nltk31_twitter情感分析
python机器学习-乳腺癌细胞挖掘(博主亲自录制视频)https://study.163.com/course/introduction.htm?courseId=1005269003&utm_campaign=commission&utm_source=cp-400000000398149&utm_medium=share

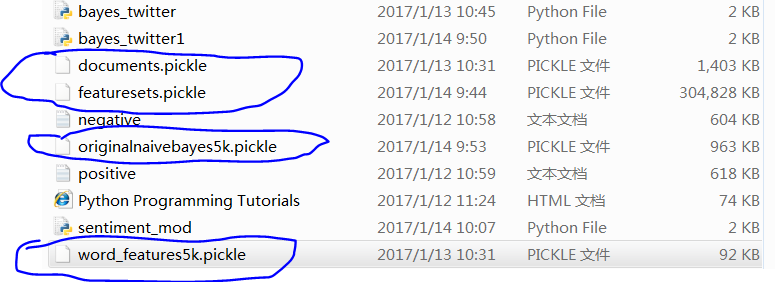
已经生成4个pickle文件,分别为documents,word_features,originalnaivebayes5k,featurests
其中featurests容量最大,3百多兆,如果扩大5000特征集,容量继续扩大,准确性也提供
https://www.pythonprogramming.net/sentiment-analysis-module-nltk-tutorial/
Creating a module for Sentiment Analysis with NLTK
# -*- coding: utf-8 -*-
"""
Created on Sat Jan 14 09:59:09 2017 @author: daxiong
""" #File: sentiment_mod.py import nltk
import random
import pickle
from nltk.tokenize import word_tokenize documents_f = open("documents.pickle", "rb")
documents = pickle.load(documents_f)
documents_f.close() word_features5k_f = open("word_features5k.pickle", "rb")
word_features = pickle.load(word_features5k_f)
word_features5k_f.close() def find_features(document):
words = word_tokenize(document)
features = {}
for w in word_features:
features[w] = (w in words) return features featuresets_f = open("featuresets.pickle", "rb")
featuresets = pickle.load(featuresets_f)
featuresets_f.close() random.shuffle(featuresets)
print(len(featuresets)) testing_set = featuresets[10000:]
training_set = featuresets[:10000] open_file = open("originalnaivebayes5k.pickle", "rb")
classifier = pickle.load(open_file)
open_file.close() def sentiment(text):
feats = find_features(text)
return classifier.classify(feats) def sentiment_test(text):
feats = find_features(text)
value=classifier.classify(feats)
if value=="pos":
print("正面评价")
else:
print("负面评价")
def sentiment_inputTest():
text=input("主人请输入留言:")
feats = find_features(text)
value=classifier.classify(feats)
if value=="pos":
print("正面评价")
else:
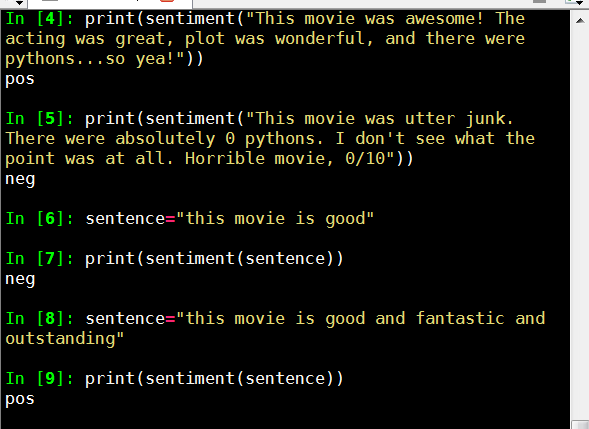
print("负面评价") print(sentiment("This movie was awesome! The acting was great, plot was wonderful, and there were pythons...so yea!"))
print(sentiment("This movie was utter junk. There were absolutely 0 pythons. I don't see what the point was at all. Horrible movie, 0/10"))
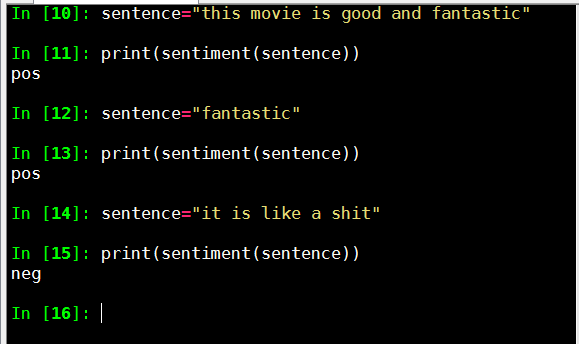
测试效果
还是比较准,the movie is good 测试不准,看来要改进算法,考虑用频率分析和过滤垃圾词来提高准确率

nltk31_twitter情感分析的更多相关文章
- 朴素贝叶斯算法下的情感分析——C#编程实现
这篇文章做了什么 朴素贝叶斯算法是机器学习中非常重要的分类算法,用途十分广泛,如垃圾邮件处理等.而情感分析(Sentiment Analysis)是自然语言处理(Natural Language Pr ...
- Stanford NLP学习笔记:7. 情感分析(Sentiment)
1. 什么是情感分析(别名:观点提取,主题分析,情感挖掘...) 应用: 1)正面VS负面的影评(影片分类问题) 2)产品/品牌评价: Google产品搜索 3)twitter情感预测股票市场行情/消 ...
- 情感分析的现代方法(包含word2vec Doc2Vec)
英文原文地址:https://districtdatalabs.silvrback.com/modern-methods-for-sentiment-analysis 转载文章地址:http://da ...
- SA: 情感分析资源(Corpus、Dictionary)
先主要摘自一篇中文Survey,http://wenku.baidu.com/view/0c33af946bec0975f465e277.html 4.2 情感分析的资源建设 4.2.1 情感分析 ...
- 爬虫再探实战(五)———爬取APP数据——超级课程表【四】——情感分析
仔细看的话,会发现之前的词频分析并没有什么卵用...文本分析真正的大哥是NLP,不过,这个坑太大,小白不大敢跳...不过还是忍不住在坑边上往下瞅瞅2333. 言归正传,今天刚了解到boson公司有py ...
- Python爬虫和情感分析简介
摘要 这篇短文的目的是分享我这几天里从头开始学习Python爬虫技术的经验,并展示对爬取的文本进行情感分析(文本分类)的一些挖掘结果. 不同于其他专注爬虫技术的介绍,这里首先阐述爬取网络数据动机,接着 ...
- C#编程实现朴素贝叶斯算法下的情感分析
C#编程实现 这篇文章做了什么 朴素贝叶斯算法是机器学习中非常重要的分类算法,用途十分广泛,如垃圾邮件处理等.而情感分析(Sentiment Analysis)是自然语言处理(Natural Lang ...
- R语言做文本挖掘 Part5情感分析
Part5情感分析 这是本系列的最后一篇文章,该.事实上这种单一文本挖掘的每一个部分进行全部值获取水落石出细致的研究,0基础研究阶段.用R里面现成的算法,来实现自己的需求,当然还參考了众多网友的智慧结 ...
- 如何科学地蹭热点:用python爬虫获取热门微博评论并进行情感分析
前言:本文主要涉及知识点包括新浪微博爬虫.python对数据库的简单读写.简单的列表数据去重.简单的自然语言处理(snowNLP模块.机器学习).适合有一定编程基础,并对python有所了解的盆友阅读 ...
随机推荐
- 软件功能说明书final修订
贪吃蛇(单词版)软件功能说明书final修订 1 开发背景 “贪吃蛇”这个游戏对于80,90后的人来说是童年的记忆,可以将其说为是一个时代的经典,实现了传统贪吃蛇的游戏功能:现在人们对英语的重视程度越 ...
- (第六周)课上Scrum站立会议演示
组名:连连看 组长:张政 组员:张金生.李权.武志远 时间:2016.10.13 20:20——20:40 会议内容: 已完成的内容: 1.选定编译语言,安装软件并配置环境,完成了游戏的基本模型. ...
- POJ 2096 Collecting Bugs 期望dp
题目链接: http://poj.org/problem?id=2096 Collecting Bugs Time Limit: 10000MSMemory Limit: 64000K 问题描述 Iv ...
- Results the mutual for the first time(alpha阶段总结)
由于前天听大家的成果展时,做得笔记不够完善,有一两个组找不到信息,如果没有评到的组望谅解. 分数分配: 由于组内某些原因,我们现重新分组: 试用版: 总结前阶段的工作: 在前一段时间,我们第一个spr ...
- Software Defined Networking(Week 2, part 3)
Control of Packet-switch Network 我们已经讨论过中心控制网络的原理,但主要是以电话网络做模型的.现在我们来看看对于分组交换网络的控制是如何改进的. Why Separa ...
- InputStreamReader & OutputStreamWriter
InputStreamReader 是字节流通向字符流的桥梁:它使用指定的 charset 读取字节并将其解码为字符. OutputStreamWriter 是字符流通向字节流的桥梁:可使用指定的 c ...
- Android:java.lang.OutOfMemoryError:GC overhead limit exceeded
Android编译:java.lang.OutOfMemoryError:GC overhead limit exceeded 百度好多什么JVM啊之类的东西,新手简单粗暴的办法: 1.在的Model ...
- 模拟alert,confirm 阻塞状态
/*** * 模拟alert弹窗 * content 为弹框显示的内容 * 确定按钮对应的下面取消关闭显示框 * **/function oAlert(content) { var oWrap = $ ...
- PAT 甲级 1137 Final Grading
https://pintia.cn/problem-sets/994805342720868352/problems/994805345401028608 For a student taking t ...
- Delphi CreateMutex 防止程序多次运行
windows是个多用户多任务的操作系统,支持多个程序同时运行,如果你的程序不想让用户同时运行一个以上, 那应该怎样做呢? 本文将介绍避免用户同时运行多个程序的例子. 需要用到的函数CreateMut ...