SQLALchemy--ORM框架
SQLAlchemy
1.介绍
SQLAlchemy是一个基于Python实现的ORM框架。该框架建立在 DB API之上,使用关系对象映射进行数据库操作,简言之便是:将类和对象转换成SQL,然后使用数据API执行SQL并获取执行结果。
pip3 install sqlalchemy
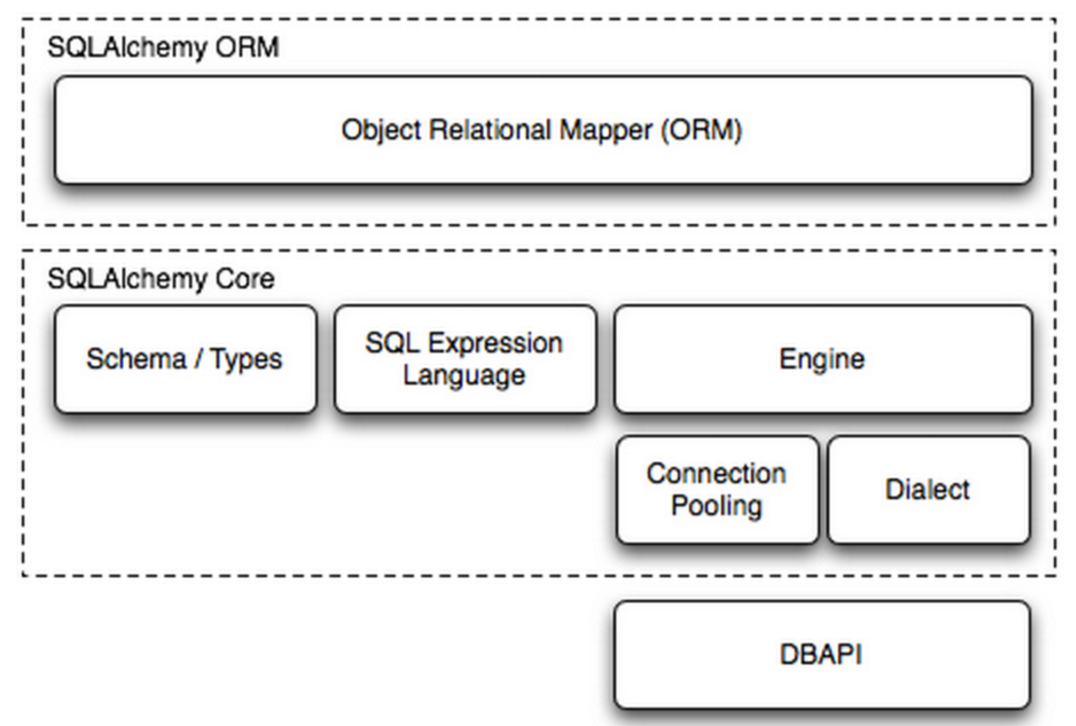
组成部分:
Engine,框架的引擎
Connection Pooling ,数据库连接池
Dialect,选择连接数据库的DB API种类
Schema/Types,架构和类型
SQL Exprression Language,SQL表达式语言
SQLAlchemy本身无法操作数据库,其必须以来pymsql等第三方插件,Dialect用于和数据API进行交流,根据配置文件的不同调用不同的数据库API,从而实现对数据库的操作,如:
MySQL-Python
mysql+mysqldb://<user>:<password>@<host>[:<port>]/<dbname> pymysql
mysql+pymysql://<username>:<password>@<host>/<dbname>[?<options>] MySQL-Connector
mysql+mysqlconnector://<user>:<password>@<host>[:<port>]/<dbname> cx_Oracle
oracle+cx_oracle://user:pass@host:port/dbname[?key=value&key=value...] 更多:http://docs.sqlalchemy.org/en/latest/dialects/index.html
2.简单使用(能创建表,删除表,不能修改表)
修改表:在数据库添加字段,类对应上
1执行原生sql(不常用)
import time
import threading
import sqlalchemy
from sqlalchemy import create_engine
from sqlalchemy.engine.base import Engine
engine = create_engine(
"mysql+pymysql://root:123456@127.0.0.1:3306/test?charset=utf8",
max_overflow=0, # 超过连接池大小外最多创建的连接
pool_size=5, # 连接池大小
pool_timeout=30, # 池中没有线程最多等待的时间,否则报错
pool_recycle=-1 # 多久之后对线程池中的线程进行一次连接的回收(重置)
)
def task(arg):
conn = engine.raw_connection()
cursor = conn.cursor()
cursor.execute(
"select * from app01_book"
)
result = cursor.fetchall()
print(result)
cursor.close()
conn.close()
for i in range(20):
t = threading.Thread(target=task, args=(i,))
t.start()
2 orm使用
models.py
import datetime
from sqlalchemy import create_engine
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import Column, Integer, String, Text, ForeignKey, DateTime, UniqueConstraint, Index
Base = declarative_base()
class Users(Base):
__tablename__ = 'users' # 数据库表名称
id = Column(Integer, primary_key=True) # id 主键
name = Column(String(32), index=True, nullable=False) # name列,索引,不可为空
# email = Column(String(32), unique=True)
#datetime.datetime.now不能加括号,加了括号,以后永远是当前时间
# ctime = Column(DateTime, default=datetime.datetime.now)
# extra = Column(Text, nullable=True)
__table_args__ = (
# UniqueConstraint('id', 'name', name='uix_id_name'), #联合唯一
# Index('ix_id_name', 'name', 'email'), #索引
)
def init_db():
"""
根据类创建数据库表
:return:
"""
engine = create_engine(
"mysql+pymysql://root:123456@127.0.0.1:3306/aaa?charset=utf8",
max_overflow=0, # 超过连接池大小外最多创建的连接
pool_size=5, # 连接池大小
pool_timeout=30, # 池中没有线程最多等待的时间,否则报错
pool_recycle=-1 # 多久之后对线程池中的线程进行一次连接的回收(重置)
)
Base.metadata.create_all(engine)
def drop_db():
"""
根据类删除数据库表
:return:
"""
engine = create_engine(
"mysql+pymysql://root:123456@127.0.0.1:3306/aaa?charset=utf8",
max_overflow=0, # 超过连接池大小外最多创建的连接
pool_size=5, # 连接池大小
pool_timeout=30, # 池中没有线程最多等待的时间,否则报错
pool_recycle=-1 # 多久之后对线程池中的线程进行一次连接的回收(重置)
)
Base.metadata.drop_all(engine)
if __name__ == '__main__':
# drop_db()
init_db()
app.py
from sqlalchemy.orm import sessionmaker
from sqlalchemy import create_engine
from models import Users
#"mysql+pymysql://root@127.0.0.1:3306/aaa"
engine = create_engine("mysql+pymysql://root:123456@127.0.0.1:3306/aaa", max_overflow=0, pool_size=5)
Connection = sessionmaker(bind=engine)
# 每次执行数据库操作时,都需要创建一个Connection
con = Connection()
# ############# 执行ORM操作 #############
obj1 = Users(name="lqz")
con.add(obj1)
# 提交事务
con.commit()
# 关闭session,其实是将连接放回连接池
con.close()
3.一对多关系
class Hobby(Base):
__tablename__ = 'hobby'
id = Column(Integer, primary_key=True)
caption = Column(String(50), default='篮球')
class Person(Base):
__tablename__ = 'person'
nid = Column(Integer, primary_key=True)
name = Column(String(32), index=True, nullable=True)
# hobby指的是tablename而不是类名
hobby_id = Column(Integer, ForeignKey("hobby.id")) # 跟数据库无关,不会新增字段,只用于快速链表操作
# 类名,backref用于反向查询
hobby=relationship('Hobby',backref='pers')
4.多对多关系
class Boy2Girl(Base):
__tablename__ = 'boy2girl'
id = Column(Integer, primary_key=True, autoincrement=True)
girl_id = Column(Integer, ForeignKey('girl.id'))
boy_id = Column(Integer, ForeignKey('boy.id'))
class Girl(Base):
__tablename__ = 'girl'
id = Column(Integer, primary_key=True)
name = Column(String(64), unique=True, nullable=False)
class Boy(Base):
__tablename__ = 'boy'
id = Column(Integer, primary_key=True, autoincrement=True)
hostname = Column(String(64), unique=True, nullable=False) # 与生成表结构无关,仅用于查询方便,放在哪个单表中都可以
servers = relationship('Girl', secondary='boy2girl', backref='boys')
5.操作数据表
from sqlalchemy.orm import sessionmaker
from sqlalchemy import create_engine
from models import Users engine = create_engine("mysql+pymysql://root:123456@127.0.0.1:3306/aaa", max_overflow=0, pool_size=5)
Session = sessionmaker(bind=engine) # 每次执行数据库操作时,都需要创建一个session
session = Session() # ############# 执行ORM操作 #############
obj1 = Users(name="lqz")
session.add(obj1) # 提交事务
session.commit()
# 关闭session
session.close()
6.基于scoped_session实现线程安全
from sqlalchemy.orm import sessionmaker
from sqlalchemy import create_engine
from sqlalchemy.orm import scoped_session
from models import Users
engine = create_engine("mysql+pymysql://root:123@127.0.0.1:3306/s6", max_overflow=0, pool_size=5)
Session = sessionmaker(bind=engine)
"""
# 线程安全,基于本地线程实现每个线程用同一个session
# 特殊的:scoped_session中有原来方法的Session中的一下方法:
public_methods = (
'__contains__', '__iter__', 'add', 'add_all', 'begin', 'begin_nested',
'close', 'commit', 'connection', 'delete', 'execute', 'expire',
'expire_all', 'expunge', 'expunge_all', 'flush', 'get_bind',
'is_modified', 'bulk_save_objects', 'bulk_insert_mappings',
'bulk_update_mappings',
'merge', 'query', 'refresh', 'rollback',
'scalar'
)
"""
#scoped_session类并没有继承Session,但是却又它的所有方法
session = scoped_session(Session)
# ############# 执行ORM操作 #############
obj1 = Users(name="alex1")
session.add(obj1)
# 提交事务
session.commit()
# 关闭session
session.close()
7.基本增删查改
import time
import threading
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import Column, Integer, String, ForeignKey, UniqueConstraint, Index
from sqlalchemy.orm import sessionmaker, relationship
from sqlalchemy import create_engine
from sqlalchemy.sql import text
from db import Users, Hosts
engine = create_engine("mysql+pymysql://root:123@127.0.0.1:3306/s6", max_overflow=0, pool_size=5)
Session = sessionmaker(bind=engine)
session = Session()
# ################ 添加 ################
"""
obj1 = Users(name="wupeiqi")
session.add(obj1)
session.add_all([
Users(name="lqz"),
Users(name="egon"),
Hosts(name="c1.com"),
])
session.commit()
"""
# ################ 删除 ################
"""
session.query(Users).filter(Users.id > 2).delete()
session.commit()
"""
# ################ 修改 ################
"""
#传字典
session.query(Users).filter(Users.id > 0).update({"name" : "lqz"})
#类似于django的F查询
session.query(Users).filter(Users.id > 0).update({Users.name: Users.name + "099"}, synchronize_session=False)
session.query(Users).filter(Users.id > 0).update({"age": Users.age + 1}, synchronize_session="evaluate")
session.commit()
"""
# ################ 查询 ################
"""
r1 = session.query(Users).all()
#只取age列,把name重命名为xx
r2 = session.query(Users.name.label('xx'), Users.age).all()
#filter传的是表达式,filter_by传的是参数
r3 = session.query(Users).filter(Users.name == "lqz").all()
r4 = session.query(Users).filter_by(name='lqz').all()
r5 = session.query(Users).filter_by(name='lqz').first()
#:value 和:name 相当于占位符,用params传参数
r6 = session.query(Users).filter(text("id<:value and name=:name")).params(value=224, name='fred').order_by(Users.id).all()
#自定义查询sql
r7 = session.query(Users).from_statement(text("SELECT * FROM users where name=:name")).params(name='ed').all()
"""
#增,删,改都要commit()
session.close()
8.常用操作
# 条件
ret = session.query(Users).filter_by(name='lqz').all()
#表达式,and条件连接
ret = session.query(Users).filter(Users.id > 1, Users.name == 'eric').all()
ret = session.query(Users).filter(Users.id.between(1, 3), Users.name == 'eric').all()
#注意下划线
ret = session.query(Users).filter(Users.id.in_([1,3,4])).all()
#~非,除。。外
ret = session.query(Users).filter(~Users.id.in_([1,3,4])).all()
#二次筛选
ret = session.query(Users).filter(Users.id.in_(session.query(Users.id).filter_by(name='eric'))).all()
from sqlalchemy import and_, or_
#or_包裹的都是or条件,and_包裹的都是and条件
ret = session.query(Users).filter(and_(Users.id > 3, Users.name == 'eric')).all()
ret = session.query(Users).filter(or_(Users.id < 2, Users.name == 'eric')).all()
ret = session.query(Users).filter(
or_(
Users.id < 2,
and_(Users.name == 'eric', Users.id > 3),
Users.extra != ""
)).all()
# 通配符,以e开头,不以e开头
ret = session.query(Users).filter(Users.name.like('e%')).all()
ret = session.query(Users).filter(~Users.name.like('e%')).all()
# 限制,用于分页,区间
ret = session.query(Users)[1:2]
# 排序,根据name降序排列(从大到小)
ret = session.query(Users).order_by(Users.name.desc()).all()
#第一个条件重复后,再按第二个条件升序排
ret = session.query(Users).order_by(Users.name.desc(), Users.id.asc()).all()
# 分组
from sqlalchemy.sql import func
ret = session.query(Users).group_by(Users.extra).all()
#分组之后取最大id,id之和,最小id
ret = session.query(
func.max(Users.id),
func.sum(Users.id),
func.min(Users.id)).group_by(Users.name).all()
#haviing筛选
ret = session.query(
func.max(Users.id),
func.sum(Users.id),
func.min(Users.id)).group_by(Users.name).having(func.min(Users.id) >2).all()
# 连表(默认用forinkey关联)
ret = session.query(Users, Favor).filter(Users.id == Favor.nid).all()
#join表,默认是inner join
ret = session.query(Person).join(Favor).all()
#isouter=True 外连,表示Person left join Favor,没有右连接,反过来即可
ret = session.query(Person).join(Favor, isouter=True).all()
#打印原生sql
aa=session.query(Person).join(Favor, isouter=True)
print(aa)
# 自己指定on条件(连表条件),第二个参数,支持on多个条件,用and_,同上
ret = session.query(Person).join(Favor,Person.id==Favor.id, isouter=True).all()
# 组合(了解)UNION 操作符用于合并两个或多个 SELECT 语句的结果集
#union和union all的区别?
q1 = session.query(Users.name).filter(Users.id > 2)
q2 = session.query(Favor.caption).filter(Favor.nid < 2)
ret = q1.union(q2).all()
q1 = session.query(Users.name).filter(Users.id > 2)
q2 = session.query(Favor.caption).filter(Favor.nid < 2)
ret = q1.union_all(q2).all()
9.执行原生sql
import time
import threading
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import Column, Integer, String, ForeignKey, UniqueConstraint, Index
from sqlalchemy.orm import sessionmaker, relationship
from sqlalchemy import create_engine
from sqlalchemy.sql import text
from sqlalchemy.engine.result import ResultProxy
from db import Users, Hosts
engine = create_engine("mysql+pymysql://root:123@127.0.0.1:3306/s6", max_overflow=0, pool_size=5)
Session = sessionmaker(bind=engine)
session = Session()
# 查询
# cursor = session.execute('select * from users')
# result = cursor.fetchall()
# 添加
cursor = session.execute('insert into users(name) values(:value)',params={"value":'lqz'})
session.commit()
print(cursor.lastrowid)
session.close()
10.一对多
import time
import threading
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import Column, Integer, String, ForeignKey, UniqueConstraint, Index
from sqlalchemy.orm import sessionmaker, relationship
from sqlalchemy import create_engine
from sqlalchemy.sql import text
from sqlalchemy.engine.result import ResultProxy
from db import Users, Hosts, Hobby, Person
engine = create_engine("mysql+pymysql://root:123@127.0.0.1:3306/s6?charset=utf8", max_overflow=0, pool_size=5)
Session = sessionmaker(bind=engine)
session = Session()
# 添加
"""
session.add_all([
Hobby(caption='乒乓球'),
Hobby(caption='羽毛球'),
Person(name='张三', hobby_id=3),
Person(name='李四', hobby_id=4),
])
person = Person(name='张九', hobby=Hobby(caption='姑娘'))
session.add(person)
#添加二
hb = Hobby(caption='人妖')
hb.pers = [Person(name='文飞'), Person(name='博雅')]
session.add(hb)
session.commit()
"""
# 使用relationship正向查询
"""
v = session.query(Person).first()
print(v.name)
print(v.hobby.caption)
"""
# 使用relationship反向查询
"""
v = session.query(Hobby).first()
print(v.caption)
print(v.pers)
"""
#方式一,自己链表
# person_list=session.query(models.Person.name,models.Hobby.caption).join(models.Hobby,isouter=True).all()
person_list=session.query(models.Person,models.Hobby).join(models.Hobby,isouter=True).all()
for row in person_list:
# print(row.name,row.caption)
print(row[0].name,row[1].caption)
#方式二:通过relationship
person_list=session.query(models.Person).all()
for row in person_list:
print(row.name,row.hobby.caption)
#查询喜欢姑娘的所有人
obj=session.query(models.Hobby).filter(models.Hobby.id==1).first()
persons=obj.pers
print(persons)
session.close()
11.多对多
import time
import threading
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import Column, Integer, String, ForeignKey, UniqueConstraint, Index
from sqlalchemy.orm import sessionmaker, relationship
from sqlalchemy import create_engine
from sqlalchemy.sql import text
from sqlalchemy.engine.result import ResultProxy
from db import Users, Hosts, Hobby, Person, Group, Server, Server2Group
engine = create_engine("mysql+pymysql://root:123@127.0.0.1:3306/s6?charset=utf8", max_overflow=0, pool_size=5)
Session = sessionmaker(bind=engine)
session = Session()
# 添加
"""
session.add_all([
Server(hostname='c1.com'),
Server(hostname='c2.com'),
Group(name='A组'),
Group(name='B组'),
])
session.commit()
s2g = Server2Group(server_id=1, group_id=1)
session.add(s2g)
session.commit()
gp = Group(name='C组')
gp.servers = [Server(hostname='c3.com'),Server(hostname='c4.com')]
session.add(gp)
session.commit()
ser = Server(hostname='c6.com')
ser.groups = [Group(name='F组'),Group(name='G组')]
session.add(ser)
session.commit()
"""
# 使用relationship正向查询
"""
v = session.query(Group).first()
print(v.name)
print(v.servers)
"""
# 使用relationship反向查询
"""
v = session.query(Server).first()
print(v.hostname)
print(v.groups)
"""
session.close()
12.其它
import time
import threading
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import Column, Integer, String, ForeignKey, UniqueConstraint, Index
from sqlalchemy.orm import sessionmaker, relationship
from sqlalchemy import create_engine
from sqlalchemy.sql import text, func
from sqlalchemy.engine.result import ResultProxy
from db import Users, Hosts, Hobby, Person, Group, Server, Server2Group
engine = create_engine("mysql+pymysql://root:123@127.0.0.1:3306/s6?charset=utf8", max_overflow=0, pool_size=5)
Session = sessionmaker(bind=engine)
session = Session()
# 关联子查询:correlate(Group)表示跟Group表做关联,as_scalar相当于对该sql加括号,用于放在后面当子查询
subqry = session.query(func.count(Server.id).label("sid")).filter(Server.id == Group.id).correlate(Group).as_scalar()
result = session.query(Group.name, subqry)
"""
SELECT `group`.name AS group_name, (SELECT count(server.id) AS sid
FROM server
WHERE server.id = `group`.id) AS anon_1
FROM `group`
"""
'''
select * from tb where id in [select id from xxx];
select id,
name,
#必须保证此次查询只有一个值
(select max(id) from xxx) as mid
from tb
例如,第三个字段只能有一个值
id name mid
1 lqz 1,2 不合理
2 egon 2
'''
# 原生SQL
"""
# 查询
cursor = session.execute('select * from users')
result = cursor.fetchall()
# 添加
cursor = session.execute('insert into users(name) values(:value)',params={"value":'wupeiqi'})
session.commit()
print(cursor.lastrowid)
"""
session.close()
13.Flask-SQLAlchemy
flask和SQLAchemy的管理者,通过他把他们做连接
db = SQLAlchemy()
- 包含配置
- 包含ORM基类
- 包含create_all
- engine
- 创建连接
离线脚本,创建表
详见代码
SQLALchemy--ORM框架的更多相关文章
- 关于SQLAlchemy ORM框架
SQLAlchemy 1.介绍 SQLAlchemy是一个基于Python实现的ORM框架.该框架建立在 DB API之上,使用关系对象映射进行数据库操作,简言之便是:将类和对象转换成SQL,然后使用 ...
- ORM框架SQLAlchemy与权限管理系统的数据库设计
SQLAlchemy是Python编程语言下的一款ORM框架,该框架建立在数据库API之上,使用对象关系映射进行数据库操作,即:将对象转换成SQL,然后使用数据API执行SQL并获取执行结果. 执行流 ...
- MySQL之ORM框架SQLAlchemy
一 介绍 SQLAlchemy是Python编程语言下的一款ORM框架,该框架建立在数据库API之上,使用关系对象映射进行数据库操作,简言之便是:将对象转换成SQL,然后使用数据API执行SQL并获取 ...
- ORM框架SQLAlchemy
SQLAlchemy orm英文全称object relational mapping,就是对象映射关系程序,简单来说就是类似python这种面向对象的程序来说一切皆对象,但是使用的数据库却都是关系型 ...
- MySQL—ORM框架,sqlalchemy模块
武老师博客:ORM框架介绍 import os #1.当一类函数公用同样参数时候,可以转变成类运行 - 分类 #2.面向对象: 数据和逻辑组合在一起了 #3. 一类事物共同用有的属性和行为(方法) # ...
- Python ORM框架之SQLAlchemy
前言: Django的ORM虽然强大,但是毕竟局限在Django,而SQLAlchemy是Python中的ORM框架: SQLAlchemy的作用是:类/对象--->SQL语句--->通过 ...
- ORM框架之SQLALchemy
一.面向对象应用场景: 1.函数有共同参数,解决参数不断重用: 2.模板(约束同一类事物的,属性和行为) 3.函数编程和面向对象区别: 面向对象:数据和逻辑组合在一起:函数编程:数据和逻辑不能组合在一 ...
- python(十二)下:ORM框架SQLAlchemy使用学习
此出处:http://blog.csdn.net/fgf00/article/details/52949973 本节内容 ORM介绍 sqlalchemy安装 sqlalchemy基本使用 多外键关联 ...
- MySQL 第八篇:ORM框架SQLAlchemy
一 介绍 SQLAlchemy是Python编程语言下的一款ORM框架,该框架建立在数据库API之上,使用关系对象映射进行数据库操作,简言之便是:将对象转换成SQL,然后使用数据API执行SQL并获取 ...
- SQL学习笔记八之ORM框架SQLAlchemy
阅读目录 一 介绍 二 创建表 三 增删改查 四 其他查询相关 五 正查.反查 一 介绍 SQLAlchemy是Python编程语言下的一款ORM框架,该框架建立在数据库API之上,使用关系对象映射进 ...
随机推荐
- node 图片上传功能
node 代码: var http = require("http"); var express = require('express') app = express(), for ...
- 使用seaborn制图(柱状图)
import numpy as np import pandas as pd import matplotlib.pyplot as plt import seaborn as sns # 设置风格, ...
- VBA 使用QueryTables 中文乱码的处理
一般情况: cnn = "OLEDB;Provider=IBMDA400;Data Source=TFB4001;User ID=;Password=;" Sql = " ...
- windows下的java项目打jar分别编写在windows与linux下运行的脚本( 本人亲测可用!)
前言: 最近公司做了一个工具,要将这个工具打包成一个可运行的程序,编写start.bat和start.sh在windows和linux下都可以运行. 在网上找了很多资料,最后终于找到一个可靠的资料,记 ...
- heat 用法 示例
heat.exe dir "./SampleFolder" -cg Files -dr INSTALLDIR -gg -g1 -sf -srd -var "var.Tar ...
- Python 3 学习笔记(2)
输入输出 str() 函数人类可读,repr() 解释器可读 rjust() 靠右,ljust() 靠左,center() 居中.zfill() 填0. 名字空间 名字到对象的映射关系被称为名字空间. ...
- 【341】Numpy 相关应用
Numpy_01 >>> from numpy import pi >>> np.linspace(0, 2, 9) array([0. , 0.25, 0.5 , ...
- ArcMap导入图层出现General function failure问题
问题描述: 使用ArcMap的FeatureClassToFeatureClass命令导入图层,出现如下图的错误提示: 解决方法: 参考http://forums.esri.com/thread.as ...
- 吴裕雄 数据挖掘与分析案例实战(14)——Kmeans聚类分析
# 导入第三方包import pandas as pdimport numpy as np import matplotlib.pyplot as pltfrom sklearn.cluster im ...
- 大型运输行业实战_day09_1_日期转换与My97DatePicker插件使用
1.日期转换 1.1字符串类型转换成时间Date类型 /** * 给定字符串 转变 为 Date 类型 * @param date 时间 * @param format 时间格式 如:yyyy-MM- ...