【CSAPP笔记】12. 高速缓存存储器
高速缓存存储器
在存储层次结构中,高速缓存存储器,也叫 cache 是最接近 CPU 寄存器的那一块。
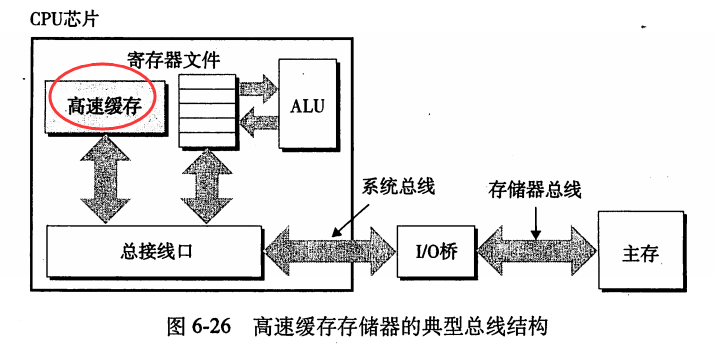
更一般而言,缓存(caching)是一个无所不在的技术。缓存的意思是:对于每层的存储设备,位于 k 层的更快更小的存储设备,都能用作位于 k+1 层的更大更慢的存储设备的缓存,这也是存储器层次结构的中心思想。
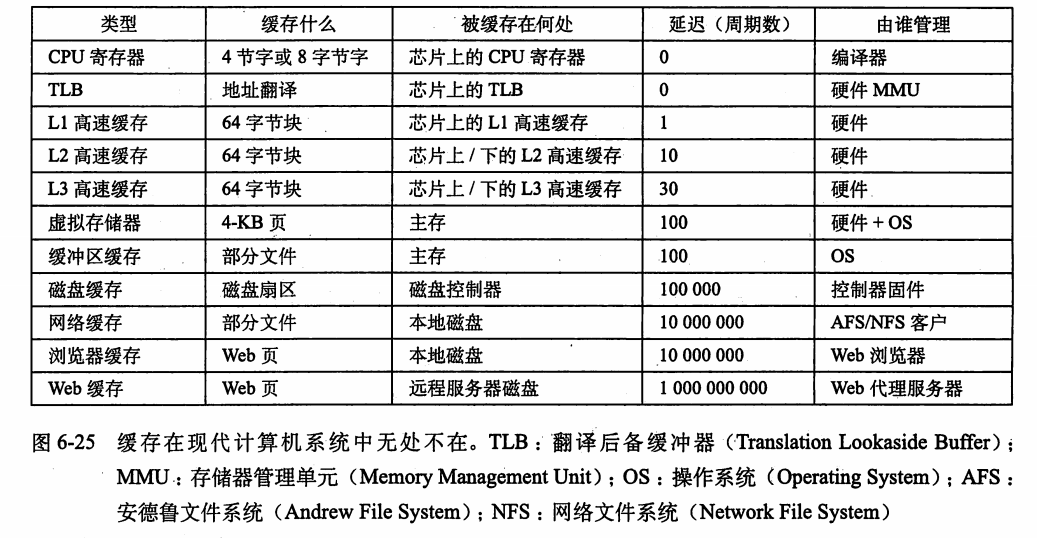
存储器层次结构的本质是:每一层存储设备都是较低一层的缓存。在每一层上,某种形式的逻辑必须管理缓存,可以是硬件、软件、或软硬结合。例如:编译器管理寄存器文件,是缓存的最高层次。L1、L2、L3 高速缓存是由硬件逻辑来管理的。在一个有虚拟存储器的系统中,DRAM 就是磁盘上的数据块的缓存,是由操作系统、CPU 上的地址翻译逻辑管理的。
缓存的基本原理、命中
当 CPU 需要一个数据的时候,不只是读取这个数据的一些字节。数据总是以块作为一个传送单元在第 k 层和第 k+1 层之间来回拷贝的。第 k 层作为第 k+1 的缓存,在任何时刻,缓存中都保存着一个 k+1 层的块的一个子集,如图所示:
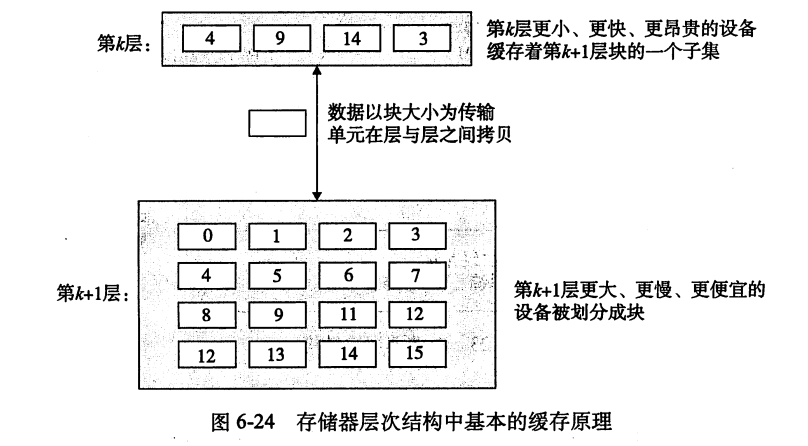
缓存命中
当程序需要第 k+1 层中的某个数据对象 d 时,会首先在更高一层的 k 层的块中查找 d,根据存储器层次结构的性质,第 k 层的读取速度比 k+1 层的快 。如果 d 刚好在第 k 层中,那么就叫做缓存命中(cache hit)。例如,一个有良好时间局部性的程序可以经常从上图中的块 14 中读取一个数据对象,因此程序运行得很快。
缓存不命中
如果 d 不在 k 层中,那就是缓存不命中(cache miss)。一旦发生不命中,可能有两种行为:一是取出 k+1 层中包含 d 那个块,放到第 k 层中。二是第 k 层中已经满了,此时就需要采取替换(replacint),取出第 k 层原有的一个块作为牺牲块(victim),然后与包含 d 的那个块替换。决定由哪一个块作为牺牲块,就叫做替换策略(replacement policy)
不命中有三种种类:
- 冷不命中(clod miss):一开始高速缓存里一定是空的,那么对任何对象的访问都不会命中。
- 冲突不命中(confilict miss):缓存足够大,但是因为某些对象会映射到同一个缓存块,会引起替换,导致缓存一直不命中。
- 容量不命中(capacity miss):工作集大小超过缓存的大小。
cache 结构
早期计算机系统存储器的层次只有三层:CPU 寄存器、DRAM 主存和磁盘。不过由于 CPU 和主存之间的差距逐渐增大,设计者被迫在寄存器文件和主存之间插入了一个小的 SRAM 高速缓存存储器,也就是 L1 高速缓存(一级 cache)。L1 cache 的访问速度几乎和寄存器一样快。随后,系统设计者又插入了 L2 高速缓存和 L3 高速缓存。
下面介绍高速缓存的通用组织。

考虑一个存储器地址有 m 位的计算机系统,能形成 $ M = 2^m $ 个不同的地址。
高速缓存有三个关键的指标:
- $ S = 2^s $ 个高速缓存组(set)的数组。
- 每个组包含 $ E $ 个高速缓存行(line)。
- 每行由一个 $ B = 2^b $ 字节的数据块(block)组成的
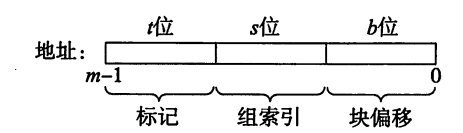
从地址上来看,可以把 S、E、B 理解为层级关系:高速缓存是一个数组,一共 S 组,每组包含 E 行,每行一个 B 字节的块和其他信息。
其他信息包括:有效位(valid bit)标明这个行是否包含有意义的信息。还有 $ t = m - b - s $ 个标记位(tag)用来标识存储在此的块。
高速缓存的大小指的是所有块大小的和。标记位和有效位不包含实际的块内数据信息,不算在内。因此:
\]

直接相映
每个组只有一行(E = 1)的高速缓存称为直接相映高速缓存(direct-mapped cache)。高速缓存确定一个请求是否命中,然后取出被请求的字的过程,分为三步:
- 组选择
- 行匹配
- 字抽取
组选择
(假设计算机系统有一个 CPU 、寄存器文件、一个 L1 高速缓存和一个主存)
当 CPU 执行一条读存储器字 w 的指令。它向 L1 高速缓存请求这个字。L1 要确定这个请求是否命中,首先进行组选择。从 w 的地址中间抽出索引位。这 s 个位就被看成是一个数组的索引,
行匹配
已经选择了一个组之后,接下来一步要确定是否有字 w 的一个拷贝存在这个组的一个高速缓存行中。在直接相映高速缓存中这很容易,因为每一组只有一行。如果有效位被设置了,而且标记位和要读的字 w 中的标记相匹配时,这一行就包含 w 的拷贝。换句话说,到这里就确定得到了一个缓冲命中。另一方面,如果有效位没有被设置(类似于冷不命中的情况),或者标记不匹配(别的数据也会放到这一组里),就得到一个缓冲不命中。
字选择
一旦我们知道 w 就在这个这个高速缓存组中,最后一步只要确定我们要读的块是从哪里开始的就行。块偏移就提供了所需要的第一个字节的偏移。
不命中时
如果缓存不命中,那就需要从存储器层次结构中的下一层取出被请求块,然后将新块存储在组索引位指示的组中的一个高速缓存行中。如果每行都满了,就要驱逐一个现有行。对于直接相映高速缓存,因为每组只有一行,所以替换策略非常简单:用取出的行替代当前行。
组相联
直接相映高速缓存的冲突不命中造成的原因就是因为每一组只有一行。组相联高速缓存(set associative cache)放松了这条限制,每个组保存多于一行的高速缓存行。$ 1 < E < \frac{C}{B} $
组选择和直接相映组选择没什么区别,也是用组索引标记组。
行匹配的话,就复杂一些,因为一个组有多个行,组中的任何一行都可以包含任何映射到这个组的存储器块,所以高速缓存必须搜索组中的每一行,来寻找一个标记与要读取的字中地址的标记匹配的有效行。
替换策略就变得复杂了。如果发生了不命中时组里还有空行,只需直接拉入 cache 中即可。但如果没有空行,我们就必须选择一个作为替换行。最简单的替换策略是随机选择一个要替换的行替换出去。更好的替换策略就考虑到了局部性原理,使得在较近的将来使用被替换出去的行的概率最小。最不常使用(Least-Frequently-Used,LFU)替换一个在过去一段时间内引用最少的一行。最近最少使用(Least-Recently-Used,LRU)替换最后一次访问时间最久远的一行。复杂的替换策略都需要额外的时间和硬件成本。一般来说,在存储器层次结构中,越往下走,一次不命中的开销就更加昂贵,用更好的替换策略也就显得更值得了。
全相联
全相连高速缓存(fully associative cache)是一个包含所有高速缓存行的组。即 $ E = \frac{C}{B} $
组选择就很简答,因为只有一个组,不需要在地址中有组索引位,只需要有效位、标记位和偏移。
行匹配和字选择和组相联高速缓存中是一样的。前面提到,对于一个组包含多个行的,就必须搜索所有行。因此构造一个又大又快的相联高速缓存很困难,也很昂贵。因此全相联高速缓存只适合做小的高速缓存,例如虚拟存储器中的翻译备用缓冲器(TLB),它缓存页表项。
写入
也就是写 cache,CPU 把待处理或已经处理的数据存入高速缓存中。
写入的情况比读要复杂一些。假设我们要写一个已经缓存了的字 w 的写命中(write hit)。在高速缓存更新了字 w 的拷贝之后,怎么更新 w 在更低层次中的拷贝呢?处理写命中有两种方式:
- 直写(write-throug):立即将 w 的高速缓存块写回紧接的低一层中。
- 写回(write-back):尽可能推迟存储器更新,只有当替换算法要驱逐更新过的块时,才将其写到紧接的低一层中。
如何处理写不命中(写不命中就是包含 w 的块不在 cache 中)?
- 写分配(write-allocate):加载相应的低一层的块到高速缓存中,然后更新这个高速缓存块
- 非写分配(not-write-allocate):避开高速缓存,直接把这个字写到低一层中。
优化写操作是一个细致而又困难的问题。
处理写命中时,直写相当简单,但缺点就是每次写都会引起总线流量。写回能显著减少总线流量,但增加了复杂性,对于高速缓存,需要维护一个额外的修改位,来表明这个块是否被修改过。处理写不命中时,写分配试图利用空间局部性,缺点是每次不命中都会导致一个低一层的块被传送到高速缓存。直写通常是非写分配的,写回通常是写分配的。
参数对性能的影响
- 高速缓存的大小:较大的高速缓存可能会提高命中率,但实现一个大的存储器总是要更难一些。
- 块大小:较大的块可能可以更好的利用空间局部性。不过,对于给定的高速缓存大小,块越大意味着高速缓存行数越小,这会损害时间局部性比空间局部性好的程序的命中率。此外,因为块比较大,当出现不命中惩罚时,传送时间较长。
- 相联度:较高的相联度的优点是降低了由于冲突不命中出现抖动的可能性,缺点就是需要更多的成本,还会增加不命中惩罚,因为选择牺牲行的算法复杂度增加了。
- 写策略:直写比较容易实现。越往存储器层次结构下面走,传送时间增加,减少传送数量就变得更加重要。一般而言,高速缓存越往下层,越可能使用写回而不是直写。比较建议采用写回和写分配的高速缓存模型
可以看到,很多事情不是非黑即白的,一项技术既不是完美无缺也不是一无是处,我们往往都需要寻找折衷方案。
编写高速缓存友好的代码
利用局部性原理
- 利用时间局部性,一旦一个数据对象在第一次不命中的时候被拷贝到缓存中,那么就期望后面对该目标有一系列的访问命中。
- 利用空间局部性:块包含多个数据对象,期望后面对该块中的其他对象的访问能弥补不命中后拷贝该块的花费。
避免冲突不命中
例如:
float dotprod(float x[8], float y[8])
{
float sum = 0.0;
int i;
for(i = 0; i < 8; i++)
sum += x[i] * y[i];
return sum;
}
对于 x 和 y 数组来说,这个函数具有良好的空间局部性,因此我们期望它对高速缓存的利用率较高。不幸的是,事实并非总是如此。这里,float是 4 个字节,假设 x 的是位于从 0 开始到 32 的连续存储器中,y 紧随其后,从 32 到 64。假设一个块是 16 个字节。高速缓存由两个组构成,整个高速缓存的大小是 32 字节。
在运行时,第一次迭代引用的是 x[0],冷不命中,加载进入 cache 的第一个块包含了 x[0] 到 x[3] 的四个浮点数。接下来是对 y[0] 的引用。很不幸的是,y[0]的组索引和 x[0] 是一样的,因此包含 y[0]的块被拷贝进来的时候,又覆盖了包含了 x[0] 到 x[3] 的块。冲突不命中就是读取数据的时候,这些数据都映射到同一个组中。虽然高速缓存有其他空余的空间,但都没有利用到。用一个术语抖动(thrash)来描述在同一个组中不断出现冲突不命中。
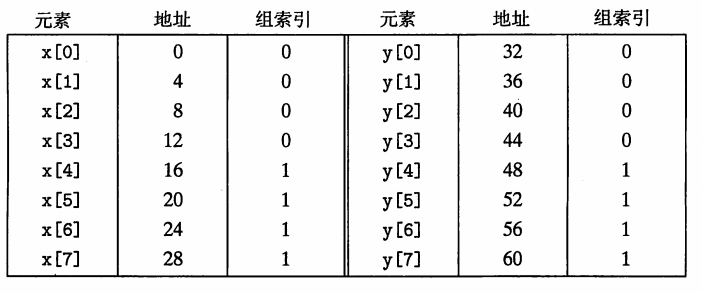
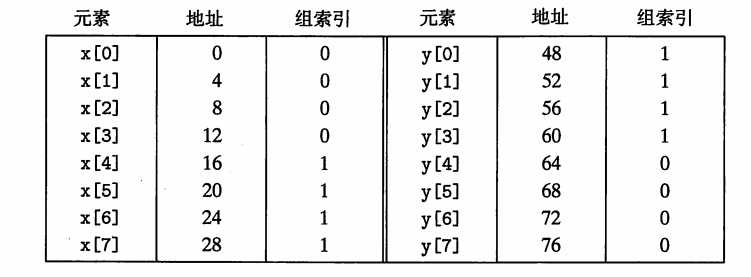
即使程序有良好的空间局部性,也可能因为抖动而出现速度下降,这个问题是很真实的。如果程序员能意识到,修正抖动是很容易的。例如,将数组 x 定义得更长一点,定义成 float x[12],让x[i]和y[i]映射到不同的组,就可以消除这个问题。
【CSAPP笔记】12. 高速缓存存储器的更多相关文章
- 【CSAPP笔记】11. 存储器层次结构
在没有专门研究存储器系统之前,我们依赖的存储器模型是一个很简单的概念,也就是把它看成一个线性数组,CPU 能在一个常数时间内访问任何一个存储器位置.虽然在研究别的问题时,这是一个有效的模型,但是它不能 ...
- [CSAPP笔记][第六章存储器层次结构]
第六章 存储器层次结构 在简单模型中,存储器系统是一个线性的字节数组,CPU能够在一个常数访问每个存储器位置. 虽然是一个行之有效的模型,但没有反应现代系统实际工作方式. 实际上,存储器系统(memo ...
- [CSAPP笔记][第八章异常控制流][呕心沥血千行笔记]
异常控制流 控制转移 控制流 系统必须能对系统状态的变化做出反应,这些系统状态不是被内部程序变量捕获,也不一定和程序的执行相关. 现代系统通过使控制流 发生突变对这些情况做出反应.我们称这种突变为异常 ...
- [CSAPP笔记][第一章计算机系统漫游]
计算机系统漫游 我们通过追踪hello程序的生命周期来开始对系统的学习—–从它被程序员创建,到系统上运行,输出简单的消息,然后终止.我们沿着这个程序的生命周期,简要介绍一些逐步出现的概念,专业术语和组 ...
- CPU的高速缓存存储器知识整理
基于缓存的存储器层次结构 基于缓存的存储器层次结构行之有效,是因为较慢的存储设备比较快的存储设备更便宜,还因为程序往往展示局部性: 时间局部性:被引用过一次的存储器的位置很可能在不远的将来被再次引用. ...
- 机器学习实战 - 读书笔记(12) - 使用FP-growth算法来高效发现频繁项集
前言 最近在看Peter Harrington写的"机器学习实战",这是我的学习心得,这次是第12章 - 使用FP-growth算法来高效发现频繁项集. 基本概念 FP-growt ...
- Ext.Net学习笔记12:Ext.Net GridPanel Filter用法
Ext.Net学习笔记12:Ext.Net GridPanel Filter用法 Ext.Net GridPanel的用法在上一篇中已经介绍过,这篇笔记讲介绍Filter的用法. Filter是用来过 ...
- SQL反模式学习笔记12 存储图片或其他多媒体大文件
目标:存储图片或其他多媒体大文件 反模式:图片存储在数据库外的文件系统中,数据库表中存储文件的对应的路径和名称. 缺点: 1.文件不支持Delete操作.使用SQL语句删除一条记录时,对应的文 ...
- JAVA自学笔记12
JAVA自学笔记12 1.Scanner 1)JDK5后用于获取用户的键盘输入 2)构造方法:public Scanner(InputStream source) 3)System.in 标准的输入流 ...
随机推荐
- jQuery----左侧导航栏面板切换实现
页面运行结果: 点击曹操 点击刘备 点击孙权 原图 需求说明:原图如上所示,点击一方诸侯的时候 ...
- laravel 5.5 《电商实战 》基础布局
我们需要为我们的项目构建一个基础的页面布局,布局文件统一存放在 resources/views/layouts 文件夹中,布局涉及的文件如下: app.blade.php —— 主要布局文件,项目的所 ...
- mac 下安装php7.1 memcache扩展
1.下载memcache源代码文件 https://github.com/websupport-sk/pecl-memcache/archive/php7.zip 文件夹名为:pecl-memcach ...
- python+soket实现 TCP 协议的客户/服务端中文(自动回复)聊天程序
[吐槽] 网上的代码害死人,看着都写的言之凿凿,可运行就是有问题. 有些爱好代码.喜欢收藏代码的朋友,看到别人的代码就粘贴复制过来.可是起码你也试试运行看啊大哥 [正文] 昨日修改运行了UDP协议的C ...
- 【转】QT事件传递与事件过滤器
[概览] 1.重载特定事件函数. 比如: mousePressEvent(),keyPressEvent(), paintEvent() . 2.重新实现QObject::ev ...
- Golang 写一个端口扫描器
前话 最近痴迷于Golang这个新兴语言,因为它是强类型编译型语言,可以直接编译成三大平台的二进制执行文件,可以直接运行无需其他依赖环境.而且Golang独特的goroutine使得多线程任务执行如n ...
- UWP DEP0700: 应用程序注册失败。[0x80073CF9] Install failed. Please contact your software vendor. (Exception from HRESULT: 0x80073CF9)
现在部署的app项目八成是从以前的一个项目复制过来,修改的.或者本地存在一个相同的app没有卸载. 解决方法: 1. 卸载之前相同的app 2.如果是复制的项目A,但是经过修改后变成了项目B,并且A和 ...
- UWP MySQL 最新版 6.10.5是坏的
#实锤#证实了,MySQL 最新版 6.10.5,在UWP平台并不能连接,是坏的 Oracle竟然没有测试吗?直接上线??? 我已经把把BUG设置为最高严重等级,提交给了官方. I'm using u ...
- 【总结】详细说说Html.ActionLink的用法
Html.ActionLink概述 在MVC的Rasor视图引擎中,微软采用一种全新的方式来表示从前的超链接方式,它代替了从前的繁杂的超链接标签,让代码看起来更加简洁,通过浏览器依然会解析成传统的a标 ...
- JavaScript——历史与简介
上一篇博文距离现在已经四个月了,一直想写些什么无奈工作比较忙碌.我的恩师老王在毕业聚餐那天带着一声酒气告诉我一定要把博客坚持写下去,所以今天下决心要开始这个新的篇章. 之所以想要从头写一个关于Java ...