计算机科学基础知识(一)The Memory Hierarchy
一、前言
最近一个问题经常萦绕在我的脑海:一个学习电子工程的机械师如何称为优秀的程序员?(注:本文作者本科学习机械设计,研究生转到电子工程系学习,毕业后却选择了系统程序员这样的职业)。经过思考,我认为阻挡我称为一个优秀程序员的障碍是计算机科学的理论知识。自然辩证法告诉我们:理论源于实践,又指导实践,她们是相辅相成的关系。虽然从业十余年,阅code无数,但计算机的理论不成体系,无法指导工程面具体技能的进一步提升。
计算机科学博大精深,CPU体系结构、离散数学、编译器原理、软件工程等等。最终选择从下面这本书作为起点:

本文就是在阅读了该书的第六章的一个读数笔记,方便日后查阅。
二、存储技术
本节主要介绍SRAM,SDRAM,FLASH以及磁盘这集中存储技术,这些技术是后面学习的基础。
1、SRAM
SRAM是RAM的一种,和SDRAM不同的是SRAM不需要refresh的动作,只要保持供电,其memory cell保存的数据就不会丢失。一个SRAM的memory cell是由六个场效应管组成,如下: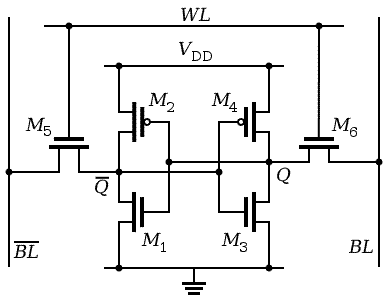
具体bit的信息是保存在M1、M2、M3、M4这四个场效应管中。M1和M2组成一个反相器,我们称之C1。Q(有上划线的那个Q)是C1的输出。M3和M4组成另外一个反相器C2,Q是C2的输出。C1的输出连接到C2的输入,C2的输出连接到C1的输入,通过这样的方法实现两个反相器的输出状态的锁定、保存,即储存了1个bit的数据。M5和M6是用来控制数据访问的。一个SRAM的memory cell有三个状态:
(1)idle状态。这种状态下,Word Line(图中标识为WL)为低电平的时候,M5和M6都处于截止状态,保存bit信息的cell和外界是隔绝的。这时候,只有有供电,cell保持原来的状态。
(2)reading状态。我们假设cell中保存的数据是1(Q点是高电平),当进行读操作的时候,首先把两根bit line(BL和BL)设置为高电平。之后assert WL,以便导通M5和M6。M5和M6导通之后,我们分成两个部分来看。右边的BL和Q都是高电平,因此状态不变。对于左边,BL是高电平,而Q是低电平,这时候,BL就会通过M5、M1进行放电,如果时间足够长,BL最终会变成低电平。cell保存数据0的情况是类似的,只不过这时候最终BL会保持高电平,而BL最终会被放电成低电平,具体的过程这里不再详述。BL和BL会接到sense amplifier上,sense amplifier可以感知BL和BL之间的电压差从而判断cell中保存的是0还是1。
(3)writing状态。假设我们要向cell中写入1,首先将BL设定为高电平,BL设定为低电平。之后assert WL,以便导通M5和M6。M5和M6导通之后,如果原来cell保存1,那么状态不会变化。如果原来cell保存0,这时候Q是低电平,M1截止,M2导通,Q是高电平,M4截止,M3导通。一旦assert WL使得M5和M6导通后,Q变成高电平(跟随BL点的电平),从而导致M1导通,M2截止。一旦M1导通,原来Q点的高电平会通过M1进行放电,使Q点变成低电平。而Q点的低电平又导致M4导通,M3截止,使得Q点锁定在高电平上。将cell的内容从1变成0也是相似的过程,这里不再详述。
了解了一个cell的结构和操作过程之后,就很容易了解SRAM芯片的结构和原理了。一般都是将cell组成阵列,再加上一些地址译码逻辑,数据读写buffer等block。
2、SDRAM。具体请参考SDRAM internals。
3、Flash。具体请参考FLASH internals。
4、Disk(硬盘)
嵌入式软件工程师多半对FLASH器件比较熟悉,而对Hard Disk相对陌生一些。这里我们只是简单介绍一些基本的信息,不深入研究。保存数据的硬盘是由一个个的“盘子”(platter)组成,每个盘子都有两面(surface),都可以用来保存数据。磁盘被堆叠在一起沿着共同的主轴(spindle)旋转。每个盘面都有一个磁头(header)用来读取数据,这些磁头被固定在一起可以沿着盘面径向移动。盘面的数据是存储在一个一个的环形的磁道(track)上,磁道又被分成了一个个的sector。还有一个术语叫做柱面(cylinder),柱面是由若干的track组成,这些track分布在每一个盘面上,有共同的特点就是到主轴的距离相等。
我们可以从容量和存取速度两个方面来理解Disk Drive。容量计算比较简单,特别是理解了上面描述的硬盘的几何结构之后。磁盘容量=(每个sector有多少个Byte)x(每个磁道有多少个sector)x(每个盘面有多少个磁道)x(每个盘子有多少个盘面)x(该硬盘有多少个盘子)。
由于各个盘面的读取磁头是固定在一起的,因此,磁头的移动导致访问的柱面的变化。因此,同一时刻,我们可以同时读取位于同一柱面上的sector的数据。对于硬盘,数据的访问是按照sector进行的,当我们要访问一个sector的时候需要考虑下面的时间:
(1)Seek time。这个时间就是磁头定位到磁道的时间。这个时间和上次访问的磁道以及移动磁头的速度有关。大约在10ms左右。
(2)Rotational latency。磁头移动到了磁道后,还不能读取sector的数据,因为保存数据的盘面都是按照固定的速率旋转的,有可能我们想要访问的sector刚好转过磁头,这时候,只能等下次旋转到磁头位置的时候才能开始数据读取。这个是时间和磁盘的转速有关,数量级和seek time类似。
(3)Transfer time。当想要访问的sector移动到磁头下面,数据访问正式启动。这时候,数据访问的速度是和磁盘转速以及磁道的sector数目相关。
举一个实际的例子可能会更直观:Seek time:9ms,Rotational latency:4ms,Transfer time:0.02ms。从这些数据可以知道,硬盘访问的速度主要受限在Seek time和Rotational latency,一旦磁头和sector相遇,数据访问就非常的快了。此外,我们还可以看出,RAM的访问都是ns级别的,而磁盘要到ms级别,可见RAM的访问速度要远远高于磁盘。
三、局部性原理(Principle of Locality)
好的程序要展现出好的局部性(locality),以便让系统(软件+硬件)展现出好的性能。到底是memory hierarchy、pipeline等硬件设计导致软件必须具备局部性,还是本身软件就是具有局部性特点从而推动硬件进行相关的设计?这个看似鸡生蛋、蛋生鸡的问题,我倾向于逻辑的本身就是有序的,是局部性原理的本质。此外,局部性原理不一定涉及硬件。例如对于AP软件和OS软件,OS软件会把AP软件最近访问的virtual address space的数据存在内存中作为cache。
局部性被分成两种类型:
(1)时间局部性(Temporal Locality)。如果程序有好的时间局部性,那么在某一时刻访问的memory,在该时刻随后比较短的时间内还多次访问到。
(2)空间局部性(Spatial Locality)。如果程序有好的空间局部性,那么一旦某个地址的memory被访问,在随后比较短的时间内,该memory附近的memory也会被访问。
1、数据访问的局部性分析
int sumvec(int v[N])
{
int i, sum = 0;
for (i = 0; i < N; i++)
sum += v[i];
return sum;
}
i和sum都是栈上的临时变量,由于i和sum都是标量,不可能表现出好的空间局部性,不过对于sumvec的主loop,i、sum以及数组v都可以表现出很好的时间局部性。虽然,i和sum没有很好的空间局部性,不过编译器会把i和sum放到寄存器中,从而优化性能。数组v在loop中是顺序访问的,因此可以表现出很好的空间局部性。总结一下,上面的程序可以表现出很好的局部性。
按照上面的例子对数组v进行访问的模式叫做stride-1 reference pattern。下面的例子可以说明stride-N reference pattern:
int sumarraycols(int v[M][N])
{
int i, j; sum = 0;
for(j = 0; j < N; j++)
for (i = 0; i < M; i++)
sum += a[i][j];
return sum;
}
二维数组v[i][j]是一个i行j列的数组,在内存中,v是按行存储的,首先是第1行的j个列数据,之后是第二行的j个列数据……依次排列。在实际的计算机程序中,我们总会有计算数组中所有元素的和的需求,在这个问题上有两种方式,一种是按照行计算,另外一种方式是按照列计算。按照行计算的程序可以表现出好的局部性,不过sumarraycols函数中是按照列进行计算的。在内循环中,累计一个列的数据需要不断的访问各个行,这就导致了数据访问不是连续的,而是每次相隔N x sizeof(int),这种情况下,N越大,空间局部性越差。
2、程序访问的局部性分析
对于指令执行而言,顺序执行的程序具备好的空间局部性。我们可以回头看看sumvec函数的执行情况,这个程序中,loop内的指令都是顺序执行的,因此,有好的空间局部性,而loop被多次执行,因此同时又具备了好的时间局部性。
3、经验总结
我们可以总结出3条经验:
(1)不断的重复访问同一个变量的程序有好的时间局部性
(2)对于stride-N reference pattern的程序,N越小,空间局部性越好,stride-1 reference pattern的程序最优。好的程序要避免以跳来跳去的方式来访问memory,这样程序的空间局部性会很差
(3)循环有好的时间和空间局部性。循环体越小,循环次数越多,局部性越好
四、存储体系
1、分层的存储体系
现代计算机系统的存储系统是分层的,主要有六个层次:
(1)CPU寄存器
(2)On-chip L1 Cache (一般由static RAM组成,size较小,例如16KB)
(3)Off-chip L2 Cache (一般由static RAM组成,size相对大些,例如2MB)
(4)Main memory(一般是由Dynamic RAM组成,几百MB到几个GB)
(5)本地磁盘(磁介质,几百GB到若干TB)
(6)Remote disk(网络存储、分布式文件系统)
而决定这个分层结构的因素主要是:容量(capacity),价格(cost)和访问速度(access time)。位于金字塔顶端的CPU寄存器访问速度最快(一个clock就可以完成访问)、容量最小。金字塔底部的存储介质访问速度最慢,但是容量可以非常的大。
2、存储体系中的cache
缓存机制可以发生在存储体系的k层和k+1层,也就是说,在k层的存储设备可以作为low level存储设备(k+1层)的cache。例如访问main memory的时候,L2 cache可以缓存main memory的部分数据,也就是说,原来需要访问较慢的SDRAM,现在可以通过L2 cache直接命中,提高了效率。同样的道理,访问本地磁盘的时候,linux内核也会建立page cache、buffer cache等用来缓存disk上数据。
下面我们使用第三层的L2 cache和第四层的Main memory来说明一些cache的基本概念。一般而言,Cache是按照cache line组织的,当访问主存储器的时候,有可能数据或者指令位于cache line中,我们称之cache hit,这种情况下,不需要访问外部慢速的主存储器,从而加快了存储器的访问速度。也有可能数据或者指令没有位于cache line中,我们称之cache miss,这种情况下,需要从外部的主存储器加载数据或指令到cache中来。由于时间局部性(tmpporal locality)和空间局部性(spatial locality)原理,load 到cache中的数据和指令往往是最近要使用的内容,因此可以提高整体的性能。当cache miss的时候,我们需要从main memory加载cache,如果这时候cache已经满了(毕竟cache的size要小于main memory的size),这时候还要考虑替换算法。比较简单的例子是随机替换算法,也就是随机的选择一个cache line进行替换。也可以采用Least-recently used(LRU)算法,这种算法会选择最近最少使用的那个cache line来加载新的cache数据,cache line中旧的数据就会被覆盖。
cache miss有三种:
(1)在系统初始化的时候,cache中没有任何的数据,这时候,我们称这个cache是cold cache。这时候,由于cache还没有warn up导致的cache miss叫做compulsory miss或者cold miss。
(2)当加载一个cache line的时候,有两种策略,一种是从main memory加载的数据可以放在cache中的任何一个cache line。这个方案判断cache hit的开销太大,需要scan整个cache。因此,在实际中,指定的main memory的数据只能加载到cache中的一个subset中。正因此如此,就产生了另外一种cache miss叫做conflict miss。也就是说,虽然目前cache中仍然有空闲的cacheline,但是由于main memory要加载的数据映射的那个subset已经满了,这种情况导致的cache miss叫做conflict miss。
(3)对于程序的执行,有时候会在若干个指令中循环,而在这个循环中有可能不断的反复访问一个或者多个数据block(例如:一个静态定义的数组)。这些数据block就叫做这个循环过程的Working Set。当Working Set的size大于cache的size之后,就会产生capacity miss。加大cache的size是解决capacit miss的唯一方法(或者减少working set的size)。
前面我们已经描述过,分层的memory hierarchy的精髓就是每层的存储设备都是可以作为下层设备的cache,而在每一层的存储设备都要有一些逻辑(可以是软件的,也可以是硬件的)来管理cache。例如:cache的size是多少?如何定义k层的cache和k+1层存储设备之间的transfer block size(也就是cache line),如何确定cache hit or miss,替换策略为何?对于cpu register而言,编译器提供了了cache的管理策略。对于L1和L2,cache管理策略是由HW logic来控管,不过软件工程师在编程的时候需要了解这个层次上的cache机制,以便写出比较优化的代码。我们都有用浏览器访问Internet的经历,我们都会有这样的常识,一般最近访问的网页都会比较快,因此这些网页是从本地加载而不是远端的主机。这就是本地磁盘对网络磁盘的cache机制,是用软件逻辑来控制的。
五、cache内幕
本节用ARM926的cache为例,描述一些cache memory相关的基础知识,对于其他level上的cache,概念是类似的。
1、ARM926 Cache的组织
ARM926的地址线是32个bit,可以访问的地址空间是4G。现在,我们要设计CPU寄存器和4G main memory空间之间的一个cache。毫无疑问,我们的cache不能那么大,因此我们考虑设计一个16K size的cache。首先考虑cache line的size,一般选择32个Bytes,这个也是和硬件相关,对于支持burst mode的SDRAM,一次burst可以完成32B的传输,也就是完成了一次cache line的填充。16K size的cache可以分成若干个set,对于ARM926,这个数字是128个。综上所述,16KB的cache被组织成128个cache set,每个cache set中有4个cache line,每个cache line中保存了32B字节的数据block。了解了Cache的组织,我们现在看看每个cache line的组成。一个cache line由下面的内容组成:
1、该cache line是否有效的标识。
2、Tag。听起来很神秘,其实一般是地址的若干MSB部分组成,用来判断是否cache hit的
3、数据块(具体的数据或者指令)。如果命中,并且有效,CPU就直接从cache中取走数据,不必再去访问memory了。
了解了上述信息之后,我们再看看virutal memory address的组成,具体如下图所示:

当CPU访问一个32 bit的地址的时候,首先要去cache中查看是否hit。由于cache line的size(指数据块部分,不包括tag和flag)是32字节,因此最低的5个bits是用来定位cache line offset的。中间的7个bit是用来寻找cache set的。7个bit可以寻址128个cache set。找到了cache set之后,我们就要对该cache set中的四个cache line进行逐一比对,是否valid,如果valid,那么要访问地址的Tag是否和cache line中的Tag一样?如果一样,那么就cache hit,否则cache miss,需要发起访问main memory的操作。
总结一下:一个cache的组织可以由下面的四个参数组来标识(S,E,B,m)。S是cache set的数目;E是每个cache set中cache line的数目;B是一个cache line中保存的数据块的字节数;m是物理地址的bit数目。
2、Direct-Mapped Cache和Set Associative Cache
如果每个cache set中只有一个cache line,也就是说E等于1,这样组织的cache就叫做Direct-Mapped Cache。这种cache的各种操作比较简单,例如判断是否cache hit。通过Set index后就定位了一个cache set,而一个cache set只有一个cache line,因此,只有该cache line的valid有效并且tag是匹配的,那么就是cache hit,否则cache miss。替换策略也简单,因为就一个cache line,当cache miss的时候,只能把当前的cache line换出。虽然硬件设计比较简单了,但是conflict Miss会比较突出。我们可以举一个简单的例子:
float dot_product(float x[8], float y[8])
{
int i; float sum = 0.0;
for(i=0; i<8; i++)
{
sum += x[i]*y[i];
}
return sum;
}
上面的程序是求两个向量的dot product,这个程序有很好的局部性,按理说应该有较高的cache hit,但是实际中未必总是这样。假设32
byte的cache被组织成2个cache set,每个cache
line是16B。假设x数组放在0x0地址开始的32B中,4B表示一个float数据,y数组放在0x20开始的地址中。第一个循环中,当访问x[0]的时候(set
index等于0),cache的set 0被加载了x[0]~x[3]的数据。当访问y[0]的时候,由于set
index也是0,因此y[0]~y[3]被加载到set 0,从而替换了之前加载到set
0的x[0]~x[3]数据。第二个循环的时候,当访问x[1],不能cache命中,于是重新将x[0]~x[3]的数据载入set
0,而访问y[1]的时候,仍然不能cache
hit,因为y[0]~y[3]已经被flush掉了。有一个术语叫做Thrashing就是描述这种情况。
正是因为E=1导致了cache thrashing,加大E可以解决上面的问题。当一个cache set中有多于1个cache
line的时候,这种cache就叫做Set Associative Cache。ARM926的cache被称为four-way set
associative cache,也就是说一个cache set中包括4个cache line。一旦有了多个cache
line,判断cache hit就稍显麻烦了,因为这时候必须要逐个比对了,直到找到匹配的Tag并且是valid的那个cache
line。如果cache miss,这时候就需要从main
memory加载cache,如果有空当然好,选择那个flag是invalid的cache line就OK了,如果所有的cache
line都是有效的,那么替换哪一个cache line呢?当然,硬件设计可以有多种选择,但是毫无疑问增加了复杂度。
还有一种cache被叫做fully Associative cache,这种cache只有一个cache
set。这种cache匹配非常耗时,因为所有的cache line都在一个set中,硬件要逐个比对才能判断出cache miss or
hit。这种cache只适合容量较小的cache,例如TLB。
3、写操作带来的问题
上面的章节主要描述读操作,对于写操作其实也存在cache hit和cache
miss,这时候,系统的行为又是怎样的呢?我们首先来看看当cache
hit时候的行为(也就是说想要写入数据的地址单元已经在cache中了)。根据写的行为,cache分成三种类型:
(1)write through。CPU向cache写入数据时,同时向memory也写一份,使cache和memory的数据保持一致。优点是简单,缺点是每次都要访问memory,速度比较慢。
(2)带write buffer的write through。策略同上,只不过不是直接写memory,而是把更新的数据写入到write buffer,在合适的时候才对memory进行更新。
(3)write back。CPU更新cache line时,只是把更新的cache
line标记为dirty,并不同步更新memory。只有在该cache line要被替换掉的时候,才更新
memory。这样做的原因是考虑到很多时候cache存入的是中间结果(根据局部性原理,程序可能随后还会访问该单元的数据),没有必要同步更新memory(这可以降低bus
transaction)。优点是CPU执行的效率提高,缺点是实现起来技术比较复杂。
在write操作时发生cache miss的时候有两种策略可以选择:
(1)no-write-allocate cache。当write cache miss的时候,简单的写入main memory而没有cache的操作。一般而言,write through的cache会采用no-write-allocate的策略。
(2)write allocate cache。当write cache miss的时候,分配cache line并将数据从main
memory读入,之后再进行数据更新的动作。一般而言,write back的cache会采用write allocate的策略。
4、物理地址还是虚拟地址?
当CPU发出地址访问的时候,从CPU出去的地址是虚拟地址,经过MMU的映射,最终变成物理地址。这时候,问题来了,我们是用虚拟地址还是物理地址(中的cache
set index)来寻找cache set?此外,当找到了cache set,那么我们用虚拟地址还是物理地址(中的Tag)来匹配cache
line?
根据使用的是物理地址还是虚拟地址,cache可以分成下面几个类别:
(1)VIVT(Virtual index Virtual tag)。寻找cache set的index和匹配cache line的tag都是使用虚拟地址。
(2)PIPT(Physical index Physical tag)。寻找cache set的index和匹配cache line的tag都是使用物理地址。
(3)VIPT(Virtual index Physical tag)。寻找cache set的index使用虚拟地址,而匹配cache line的tag使用的是物理地址。
对于一个计算机系统,CPU core、MMU和Cache是三个不同的HW
block。采用PIPT的话,CPU发出的虚拟地址要先经过MMU翻译成物理地址之后,再输入到cache中进行cache hit or
miss的判断,毫无疑问,这个串行化的操作损害了性能。但是这样简单而粗暴的使用物理地址没有歧义,不会有cache
alias。VIVT的方式毫无疑问是最快的,不需要MMU的翻译直接进入cache判断hit or
miss,不过会引入其他问题,例如:一个物理地址的内容可以出现在多个cache line中,这就需要更多的cache
flush操作。反而影响了速度(这就是传说中的cache
alias,具体请参考下面的章节)。采用VIPT的话,CPU输出的虚拟地址可以同时送到MMU(进行翻译)和cache(进行cache
set的选择)。这样cache 和MMU可以同时工作,而MMU完成地址翻译后,再用物理的tag来匹配cache line。这种方法比不上VIVT
的cache 速度, 但是比PIPT 要好。在某些情况下,VIPT也会有cache alias的问题,但可以用巧妙的方法避过,后文会详细描述。
对于ARM而言,随着技术进步,MMU的翻译速度提高了,在cache 用index查找cache
set的过程中MMU已经可以完成虚拟地址到物理地址的转换工作,因此在cache比较tag的时候物理地址已经可以使用了,就是说采用
physical
tag可以和cache并行工作,不会影响cache的速度。因此,在新的ARM构建中(如ARMv6和ARMv7中),采用了VIPT的方式。
5、cache alias
在linux内核中可能有这样的场景:同一个物理地址被映射到多个不同的虚拟地址上。在这样的场景下,我们可以研究一下cache是如何处理的。
对于PIPT,没有alias,因为cache set selection和tag匹配都是用物理地址,对于一个物理地址,cache中只会有一个cache line的数据与之对应。
对于VIPT的cache system,虽然在匹配tag的时候使用physical address tag,但是却使用virtual
address的set index进行cache set查找,这时候由于使用不同的虚拟地址而导致多个cache
line针对一个物理地址。对于linux的内存管理子系统而言,virtual address
space是通过4k的page进行管理的。对于物理地址和虚拟地址,其低12 bit是完全一样。
因此,即使是不同的虚拟地址映射到同一个物理地址,这些虚拟地址的低12bit也是一样的。在这种情况下,如果查找cache
set的index位于低12 bit的范围内,那么alais不会发生,因为不同的虚拟地址对应同一个cache line。当index超过低12
bit的范围,就会产生alais。在实际中,cache line一般是32B,占5个bit,在VIPT的情况下,set
index占用7bit(包括7bit)一下,VIPT就不存在alias的问题。在我接触到的项目中,ARM的16K
cache都是采用了128个cache set,也就是7个bit的set index,恰好满足了no alias的需求。
对于VIVT,cache中总是存在多于一个的cache line 包含这个物理地址的数据,总是存在cache alias的问题。
cache alias会影响cache flush的接口,特别是当flush某个或者某些物理地址的时候。这时候,系统软件需要找到该物理地址对应的所有的cache line进行flush的动作。
6、Cache Ambiguity
Cache
Ambiguity是指将不同的物理地址映射到相同的虚拟地址而造成的混乱。这种情况下在linux内核中只有在不同进程的用户空间的页面才可能发生。
Cache Ambiguity会造成同一个cache line在不同的进程中代表不同的数据, 切换进程的时候需要进行处理。
对于PIPT,不存在Cache Ambiguity,虽然虚拟地址一样,但是物理地址是不同的。对于VIPT,由于使用物理地址来检查是否cache
hit,因此不需要在进程切换的时候flush用户空间的cache来解决Cache Ambiguity的问题。VIVT会有Cache
Ambiguity的问题,一般会在进程切换或者exit mm的时候flush用户空间的cache
计算机科学基础知识(一)The Memory Hierarchy的更多相关文章
- CS(计算机科学)知识体
附 录 A CS( 计算机科学)知识体 计算教程 2001 报告的这篇附录定义了计算机科学本科教学计划中可能讲授的知识领域.该分类方案的依据及其历史.结构和应用的其 ...
- Python开发【第二篇】:Python基础知识
Python基础知识 一.初识基本数据类型 类型: int(整型) 在32位机器上,整数的位数为32位,取值范围为-2**31-2**31-1,即-2147483648-2147483647 在64位 ...
- IOS开发基础知识碎片-导航
1:IOS开发基础知识--碎片1 a:NSString与NSInteger的互换 b:Objective-c中集合里面不能存放基础类型,比如int string float等,只能把它们转化成对象才可 ...
- Oracle数据库基础知识
oracle数据库plsql developer 目录(?)[-] 一 SQL基础知识 创建删除数据库 创建删除修改表 添加修改删除列 oracle cascade用法 添加删除约束主键外 ...
- 谈谈计算机上的那些存储器-Memory Hierarchy
文章首发于浩瀚先森博客http://www.guohao1206.com/2016/12/07/1248.html 说到计算机上的存储器,很多人第一反应是硬盘,然后是内存. 其实在计算机上除了硬盘和内 ...
- JAVA多线程基础知识(一)
一. 基础知识 要了解多线程首先要知道一些必要的概念,如进程,线程等等.开发多线程的程序有利于充分的利用系统资源(CPU资源),使你的程序执行的更快,响应更及时. 1. 进程,一般是指程序或者任务的执 ...
- jQuery学习笔记 - 基础知识扫盲入门篇
jQuery学习笔记 - 基础知识扫盲入门篇 2013-06-16 18:42 by 全新时代, 11 阅读, 0 评论, 收藏, 编辑 1.为什么要使用jQuery? 提供了强大的功能函数解决浏览器 ...
- Unity3D基础知识梳理
这段时间在做Unity的项目,这差不多是我的第一次实战啊~然后公司来了实习的童鞋要学Unity,但是我一向不靠谱啊,所以只能帮他们稍微梳理下基础的东西了啊,唉~学长只能帮你们到这里了~顺便就把自己这两 ...
- css+js+html基础知识总结
css+js+html基础知识总结 一.CSS相关 1.css的盒子模型:IE盒子模型.标准W3C盒子模型: 2.CSS优先级机制: 选择器的优先权:!important>style(内联样式) ...
随机推荐
- iOS开发-plist文件增删改查
plist第一次看到这个后缀名文件的时候感觉怪怪的,不过接触久了也就习以为常了,plist是Property List的简称可以理解成属性列表文件,主要用来存储串行化后的对象的文件.扩展名为.plis ...
- Android中Fragment的简单介绍
Android是在Android 3.0 (API level 11)引入了Fragment的,中文翻译是片段或者成为碎片(个人理解),可以把Fragment当成Activity中的模块,这个模块有自 ...
- java 解析 XML实例
package com.hseact.fecp.servlet; import java.io.IOException; import javax.xml.parsers.DocumentBuilde ...
- IOS实现多媒体音频之音乐播放器
随着智能手机市场越来越活跃,相应的app也变得五彩缤纷,各式各样,让你的app更吸引人多媒体技术不可避免.通过对音频和视频等控制让你的app更加丰富多彩,今天和大家一起研究下基本的音频使用.本文只提供 ...
- 在Foreda8中整合Apche httpd2.4.6和Tomcat7.0.42(使用tomcat-connectors-1.2.37)
本地Apche httpd2.4.6(http://pan.baidu.com/share/link?shareid=4003375081&uk=34256769)和Tomcat7.0.42是 ...
- 【Flash 插件】时钟类插件
1.honehone_clock人体时钟实现 原理:就是在网页上播放已写好的.SWF文件. 效果如下: 效果一:背景透明,推荐为白色或浅背景 效果二:背景白色,推荐黑色或深色背景 实现步骤: 先引用 ...
- poj 2486 Apple Tree (树形背包dp)
本文出自 http://blog.csdn.net/shuangde800 题目链接: poj-2486 题意 给一个n个节点的树,节点编号为1~n, 根节点为1, 每个节点有一个权值. 从 ...
- PHP 循环
PHP 中的循环语句用于执行相同的代码块指定的次数. 循环 在您编写代码时,您经常需要让相同的代码块运行很多次.您可以在代码中使用循环语句来完成这个任务. 在 PHP 中,我们可以使用下列循环语句: ...
- yum安装MangoDB
1:操作系统信息 2:yum命令查看MongoDB的包信息 3:配置yum源 #vi /etc/yum.repos.d/10gen.repo 4:查看mongoDB的服务器包的信息 5:安装Mongo ...
- 【docker】挂载web应用
现在将webapps目录挂载在宿主机目录,方便运维 docker run -p 8090:8080 --name app -v /usr/app:/usr/local/tomcat/webapps d ...