Spark系列-核心概念
一. Spark核心概念
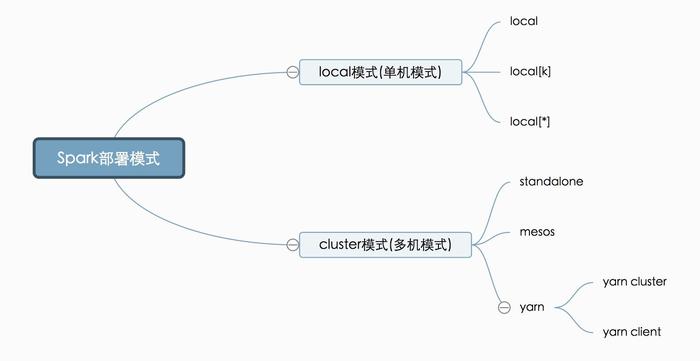
- Master,也就是架构图中的Cluster Manager。Spark的Master和Workder节点分别Hadoop的NameNode和DataNode相似,是一种主从结构。Master是集群的领导者,负责协调和管理集群内的所有资源(接收调度和向WorkerNode发送指令)。从大类上来分Master分为local和cluster两大类
- local:也就是本地模式,所有计算都在一台服务器上完成,通常用于本地开发调试。思维导图中
- local:表示启动一个线程,所有的计算都在这个线程中完成
- local[k]:启动k个worker线程
- local[*]:按照当前服务器的cpu核数来启动
- cluster:也就是集群模式,由多台服务器并行执行。
- standalone:spark自带的资源管理器
- mesos:由mesos来管理
- yarn:通常和MapReduce作业一样,资源共享,所以使用的最多。(yarn cluster:所有调度资源都在集群上运行,yarn client:出了spark driver和master进程,其余都在集群上)
- local:也就是本地模式,所有计算都在一台服务器上完成,通常用于本地开发调试。思维导图中
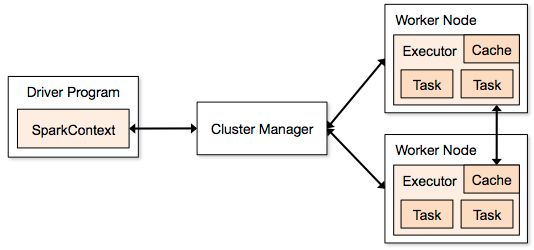
- Worker,也就是WorkderNode,负责执行Master所发送的指令,来具体分配资源并执行任务
- Driver:一个Spark job运行前会启动一个Driver进程,也就是作业的主进程,负责解析和生成各个Stage,并调度Task到Executor上
- Executer:负责执行作业。如图中所以,Executer是分步在各个Worker Node上,接收来自Driver的命令并加载Task
- SparkContext:程序运行调度的核心,高层调度去DAGScheduler划分程序的每个阶段,底层调度器TaskScheduler划分每个阶段具体任务
- DAGScheduler:负责高层调度,划分stage并生产DAG有向无环图
- TaskScheduler:负责具体stage内部的底层调度,具体task的调度和容错
- Job:每次Action都会触发一次Job,一个Job可能包含一个或多个stage
- Stage:用来计算中间结果的Tasksets。分为ShuffleMapStage和ResultStage,出了最后一个Stage是ResultStage外,其他都是ShuffleMapStage。ShuffleMapStage会产生中间结果,是以文件的方式保存在集群当中,以便能够在不同stage种重用
- Task:任务执行的工作单位,每个Task会被发送到一个节点上,每个Task对应RDD的一个partition.
- RDD:是以partition分片的不可变,Lazy级别数据集合
- 算子
- Transformation:由DAGScheduler划分到pipeline中,是Lazy级别的,不会触发任务的执行
- Action:会触发Job来执行pipeline中的运算
Spark系列-核心概念的更多相关文章
- Spark Streaming核心概念与编程
Spark Streaming核心概念与编程 1. 核心概念 StreamingContext Create StreamingContext import org.apache.spark._ im ...
- Spark系列-初体验(数据准备篇)
Spark系列-初体验(数据准备篇) Spark系列-核心概念 在Spark体验开始前需要准备环境和数据,环境的准备可以自己按照Spark官方文档安装.笔者选择使用CDH集群安装,可以参考笔者之前的文 ...
- Spark系列-SparkSQL实战
Spark系列-初体验(数据准备篇) Spark系列-核心概念 Spark系列-SparkSQL 之前系统的计算大部分都是基于Kettle + Hive的方式,但是因为最近数据暴涨,很多Job的执行时 ...
- spark系列-2、Spark 核心数据结构:弹性分布式数据集 RDD
一.RDD(弹性分布式数据集) RDD 是 Spark 最核心的数据结构,RDD(Resilient Distributed Dataset)全称为弹性分布式数据集,是 Spark 对数据的核心抽象, ...
- Spark核心概念理解
本文主要内容来自于<Hadoop权威指南>英文版中的Spark章节,能够说是个人的翻译版本号,涵盖了基本的Spark概念.假设想获得更好地阅读体验,能够訪问这里. 安装Spark 首先从s ...
- ZooKeeper 系列(一)—— ZooKeeper核心概念详解
一.Zookeeper简介 二.Zookeeper设计目标 三.核心概念 3.1 集群角色 3.2 会话 3.3 数据节点 3.4 节点 ...
- 大话Spark(1)-Spark概述与核心概念
说到Spark就不得不提MapReduce/Hadoop, 当前越来越多的公司已经把大数据计算引擎从MapReduce升级到了Spark. 至于原因当然是MapReduce的一些局限性了, 我们一起先 ...
- ZooKeeper系列(一)—— ZooKeeper 简介及核心概念
一.Zookeeper简介 Zookeeper 是一个开源的分布式协调服务,目前由 Apache 进行维护.Zookeeper 可以用于实现分布式系统中常见的发布/订阅.负载均衡.命令服务.分布式协调 ...
- Storm 系列(二)—— Storm 核心概念详解
一.Storm核心概念 1.1 Topologies(拓扑) 一个完整的 Storm 流处理程序被称为 Storm topology(拓扑).它是一个是由 Spouts 和 Bolts 通过 Stre ...
随机推荐
- android service服务的学习
1.Service简单概述 Service(服务)是一个一种可以在后台执行长时间运行操作而没有用户界面的应用组件.服务可由其他应用组件启动(如Activity),服务一旦被启动将在后台一直运行,即 ...
- [日常] Go语言圣经-WEB服务与习题
Go语言圣经-web服务 1.Web服务程序,标准库里的方法已经帮我们完成了大量工作 2.main函数将所有发送到/路径下的请求和handler函数关联起来,/开头的请求其实就是所有发送到当前站点上的 ...
- 关于JavaScript线程的讲解
讲述js执行的相关线程.DOM操作等问题.参考博客:http://www.codeceo.com/article/javascript-threaded.html
- LeetCode刷题第二天
2.给出两个 非空 的链表用来表示两个非负的整数.其中,它们各自的位数是按照 逆序 的方式存储的,并且它们的每个节点只能存储 一位 数字. 如果,我们将这两个数相加起来,则会返回一个新的链表来表示它们 ...
- WAI-ARIA无障碍网页应用属性完全展示——张鑫旭
一.你至少应该知道ARIA是什么东西! WAI-ARIA指无障碍网页应用.主要针对的是视觉缺陷,失聪,行动不便的残疾人以及假装残疾的测试人员.尤其像盲人,眼睛看不到,其浏览网页则需要借助辅助设备,如屏 ...
- VMware安装vnwaretools
1. 在VMware Fusion 6.0.4下安装Ubuntu镜像:ubuntu-14.04.1-desktop-amd64.iso 2. 点击虚拟机菜单栏-安装VMware Tools 3. 进入 ...
- 一步一步 Pwn RouterOS之调试环境搭建&&漏洞分析&&poc
前言 本文由 本人 首发于 先知安全技术社区: https://xianzhi.aliyun.com/forum/user/5274 本文分析 Vault 7 中泄露的 RouterOs 漏洞.漏洞影 ...
- ArrayMap代替HashMap
ArrayMap是一个<key,value>映射的数据结构,它设计上更多的是考虑内存的优化,内部是使用两个数组进行数据存储,一个数组记录key的hash值,另外一个数组记录Value值,它 ...
- git常用命令简集
基础操作: 初始化git仓库: git init 提交到暂存区: git add “filename” 提交到分支: git commit -m "注释" 工作区状态: git s ...
- Week5——applet
1.定义 applet是一种Java程序.它一般运行在支持Java的Web浏览器内.因为它有完整的Java API支持,所以applet是一个全功能的Java应用程序. 2.特点(不同于Java a ...