experimentation. The default behavior of recovery is to recover along the same timeline that was current when the base backup was taken. If you wish to recover into some child timeline (that is, you want to return to some state that was itself generated after a recovery attempt), you need to specify the target timeline ID in recovery.conf. You cannot recover into timelines that branched off earlier than the base backup.
经过我的实验,发现是这样的,一旦开始第一次的restore,那么就产生了一个交叉点,于是"平行宇宙"诞生了。但是还有一个问题:
参见下图:
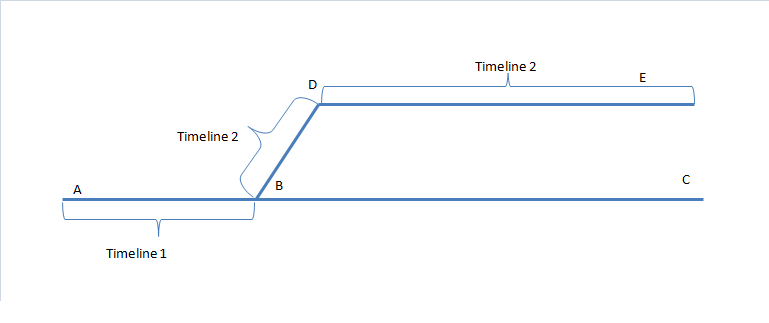
如果我当初在A点与B点之间插入数据,又在B点和C点之间插入数据。
然后,在B点所在的时间点处Restore,那么,Timeline2就产生了。
我可以接着在B点和D点至今插入数据,又在D点和E点之间插入数据。
可以说A到B是 timeline2, B到D到E是timeline1。
到达了D点或E点后,我是无法再次Restore到 B点和C点之间了。
这是因为:
B点到C点已经成为不存在了。
(虽然所有的archive wal log我都有,但是某些数据是保留在online wal log中,这部分的数据变化,经过timeline2的处理后,其实是永远失去了)
回到上一级页面: PostgreSQL基础知识与基本操作索引页 回到顶级页面:PostgreSQL索引页
磨砺技术珠矶,践行数据之道,追求卓越价值
PostgreSQL timeline的更多相关文章
- replication_slot and PostgreSQL Replication
主库IP:192.168.230.128 备库IP:192.168.230.129 PostgreSQL版本: 主备机PostgreSQL源码包均位于/opt/soft_bak OS:CentOS5 ...
- PostgreSQL Cascade Replication
PostgreSQL Cascade Replication node1:master:10.2.208.10:repclia(user) node2:upstreamnode:10.2.208.11 ...
- PostgreSQL Replication之第十五章 与Walbouncer 一起工作
与Walbouncer 一起工作 在本书的最后一章,将引导您通向2014年发布的一个工具,称为walbouncer.本书中的大多数技巧说明了如何复制整个数据库实例,如何分片,等等.在最后一章,是关于w ...
- PostgreSQL 同步复制(1master+2standby)
OS: Red Hat Enterprise Linux Server release 6.5 (Santiago) PostgreSQL: postgresql-9.4.5.tar.bz2 mast ...
- postgreSQL 时间线
“时间线”(Timeline)是PG一个很有特色的概念,在备份恢复方面的文档里面时有出现.但针对这个概念的详细解释却很少,也让人不太好理解,我们在此仔细解析一下. 时间线的引入 为了理解引入时间线的背 ...
- UNDERSTANDING POSTGRESQL.CONF: CHECKPOINT_SEGMENTS, CHECKPOINT_TIMEOUT, CHECKPOINT_WARNING
While there are some docs on it, I decided to write about it, in perhaps more accessible language – ...
- postgresql如何维护WAL日志/归档日志
WAL日志介绍 wal全称是write ahead log,是postgresql中的online redo log,是为了保证数据库中数据的一致性和事务的完整性.而在PostgreSQL 7中引入的 ...
- PostgreSQL数据库单机扩展为流复制
primary:10.189.102.118 standby:10.189.100.195 1. 配置ssh互信机制 在primary主库执行 $ ssh-keygen -t rsa $ cp ~/. ...
- PostgreSQL主备流复制机制
原文出处 http://mysql.taobao.org/monthly/2015/10/04/ PostgreSQL在9.0之后引入了主备流复制机制,通过流复制,备库不断的从主库同步相应的数据,并在 ...
随机推荐
- 《SQL Server 2008从入门到精通》20180627
数据库范式理论 范式理论是为了建立冗余较小结构合理的数据库所遵循的规则.关系数据库中的关系必须满足不同的范式.目前关系数据库有六种范式:第一范式(1NF).第二范式(2NF).第三范式(3NF).BC ...
- Tomcat6.0下的jsp、servlet和javabean的配置
第一步:下载jdk和tomcat: 第二步:安装和配置你的jdk和tomcat:执行jdk和tomcat的安装程序,然后设置按照路径进行安装即可.1.安装jdk以后,需要配置一下环境变量,在我的电脑- ...
- 转:线程Thread (1)
引言 1.理解多线程 2. 线程异步与线程同步 3.创建多线程应用程序 3.1通过System.Threading命名空间的类构建 3.1.1异步调用线程 3.1.2并发问题 3.1.3线程同步 3. ...
- Ubuntu16.04安装redis和php的redis扩展
安装redis服务 sudo apt-get install redis-server 装好之后默认就是自启动.后台运行的,无需过多设置,安装目录应该是 /etc/redis 启动 sudo ser ...
- Log Structured Merge Trees (LSM)
1 概念 LSM = Log Structured Merge Trees 来源于google的bigtable论文. 2 解决问题 传统的数据库如MySql采用B+树存放数据,B ...
- September 21st 2017 Week 38th Thursday
What fire does not destroy, it hardens. 烈火摧毁不了的东西,只会变得更坚固. The true gold can stand the test of fire, ...
- python3编程的一些实用技巧1
1.choice函数:返回一个列表,元组,字符串的随机项 : 调用时应导入random模块,如from random import choice 2.print 两个字符串, 逗号,+号进行连 ...
- npm使用小结
npm包管理工具使用小结 npm(node package manager)是一个node包管理工具,我们可以方便的从npm服务器下载第三方包到本地使用. 安装: NPM是随同NodeJS一起安装的包 ...
- Java 处理cookie的方法
一.java创建cookie 方法一: Response.Cookies["userName"].Value = "patrick"; Response.Coo ...
- Charles应用指南--安装与代理篇
Charles是开发测试过程中十分常用的一款代理软件,之前也写了一点基本使用.最近有新同事入职头一次用这个,就写了这么一份基本的安装和配置笔记. Charles 下载地址 mac:链接: https: ...