python之I/O操作
IO在计算机中指Input/Output,也就是输入和输出。由于程序和运行时数据是在内存中驻留,由CPU这个超快的计算核心来执行,涉及到数据交换的地方,通常是磁盘、网络等,就需要IO接口。
比如你打开浏览器,访问新浪首页,浏览器这个程序就需要通过网络IO获取新浪的网页。浏览器首先会发送数据给新浪服务器,告诉它我想要首页的HTML,这个动作是往外发数据,叫Output,随后新浪服务器把网页发过来,这个动作是从外面接收数据,叫Input。所以,通常,程序完成IO操作会有Input和Output两个数据流。当然也有只用一个的情况,比如,从磁盘读取文件到内存,就只有Input操作,反过来,把数据写到磁盘文件里,就只是一个Output操作。
事件驱动模型
通常情况,有一下几种情况模型:
- 每收到一个请求,创建一个新的进程,来处理该请求。
- 每收到一个请求,创建一个新的线程,来处理该请求。
- 每收到一个请求,放入一个时间列表,让主进程通过非阻塞IO来处理请求。
综上普遍认为第三种方式为大多数网络服务器采用的方式。
例如在UI编程中,常常用到鼠标点击进行操作,那么如何,何时去获得鼠标的点击进行处理呢?
在前面学到的线程中,我们可以创建一个线程对鼠标进行检测。那么问题来了?
- CPU资源浪费,可能鼠标点击的频率非常小,但是扫描线程还是会一直循环检测,这会造成很多的CPU资源浪费;如果扫描鼠标点击的接口是阻塞的呢?
- 如果是堵塞的,又会出现下面这样的问题,如果我们不但要扫描鼠标点击,还要扫描键盘是否按下,由于扫描鼠标时被堵塞了,那么可能永远不会去扫描键盘;
- 如果一个循环需要扫描的设备非常多,这又会引来响应时间的问题;
所以此方式是不可取的
第二种就是刚提到的事件驱动模型
目前大部分的UI编程都是事件驱动模型。如很多UI平台都会提供onClick()事件,这个事件就代表鼠标按下事件。事件驱动模型大体思路如下:
- 有一个消息队列
- 鼠标点击时,往这个队列里增加一个点击事件。
- 有个循环,不断的从队列中取出事件,根据不同事件调用不同的函数。
- 事件一般都各自保存各自的处理函数指针,这样,每个消息都有独立的处理函数。
简单的代码示例如下
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body>
<p onclick="func()">点我</p> <script>
function func() {
alert("你好")
} </script>
</body>
</html>
图形讲解

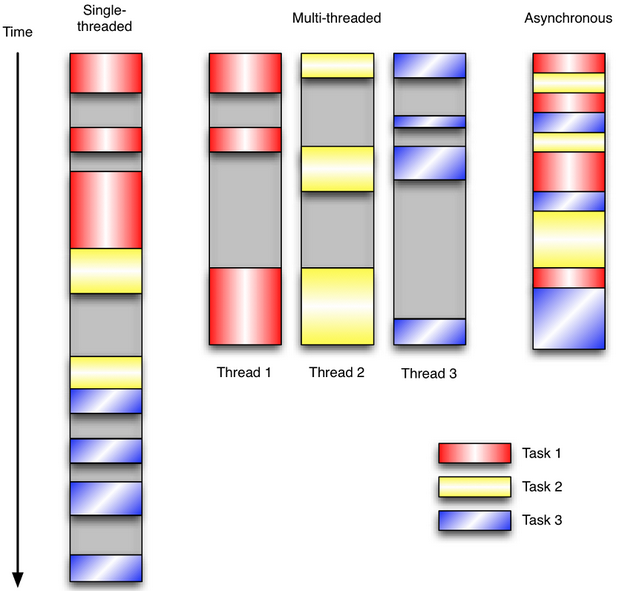
事件驱动编程是一种编程范式,这里程序的执行流由外部事件来决定。它的特点是包含一个事件循环,当外部事件发生时使用回调机制来触发相应的处理。另外两种常见的编程范式是(单线程)同步以及多线程编程。
用个简单的图例来讲解三者关系
图中灰色部分表示I/O操作阻塞的时间
同步IO和异步IO
于CPU和内存的速度远远高于外设的速度,所以,在IO编程中,就存在速度严重不匹配的问题。举个例子来说,比如要把100M的数据写入磁盘,CPU输出100M的数据只需要0.01秒,可是磁盘要接收这100M数据可能需要10秒,怎么办呢?有两种办法:
- 第一种是CPU等着,也就是程序暂停执行后续代码,等100M的数据在10秒后写入磁盘,再接着往下执行,这种模式称为同步IO;
- 另一种方法是CPU不等待,只是告诉磁盘,“您老慢慢写,不着急,我接着干别的事去了”,于是,后续代码可以立刻接着执行,这种模式称为异步IO。
同步和异步的区别就在于是否等待IO执行的结果。举个例子来说。
好比你去麦当劳点餐,你说“来个汉堡”,服务员告诉你,对不起,汉堡要现做,需要等5分钟,于是你站在收银台前面等了5分钟,拿到汉堡再去逛商场,这是同步IO。
你说“来个汉堡”,服务员告诉你,汉堡需要等5分钟,你可以先去逛商场,等做好了,我们再通知你,这样你可以立刻去干别的事情(逛商场),这是异步IO。
异步IO模型
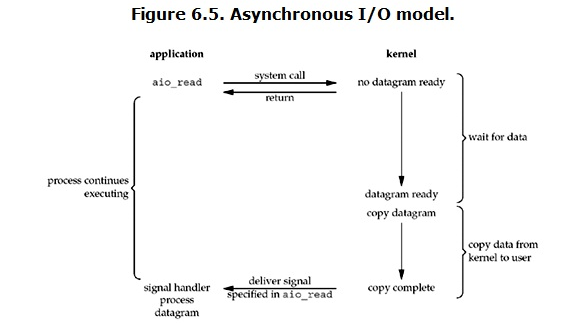
异步IO全程过程没有阻塞状态。
注: 异步IO模块3.0才有,叫asyncio
阻塞IO(blocking IO )
就上面的例子你去麦当劳点汉堡,但此时没有了,要5分钟后才出来,而你咬着等5分钟,此刻的5分钟就浪费了,这就是典型的阻塞IO。大概流程可以这样表示

非阻塞IO(non-blocking IO)
假设你不想在那等,就出去办其他的事了,但是你又担心你点的汉堡被别人拿走了,你就来来回回好多趟,最后终于做好了。大概流程如下

需要注意,拷贝数据整个过程,进程仍然是属于阻塞的状态
IO多路复用(IO multiplexing)
它的基本原理就是select/epoll这个function会不断的轮询所负责的所有socket,当某个socket有数据到达了,就通知用户进程。就如我们点好餐后,不用每次都去问服务员了,看专门的显示屏即可知道,那样每个顾客都知道自己的等待时间了。它的流程如图:

注意:当用户进程调用了select时,那么整个进程就会阻塞住。看似和阻塞IO没有太大的区别,但是这可以同时监听处理多个connection。整个用户的process其实是一直被block的。只不过process是被select这个函数block,而不是被socket IO给block。
综上所述,对几种IO模型进行比较如下:

IO多路复用select,poll,epoll
select
select 函数监视的文件描述符分3类,分别是writefds、readfds、和exceptfds。调用后select函数会阻塞,直到有描述符就绪(可读、可写、或except),或超时(timeout等待时间,如立即返回设为null即可),函数返回。当select函数返回后,可以通过遍历fdset,来找到就绪的描述符。
select优势在于几乎支持所有平台。
缺点在于
- 单个进程能够监视的文件描述符的数量存在最大限制,默认为1024.
- 每次select()都要轮询遍历FD_SETSIZE个Socket来完成调度,效率较低。
- 需要维护一个用来存放大量fd的数据结构,使得用户空间和内核空间在传递时复制开销大。
poll
相当于是select和epoll之间的过度,唯一的改动就是没有了文件描述符的数量限制
epoll(linux特有的实现方法,目前windows不支持)
epoll有两种模式,区别在当epoll_wait检测到描述符事件发生并将此事件通知应用程序。
- LT模式:应用程序可以不立即处理该事件。下次调用epoll_wait时,会再次响应应用程序并通知此事件。
- ET模式:应用程序必须立即处理该事件。如果不处理,下次调用epoll_wait时,不会再次响应应用程序并通知此事件。须使用非阻塞套接口
最后举个并发聊天的例子如
import socket
import select sk = socket.socket()
sk.bind(('127.0.0.1', 8080))
sk.listen(3) sk_list = [sk, ] while True:
r_list, w_list, x_list = select.select(sk_list, [], [],) for i in r_list:
if i == sk:
conn, addr = i.accept() #接收第一个传进来的也就是sk,之后开始执行conn了
sk_list.append(conn)
elif i == conn: data = conn.recv(1024)
data = data.decode('utf8')
try:
# data is False
if data is not False:
print(data)
inp = input("回复客户端 %s >>>>" % sk_list.index(i))
conn.sendall(inp.encode('utf8')) except Exception:
# print(e)
sk_list.remove(i)
server
import socket
sk = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
sk.connect(('127.0.0.1', 8080))
while True:
inp = input(">>>>")
sk.sendall(inp.encode('utf8'))
data = sk.recv(1024)
print(data.decode('utf8'))
client
python之I/O操作的更多相关文章
- Python开发【第三篇】:Python基本之文件操作
Python基本之文本操作 一.初识文本的基本操作 在python中打开文件有两种方式,即:open(...) 和 file(...) ,本质上前者在内部会调用后者来进行文件操作,推荐使用 open ...
- 【Python数据分析】Python3操作Excel(二) 一些问题的解决与优化
继上一篇[Python数据分析]Python3操作Excel-以豆瓣图书Top250为例 对豆瓣图书Top250进行爬取以后,鉴于还有一些问题没有解决,所以进行了进一步的交流讨论,这期间得到了一只尼玛 ...
- [python]用Python进行SQLite数据库操作
用Python进行SQLite数据库操作 1.导入Python SQLITE数据库模块 Python2.5之后,内置了SQLite3,成为了内置模块,这给我们省了安装的功夫,只需导入即可~ ]: u ...
- python学习笔记:文件操作和集合(转)
转自:http://www.nnzhp.cn/article/16/ 这篇博客来说一下python对文件的操作. 对文件的操作分三步: 1.打开文件获取文件的句柄,句柄就理解为这个文件 2.通过文件句 ...
- python os&shutil 文件操作
python os&shutil 文件操作 # os 模块 os.sep 可以取代操作系统特定的路径分隔符.windows下为 '\\' os.name 字符串指示你正在使用的平台.比如对于W ...
- python对mysql数据库操作的三种不同方式
首先要说一下,在这个暑期如果没有什么特殊情况,我打算用python尝试写一个考试系统,希望能在下学期的python课程实际使用,并且尽量在此之前把用到的相关技术都以分篇博客的方式分享出来,有想要交流的 ...
- Python实现浏览器自动化操作
Python实现浏览器自动化操作 (2012-08-02 17:35:43) 转载▼ 最近在研究网站自动登录的问题,涉及到需要实现浏览器自动化操作,网上有不少介绍,例如使用pamie,但是只是 ...
- [转载]Python实现浏览器自动化操作
原文地址:Python实现浏览器自动化操作作者:rayment 最近在研究网站自动登录的问题,涉及到需要实现浏览器自动化操作,网上有不少介绍,例如使用pamie,但是只是支持IE,而且项目也较久没 ...
- [Python爬虫]使用Selenium操作浏览器订购火车票
这个专题主要说的是Python在爬虫方面的应用,包括爬取和处理部分 [Python爬虫]使用Python爬取动态网页-腾讯动漫(Selenium) [Python爬虫]使用Python爬取静态网页-斗 ...
- python中的赋值操作和复制操作
之前一直写C#,变量之间赋值相当于拷贝,修改拷贝变量不会改变原来的值.但是在python中发现赋值操作本质是和C++中的引用类似,即指向同一块内存空间.下面通过一个例子说明: p=[0,1,2,3,4 ...
随机推荐
- jQuery—常用操作
一.jquery各版本变化 1.3:增加live(),为当前和将来增加的元素绑定事件 1.4:增加delegate().undelegate(),替代live(),可以遍历绑定 1.6:2个破坏性变更 ...
- UICollectionViewCell 网格显示数据
using System; using System.Collections.Generic; using Foundation; using UIKit; namespace ddd { publi ...
- 【总结】富有表现力的JavaScript
1.JavaScript的灵活性 JavaScript是目前最流行.应用最广泛的语言之一,它是一种极富表现力的语言,它具有C家族语言所罕见的特性.这种语言允许我们使用各种方式来完成同一个任务或者功能, ...
- HTTP Cache
最近在学习HTTP协议,看的书籍是<HTTP权威指南>,这本书讲的很不错,细节都讲的很透彻,虽然书本比较厚,因为讲的通俗易懂,所以比较有意思并不觉得枯燥.下面是读书后做的读书笔记. [图片 ...
- Base64编码【转】
转http://www.cnblogs.com/luguo3000/p/3940197.html 开发者对Base64编码肯定很熟悉,是否对它有很清晰的认识就不一定了.实际上Base64已经简单到不能 ...
- [Android]优化相关
尽量减少布局的层次,最多10层,可以通过LinearLayout向RelativeLayout的转变来减少层的数量 使用ListView的时候,getView方法中的对象尽量重用
- Visual SVN 5.01 Po jie 笔记
最近搞项目要与几个同事一起coding,鉴于代码的合并和提交的问题,所以要搞个版本管理.由于是私有的项目,所以退git 求SVN了.装了乌龟和Visual SVN,才发现Visual SVN的客户端不 ...
- 2.5多重else嵌套的二次方程求根
#include<stdio.h> #include<math.h> int main() { double a, b, c, disc, x1, x2, realpart, ...
- python之numpy
一.矩阵的拼接合并 列拼接:np.column_stack() >>> import numpy as np >>> a = np.arange(9).reshap ...
- 第4天--linux内核学习
驱动使用方式1.编译到内核中 * make uImage进入到系统后mknod /dev/led c 500 0 创建设备节点 2.编译为模块 M make module进入到系统后 mknod /d ...